1. 引入
我们可以在[1]中,看到RNN的结构,如下图所示。
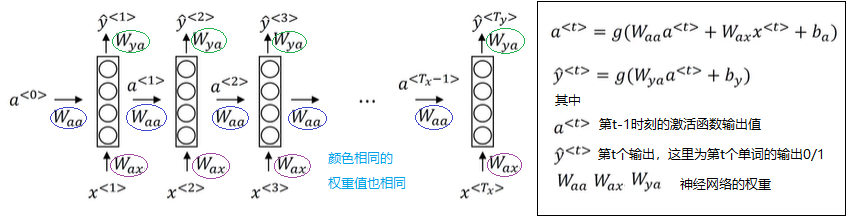
假设我们输入两个句子如下:
- The cat, which already xxx yyy zzz …, was full.
- The cats, which alrady xxx yyy zzz …, were full.
这两句话中,“xxx yyy zzz …”表示句子中间有很长的文本,此处略去。我们只看单数与复数,最后一个逗号后,也要对应was和were。我们期望RNN网络能学到这种单数复数的语法。
但是由于句子太长了,而RNN本身是不擅长捕捉这种长期依赖效应(very long-term dependencies)的。
这是为什么呢?
2. 梯度消失
在文章[3]中,我们解释过一种情况:普通的多层神经网络中,如果网络深度很深,则“激活函数将会成指数级递增”,最终导致在反向传播过程中梯度很难向前传递,也就是“梯度消失”。这就是从y输出的梯度,很难传播回去。
RNN也具有同样的问题,各个时刻激活函数的输出值a累乘到一起,传到靠后的时刻后,值已经很小了,在反向传播过程中,就很容易出现“梯度消失”。
所以,需要在序列后面生成单复数was或were,也是比较困难的,因为前面序列传过来的a,可能到后面就消失了。
正因如此,输出序列某个值,是比较容易受到附近值的影响,但不容易受到离他很远的值的影响。比如y<10>,容易被x<9>,x<8>,x<7>影响到,但不容易被x<2>影响到。
3. 梯度爆炸
除了“梯度消失”,RNN训练过程中也可能遇到“梯度爆炸”。但对RNN来说,“梯度消失”更严重。为什么呢?
因为“梯度爆炸”会导致你的网络参数大到崩溃,所以“梯度爆炸”更容易被发现。“梯度爆炸”时,你可以观测到网络参数出现数值溢出(数据过大)。
出现“梯度爆炸”时,可以用梯度修剪的方法来解决:
- 观察梯度向量,如果它大于某个阈值,就缩放梯度向量,保证它不会太大。
这种梯度修剪法,相对是比较鲁棒的方法。而梯度消失则很难解决。
4. 总结
在训练很深的神经网络时,随着层数的增加,导数可能呈指数型的下降或增加,所以我们会遇到“梯度消失”(使得你的网络无法捕获长期依赖)或“梯度爆炸”。
如果一个RNN处理10000个值的序列,这就是一个10000个层的神经网络(因为前面时刻激活函数的输出值a会不断叠加到后面时刻)。
其中,“梯度爆炸”问题用梯度修剪法基本就能解决。但“梯度消失”则很难解决(可以用GRU来解决,后面再介绍,门控循环单元网络)。
参考
- [1]. 理解RNN的结构+特点+计算公式. https://blog.csdn.net/ybdesire/article/details/103449597
- [2]. 序列模型用途介绍及数学符号. https://blog.csdn.net/ybdesire/article/details/102963683
- [3]. 深度学习中的梯度消失与梯度爆炸. https://blog.csdn.net/ybdesire/article/details/79618727
- [4]. Andrew Ng Sequence Models video
最后
以上就是标致香水最近收集整理的关于RNN中的梯度消失与梯度爆炸1. 引入2. 梯度消失3. 梯度爆炸4. 总结参考的全部内容,更多相关RNN中的梯度消失与梯度爆炸1.内容请搜索靠谱客的其他文章。








发表评论 取消回复