RNN的提出是为了解决网络无法利用历史信息的问题,但由于RNN具有梯度消失和梯度爆炸的问题,导致RNN不能存储长期记忆。
网络结构
首先来看RNN的结构,如下图1所示:
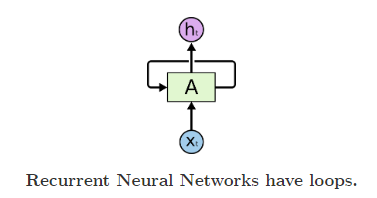
上图的结构很好理解, x t x_{t} xt为网络输入, A A A为隐藏层, h t h_{t} ht为网络输出。既然我们想利用之前的历史信息,那我们就将网络在上一时刻的输出保存下来,作为当前时刻的输入,也就是上图中的反馈连接。我们将上图中的RNN结构按时序展开,如下图2所示:
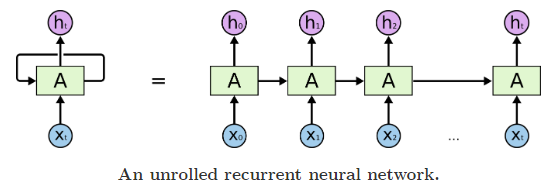
x 0 x_{0} x0~ x t x_{t} xt是网络在不同时刻的输入, h 0 h_{0} h0 ~ h t h_{t} ht是网络在不同时刻的输出,A是隐藏层。需要注意的是,上图中的RNN展开图是RNN按时序的展开图,并不是真正的拓扑结构,对于某一固定的时刻 t t t,RNN的结构就是图1;这是很多资料容易让人产生误解的地方。所以,图2中的那么多A其实是同一个隐藏层,这也就是RNN中的“参数共享”。当然,你也可以增加RNN的深度,即增加隐藏层,如下图3所示:
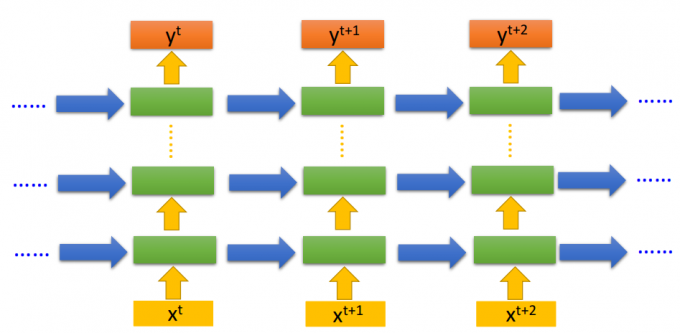
如上图所示,纵向是增加网络深度,横向是增加时间步。
工作原理
介绍了RNN的网络结构,下面来看RNN的工作过程。我们假设网络只有一个隐藏层,网络输入为 x x x,输出为 y y y,隐藏层状态为 h h h,如下图4所示,
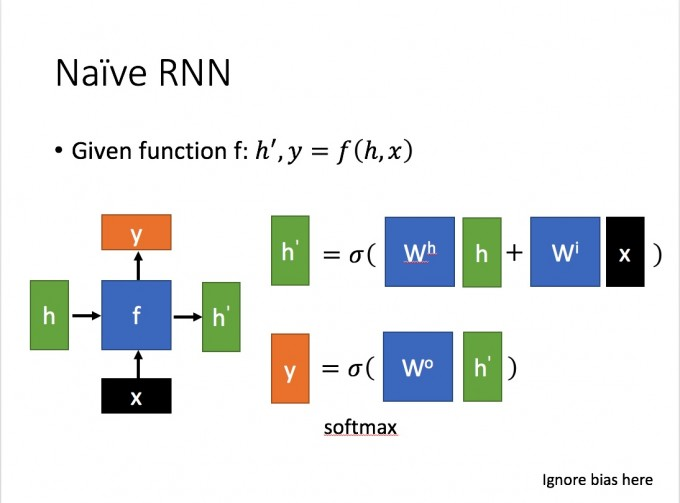
则在时刻 t t t有:
h
t
=
f
(
w
i
x
+
w
h
h
t
−
1
)
h_{t}=f(w_{i}x+w_{h}h_{t-1})
ht=f(wix+whht−1)
y
t
=
f
(
w
o
h
t
)
y_{t}=f(w_{o}h_{t})
yt=f(woht)
上式中, f f f为激活函数,一般为 s i g m o i d sigmoid sigmoid或 t a n h tanh tanh。
梯度消失与梯度爆炸
了解了RNN的工作原理,下面我们就可以去分析RNN梯度消失和梯度爆炸的原因了。为了简化问题,只考虑三个时间步,如下图5所示:
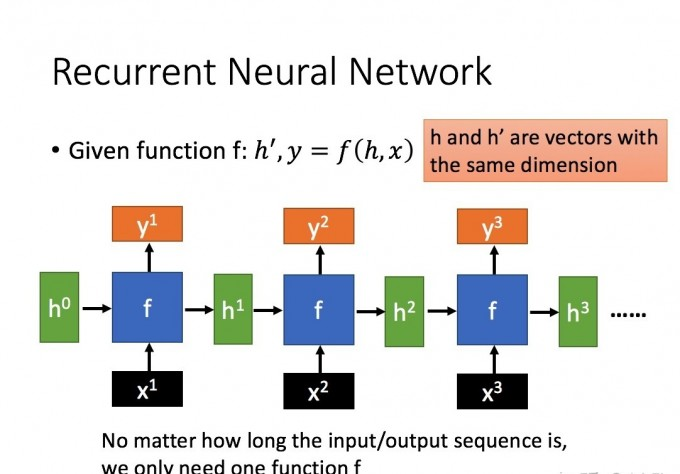
则有:
h 1 = f ( w i x 1 + w h h 0 ) , y 1 = f ( w o h 1 ) h_{1}=f(w_{i}x_{1}+w_{h}h_{0}) , y_{1}=f(w_{o}h_{1}) h1=f(wix1+whh0),y1=f(woh1)
h 2 = f ( w i x 2 + w h h 1 ) , y 2 = f ( w o h 2 ) h_{2}=f(w_{i}x_{2}+w_{h}h_{1}) , y_{2}=f(w_{o}h_{2}) h2=f(wix2+whh1),y2=f(woh2)
h 3 = f ( w i x 3 + w h h 2 ) , y 3 = f ( w o h 3 ) h_{3}=f(w_{i}x_{3}+w_{h}h_{2}) , y_{3}=f(w_{o}h_{3}) h3=f(wix3+whh2),y3=f(woh3)
RNN的损失函数为
L = ∑ t = 0 T L t = ∑ t = 0 T g ( y t ) L=sum_{t=0}^{T}L_{t}=sum_{t=0}^{T}g(y_{t}) L=t=0∑TLt=t=0∑Tg(yt),
L t L_{t} Lt为 t t t时刻输出的损失, g g g为网络的损失函数。根据链式求导法则,求L对各个参数的偏导即为参数更新的梯度。
先只考虑 L 3 L_{3} L3求偏导,有:
∂ L 3 ∂ w o = ∂ L 3 ∂ y 3 ∂ y 3 ∂ w o frac{partial L_{3}}{partial w_{o}}=frac{partial L_{3}}{partial y_{3}}frac{partial y_{3}}{partial w_{o}} ∂wo∂L3=∂y3∂L3∂wo∂y3
∂ L 3 ∂ w i = ∂ L 3 ∂ y 3 ∂ y 3 ∂ h 3 ∂ h 3 ∂ w i + ∂ L 3 ∂ y 3 ∂ y 3 ∂ h 3 ∂ h 3 ∂ h 2 ∂ h 2 ∂ w i + ∂ L 3 ∂ y 3 ∂ y 3 ∂ h 3 ∂ h 3 ∂ h 2 ∂ h 2 ∂ h 1 ∂ h 1 ∂ w i frac{partial L_{3}}{partial w_{i}}=frac{partial L_{3}}{partial y_{3}}frac{partial y_{3}}{partial h_{3}}frac{partial h_{3}}{partial w_{i}}+frac{partial L_{3}}{partial y_{3}}frac{partial y_{3}}{partial h_{3}}frac{partial h_{3}}{partial h_{2}}frac{partial h_{2}}{partial w_{i}}+frac{partial L_{3}}{partial y_{3}}frac{partial y_{3}}{partial h_{3}}frac{partial h_{3}}{partial h_{2}}frac{partial h_{2}}{partial h_{1}}frac{partial h_{1}}{partial w_{i}} ∂wi∂L3=∂y3∂L3∂h3∂y3∂wi∂h3+∂y3∂L3∂h3∂y3∂h2∂h3∂wi∂h2+∂y3∂L3∂h3∂y3∂h2∂h3∂h1∂h2∂wi∂h1
∂ L 3 ∂ w h = ∂ L 3 ∂ y 3 ∂ y 3 ∂ h 3 ∂ h 3 ∂ w h + ∂ L 3 ∂ y 3 ∂ y 3 ∂ h 3 ∂ h 3 ∂ h 2 ∂ h 2 ∂ w h + ∂ L 3 ∂ y 3 ∂ y 3 ∂ h 3 ∂ h 3 ∂ h 2 ∂ h 2 ∂ h 1 ∂ h 1 ∂ w h frac{partial L_{3}}{partial w_{h}}=frac{partial L_{3}}{partial y_{3}}frac{partial y_{3}}{partial h_{3}}frac{partial h_{3}}{partial w_{h}}+frac{partial L_{3}}{partial y_{3}}frac{partial y_{3}}{partial h_{3}}frac{partial h_{3}}{partial h_{2}}frac{partial h_{2}}{partial w_{h}}+frac{partial L_{3}}{partial y_{3}}frac{partial y_{3}}{partial h_{3}}frac{partial h_{3}}{partial h_{2}}frac{partial h_{2}}{partial h_{1}}frac{partial h_{1}}{partial w_{h}} ∂wh∂L3=∂y3∂L3∂h3∂y3∂wh∂h3+∂y3∂L3∂h3∂y3∂h2∂h3∂wh∂h2+∂y3∂L3∂h3∂y3∂h2∂h3∂h1∂h2∂wh∂h1
观察上式,由于 h t , t ∈ ( 0 , T ) h_{t},tin (0,T) ht,t∈(0,T)的存在,使得损失函数对参数求偏导的过程中存在大量的复合求导。再将上述等式推广到所有时间步,则有
∂ L ∂ w o = ∑ t = 0 T ∂ L t ∂ y t ∂ y t ∂ w o frac{partial L}{partial w_{o}}=sum_{t=0}^{T}frac{partial L_{t}}{partial y_{t}}frac{partial y_{t}}{partial w_{o}} ∂wo∂L=t=0∑T∂yt∂Lt∂wo∂yt
∂ L ∂ w i = ∑ t = 0 T ∑ j = 0 t ∂ L t ∂ y t ∂ y t ∂ h t ( ∏ k = j + 1 t ∂ h k ∂ h k − 1 ) ∂ h j ∂ w i frac{partial L}{partial w_{i}}=sum_{t=0}^{T}sum_{j=0}^{t}frac{partial L_{t}}{partial y_{t}}frac{partial y_{t}}{partial h_{t}}(prod_{k=j+1}^{t}frac{partial h_{k}}{partial h_{k-1}})frac{partial h_{j}}{partial w_{i}} ∂wi∂L=t=0∑Tj=0∑t∂yt∂Lt∂ht∂yt(k=j+1∏t∂hk−1∂hk)∂wi∂hj
∂ L ∂ w h = ∑ t = 0 T ∑ j = 0 t ∂ L t ∂ y t ∂ y t ∂ h t ( ∏ k = j + 1 t ∂ h k ∂ h k − 1 ) ∂ h j ∂ w h frac{partial L}{partial w_{h}}=sum_{t=0}^{T}sum_{j=0}^{t}frac{partial L_{t}}{partial y_{t}}frac{partial y_{t}}{partial h_{t}}(prod_{k=j+1}^{t}frac{partial h_{k}}{partial h_{k-1}})frac{partial h_{j}}{partial w_{h}} ∂wh∂L=t=0∑Tj=0∑t∂yt∂Lt∂ht∂yt(k=j+1∏t∂hk−1∂hk)∂wh∂hj
推导到这里,RNN梯度消失和梯度爆炸的原因就产生了。上述的第二个和第三个等式中出现了与时间 t t t相关的连乘的因式,根据第二节中RNN工作原理的介绍,以第二个等式为例,
∂ h k ∂ h k − 1 = f ′ ⋅ w i frac{partial h_{k}}{partial h_{k-1}}=f^{'}cdot w_{i} ∂hk−1∂hk=f′⋅wi
其中 f ′ f^{'} f′为激活函数的导数,以 s i g m o i d sigmoid sigmoid函数为例, f ∈ ( 0 , 1 ) fin(0,1) f∈(0,1)其导数为 f ′ = f ( 1 − f ) ∈ ( 0 , 1 4 ) f^{'}=f(1-f)in(0,frac{1}{4}) f′=f(1−f)∈(0,41),则 w i < 1 w_{i}<1 wi<1时, ∂ h k ∂ h k − 1 < 1 frac{partial h_{k}}{partial h_{k-1}}<1 ∂hk−1∂hk<1,经过数次相乘后, ∂ L ∂ w i frac{partial L}{partial w_{i}} ∂wi∂L逐渐接近于0,即梯度消失; w i > 4 w_{i}>4 wi>4时, ∂ h k ∂ h k − 1 > 1 frac{partial h_{k}}{partial h_{k-1}}>1 ∂hk−1∂hk>1,经过数次相乘后, ∂ L ∂ w i frac{partial L}{partial w_{i}} ∂wi∂L越来越大,即梯度爆炸。
至此,我们就从理论上分析了RNN中存在梯度消失和梯度爆炸的原因。但为了能够使用RNN利用历史信息的特性,对RNN的结构进行适当的改造就能得到性能更加优越的LSTM。LSTM的结构大大缓解了传统RNN中存在的梯度消失和梯度爆炸的问题,从而使时间步能够大大增长。具体的分析请参考下一篇文章。
最后
以上就是凶狠发带最近收集整理的关于理论推导RNN梯度消失和梯度爆炸的原因的全部内容,更多相关理论推导RNN梯度消失和梯度爆炸内容请搜索靠谱客的其他文章。








发表评论 取消回复