PRML中文版(马春鹏)勘误表
PRML中文版(马春鹏)勘误表
前言:
PRML是严肃学习机器学习的首选教材。虽然内容略微陈旧,但是从写作水平来说,目前没有与之匹敌的其他读物。可惜我英语水平有限,原著读起来很容易疲劳,幸得网上流传的PRML中译版,整体流畅严谨,显然是译者在有相当理解的基础上翻译的。只是阅读的过程中偶有卡壳,结合英文版原著,发现有些小问题,这里都列出来,方便其他读者。根据我的阅读进度,本文会不定期更新。
位置:p11 (1.2)上面
原文:
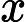
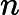 的预测值
的预测值
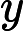
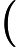
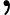
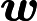
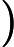 与目标值
与目标值
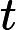 的平方和
的平方和
建议:
的预测值
与目标值
之差的平方和
位置:p21 (1.32)下面
原文:把每个实数变量除以区间的宽度△
建议:把每个实数变量划分为宽度为△的区间
位置:p23 中间
原文:袁术数据集
建议:原始数据集
位置:p23 (1.60) 式
说明:公式抄写有误,右括号位置不对。请参考原作
位置:p29倒数第二段
原文:如果验证机很小
建议:如果验证集很小
位置:p32 下半部分
原文:然后把方向变量积分出来
建议:然后把方向变量积分掉
说明:当时阅读这行没看懂,后来看原文是"integrate out"。这里意思是,二重积分中有两个变量,先将方向变量通过积分可以消去,只剩下半径,变成一重积分。
位置:p33 最后一行
原文:通过贝叶斯定理修改
建议:通过贝叶斯定理校正
说明:revised翻译为修改,不是太好理解。当然,我建议的翻译未必更好。所以看不懂的地方看看原文吧。
位置:p52 中间
原文:多项式分布
建议:多项分布
说明:Multinomial和多项式没关系,译文中出现过“多元分布”和“多项式分布”两种提法,建议统一改成“多项分布”
位置:p56 (2.24)式下方
原文:由于这个方差是一个整数
建议:由于这个方差是一个正数
位置:p61 (2.54)式
原文:公式抄写有误,
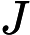
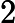 应为
。读者可参考原文
应为
。读者可参考原文
位置:p61 (2.54)式下方
原文:行列式
 的协方差矩阵可以写成特征值的乘积
的协方差矩阵可以写成特征值的乘积
建议:协方差矩阵的行列式
可以写成特征值的乘积
位置:p62 (2.60)式上方
原文:项
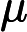
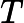 是常数,可以从积分中拿出。它本⾝等于单位矩阵,因为⾼斯分布是归⼀化的。
是常数,可以从积分中拿出。它本⾝等于单位矩阵,因为⾼斯分布是归⼀化的。
建议:项
是常数,可以从积分中拿出,此时积分为1,因为⾼斯分布是归⼀化的。
位置:p64 (2.70)式下方
原文:“完成平方项“
建议:“配平方”
原文:我们一直一个二次型
建议:我们已知一个二次型
位置:p64 (2.73)式下方
原文:现在考虑公式(2.70)中所有
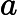 的常数项
的常数项
建议:现在考虑公式(2.70)中所有
的一阶项
位置:p70 (2.127)式下方
原文:如果我们有观测z和
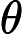 的一个大数据集
的一个大数据集
建议:如果我们有一个包含z和
观测值的大数据集。
位置:p76 (2.159)式上方
原文:
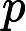
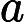
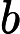
建议:
位置:p78 (2.168)式上方
原文:然后令分量
 和
相等
和
相等
建议:然后算出分量
和
位置:p78 (2.170)式上方
原文:感召惯例
建议:按照惯例
位置:p84 (2.205)式下方
原文:其中
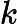

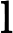
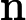
建议:其中
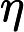
位置:p85 (2.211)式
说明:公式最后一行漏了个
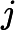 ,请参看原版。
,请参看原版。
位置:p85 (2.212)式下方
原文:回带
建议:回代
位置:p85 (2.214)式
说明:式中的

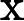
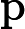 应为
应为
位置:p85 (2.217)式
说明:最右边的
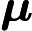
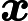 应为
应为
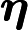
位置:p86 (2.224)上方
原文:对
取梯度
建议:对
取梯度
位置:p86 (2.224)式
说明:
应为
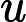
位置:p86 (2.228)式下方
原文:那么公式(2.228)的右侧变成了
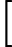
建议:那么公式(2.228)的右侧变成了
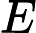
位置:p89 中间
原文:流入,如果生成数据的过程是单峰的
建议:例如,如果生成数据的过程是单峰的
位置:p91 (2.250)式下方
原文:令每个数据点都服从高斯分布
建议:将高斯函数应用到每个数据点
位置:p91 (2.251)式上方
原文:对于箱子狂赌的选择
建议:对于箱子宽度的选择
位置:p104 (3.21)式上方
原文:我们也可以关于噪声精度参数
建议:我们也可以针对噪声精度参数
位置:p107 (3.31)式下方
原文:是一个M为向量
建议:是一个M维向量
位置:p107 最后一行
原文:我们值考虑
建议:我们只考虑
位置:p113 (3.57)式下方
原文:
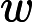
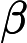
建议:
位置:p118 (3.66)式下面
原文:先验分布让我们能够表达不同模型之间的优先级
建议:先验分布让我们能够表达对不同模型之间的偏好
原文:它表达了数据展现出的不同模型的优先级
建议:它表达了数据展现出的对不同模型的偏好
位置:p121 (3.74)式上面
原文:或者被称为推广的最大似然
建议:或者被称为广义最大似然
位置:p136 (4.24)式上面
原文:一位空间
建议:一维空间
位置:p136 (4.27)式
公式抄错
位置:p138 (4.41)式
公式抄错
位置:p139 (4.54)式下方
原文:其中
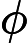 和
和
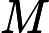 表示所有误分类模式的集合。
表示所有误分类模式的集合。
建议:其中
,且
表示所有误分类模式的集合。
位置:p147 中央
原文:另一种方法是显示地使用一般的线性模型的函数形式
建议:另一种方法是显式地使用一般的线性模型的函数形式
位置:p147 中央
原文:在直接方法中
建议:而直接方法是
说明:本段分为两部分,分别介绍直接方法和间接方法。使用这种表达会清楚一些。
位置:p168 上方
原文:这就使得误差函数在权空间的某些方向上是常数
建议:这就使得误差函数在权空间的某些方向上不变
位置:p168 上方
原文:对应的多分类交叉熵错误函数
建议:对应的多分类交叉熵误差函数
位置:p169 (5.31)式上方
原文:根据公式(5.18)
建议:根据公式(5.28)
位置:p198 (5.161)上方
原文:精度(方差的倒数)β为
建议:精度(方差的倒数)为β
最后
以上就是高大鱼最近收集整理的关于PRML中文版(马春鹏)勘误表PRML中文版(马春鹏)勘误表的全部内容,更多相关PRML中文版(马春鹏)勘误表PRML中文版(马春鹏)勘误表内容请搜索靠谱客的其他文章。








发表评论 取消回复