一个经典的RNN结构如下图所示:
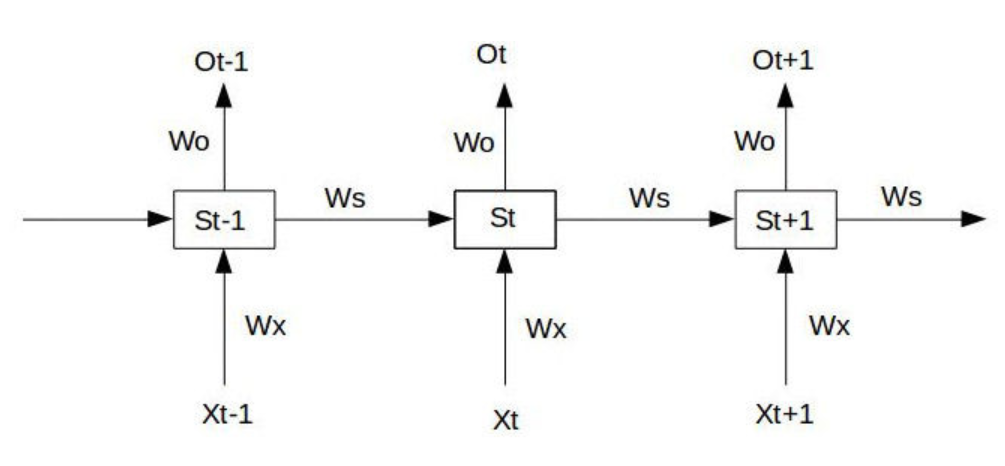 假设我们的时间序列只有三段,
S
0
S_0
S0为给定值,神经元没有激活函数,则RNN最简单的前向传播过程如下:
S
1
=
W
x
X
1
+
W
s
S
0
+
b
1
O
1
=
W
o
S
1
+
b
2
S_{1}=W_{x} X_{1}+W_{s} S_{0}+b_{1} O_{1}=W_{o} S_{1}+b_{2}
S1=WxX1+WsS0+b1O1=WoS1+b2
S
2
=
W
x
X
2
+
W
s
S
1
+
b
1
O
2
=
W
o
S
2
+
b
2
S_{2}=W_{x} X_{2}+W_{s} S_{1}+b_{1} O_{2}=W_{o} S_{2}+b_{2}
S2=WxX2+WsS1+b1O2=WoS2+b2
S
3
=
W
x
X
3
+
W
s
S
2
+
b
1
O
3
=
W
o
S
3
+
b
2
S_{3}=W_{x} X_{3}+W_{s} S_{2}+b_{1} O_{3}=W_{o} S_{3}+b_{2}
S3=WxX3+WsS2+b1O3=WoS3+b2 假设在t=3时刻,损失函数为
L
3
=
1
2
(
Y
3
−
O
3
)
2
L_{3}=frac{1}{2}left(Y_{3}-O_{3}right)^{2}
L3=21(Y3−O3)2。则对于一次训练任务的损失函数为
L
=
∑
t
=
0
T
L
t
L=sum_{t=0}^{T} L_{t}
L=t=0∑TLt即每一时刻损失值的累加。使用随机梯度下降法训练RNN其实就是对
W
x
W_x
Wx、
W
s
W_s
Ws、
W
o
W_o
Wo 以及
b
1
b_1
b1、
b
2
b_2
b2求偏导,并不断调整它们以使
L
L
L尽可能达到最小的过程。现在假设我们我们的时间序列只有三段,
t
1
t_1
t1,
t
2
t_2
t2,
t
3
t_3
t3。我们只对
t
3
t_3
t3时刻的
W
x
W_x
Wx、
W
s
W_s
Ws、
W
o
W_o
Wo 求偏导(其他时刻类似):
∂
L
3
∂
W
0
=
∂
L
3
∂
O
3
∂
O
3
∂
W
o
frac{partial L_{3}}{partial W_{0}}=frac{partial L_{3}}{partial O_{3}} frac{partial O_{3}}{partial W_{o}}
∂W0∂L3=∂O3∂L3∂Wo∂O3
∂
L
3
∂
W
x
=
∂
L
3
∂
O
3
∂
O
3
∂
S
3
∂
S
3
∂
W
x
+
∂
L
3
∂
O
3
∂
O
3
∂
S
3
∂
S
3
∂
S
2
∂
S
2
∂
W
x
+
∂
L
3
∂
O
3
∂
O
3
∂
S
3
∂
S
3
∂
S
2
∂
S
2
∂
S
1
∂
S
1
∂
W
x
frac{partial L_{3}}{partial W_{x}}=frac{partial L_{3}}{partial O_{3}} frac{partial O_{3}}{partial S_{3}} frac{partial S_{3}}{partial W_{x}}+frac{partial L_{3}}{partial O_{3}} frac{partial O_{3}}{partial S_{3}} frac{partial S_{3}}{partial S_{2}} frac{partial S_{2}}{partial W_{x}}+frac{partial L_{3}}{partial O_{3}} frac{partial O_{3}}{partial S_{3}} frac{partial S_{3}}{partial S_{2}} frac{partial S_{2}}{partial S_{1}} frac{partial S_{1}}{partial W_{x}}
∂Wx∂L3=∂O3∂L3∂S3∂O3∂Wx∂S3+∂O3∂L3∂S3∂O3∂S2∂S3∂Wx∂S2+∂O3∂L3∂S3∂O3∂S2∂S3∂S1∂S2∂Wx∂S1
∂
L
3
∂
W
s
=
∂
L
3
∂
O
3
∂
O
3
∂
S
3
∂
S
3
∂
W
s
+
∂
L
3
∂
O
3
∂
O
3
∂
S
3
∂
S
3
∂
S
2
∂
S
2
∂
W
s
+
∂
L
3
∂
O
3
∂
O
3
∂
S
3
∂
S
3
∂
S
2
∂
S
2
∂
S
1
∂
S
1
∂
W
s
frac{partial L_{3}}{partial W_{s}}=frac{partial L_{3}}{partial O_{3}} frac{partial O_{3}}{partial S_{3}} frac{partial S_{3}}{partial W_{s}}+frac{partial L_{3}}{partial O_{3}} frac{partial O_{3}}{partial S_{3}} frac{partial S_{3}}{partial S_{2}} frac{partial S_{2}}{partial W_{s}}+frac{partial L_{3}}{partial O_{3}} frac{partial O_{3}}{partial S_{3}} frac{partial S_{3}}{partial S_{2}} frac{partial S_{2}}{partial S_{1}} frac{partial S_{1}}{partial W_{s}}
∂Ws∂L3=∂O3∂L3∂S3∂O3∂Ws∂S3+∂O3∂L3∂S3∂O3∂S2∂S3∂Ws∂S2+∂O3∂L3∂S3∂O3∂S2∂S3∂S1∂S2∂Ws∂S1
假设我们的时间序列只有三段,
S
0
S_0
S0为给定值,神经元没有激活函数,则RNN最简单的前向传播过程如下:
S
1
=
W
x
X
1
+
W
s
S
0
+
b
1
O
1
=
W
o
S
1
+
b
2
S_{1}=W_{x} X_{1}+W_{s} S_{0}+b_{1} O_{1}=W_{o} S_{1}+b_{2}
S1=WxX1+WsS0+b1O1=WoS1+b2
S
2
=
W
x
X
2
+
W
s
S
1
+
b
1
O
2
=
W
o
S
2
+
b
2
S_{2}=W_{x} X_{2}+W_{s} S_{1}+b_{1} O_{2}=W_{o} S_{2}+b_{2}
S2=WxX2+WsS1+b1O2=WoS2+b2
S
3
=
W
x
X
3
+
W
s
S
2
+
b
1
O
3
=
W
o
S
3
+
b
2
S_{3}=W_{x} X_{3}+W_{s} S_{2}+b_{1} O_{3}=W_{o} S_{3}+b_{2}
S3=WxX3+WsS2+b1O3=WoS3+b2 假设在t=3时刻,损失函数为
L
3
=
1
2
(
Y
3
−
O
3
)
2
L_{3}=frac{1}{2}left(Y_{3}-O_{3}right)^{2}
L3=21(Y3−O3)2。则对于一次训练任务的损失函数为
L
=
∑
t
=
0
T
L
t
L=sum_{t=0}^{T} L_{t}
L=t=0∑TLt即每一时刻损失值的累加。使用随机梯度下降法训练RNN其实就是对
W
x
W_x
Wx、
W
s
W_s
Ws、
W
o
W_o
Wo 以及
b
1
b_1
b1、
b
2
b_2
b2求偏导,并不断调整它们以使
L
L
L尽可能达到最小的过程。现在假设我们我们的时间序列只有三段,
t
1
t_1
t1,
t
2
t_2
t2,
t
3
t_3
t3。我们只对
t
3
t_3
t3时刻的
W
x
W_x
Wx、
W
s
W_s
Ws、
W
o
W_o
Wo 求偏导(其他时刻类似):
∂
L
3
∂
W
0
=
∂
L
3
∂
O
3
∂
O
3
∂
W
o
frac{partial L_{3}}{partial W_{0}}=frac{partial L_{3}}{partial O_{3}} frac{partial O_{3}}{partial W_{o}}
∂W0∂L3=∂O3∂L3∂Wo∂O3
∂
L
3
∂
W
x
=
∂
L
3
∂
O
3
∂
O
3
∂
S
3
∂
S
3
∂
W
x
+
∂
L
3
∂
O
3
∂
O
3
∂
S
3
∂
S
3
∂
S
2
∂
S
2
∂
W
x
+
∂
L
3
∂
O
3
∂
O
3
∂
S
3
∂
S
3
∂
S
2
∂
S
2
∂
S
1
∂
S
1
∂
W
x
frac{partial L_{3}}{partial W_{x}}=frac{partial L_{3}}{partial O_{3}} frac{partial O_{3}}{partial S_{3}} frac{partial S_{3}}{partial W_{x}}+frac{partial L_{3}}{partial O_{3}} frac{partial O_{3}}{partial S_{3}} frac{partial S_{3}}{partial S_{2}} frac{partial S_{2}}{partial W_{x}}+frac{partial L_{3}}{partial O_{3}} frac{partial O_{3}}{partial S_{3}} frac{partial S_{3}}{partial S_{2}} frac{partial S_{2}}{partial S_{1}} frac{partial S_{1}}{partial W_{x}}
∂Wx∂L3=∂O3∂L3∂S3∂O3∂Wx∂S3+∂O3∂L3∂S3∂O3∂S2∂S3∂Wx∂S2+∂O3∂L3∂S3∂O3∂S2∂S3∂S1∂S2∂Wx∂S1
∂
L
3
∂
W
s
=
∂
L
3
∂
O
3
∂
O
3
∂
S
3
∂
S
3
∂
W
s
+
∂
L
3
∂
O
3
∂
O
3
∂
S
3
∂
S
3
∂
S
2
∂
S
2
∂
W
s
+
∂
L
3
∂
O
3
∂
O
3
∂
S
3
∂
S
3
∂
S
2
∂
S
2
∂
S
1
∂
S
1
∂
W
s
frac{partial L_{3}}{partial W_{s}}=frac{partial L_{3}}{partial O_{3}} frac{partial O_{3}}{partial S_{3}} frac{partial S_{3}}{partial W_{s}}+frac{partial L_{3}}{partial O_{3}} frac{partial O_{3}}{partial S_{3}} frac{partial S_{3}}{partial S_{2}} frac{partial S_{2}}{partial W_{s}}+frac{partial L_{3}}{partial O_{3}} frac{partial O_{3}}{partial S_{3}} frac{partial S_{3}}{partial S_{2}} frac{partial S_{2}}{partial S_{1}} frac{partial S_{1}}{partial W_{s}}
∂Ws∂L3=∂O3∂L3∂S3∂O3∂Ws∂S3+∂O3∂L3∂S3∂O3∂S2∂S3∂Ws∂S2+∂O3∂L3∂S3∂O3∂S2∂S3∂S1∂S2∂Ws∂S1
可以看出对于
W
o
W_o
Wo 求偏导并没有长期依赖,但是对于
W
x
W_x
Wx、
W
s
W_s
Ws求偏导,会随着时间序列产生长期依赖。因为
S
t
S_t
St 随着时间序列向前传播,而
S
t
S_t
St又是
W
x
W_x
Wx、
W
s
W_s
Ws的函数。
根据上述求偏导的过程,我们可以得出任意时刻对
W
x
W_x
Wx、
W
s
W_s
Ws求偏导的公式:
∂
L
t
∂
W
x
=
∑
k
=
0
t
∂
L
t
∂
O
t
∂
O
t
∂
S
t
(
∏
j
=
k
+
1
t
∂
S
j
∂
S
j
−
1
)
∂
S
k
∂
W
x
frac{partial L_{t}}{partial W_{x}}=sum_{k=0}^{t} frac{partial L_{t}}{partial O_{t}} frac{partial O_{t}}{partial S_{t}}left(prod_{j=k+1}^{t} frac{partial S_{j}}{partial S_{j-1}}right) frac{partial S_{k}}{partial W_{x}}
∂Wx∂Lt=k=0∑t∂Ot∂Lt∂St∂Ot⎝⎛j=k+1∏t∂Sj−1∂Sj⎠⎞∂Wx∂Sk任意时刻对
W
s
W_s
Ws 求偏导的公式同上。
如果再加上激活函数:
S
j
=
tanh
(
W
x
X
j
+
W
s
S
j
−
1
+
b
1
)
S_{j}=tanh left(W_{x} X_{j}+W_{s} S_{j-1}+b_{1}right)
Sj=tanh(WxXj+WsSj−1+b1)。其中
tanh
′
=
[
0
,
1
]
tanh ^{prime}=[0,1]
tanh′=[0,1]
f
(
z
)
=
tanh
(
z
)
f(z)=tanh (z)
f(z)=tanh(z)
f
(
z
)
′
=
1
−
(
f
(
z
)
)
2
f(z)^{prime}=1-(f(z))^{2}
f(z)′=1−(f(z))2激活函数tanh和它的导数图像如下:
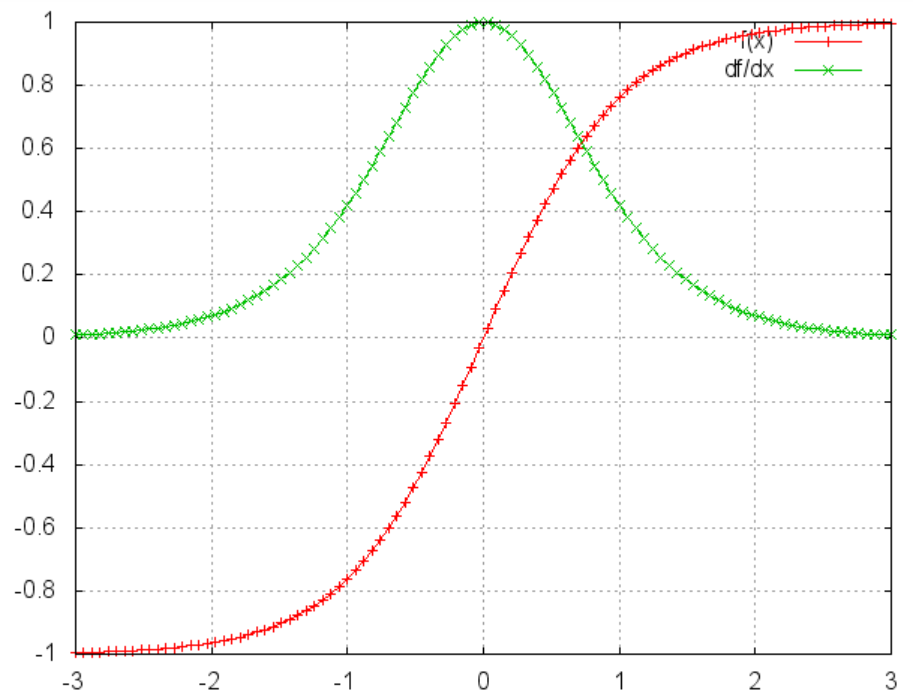 由上图可以看出
tanh
′
≤
1
tanh ^{prime} leq 1
tanh′≤1,对于训练过程大部分情况下tanh的导数是小于1的,因为很少情况下会出现
W
x
X
j
+
W
s
S
j
−
1
+
b
1
=
0
W_{x} X_{j}+W_{s} S_{j-1}+b_{1}=0
WxXj+WsSj−1+b1=0,如果
W
s
W_s
Ws也是一个大于0小于1的值,则当
t
t
t很大时
∏
j
=
k
+
1
t
tanh
′
W
s
prod_{j=k+1}^{t} tanh ^{prime} W_{s}
j=k+1∏ttanh′Ws会趋于0,和
0.0
1
50
0.01^{50}
0.0150趋近于0是一个概念,同理当
W
s
W_s
Ws很大时,
∏
j
=
k
+
1
t
tanh
′
W
s
prod_{j=k+1}^{t} tanh ^{prime} W_{s}
∏j=k+1ttanh′Ws会趋于无穷。这就是RNN中梯度消失和爆炸的原因。
由上图可以看出
tanh
′
≤
1
tanh ^{prime} leq 1
tanh′≤1,对于训练过程大部分情况下tanh的导数是小于1的,因为很少情况下会出现
W
x
X
j
+
W
s
S
j
−
1
+
b
1
=
0
W_{x} X_{j}+W_{s} S_{j-1}+b_{1}=0
WxXj+WsSj−1+b1=0,如果
W
s
W_s
Ws也是一个大于0小于1的值,则当
t
t
t很大时
∏
j
=
k
+
1
t
tanh
′
W
s
prod_{j=k+1}^{t} tanh ^{prime} W_{s}
j=k+1∏ttanh′Ws会趋于0,和
0.0
1
50
0.01^{50}
0.0150趋近于0是一个概念,同理当
W
s
W_s
Ws很大时,
∏
j
=
k
+
1
t
tanh
′
W
s
prod_{j=k+1}^{t} tanh ^{prime} W_{s}
∏j=k+1ttanh′Ws会趋于无穷。这就是RNN中梯度消失和爆炸的原因。
至于怎么避免这种现象,让我在看看就是 ∂ L t ∂ W x = ∑ k = 0 t ∂ L t ∂ O t ∂ O t ∂ S t ( ∏ j = k + 1 t ∂ S j ∂ S j − 1 ) ∂ S k ∂ W x frac{partial L_{t}}{partial W_{x}}=sum_{k=0}^{t} frac{partial L_{t}}{partial O_{t}} frac{partial O_{t}}{partial S_{t}}left(prod_{j=k+1}^{t} frac{partial S_{j}}{partial S_{j-1}}right) frac{partial S_{k}}{partial W_{x}} ∂Wx∂Lt=k=0∑t∂Ot∂Lt∂St∂Ot⎝⎛j=k+1∏t∂Sj−1∂Sj⎠⎞∂Wx∂Sk梯度消失和爆炸的根本原因就是 ∏ j = k + 1 t ∂ S j ∂ S j − 1 prod_{j=k+1}^{t} frac{partial S_{j}}{partial S_{j-1}} j=k+1∏t∂Sj−1∂Sj这一坨,要消除这种情况就需要把这一坨在求偏导的过程中去掉,至于怎么去掉,一种办法就是使 ∂ S j ∂ S j − 1 ≈ 1 或 者 ∂ S j ∂ S j − 1 ≈ 0 frac{partial S_{j}}{partial S_{j-1}} approx 1或者frac{partial S_{j}}{partial S_{j-1}} approx 0 ∂Sj−1∂Sj≈1或者∂Sj−1∂Sj≈0其实这就是LSTM做的事情。
总结:
梯度消失:一句话,RNN梯度消失是因为激活函数tanh函数的倒数在0到1之间,反向传播时更新前面时刻的参数时,当参数W初始化为小于1的数,则多个(tanh函数’ * W)相乘,将导致求得的偏导极小(小于1的数连乘),从而导致梯度消失。
梯度爆炸:当参数初始化为足够大,使得tanh函数的导数乘以W大于1,则将导致偏导极大(大于1的数连乘),从而导致梯度爆炸。
最后
以上就是甜美乐曲最近收集整理的关于RNN梯度消失和爆炸的原因的全部内容,更多相关RNN梯度消失和爆炸内容请搜索靠谱客的其他文章。








发表评论 取消回复