LSTM+GRU
参考:脑补链接。。图片都是这里的,我只是补充一些。。
了解一下RNN
卷积神经网络就通过各种卷积核共享参数,降低参数量并且可以利用空间位置信息。但是输入的大小要是固定的,所以在NLP方面,对于输入大小不固定,信息还要与前后关联,这种序列数据就需要循环神经网络了。RNN通过共享全连接的权重来大大的减少参数量。
RNN的工作原理是:第一个词被转换成机器可读的向量(词向量吗)。然后RNN逐个处理向量序列,学习词与词之间的语义关系(时序信息)。
RNN 就是将先前的隐藏状态传递给序列的下一步。隐藏状态充当神经网络的记忆。它保存着网络以前见过的数据信息。
H
t
=
f
(
X
W
x
h
+
H
t
−
1
W
h
h
+
b
h
)
H_t = f(XW_{xh} + H_{t-1}W_{hh} +b_h)
Ht=f(XWxh+Ht−1Whh+bh) X为输入,W权重,H时间步的隐藏变量,b偏置。在传递的过程中W是共享的。不同的时间步,RNN使用的是同一个模型的参数。
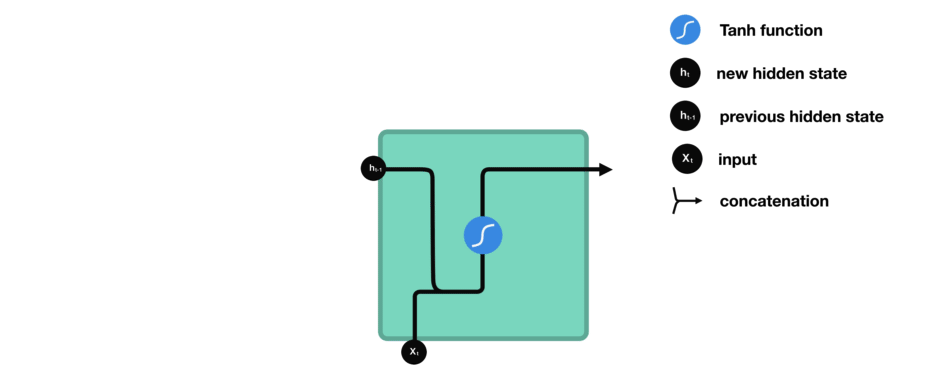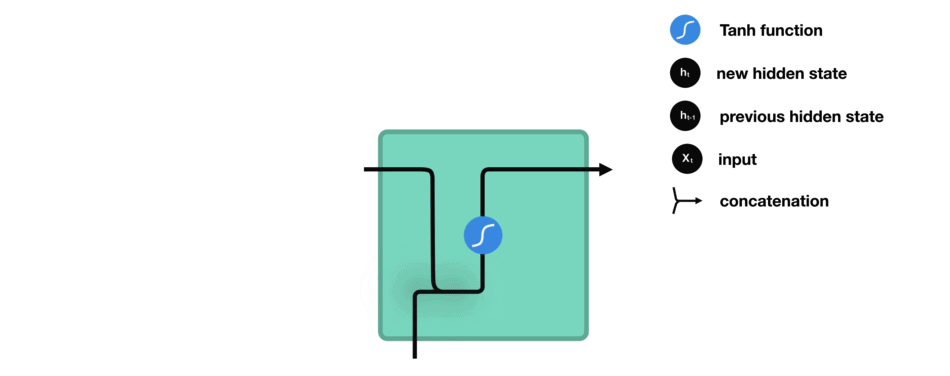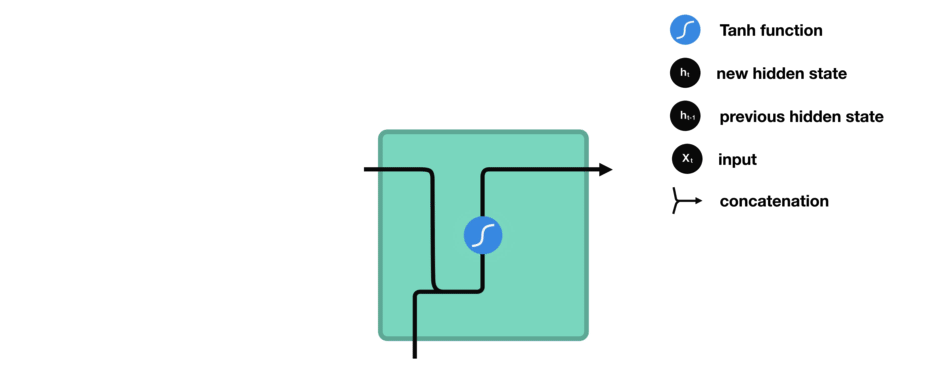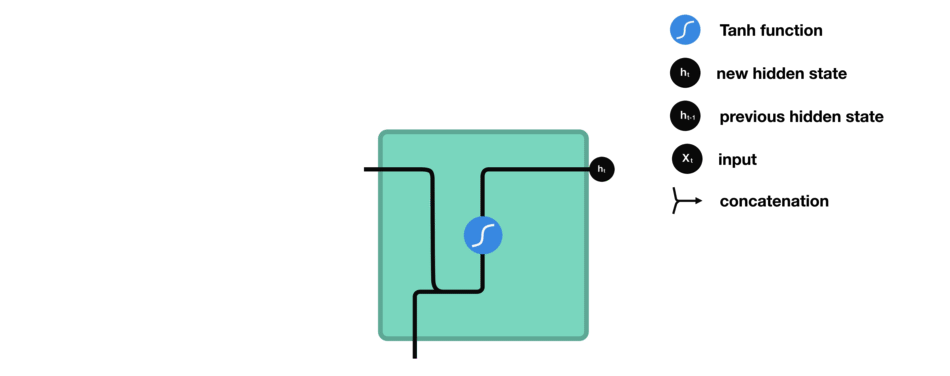
激活函数tanh的作用就是将结果保持在-1,1 的范围内,防止出现某个数过大

LSTM和GRU是作为短期记忆的解决方案而创建的。它们具有称为门(gate)的内部机制,它可以调节信息流。这些门可以了解序列中哪些数据重要以进行保留或丢弃。这样,它可以将相关信息传递到长序列中进行预测。
只保留相关信息进行预测,忘记不相干信息。
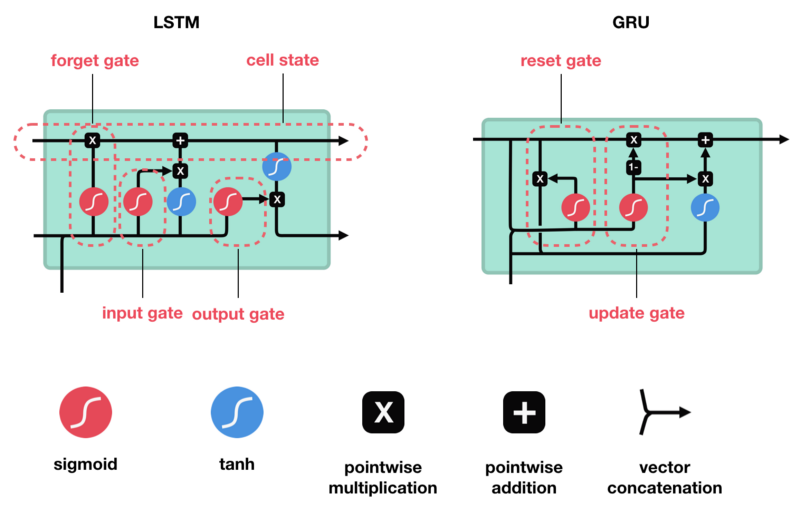
LSTM
- 遗忘门:此门决定应丢弃或保留哪些信息。来自先前隐藏状态和来自当前输入的信息通过sigmoid函数传递。值介于0和1之间。越接近0越容易遗忘,越接近1则意味着要保留。
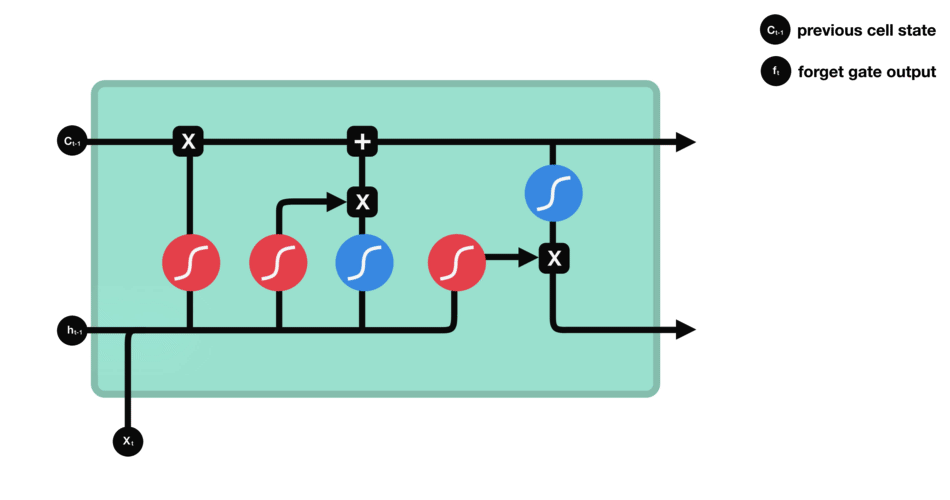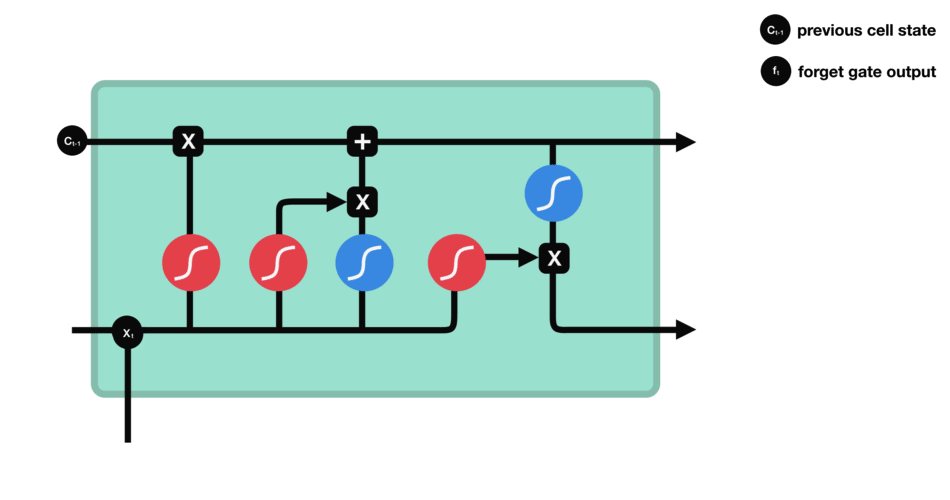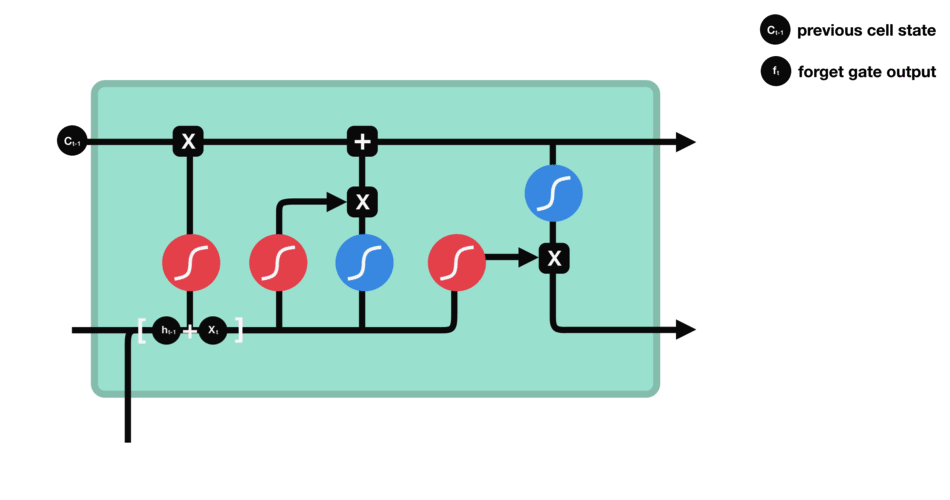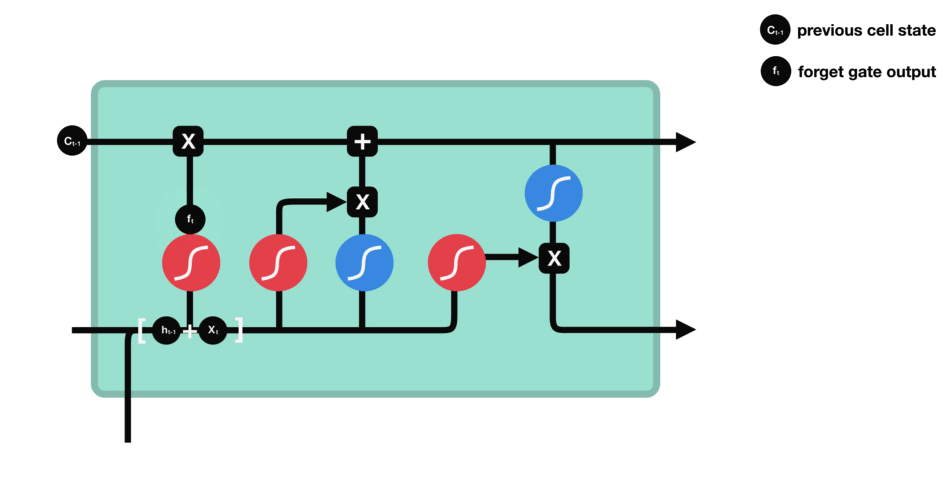
- 输入门:更新单元状态。先前的隐藏状态和当前输入传递给sigmoid函数。这决定了通过将值转换为0到1来更新哪些值。0表示不重要,1表示重要。你还将隐藏状态和当前输入传递给tanh函数,将它们压缩到-1和1之间以帮助调节网络。然后将tanh输出与sigmoid输出相乘。sigmoid输出将决定哪些信息很重要,需要tanh输出保存。
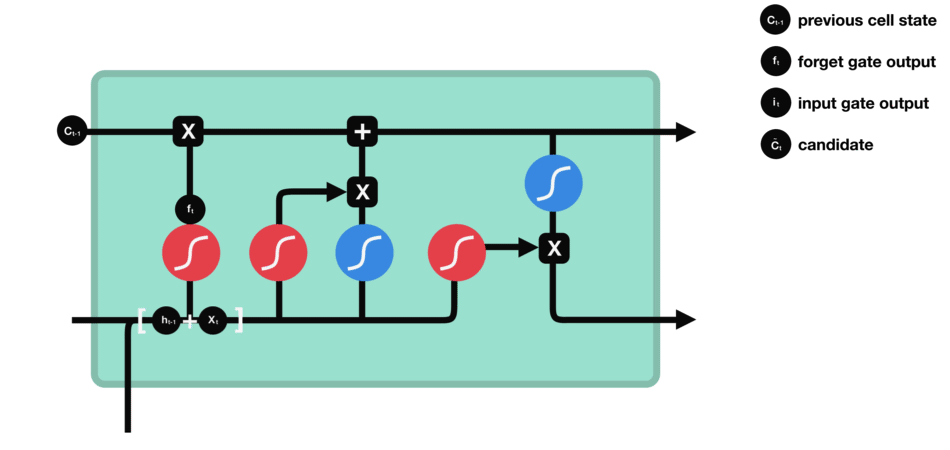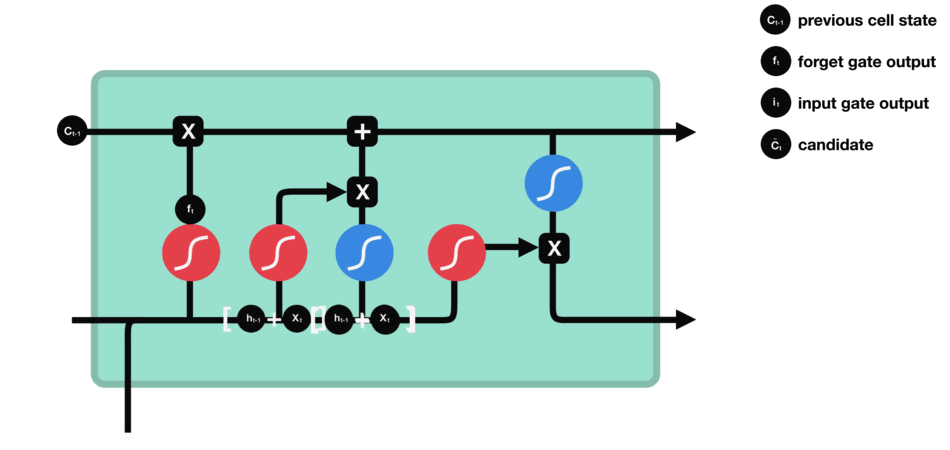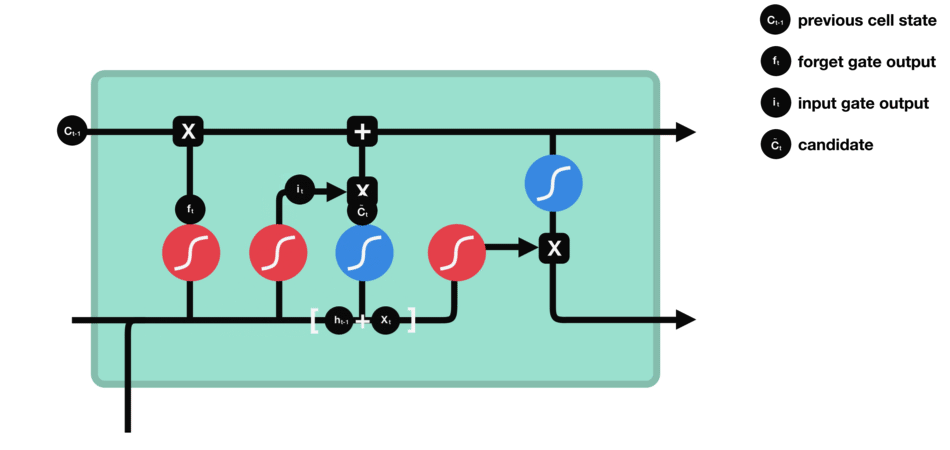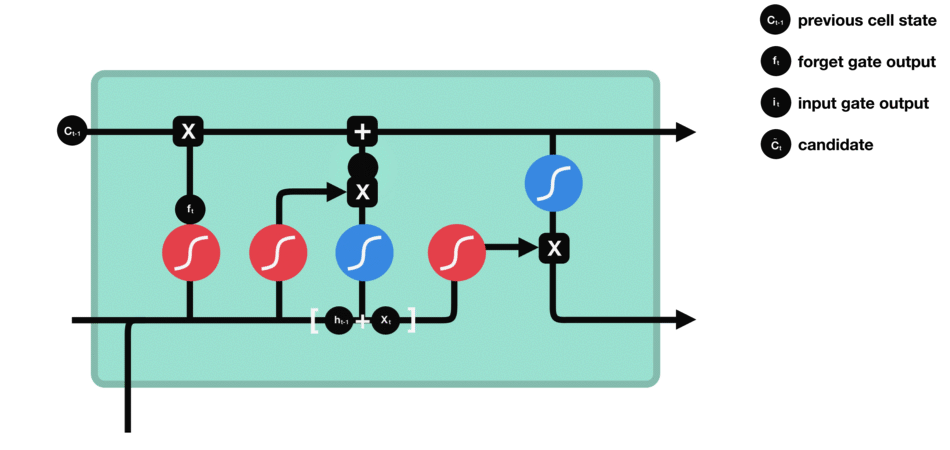
- 单元状态:现在我们有足够的信息来计算单元状态。首先,单元状态逐点乘以遗忘向量。如果它乘以接近0的值,则有可能在单元状态中丢弃值。然后我们从输入门获取输出并进行逐点加法,将单元状态更新为神经网络发现相关的新值。这就得到了新的单元状态。
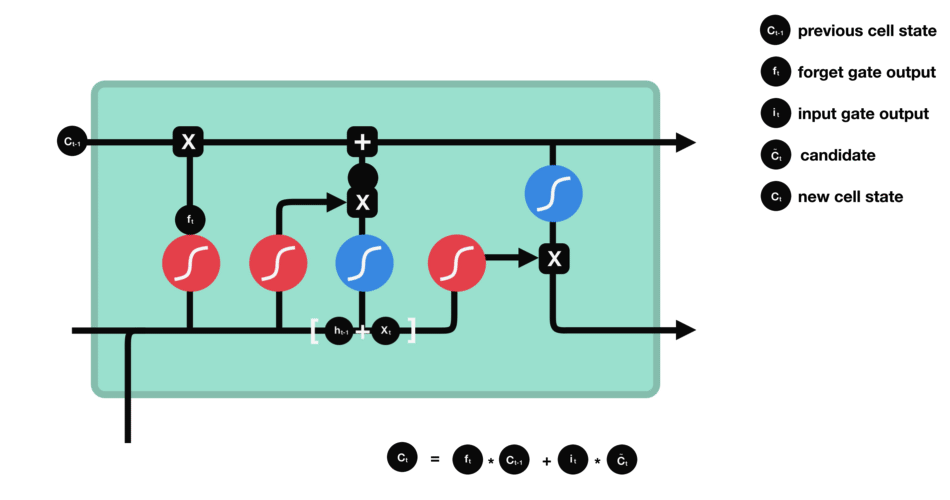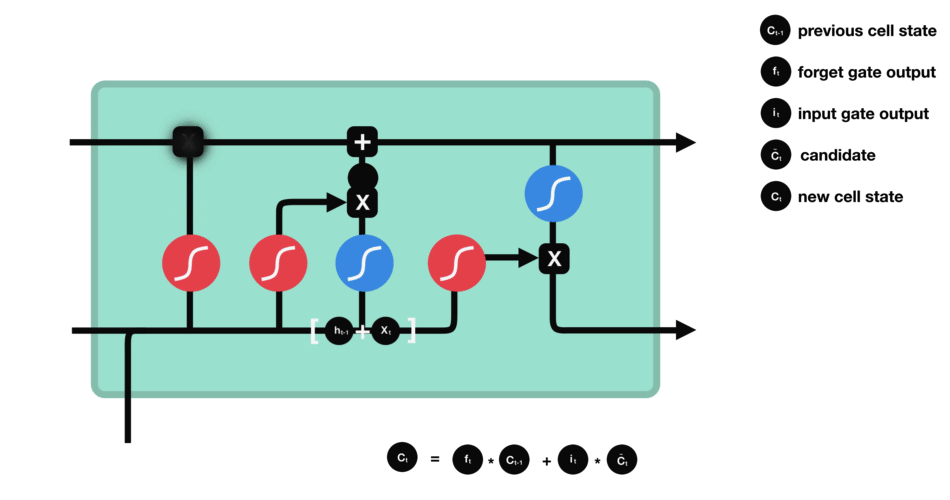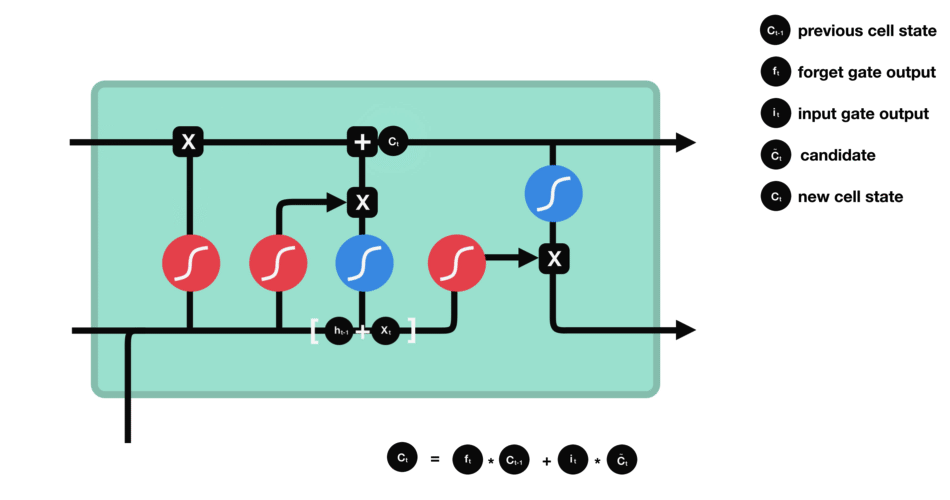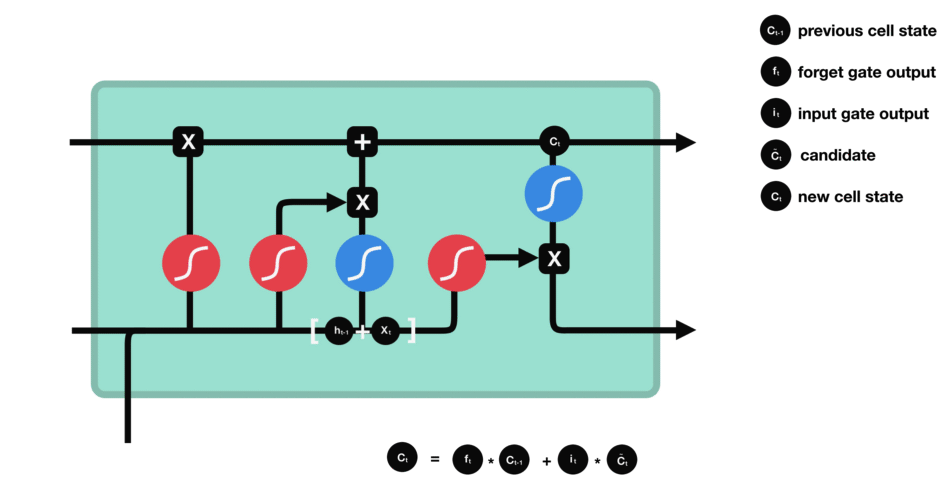
- 输出门:输出门决定下一个隐藏状态是什么。请记住,隐藏状态包含有关先前输入的信息。隐藏状态也用于预测。首先,我们将先前的隐藏状态和当前输入传递给sigmoid函数。然后我们将新的单元状态传递给tanh函数。将tanh输出与sigmoid输出相乘,以决定隐藏状态应携带的信息。它的输出是隐藏状态。然后将新的单元状态和新的隐藏状态传递到下一个时间步。
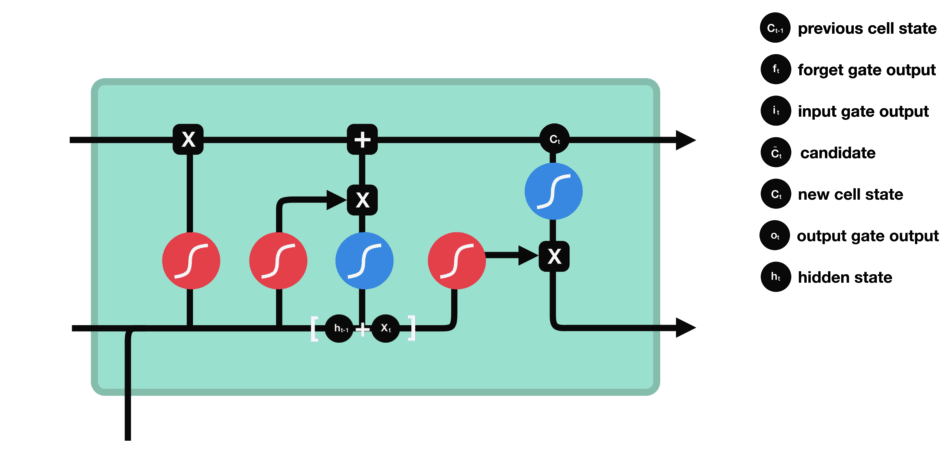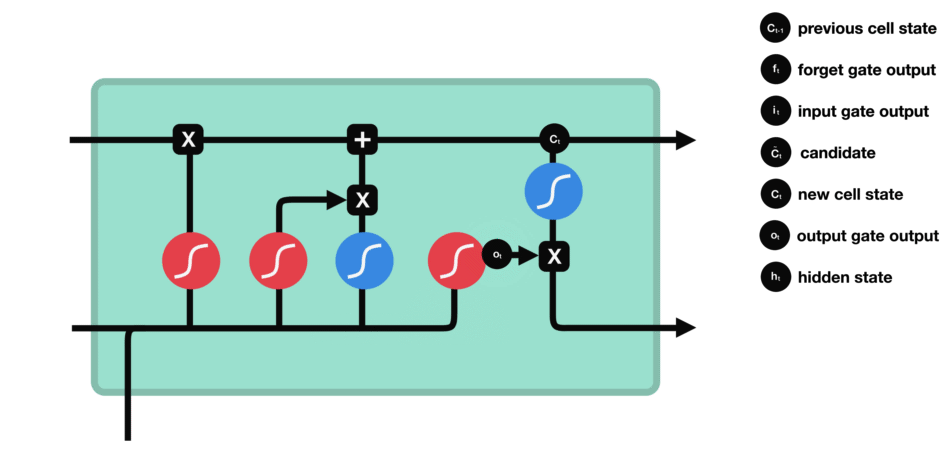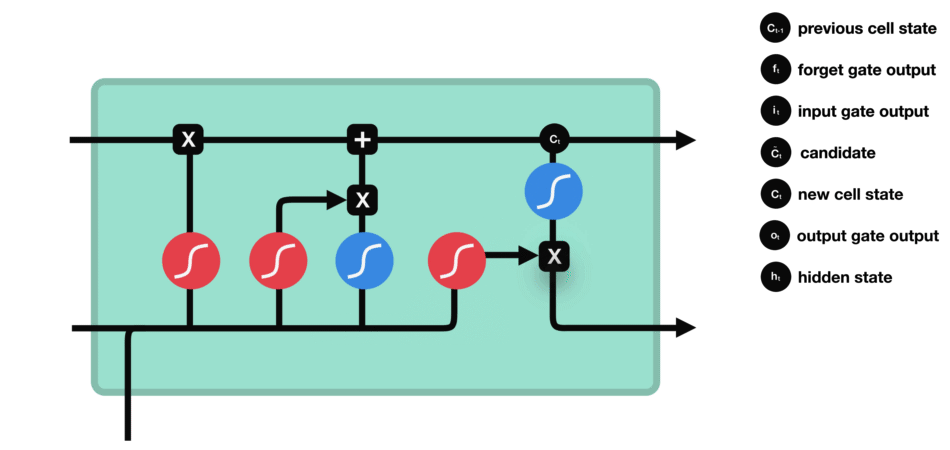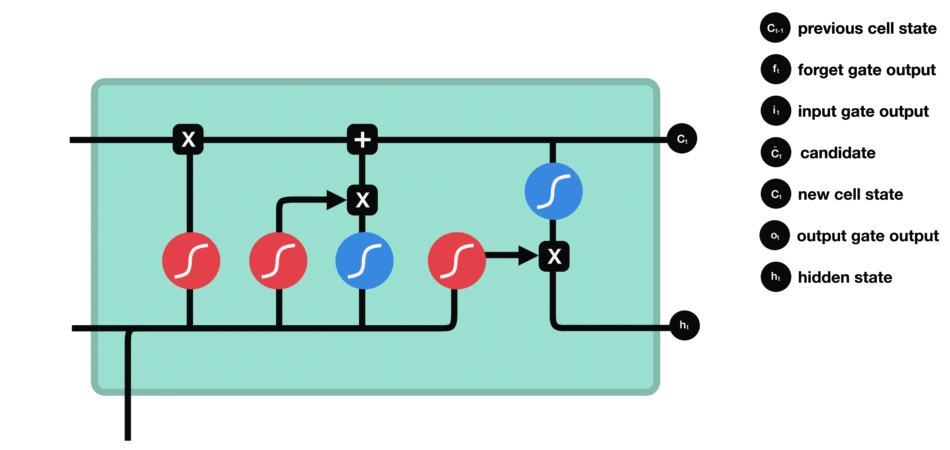
遗忘门决定了哪些内容与前面的时间步相关。输入门决定了从当前时间步添加哪些信息。输出门决定下一个隐藏状态应该是什么。
I t = σ ( X t W x i + H t − 1 W h i + b i ) 输 入 门 F t = σ ( X t W x f + H t − 1 W h f + b f ) 遗 忘 门 O t = σ ( X t W x o + H t − 1 W h o + b o ) 输 出 门 C ^ t = t a n h ( X t W x c + H t − 1 W h c + b c ) 候 选 记 忆 细 胞 C t = F t ⨀ C t − 1 + I t ⨀ C ^ t 点 乘 得 到 记 忆 细 胞 H t = O t ⨀ t a n h ( C t ) 得 到 下 一 个 时 间 的 隐 藏 状 态 I_t = sigma(X_tW_{xi} + H_{t-1}W_{hi} +b_i) 输入门\ F_t = sigma(X_tW_{xf} + H_{t-1}W_{hf} +b_f) 遗忘门\ O_t = sigma(X_tW_{xo} + H_{t-1}W_{ho} +b_o) 输出门\ hat{C}_t = tanh(X_tW_{xc} + H_{t-1}W_{hc} +b_c) 候选记忆细胞\ C_t = F_tbigodot C_{t-1} + I_t bigodot hat{C}_t 点乘得到记忆细胞\ H_t = O_tbigodot tanh(C_t) 得到下一个时间的隐藏状态 It=σ(XtWxi+Ht−1Whi+bi)输入门Ft=σ(XtWxf+Ht−1Whf+bf)遗忘门Ot=σ(XtWxo+Ht−1Who+bo)输出门C^t=tanh(XtWxc+Ht−1Whc+bc)候选记忆细胞Ct=Ft⨀Ct−1+It⨀C^t点乘得到记忆细胞Ht=Ot⨀tanh(Ct)得到下一个时间的隐藏状态
# pytorch 实现,这个过程按照上面哪个LSTM 的流程图来看,还是很直观的。。。
class LSTMCell(nn.Module):
def __init__(self, input_size, hidden_size, cell_size, output_size):
# 维度:10,20,20,10
super(LSTMCell, self).__init__()
self.hidden_size = hidden_size # 20
self.cell_size = cell_size # 20
self.gate = nn.Linear(input_size + hidden_size, cell_size)
# 30 -> 20
self.output = nn.Linear(hidden_size, output_size)
# 20->10
self.sigmoid = nn.Sigmoid()
self.tanh = nn.Tanh()
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden, cell): # (32,10),(32,20),(32,20)
combined = torch.cat((input, hidden), 1)
# (32,30)
f_gate = self.sigmoid(self.gate(combined)) # 遗忘门
# (32,20)
i_gate = self.sigmoid(self.gate(combined)) # 输入门
# (32,20)
o_gate = self.sigmoid(self.gate(combined)) # 输出门
# (32,20)
z_state = self.tanh(self.gate(combined)) # 输入状态
# (32,20)
cell = torch.add(torch.mul(cell, f_gate), torch.mul(z_state, i_gate))
# (32,20)
hidden = torch.mul(self.tanh(cell), o_gate) # cell记忆细胞
# (32,20)
output = self.output(hidden)
# ->(32,10)
output = self.softmax(output)
return output, hidden, cell # 得到输出,隐藏状态,记忆细胞进行下一次
def initHidden(self):
return torch.zeros(1, self.hidden_size)
def initCell(self):
return torch.zeros(1, self.cell_size)
lstmcell = LSTMCell(input_size=10, hidden_size = 20,cell_size = 20, output_size=10)
input = torch.randn(32,10)
h_0 = torch.randn(32,20)
out,hn,cn = lstmcell(input,h_0,h_0)
print(out.size(),hn.size(),cn.size())
torch.Size([32, 10]) torch.Size([32, 20]) torch.Size([32, 20])
# 以上只是LSTMCELL 就是单层的
# 下面使用现成的构建输入维度为10,隐含状态维度20,单向两层网络(就是得到的输入和隐藏状态再来一轮),输入节点和隐藏层节点之间是全连接
lstm = nn.LSTM(input_size=10,hidden_size=20,num_layers=2)
# LSTM比RNN 多了三个线性变化,组合一起就是权重就是RNN的四倍。(应该就是多了四个全连接的组合)
print("第一层:wih形状{},whh形状{},bih形状{}"
.format(lstm.weight_ih_l0.shape,lstm.weight_hh_l0.shape,lstm.bias_hh_l0.shape))
print("第二层:wih形状{},whh形状{},bih形状{}"
.format(lstm.weight_ih_l1.shape,lstm.weight_hh_l1.shape,lstm.bias_hh_l1.shape))
# 结果正好是RNN 的四倍。
第一层:wih形状torch.Size([80, 10]),whh形状torch.Size([80, 20]),bih形状torch.Size([80])
第二层:wih形状torch.Size([80, 20]),whh形状torch.Size([80, 20]),bih形状torch.Size([80])
input=torch.randn(100,32,10)
# 隐藏状态是两个(h0,c0)二者形状相同为(层数*方向,批量,hidden_size)
h_0=torch.randn(2,32,20)
h0 = (h_0,h_0) # 这就是合并嘛。。。
output,h_n = lstm(input,h0)
print(output.size(),h_n[0].size(),h_n[1].size()) # 隐藏状态的输入输出维度应该不变
torch.Size([100, 32, 20]) torch.Size([2, 32, 20]) torch.Size([2, 32, 20])
torch.nn.LSTM(* args,** kwargs )
-
input_size – 输入的特征
-
hidden_size – 隐藏层特征
-
num_layers – 循环图层数。设置num_layers=2 将意味着将两个LSTM堆叠在一起以形成堆叠的LSTM,而第二个LSTM则接收第一个LSTM的输出并计算最终结果。默认值:1
-
bias – 如果为False,则该层不使用偏差权重b_ih和b_hh。默认:True
-
batch_first – 如果为True,则输入和输出张量按(batch,seq,feature)提供。默认:False
-
dropout – 如果非零,则在除最后一层以外的每个LSTM层的输出上引入一个Dropout层,其 丢弃概率等于 dropout。默认值:0
-
bidirectional – 如果True成为双向LSTM。默认:False
-
proj_size – If > 0, will use LSTM with projections of corresponding size. Default: 0
-
输入:input(seq_len,batch,input_size), (h_0,c_0) shape = (num_layers * num_directions,batch,hidden_size) 层数*方向,默认为零,初始的记忆细胞和隐藏状态
-
输出:output(seq_len,batch,num_directions * hidden_size) ,(h_n,c_n) shape不变
话说同样是LSTM ,keras的参数怎么那么多。。。
GRU
R t = σ ( X t W x r + H t − 1 W h r + b r ) 重 置 门 Z t = σ ( X t W x z + H t − 1 W h z + b z ) 更 新 门 H ^ t = t a n h ( X t W x h + ( R t ⨀ H t − 1 ) W h h + b h ) H t = Z t ⨀ H t − 1 + ( 1 − Z t ) ⨀ H ^ t R_t = sigma(X_tW_{xr} + H_{t-1}W_{hr} +b_r) 重置门\ Z_t = sigma(X_tW_{xz} + H_{t-1}W_{hz} +b_z) 更新门\ hat{H}_t = tanh(X_tW_{xh} + (R_t bigodot H_{t-1})W_{hh} + b_h)\ H_t = Z_t bigodot H_{t-1} + (1-Z_t) bigodot hat{H}_t Rt=σ(XtWxr+Ht−1Whr+br)重置门Zt=σ(XtWxz+Ht−1Whz+bz)更新门H^t=tanh(XtWxh+(Rt⨀Ht−1)Whh+bh)Ht=Zt⨀Ht−1+(1−Zt)⨀H^t
-
更新门
更新门的作用类似于LSTM的遗忘和输入门。它决定要丢弃哪些信息和要添加哪些新信息。更新门帮助模型决定到底要将多少过去的信息传递到未来,或到底前一时间步和当前时间步的信息有多少是需要继续传递的。这一点非常强大,因为模型能决定从过去复制所有的信息以减少梯度消失的风险。 -
重置门
重置门是另一个用来决定要忘记多少过去的信息的门。 -
当前记忆内容
就是第三个式子,重置门与H_{t-1} 的乘积,重置门为一个0-1 值组成的向量,它会衡量门控开启的大小。例如某个元素对应的门控值为 0,那么它就代表这个元素的信息完全被遗忘掉,以此来确定所要保留与遗忘的以前信息。 -
当前时间步的最终记忆
最后一个式子,更新门同样以门控的形式控制了信息的流入,前部分表示前一时间步保留到最终记忆的信息,该信息加上当前记忆保留至最终记忆的信息就等于最终门控循环单元输出的内容。
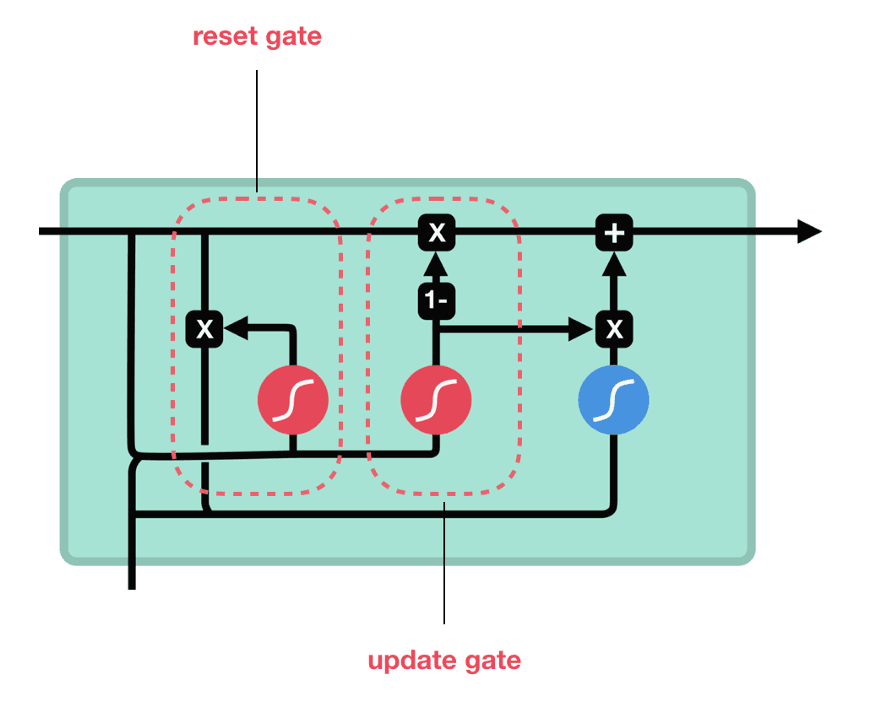
没有动图了,,,直接看代码的也挺形象的。。。
# 这个实现和 LSTM 很相似
class GRUCell(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(GRUCell, self).__init__()
self.hidden_size = hidden_size
self.gate = nn.Linear(input_size + hidden_size, hidden_size)
self.output = nn.Linear(hidden_size, output_size)
self.sigmoid = nn.Sigmoid()
self.tanh = nn.Tanh()
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden):
combined = torch.cat((input, hidden), 1)
z_gate = self.sigmoid(self.gate(combined)) # 两个门
r_gate = self.sigmoid(self.gate(combined))
combined01 = torch.cat((input, torch.mul(hidden,r_gate)), 1)
h1_state = self.tanh(self.gate(combined01)) # 一个隐含状态
h_state = torch.add(torch.mul((1-z_gate), hidden), torch.mul(h1_state, z_gate))
output = self.output(h_state)
output = self.softmax(output)
return output, h_state
def initHidden(self):
return torch.zeros(1, self.hidden_size)
grucell = GRUCell(input_size=10,hidden_size=20,output_size=10)
input=torch.randn(32,10)
h_0=torch.randn(32,20)
output,hn=grucell(input,h_0)
print(output.size(),hn.size())
>>> torch.Size([32, 10]) torch.Size([32, 20])
torch.nn.GRU(*args, **kwargs)
参数跟LSTM 差不多。。。
- 输入:input( seq_len,batch,input_size),h_0(num_layers * num_directions,batch,hidden_size)
- 输出:(seq_len,batch,num_directions * hidden_size)
rnn = nn.GRU(10, 20, 2)
input = torch.randn(5, 3, 10)
h0 = torch.randn(2, 3, 20)
output, hn = rnn(input, h0)
循环神经网络的训练方法 BPTT
参考:脑补链接
随时间反向传播,基本原理还是BP,但BP 是按照层进行反向,BPTT 是按照时间T进行反向。
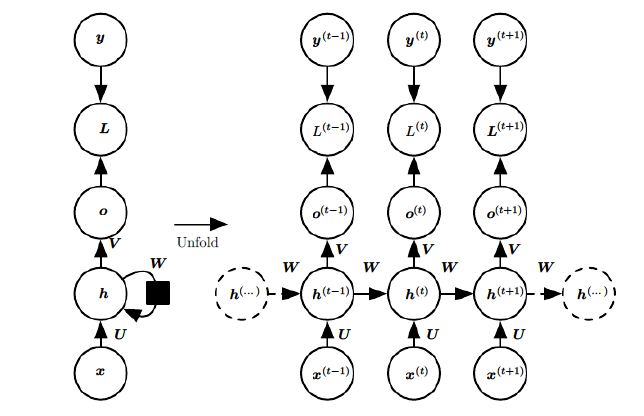
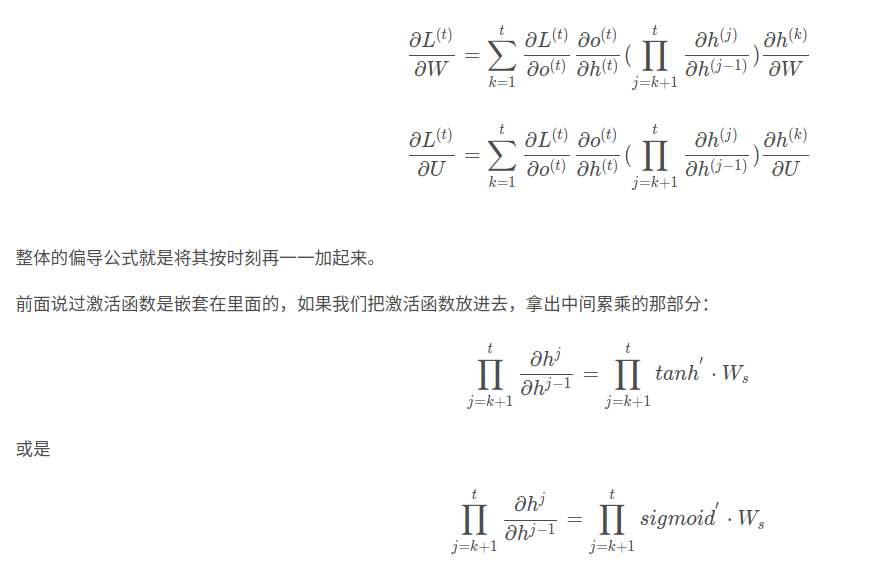
这里需要优化的参数就是 U,V,W。与BP算法不同的是,其中W和U两个参数的寻优过程需要追溯之前的历史数据,参数V相对简单只需关注目前。
我不是懒啊。。。。。

最后
以上就是伶俐帆布鞋最近收集整理的关于LSTM+GRU原理加实现LSTM+GRU的全部内容,更多相关LSTM+GRU原理加实现LSTM+GRU内容请搜索靠谱客的其他文章。








发表评论 取消回复