PyTorch-GPU加速
硬件:NVIDIA-GTX1080
软件:Windows7、python3.6.5、pytorch-gpu-0.4.1
一、基础知识
将数据和网络都推到GPU,接上.cuda()
二、代码展示
import torch
import torch.nn as nn
import torch.utils.data as Data
import torchvision
# torch.manual_seed(1)
EPOCH = 1
BATCH_SIZE = 50
LR = 0.001
DOWNLOAD_MNIST = False
train_data = torchvision.datasets.MNIST(root='./mnist/', train=True, transform=torchvision.transforms.ToTensor(), download=DOWNLOAD_MNIST,)
train_loader = Data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
test_data = torchvision.datasets.MNIST(root='./mnist/', train=False)
# !!!!!!!! Change in here !!!!!!!!! #
test_x = torch.unsqueeze(test_data.test_data, dim=1).type(torch.FloatTensor)[:2000].cuda()/255. # Tensor on GPU
test_y = test_data.test_labels[:2000].cuda()
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Sequential(nn.Conv2d(in_channels=1, out_channels=16, kernel_size=5, stride=1, padding=2,),
nn.ReLU(), nn.MaxPool2d(kernel_size=2),)
self.conv2 = nn.Sequential(nn.Conv2d(16, 32, 5, 1, 2), nn.ReLU(), nn.MaxPool2d(2),)
self.out = nn.Linear(32 * 7 * 7, 10)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1)
output = self.out(x)
return output
cnn = CNN()
# !!!!!!!! Change in here !!!!!!!!! #
cnn.cuda() # Moves all model parameters and buffers to the GPU.
optimizer = torch.optim.Adam(cnn.parameters(), lr=LR)
loss_func = nn.CrossEntropyLoss()
for epoch in range(EPOCH):
for step, (x, y) in enumerate(train_loader):
# !!!!!!!! Change in here !!!!!!!!! #
b_x = x.cuda() # Tensor on GPU
b_y = y.cuda() # Tensor on GPU
output = cnn(b_x)
loss = loss_func(output, b_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if step % 50 == 0:
test_output = cnn(test_x)
# !!!!!!!! Change in here !!!!!!!!! #
pred_y = torch.max(test_output, 1)[1].cuda().data # move the computation in GPU
accuracy = torch.sum(pred_y == test_y).type(torch.FloatTensor) / test_y.size(0)
print('Epoch: ', epoch, '| train loss: %.4f' % loss, '| test accuracy: %.2f' % accuracy)
test_output = cnn(test_x[:10])
# !!!!!!!! Change in here !!!!!!!!! #
pred_y = torch.max(test_output, 1)[1].cuda().data # move the computation in GPU
print(pred_y, 'prediction number')
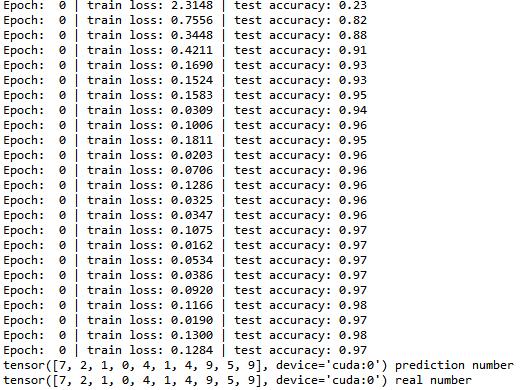
print(test_y[:10], 'real number')三、结果展示
四、参考:
https://morvanzhou.github.io/
任何问题请加唯一QQ2258205918(名称samylee)!
或唯一VX:samylee_csdn
最后
以上就是伶俐帆布鞋最近收集整理的关于PyTorch-GPU加速的全部内容,更多相关PyTorch-GPU加速内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复