RNN 简介
文章目录
- RNN 简介
- 1. RNN起因
- 2. 为什么需要RNN
- 3. RNN都能做什么
- 3.1 机器翻译
- 3.2 语音识别
- 3.3 生成图像描述
- RNN的结构和原理
1. RNN起因
现实世界中,很多元素都是相互连接的,比如室外的温度是随着气候的变化而周期性的变化的、我们的语言也需要通过上下文的关系来确认所表达的含义。但是机器要做到这一步就相当得难了。因此,就有了现在的循环神经网络,他的本质是:拥有记忆的能力,并且会根据这些记忆的内容来进行推断。因此,他的输出就依赖于当前的输入和记忆。
2. 为什么需要RNN
RNN背后的想法是利用顺序的信息。 在传统的神经网络中,我们假设所有输入(和输出)彼此独立。 如果你想预测句子中的下一个单词,你就要知道它前面有哪些单词,甚至要看到后面的单词才能够给出正确的答案。
RNN之所以称为循环,就是因为它们对序列的每个元素都会执行相同的任务,所有的输出都取决于先前的计算。 从另一个角度讲RNN的它是有“记忆”的,可以捕获到目前为止计算的信息。 理论上,RNN可以在任意长的序列中使用信息,但实际上它们仅限于回顾几个步骤。 循环神经网络的提出便是基于记忆模型的想法,期望网络能够记住前面出现的特征.并依据特征推断后面的结果,而且整体的网络结构不断循环,因为得名循环神经网络。
3. RNN都能做什么
RNN在许多NLP任务中取得了巨大成功。 在这一点上,我应该提到最常用的RNN类型是LSTM,它在捕获长期依赖性方面要比RNN好得多。 以下是RNN在NLP中的一些示例: 语言建模与生成文本
3.1 机器翻译
机器翻译类似于语言建模,我们的输入源语言中的一系列单词,通过模型的计算可以输出目标语言与之对应的内容。
3.2 语音识别
给定来自声波的声学信号的输入序列,我们可以预测一系列语音片段及其概率,并把语音转化成文字
3.3 生成图像描述
与卷积神经网络一起,RNN可以生成未标记图像的描述。
RNN的结构和原理
循环神经网络的基本结构特别简单,就是将网络的输出保存在一个记忆单元中,这个记忆单元和下一次的输入一起进入神经网络中。我们可以看到网络在输入的时候会联合记忆单元一起作为输入,网络不仅输出结果,还会将结果保存到记忆单元中,下图就是一个最简单的循环神经网络在输入时的结构示意图:
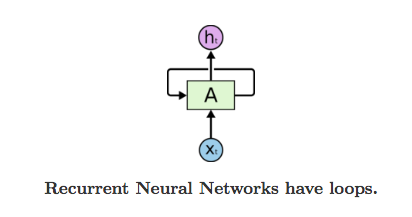
RNN 可以被看做是同一神经网络的多次赋值,每个神经网络模块会把消息传递给下一个,我们将这个图的结构展开
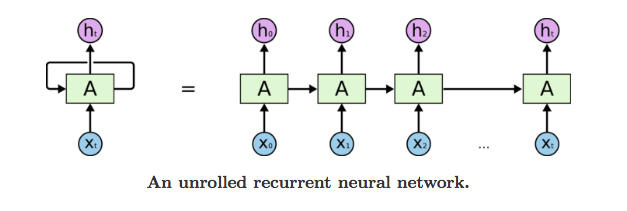
网络中具有循环结构,这也是循环神经网络名字的由来,同时根据循环神经网络的结构也可以看出它在处理序列类型的数据上具有天然的优势。因为网络本身就是 一个序列结构,这也是所有循环神经网络最本质的结构
循环神经网络具有特别好的记忆特性,能够将记忆内容应用到当前情景下,但是网络的记忆能力并没有想象的那么有效。记忆最大的问题在于它有遗忘性,我们总是更加清楚地记得最近发生的事情而遗忘很久之前发生的事情,循环神经网络同样有这样的问题。
pytorch 中使用 nn.RNN类来搭建基于序列的循环神经网络,它的构造函数有以下几个参数:
- input_size:输入数据X的特征值的数目。
- hidden_size:隐藏层的神经元数量,也就是隐藏层的特征数量。
- num_layers:循环神经网络的层数,默认值是 1。
- bias:默认为 True,如果为 false 则表示神经元不使用 bias 偏移参数。
- batch_first:如果设置为 True,则输入数据的维度中第一个维度就是 batch 值,默认为 False。默认情况下第一个维度是序列的长度, 第二个维度才是 - - batch,第三个维度是特征数目。
- dropout:如果不为空,则表示最后跟一个 dropout 层抛弃部分数据,抛弃数据的比例由该参数指定。
RNN 中最主要的参数是 input_size 和 hidden_size,这两个参数务必要搞清楚。其余的参数通常不用设置,采用默认值就可以了。
import torch
torch.__version__
'1.7.1+cpu'
rnn = torch.nn.RNN(20,50,2)
input = torch.randn(100 , 32 , 20)
h_0 =torch.randn(2 , 32 , 50)
output,hn=rnn(input ,h_0)
print(output.size(),hn.size())
torch.Size([100, 32, 50]) torch.Size([2, 32, 50])
这些都是什么东西,在实际中如何使用? 下面我们通过pytorch来手写一个RNN的实现这样,通过自己的实现就会对RNN的结构有个更深入的了解了。
在实现之前,我们继续深入介绍一下RNN的工作机制,RNN其实也是一个普通的神经网络,只不过多了一个hidden_state来保存历史信息。这个hidden_state的作用就是为了保存以前的状态,我们常说RNN中保存的记忆状态信息,就是这个 hidden_state 。
对于RNN来说,我们只要己住一个公式:
h t = tanh ( W i h x t + b i h + W h h h ( t − 1 ) + b h h ) h_t = tanh(W_{ih} x_t + b_{ih} + W_{hh} h_{(t-1)} + b_{hh}) ht=tanh(Wihxt+bih+Whhh(t−1)+bhh)
这个公式里面的 x t x_t xt是我们当前状态的输入值, h ( t − 1 ) h_{(t−1)} h(t−1)就是上面说的要传入的上一个状态的hidden_state,也就是记忆部分。 整个网络要训练的部分就是 W i h W_{ih} Wih当前状态输入值的权重, W h h W_{hh} Whhhidden_state也就是上一个状态的权重,还有这两个输入偏置值。这四个值加起来使用tanh进行激活,pytorch默认是使用tanh作为激活,也可以通过设置使用relu作为激活函数。
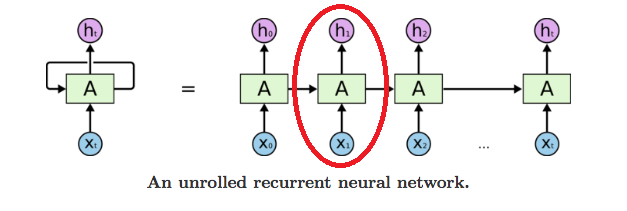
这个步骤与普通的神经网络没有任何的区别,而 RNN 因为多了 序列(sequence) 这个维度,要使用同一个模型跑 n 次前向传播,这个n就是我们序列设置的个数。 下面我们开始手动实现我们的RNN:
class RNN(object):
def __init__(self,input_size,hidden_size):
super().__init__()
self.W_xh=torch.nn.Linear(input_size,hidden_size) #因为最后的操作是相加 所以hidden要和output 的shape一致
self.W_hh=torch.nn.Linear(hidden_size,hidden_size)
def __call__(self,x,hidden):
return self.step(x,hidden)
def step(self, x, hidden):
#前向传播的一步
h1=self.W_hh(hidden)
w1=self.W_xh(x)
out = torch.tanh( h1+w1)
hidden=self.W_hh.weight
return out,hidden
rnn = RNN(20,50)
input = torch.randn( 32 , 20)
h_0 =torch.randn(32 , 50)
seq_len = input.shape[0]
for i in range(seq_len):
output,hn= rnn(input[i, :], h_0)
print(output.size(),h_0.size())
torch.Size([32, 50]) torch.Size([32, 50])
参考:循环神经网络
最后
以上就是眯眯眼灯泡最近收集整理的关于RNN(一)简介RNN 简介RNN的结构和原理的全部内容,更多相关RNN(一)简介RNN内容请搜索靠谱客的其他文章。








发表评论 取消回复