特别说明:要在我的随笔后写评论的小伙伴们请注意了,我的博客开启了 MathJax 数学公式支持,MathJax 使用
$标记数学公式的开始和结束。如果某条评论中出现了两个$,MathJax 会将两个$之间的内容按照数学公式进行排版,从而导致评论区格式混乱。如果大家的评论中用到了$,但是又不是为了使用数学公式,就请使用$转义一下,谢谢。
想从头阅读该系列吗?下面是传送门:
- Linux 桌面玩家指南:01. 玩转 Linux 系统的方法论 【约 1.1 万字,22 张图片】
- Linux 桌面玩家指南:02. 以最简洁的方式打造实用的 Vim 环境 【约 0.97 万字,7 张图片】
- Linux 桌面玩家指南:03. 针对 Gnome 3 的 Linux 桌面进行美化 【约 0.58 万字,32 张图片】
- Linux 桌面玩家指南:04. Linux 桌面系统字体配置要略 【约 1.2 万字,34 张图片】
- Linux 桌面玩家指南:05. 发博客必备的图片处理和视频录制神器 【约 0.25 万字,14 张图片】
前言
虽然我们玩的是 Linux 桌面系统,但是很多时候我们仍然离不开命令行。有时候,是因为某些工具只有命令行版本,要解决某些问题必须使用命令行,特别是对于我们程序猿和系统管理员来说更是这样。有时候,是因为使用命令行解决问题确实比使用图形界面更加高效。还有些时候,为了自动化、批量化运行程序,我们也不得不使用命令行。得益于 Unix 系统的传统,在命令行中使用管道和文件重定向以及 Shell 脚本语言作为粘合剂,可以将许多简单的工具组合到一起完成更加复杂的任务。总之,Linux 系统中的命令行是相当舒服和优雅的。
我这里使用的终端程序就是 Gnome 3 桌面自带的 gnome-terminal,而我使用的 Shell 就是 Bash。网上有很多人推崇 Z Shell,但是我并没有改弦易辙,而是坚持使用 Bash。我认为,Bash 的功能也是很强大的,只是我自己水平有限,不能发挥出它全部的威力而已。关于高效使用命令行这个话题,在网上已经是老生常谈了。我这里主要的参考资料是 Bash 的官方文档,使用man bash即可以阅读,当然也可以到 Bash 的官网上下载 pdf 版的文档,放到手机上有空的时候慢慢看。在本文中,也有不少我自己的观点和体会,我会提到有些快捷键要熟记,有些则完全不需要记,毕竟我们的记忆力也是有限的,我还会提到一些助记的方法。所以,本文绝对不是照本宣科,值得大家拥有,请大家一定记得点赞。
四年前,我脑子一抽,写了一篇 Bash 脚本编程语言中的美学与哲学,还非常洋洋得意。现在回看起来,觉得还是幼稚了一些。但是我觉得我写的这些也不是完全没有帮助,相比于长达 171 页的详细的 Bash 官方文档,也许我对 Bash 脚本编程语言的定位——面向字符串的编程语言——更能让大家理解记住并熟练使用命令行呢。
使用 tmux 复用控制台窗口
高效使用命令行的首要原则就是要尽量避免干扰,什么意思呢?就是说一但开启了一个控制台窗口,就尽量不要再在桌面上切换来切换去了,不要一会儿被别的窗口挡住控制台,一会儿又让别的窗口破坏了控制台的背景,最好是把控制台最大化或全屏,甚至连鼠标都不要用。但是在实际工作中,我们又经常需要同时在多个控制台窗口中进行工作,例如:在一个控制台窗口中运行录制屏幕的命令,在另外一个控制台窗口中工作;或者在一个控制台窗口中工作,在另外一个控制台窗口中阅读文档。如果既想在多个控制台窗口中工作,又不想一大堆窗口挡来挡去、换来换去的话,就可以考虑试试 tmux 了。如下图:
tmux 的功能很多,什么 Session 啊、Atach 啊、Detach 啊等功能都非常强大。但是我们暂时不用去关心这些,只把重点放在它的控制台窗口复用功能上就行了。tmux 中有 window 和 pane 的概念,tmux 可以创建多个 window,这些 window 是不会互相遮挡的,每次只显示一个 window,其它的 window 会自动隐藏,可以使用快捷键在 window 之间切换。同时,可以把一个 window 切分成多个 pane,这些 pane 同时显示在屏幕上,可以使用快捷键在 pane 之间切换。
tmux 的快捷键很多,要想全面了解 tmux 的最好办法当然是使用man tmux命令阅读 tmux 的文档。但是我们只需要记住少数几个重要的快捷键就可以了,如下表:
| 快捷键 | 功能 |
|---|---|
| Ctrl+B c | 创建一个 window |
| Ctrl+B [n][p] | 切换到下一个窗口或上一个窗口 |
| Ctrl+B & | 关闭当前窗口 |
| Ctrl+B " | 将当前 window 或 pane 切分成两个 pane,上下排列 |
| Ctrl+B % | 将当前 window 或 pane 切分成两个 pane,左右排列 |
| Ctrl+B x | 关闭当前 pane |
| Ctrl+B [↑][↓][←][→] | 在 pane 之间移动 |
| Ctrl+[↑][↓][←][→] | 调整当前 pane 的大小,一次调整一格 |
| Alt+[↑][↓][←][→] | 调整当前 pane 的大小,一次调整五格 |
tmux 的快捷键比较特殊,除了调整 pane 大小的快捷键之外,其它的都是先按 Ctrl+B,再按一个字符。先按 Ctrl+B,再按 c,就会创建一个 window,这里 c 就是 create window。先按 Ctrl+B,再按 n 或者 p,就可以在窗口之间切换,它们是 next window 和 previous window 的意思。关闭窗口是先按 Ctrl+B,再按 &,这个只能死记。先按 Ctrl+B,再按 " ,表示上下拆分窗口,可以想象成单引号和双引号在键盘上是上下铺关系。先按 Ctrl+B,再按 % 表示左右拆分窗口,大概是因为百分数都是左右书写的吧。至于在 pane 之间移动和调整 pane 大小的方向键,就不用多说了吧。
在命令行中快速移动光标
在命令行中输入命令时,经常要在命令行中移动光标。这个很简单嘛,使用左右方向键就可以了,但是有时候我们输入了很长一串命令,却突然要修改这个命令最开头的内容,如果使用向左的方向键一个字符一个字符地把光标移到命令的开头,是否太慢了呢?有时我们需要直接在命令的开头和结尾之间切换,有时又需要能够一个单词一个单词地移动光标,在命令行中,其实这都不是事儿。如下图:
这几种移动方式都是有快捷键的。其实一个字符一个字符地移动光标也有快捷键 Ctrl+B 和 Ctrl+F,但是这两个快捷键我们不需要记,有什么能比左右方向键更方便的呢?我们真正要记的是下面这几个:
| 快捷键 | 功能 |
|---|---|
| Ctrl + A | 将光标移动到命令行的开头 |
| Ctrl + E | 将光标移动到命令行的结尾 |
| Alt + B | 将光标向左移动一个单词 |
| Alt + F | 将光标向右移动一个单词 |
这几个快捷键太好记了,A 代表 ahead,E 代表 end,B 代表 back,F 代表 forward。为什么按单词移动光标的快捷键都是以 Alt 开头呢?那是因为按字符移动光标的快捷键把 Ctrl 占用了。但是按字符移动光标的快捷键我们用不到啊,因为我们有左右方向键啊。
在命令行中快速删除文本
对输入的内容进行修改也是我们经常要干的事情,对命令行进行修改就涉及到先删除一部分内容,再输入新内容。我们碰到的情况是有时候只需要修改个别字符,有时候需要修改个别单词,而有时候,输入了半天的很长的一段命令,我们说不要就全都不要了,要整行删除。常用的删除键当然是 BackSpace 和 Delete 啦,不过一次删除一个字符,还是太慢了些。要在命令行中快速删除文本,请熟记以下几个快捷键吧:
| 快捷键 | 功能 |
|---|---|
| Ctrl + U | 删除从光标到行首的所有内容,如果光标在行尾,自然就整行都删除了啊 |
| Ctrl + K | 删除从光标到行尾的所有内容,如果光标在行首,自然也是整行都删除了啊 |
| Ctrl + W | 删除光标前的一个单词 |
| Alt + D | 删除光标后的一个单词 |
| Ctrl + Y | 将刚删除的内容粘贴到光标处,有时候删错了可以用这个快捷键恢复删除的内容 |
效果请看下图:
这几个快捷键也是蛮好记的,U 代表 undo,K 代表 kill,W 代表 word,D 代表 delete, Y 代表 yank。其中比较奇怪的是 Alt+D 又是以 Alt 开头的,那是因为 Ctrl+D 又被占用了。Ctrl+D 有两个意思,一是在编辑命令行的时候它代表删除一个字符,当然,这个快捷键其实我们用不到,因为 BackSpace 和 Delete 方便多了;二是在某些程序从 stdin 读取数据的时候,Ctrl+D 代表 EOF,这个我们偶尔会用到。
快速查看和搜索历史命令
对于曾经运行过的命令,除非特别短,我们一般不会重复输入,从历史记录中找出来用自然要快得多。我们用得最多的就是 ↑ 和 ↓,特别是不久前才刚刚输入过的命令,使用 ↑ 向上翻几行就找到了,按一下 Enter 就执行,多舒服。但是有时候,明明记得是不久前才用过的命令,但是向上翻了半天也没找到,怎么办?那只好使用history命令来查看所有的历史记录了。历史记录又特别长,怎么办?可以使用 history | less和history | grep '...'。除此之外,还有终极大杀招,那就是按 Ctrl+R 从历史记录中进行搜索。按了 Ctrl+R 之后,每输入一个字符,都会和历史记录中进行增量匹配,输入得越多,匹配越精确。当然,有时候含有相同搜索字符串的命令特别多,怎么办?继续按 Ctrl+R,就会继续搜索下一条匹配的历史记录。如下图:
这里,需要记住的命令和快捷键如下表:
| 命令或快捷键 | 功能 |
|---|---|
| history | 查看历史记录 |
| history | less | 分页查看历史记录 |
| history | grep '...' | 在历史记录中搜索匹配的命令,并显示 |
| Ctrl + R | 逆向搜索历史记录,和输入的字符进行增量匹配 |
| Esc | 停止搜索历史记录,并将当前匹配的结果放到当前输入的命令行上 |
| Enter | 停止搜索历史记录,并将当前匹配的结果立即执行 |
| Ctrl + G | 停止搜索历史记录,并放弃当前匹配的结果 |
| Alt + > | 将历史记录中的位置标记移动到历史记录的尾部 |
这里需要注意的是,当我们在历史记录中搜索的时候,是有位置标记的,Ctrl+R 是指从当前位置开始,逆向搜索,R 代表的是 reverse,每搜索一条记录,位置标记都会向历史记录的头部移动,下次搜索又从这里开始继续向头部搜索。所以,我们一定要记住快捷键 Alt+>,它可以把历史记录的位置标记还原。另外需要注意的是停止搜索历史记录的快捷键有三个,如果按 Enter 键,匹配的命令就立即执行了,如果你还想有修改这条命令的机会的话,一定不要按 Enter,而要按 Esc。如果什么都不想要,就按 Ctrl+G,它会还你一个空白的命令行。
快速引用和修饰历史命令
除了查看和搜索历史记录,我们还可以以更灵活的方式引用历史记录中的命令。常见的简单的例子有!!代表引用上一条命令,!$代表引用上一条命令的最后一个参数,^oldstring^newstring^代表将上一条命令中的 oldstring 替换成 newstring。这些操作是我们平时使用命令行的时候的一些常用技巧,其实它们的本质,是由 history 库提供的 history expansion 功能。Bash 使用了 history 库,所以也能使用这些功能。其完整的文档可以查看man history手册页。知道了 history expansion 的理论,我们还可以做一些更加复杂的操作,如下图:
引用和修饰历史命令的完整格式是这样的:
![!|[?]string|[-]number]:[n|x-y|^|$|*|n*|%]:[h|t|r|e|p|s|g]可以看到,一个对历史命令的引用被 : 分为了三个部分,第一个部分决定了引用哪一条历史命令;第二部分决定了选取该历史命令中的第几个单词,单词是从0开始编号的,也就是说第0个单词代表命令本身,第1个到最后一个单词代表命令的参数;第三部分决定了对选取的单词如何修饰。下面我列出完整表格:
表格一、引用哪一条历史命令:
| 操作符 | 功能 |
|---|---|
| ! | 所有对历史命令的引用都以 ! 开始,除了 ^oldstring^newstring^ 形式的快速替换 |
| !n | 引用第 n 条历史命令 |
| !-n | 引用倒数第 n 条历史命令 |
| !! | 引用上一条命令,等于 !-1 |
| !string | 逆向搜索历史记录,第一条以 string 开头的命令 |
| !?string[?] | 逆向搜索历史记录,第一条包含 string 的命令 |
| ^oldstring^newstring^ | 对上一条命令进行快速替换,将 oldstring 替换为 newstring |
| !# | 引用当前输入的命令 |
表格二、选取哪一个单词:
| 操作符 | 功能 |
|---|---|
| 0 | 第0个单词,在 shell 中就是命令本身 |
| n | 第n个单词 |
| ^ | 第1个单词,使用 ^ 时可以省略前面的冒号 |
| $ | 最后一个单词,使用 $ 时可以省略前面的冒号 |
| % | 和 ?string? 匹配的单词,可以省略前面的冒号 |
| x-y | 从第 x 个单词到第 y 个单词,-y 代表 0-y |
| * | 除第 0 个单词外的所有单词,等于 1-$ |
| x* | 从第 x 个单词到最后一个单词,等于 x-$,可以省略前面的冒号 |
| x- | 从第 x 个单词到倒数第二个单词 |
表格三、对选取的单词做什么修饰:
| 操作符 | 功能 |
|---|---|
| h | 选取路径开头,不要文件名 |
| t | 选取路径结尾,只要文件名 |
| r | 选取文件名,不要扩展名 |
| e | 选取扩展名,不要文件名 |
| s/oldstring/newstring/ | 将 oldstring 替换为 newstring |
| g | 全局替换,和 s 配合使用 |
| p | 只打印修饰后的命令,不执行 |
这几个命令其实挺好记的,h 代表 head,只要路径开头不要文件名,t 代表 tail,只要路径结尾的文件名,r 代表 realname,只要文件名不要扩展名,e 代表 extension,只要扩展名不要文件名,s 代表 substitute,执行替换功能,g 代表 global,全局替换,p 代表 print,只打印不执行。有时候光使用 :p 还不够,我们还可以把这个经过引用修饰后的命令直接在当前命令行上展开而不立即执行,它的快捷键是:
| 操作符 | 功能 |
|---|---|
| Ctrl + Alt + E | 在当前命令行上展开历史命令引用,展开后不立即执行,可以修改,按 Enter 后才会执行 |
| Alt + ^ | 和上面的功能一样 |
这两个快捷键,记住一个就行。这样,当我们对历史命令的引用修饰完成后,可以先展开来看一看,如果正确再执行。眼见为实嘛,反正我是每次都展开看看才放心。
使用 Tab 键进行补全
在使用命令行的时候,可以使用 Tab 键对命令和文件名进行补全。一般如果你输入一条命令的前面几个字符后,按 Tab 键两次,将会提示所有可用的命令。输入命令后,在输入参数的位置,如果输入了一个文件名的前几个字符,按 Tab 键,Shell 会查找当前目录下的文件,对文件名进行补全。或者在输入参数的位置直接按两次 Tab 键,将提示所有可用的文件名。效果如下:
快速切换当前目录
在使用命令行时,可以使用cd命令切换当前目录,但是,如果每次都输入一个超长的目录名,则会严重影响效率,特别是在多个目录之间快速切换的时候。例如,在我前面几篇中,经常需要进入/usr/share/backgrounds/contest目录和/etc/fonts/conf.d目录查看配置文件,也会进入/usr/src/linux-source-4.15.0目录查看内核源代码,这些目录名都比较长,如果每次都自己输入,效率低不说,还容易出错。这时,可以通过 Bash 提供的pushd命令和popd命令维护一个目录堆栈,并使用dirs命令查看目录堆栈,使用pushd命令在目录之间切换。效果如下图:
这三个命令的具体参数如下:
1、dirs——显示当前目录栈中的所有记录(不带参数的dirs命令显示当前目录栈中的记录)
格式:dirs
[-clpv]
[+n]
[-n]
选项
-c
删除目录栈中的所有记录
-l
以完整格式显示
-p
一个目录一行的方式显示
-v
每行一个目录来显示目录栈的内容,每个目录前加上的编号
+N
显示从左到右的第n个目录,数字从0开始
-N
显示从右到左的第n个日录,数字从0开始2、pushd——pushd命令常用于将目录加入到栈中,加入记录到目录栈顶部,并切换到该目录;若pushd命令不加任何参数,则会将位于记录栈最上面的2个目录对换位置
格式:pushd
[目录 | -N | +N]
[-n]
选项
目录
将该目录加入到栈顶,并执行"cd 目录",切换到该目录
+N
将第N个目录移至栈顶(从左边数起,数字从0开始)
-N
将第N个目录移至栈顶(从右边数起,数字从0开始)
-n
将目录入栈时,不切换目录3、popd——popd用于删除目录栈中的记录;如果popd命令不加任何参数,则会先删除目录栈最上面的记录,然后切换到删除过后的目录栈中的最上面的目录
格式:popd
[-N | +N]
[-n]
选项
+N
将第N个目录删除(从左边数起,数字从0开始)
-N
将第N个目录删除(从右边数起,数字从0开始)
-n
将目录出栈时,不切换目录Bash 脚本编程语言的本质:一切都是字符串
下面,我将探讨 Bash 脚本语言中的美学与哲学。 这不是一篇 Bash 脚本编程的教程,但是却能让人更加深入地了解 Bash 脚本编程,更加快速地学习 Bash 脚本编程。 阅读以下内容,不需要你有 Bash 编程的经验,但一定要和我一样热衷于探索各种编程语言的本质,感悟它们的魅力。
我们平时喜欢对编程语言进行分类,把编程语言分为面向过程的编程语言、面向对象的编程语言、函数式编程语言等等。在我心中,我认为 Bash 就是一个面向字符串的编程语言。Bash 脚本语言的本质:一切皆是字符串。 Bash 脚本语言的一切哲学都围绕着字符串:它们从哪里来?到哪里去?使命是什么? Bash 脚本语言的一切美学都源自字符串: 由键盘上几乎所有的符号 “$ ~ ! # & ( ) [ ] { } | > < - . , ; * @ ' " ` ^” 排列组合而成的极富视觉冲击力的、功能极其复杂的字符串。
Bash 是一个 Shell,Shell 出现的初衷是为了将系统中的各种工具粘合在一起,所以它最根本的功能是调用各种命令。而命令以及命令的参数都是由字符串组成的,所以 Bash 脚本语言最终进化成一个面向字符串的语言。 Bash 语言的本质就是:一切都是字符串。 看看下图中的这些变量: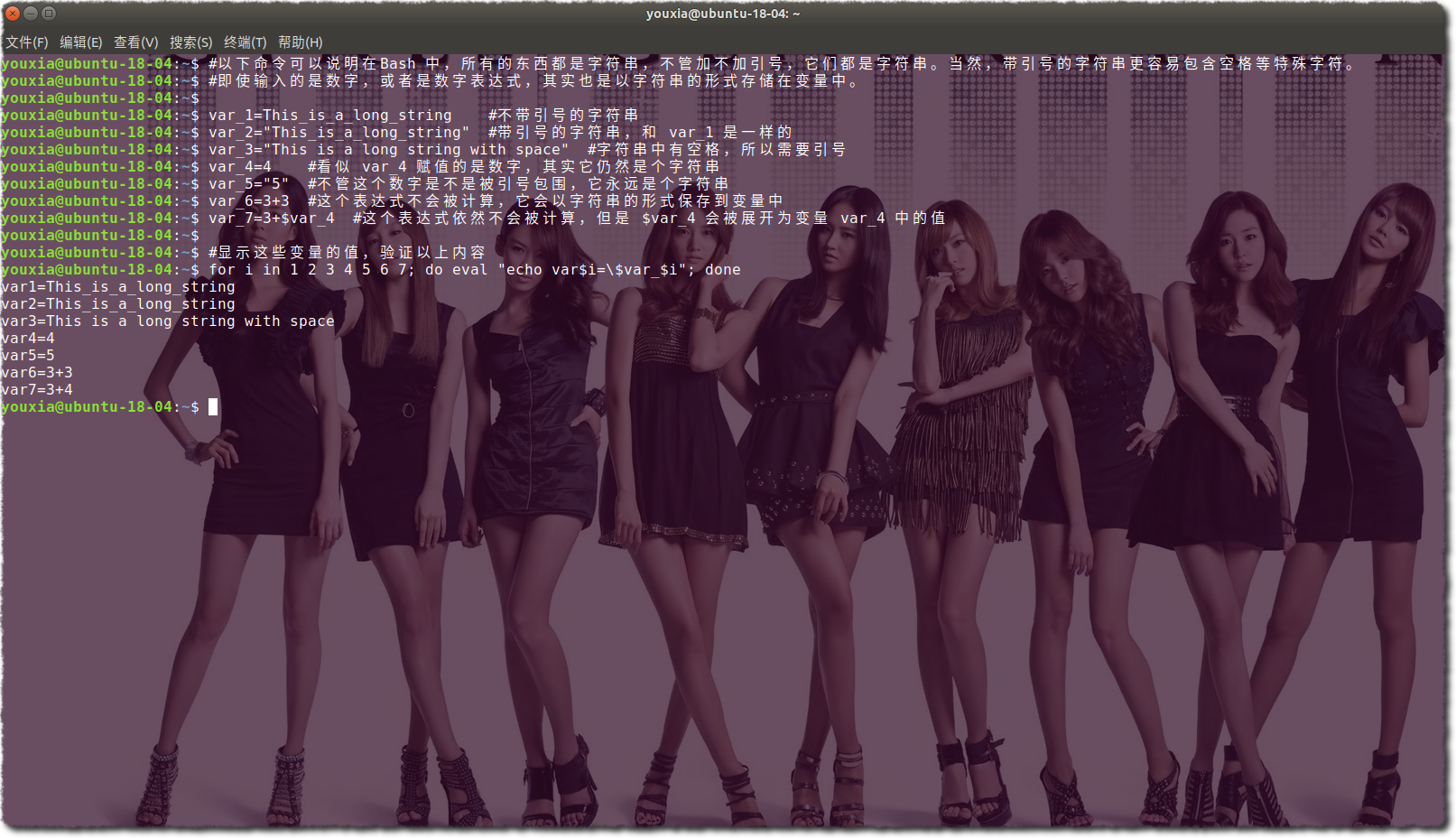
上图是我在交互式的 Bash 命令行中做的一些演示。在上图中,我对变量分别赋值,不管等号右边是一个不带引号的字符串,还是带有引号的字符串,甚至数字,或者数学表达式,最终的结果,变量里面存储的都是字符串。我使用一个 for 循环显示所有的变量,可以看到数学表达式也只是以字符串的形式储存,没有被求值。
Bash 脚本编程语言中的引号、元字符和反斜杠
如果一切都是没有特殊功能的平凡的字符串,那就无法构成一门编程语言。在 Bash 中,有很多符号具有特殊含义,如$符号被用于字符串展开,&符号用于让命令在后台执行, |用作管道,> <用于输入输出重定向等等。所以在 Bash 中,虽然同样是字符串,但是被引号包围的字符串和不被引号包围的字符串使用起来是不一样的,被单引号包围的字符串和被双引号包围起来的字符串也是不一样的。
究竟带引号的字符串和不带引号的字符串使用起来有什么不一样呢?下图是我构建的一些比较典型的例子: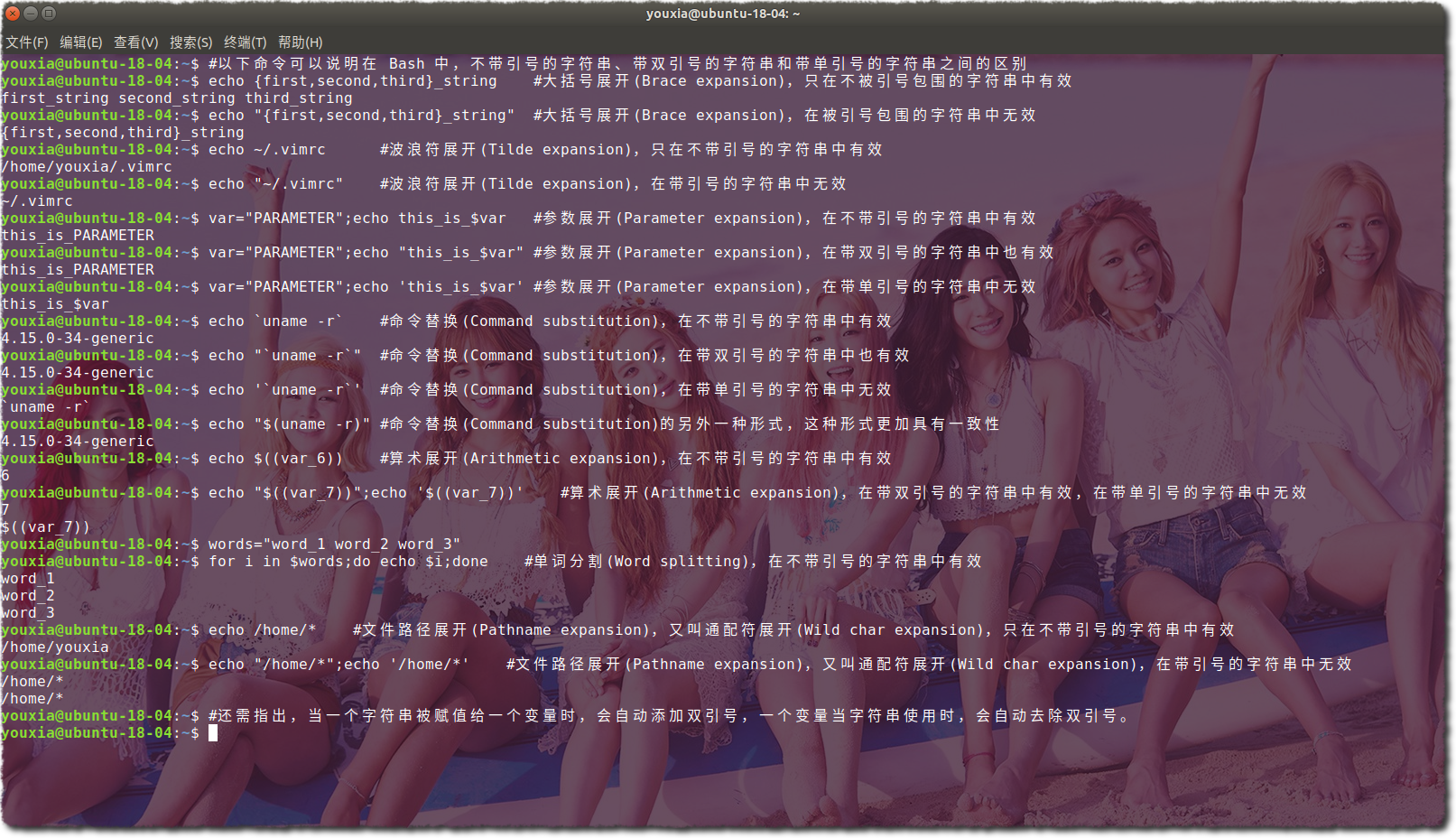
在上图中,我展示了 Bash 中生成字符串的 7 种方法:大括号展开、波浪符展开、参数展开、命令替换、算术展开、单词分割和文件路径展开。还有历史命令展开没有在上图展示,但是历史命令展开在前面快速引用和修饰历史命名那一节有展示,可以看到历史命令展开都是使用!开头的。在使用 Bash 脚本编程的时候,了解以上 7 种字符串生成的方式就够了。在交互式使用 Bash 命令行的时候,才需要了解历史命令展开,熟练使用历史命令展开可以让人事半功倍。
在上面的图片中可以看到,有一些展开方式在被双引号包围的字符串中是不起作用的,如大括号展开、波浪符展开、单词分割、文件路径展开,而只有参数展开、命令替换和算术展开是起作用的。从图片中还可以看出,字符串中的参数展开、命令替换和算术展开都是由$符号引导,命令替换还可以由` 引导。所以,可以进一步总结为,在双引号包围的字符串中,只有$ `这三个字符具有特殊含义。
如果想让任何一个字符都不具有特殊含义,可以使用单引号将字符串包围,例如使用正则表达式的时候。还有就是在使用 sed、awk 等工具的时候,由于 sed 和 awk 自己执行的命令中往往包含有很多特殊字符,所以它们的命令最好用单引号包围。 例如使用 awk 命令显示/etc/passwd文件中的每个用户的用户名和全名,可以使用这个命令awk -e '{print $1,$5}',其中,传递给 awk 的命令用单引号包围,说明 bash 不执行其中的任何替换或展开。
另外一个特殊的字符是,它也是引用的一种。它可以解除紧跟在它后面的一个特殊字符的特殊含义(引用)。之所以需要的存在,是因为在 Bash 中,有些字符称为元字符,这些字符一旦出现,就会将一个字符串分割为多个子串。如果需要在一个字符串中包含这些元字符本身,就必须对它们进行引用。如下图:
最常见的元字符就是空格。 从上面几张图片可以看出,如果要将一个含有空格的字符串赋值给一个变量,要么把这个字符串用双引号包围,要么使用对空格进行引用。 从上图中可以看出,Bash 中只有9个元字符,它们分别是| & ( ) ; < > space tab,而在其它编程语言中经常出现的元字符. { } [ ]以及作为数学运算的加减乘除,在 Bash 中都不是元字符。
字符串从哪里来,到哪里去
介绍完字符串、介绍完引用和元字符,下一个目标就是来探讨这一个哲学问题:字符串从哪里来、到哪里去?通过该哲学问题的探讨,可以推导出 Bash 脚本语言的整个语法。字符串从哪里来?很显然,其中一个很直接的来源就是我们从键盘上敲上去的。除此之外,就是我前面提到的七八九种字符串展开的方法了。
字符串展开的流程如下:
1.先用元字符将一个字符串分割为多个子串;
2.如果字符串是用来给变量赋值,则不管它是否被双引号包围,都认为它被双引号包围;
3.如果字符串不被单引号和双引号包围,则进行大括号展开,即将 {a,b}c 展开为 ab ac;
以上三个流程可以通过下图证明: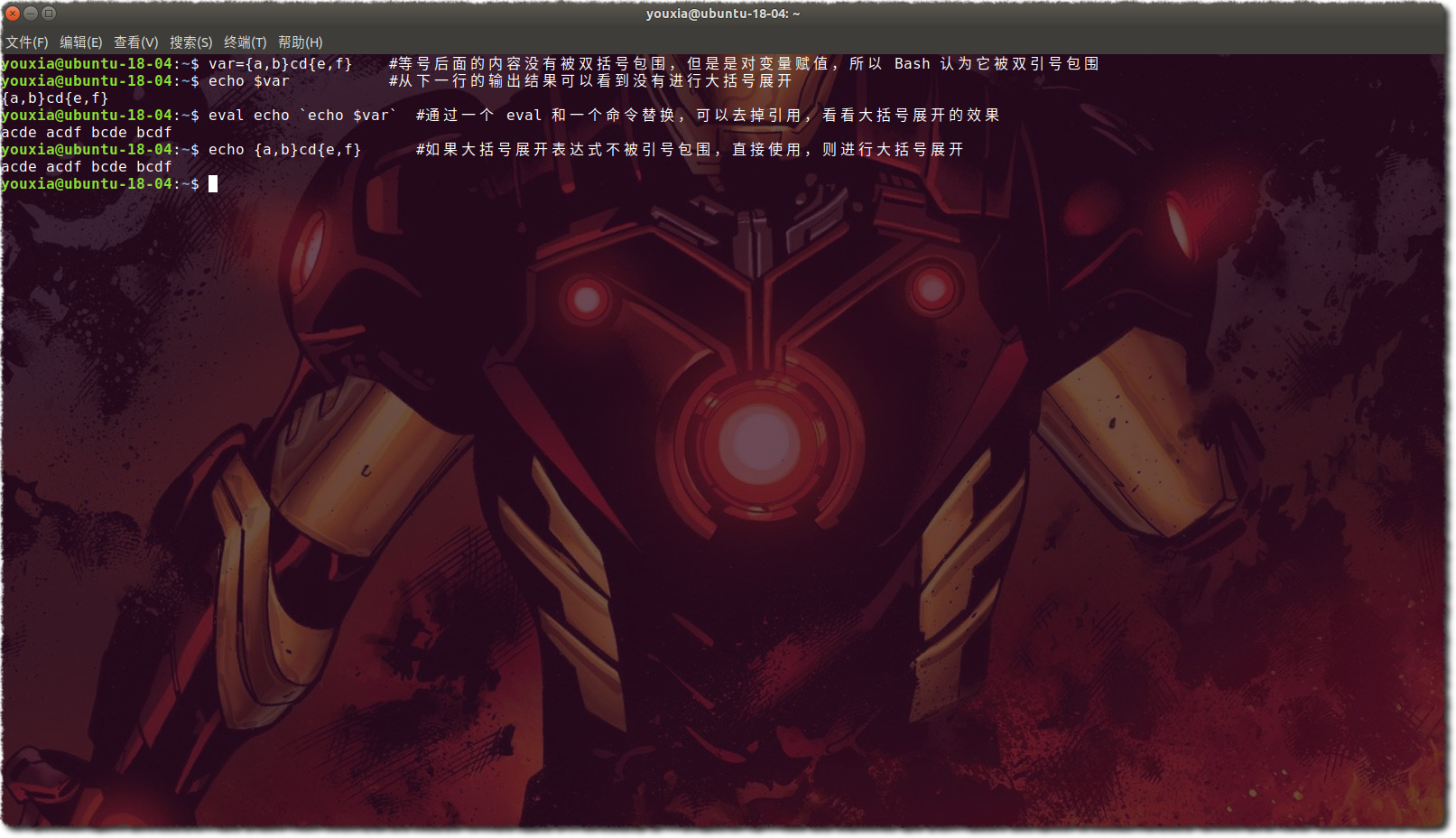
4.如果字符串不被单引号或双引号包围,则进行波浪符展开,即将 ~/ 展开为用户的主目录,将 ~+/ 展开为当前工作目录(PWD),将 ~-/ 展开为上一个工作目录(OLDPWD);
5.如果字符串不被单引号包围,则进行参数和变量展开;这一类的展开全都以$开头,这是整个 Bash 字符串展开中最复杂的,其中包括用户定义的变量,包括所有的环境变量,以上两种展开方式都是$后跟变量名,还包括位置变量$1 $2 ... $9,其它特殊变量:$@ $* $# $- $! $0 $? $_,甚至还有数组:${var[i]}, 还可以在展开的过程中对字符串进行各种复杂的操作,如:${parameter:-word} ${parameter:=word} ${parameter:+word} ${parameter:?word} ${parameter:offset} ${parameter:offset:length} ${!prefix*} ${!prefix@} ${name[@]} ${!name[*]} ${#parameter} ${parameter#word} ${parameter##word} ${parameter%word} ${parameter%%word} ${parameter/pattern/string} ${parameter^pattern} ${parameter^^pattern} ${parameter,pattern} ${parameter,,pattern};
6.如果字符串不被单引号包围,则进行命令替换;命令替换有两种格式,一种是 $(...),一种是 `...`;也就是将命令的输出作为字符串的内容;
7.如果字符串不被单引号包围,则进行算术展开;算术展开的格式为 $((...));
8.如果字符串不被单引号或双引号包围,则进行单词分割;
9.如果字符串不被单引号或双引号包围,则进行文件路径展开;
10.以上流程全部完成后,最后去掉字符串外面的引号(如果有的话)。以上流程只按以上顺序进行一遍。不会在变量展开后再进行大括号展开,更不会在第 10 步去除引用后执行前面的任何一步。如果需要将流程再走一遍,请使用 eval。
探讨完了字符串从哪里来,下面来看看字符串到哪里去。也就是怎么使用这些字符串。使用字符串有以下几种方式:
1.把它当命令执行;这是 Bash 中的最根本的用法,毕竟 Shell 的存在就是为了粘合各种命令。如果一个字符串出现在本该命令出现的地方(一行的开头,或者关键字 then、do 等的后面),它将会被当成命令执行,如果它不是个合法的命令,就会报错;
2.把它当成表达式;Bash 中本没有表达式,但是有了 ((...)) 和 [[...]],就有了表达式;((...)) 可以把它里面的字符串当成算术表达式,而 [[...]] 会把它里面的字符串当逻辑表达式,仅此两个特例;
3.给变量赋值;这也是一个特例,有点破坏 Bash 编程语言语法哲学的完整性。为什么这么说呢?因为=即不是一个元字符,也不允许两边有空格,而且只有第 1 个等号会被当成赋值运算符。
下面图片为以上观点给出证据: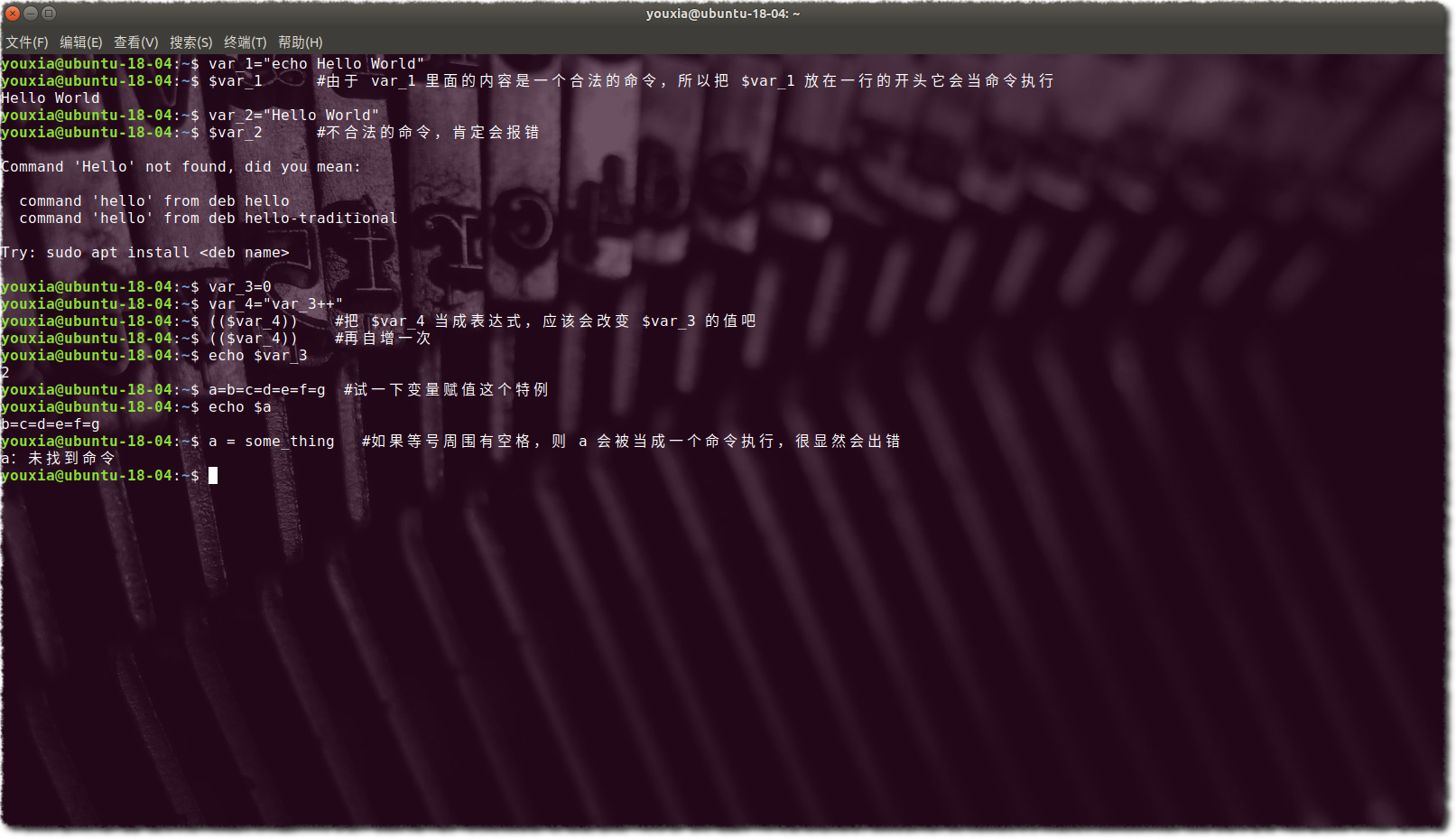
再加上一点点的定义,就可以推导出整个 Bash 脚本编程语言的语法了
前面我已经展示了我对字符串从哪里来、到哪里去这个问题的理解。关于字符串的去向,除了两个表达式和一个为变量赋值这三个特例,剩下的就只有当命令来执行了。在前面,我提到了元字符和引用的概念,这里,还得再增加一点点定义:
定义1:控制操作符(Control Operator) 前面提到元字符是为了把一个字符串分割为多个子串,而控制操作符就是为了把一系列的字符串分割成多个命令。举例说明,在 Bash中,一个字符串 cat /etc/passwd 就是一个命令,第一个单词 cat 是命令,第 2 个单词 /etc/passwd 是命令的参数,而字符串 cat /etc/passwd | grep youxia 就是两个命令,这两个命令分别是 cat 和 grep,它们之间通过|分割,所以这里的|是控制操作符。熟悉 Shell 的朋友肯定知道|代表的是管道,所以它的作用是:1.把一个字符串分割为两个命令,2.将第一个命令的输出作为第二个命令的输入。在 Bash 中,总共只有 10 个控制操作符,它们分别是|| & && | ; ;; () |& <newline>。只要看到这些控制操作符,就可以认为它前面的字符串是一个完整的命令。
定义2:关键字(Reserved Words) 我没有将其翻译成保留字,很显然,作为编程语言来说,它们应该叫做关键字。一门编程语言肯定必须得提供选择、循环等流程控制语句,还得提供定义函数的功能。这些功能只能通过关键字实现。在 Bash 中,只有 22 个关键字,它们是“! case coproc do done elif else esac fi for function if in select then until while { } time [[ ]]”。这其中有不少的特别之处,比如“! { } [[ ]]”等符号都是关键字,也就是说它们当关键字使用时相当于一个单词,也就是说它们和别的单词必须以元字符分开(否则无法成为独立的单词)。这也是为什么在 Bash 中使用“! { } [[ ]]”时经常要在它们周围留空格的原因。(再一次证明=是一个很变态的特例,因为它既不是元字符,也不是控制操作符,更加不是关键字,它到底是什么?)
下面开始推导 Bash 脚本语言的语法:
推导1:简单命令(Simple command) 就是一条简单的命令,它可以是一个以上述控制操作符结尾的字符串。比如单独放在一行的 uname -r 命令(单独放在一行的命令其实是以<newline>结尾,<newline>是控制操作符),或者虽然不单独放在一行,但是以;或&结尾,比如 uname -r; who; pwd; gvim& 其中每一个命令都是一个简单命令(当然,这四个命令放在一起的这行代码不叫简单命令),;就是简单地分割命令,而&还有让命令在后台执行的功能。这里比较特殊的是双分号;;,它只用在 case 语句中。
推导2:管道(Pipe Line) 管道是 Shell 中的精髓,就是让前一个命令的输出成为后一个命令的输入。管道的完整语法是这样 [time [-p]] [ ! ] command1 | command2 或这样 [time [-p]] [ ! ] command1 |& command2 的。其中 time 关键字和 ! 关键字都是可选的(使用[...]指出哪些部分是可选的),time 关键字可以计算命令运行的时间,而 ! 关键字是将命令的返回状态取反。看清楚 ! 关键字周围的空格哦。如果使用|,就是把第一个命令的标准输出作为第二个命令的标准输入,如果使用|&,则将第一个命令的标准输出和标准错误输出都当成第二个命令的输入。
推导3:命令序列(List) 如果多个简单命令或多个管道放在一起,它们之间以; & <newline> || &&等控制操作符分开,就称之为一个命令序列。关于||和&&,熟悉 C、C++、Java 等编程语言的朋友们肯定也不会陌生,它们遵循同样的短路求值的思想。比如 command1 || command2 只有当 command1 执行不成功的时候才执行 command2,而 command1 && command2 只有当 command1 执行成功的时候才执行 command2。
推导4:复合命令(Compound Commands) 如果将前面的简单命令、管道或者命令序列以更复杂的方式组合在一起,就可以构成复合命令。在 Bash 中,有 4 种形式的复合命令,它们分别是 (list) 、 { list; } 、 ((expression)) 、 [[ expression ]] 。请注意第 2 种形式和第 4 种形式大括号和中括号周围的空格,也请注意第 2 种形式中 list 后面的;,不过如果}另起一行,则不需要;,因为<newline>和;是起同样作用的。在以上4种复合命令中, (list) 是在一个新的Shell中执行命令序列,这些命令的执行不会影响当前Shell的环境变量,而 { list; } 只是简单地将命令序列分组。后面两种表达式求值前面已经讲过,这里就不讲了。后面可能会详细列出逻辑表达式求值的选项。
上面的4步推导是一步更进一步的,是由简单逐渐到复杂的,最简单的命令可以组合成稍复杂的管道,再组合成更复杂的命令序列,最后组成最复杂的复合命令。
下面是 Bash 脚本语言的流程控制语句,如下:
1. for name [ [ in [ word ... ] ] ; ] do list ; done ;
2. for (( expr1 ; expr2 ; expr3 )) ; do list ; done ;
3. select name [ in word ] ; do list ; done ;
4. case word in [ [(] pattern [ | pattern ] ... ) list ;; ] ... esac ;
5. if list; then list; [ elif list; then list; ] ... [ else list; ] fi ;
6. while list-1; do list-2; done ;
7. until list-1; do list-2; done 。
上面的公式大家看得懂吧,我相信大家肯定看得懂。其中的 [...] 代表的是可以有也可以真没有的部分。在以上公式中,请注意第 2 个公式 for 循环中的双括号,它执行的是其中的表达式的算术运算,这是和其它高级语言的 for 循环最像的,但是很遗憾,Bash 中的算术表达式目前只能计算整数。再请注意第 3 个公式,select 语法,和 for...in... 循环的语法比较类似,但是它可以在屏幕上显示一个菜单。如果我没有记错的话,Basic 语言中应该有这个功能。其它的控制结构在别的高级语言中都很常见,就不需要我在这里啰嗦了。
最后,再来展示一下如何定义函数:
name () compound-command [redirection]
或者
function name [()] compound-command [redirection]
可以看出,如果有 function 关键字,则()是可选的,如果没有 function 关键字,则()是必须的。这里需要特别指出的是:函数体只要求是 compound-command,我前面总结过 compound-command 有四种形式,所以有时候定义一个函数并不会出现{ }哦。如下图,这样的函数也是合法的:
That's all。这就是 Bash 脚本语言的全部语法。就这么简单。
好像忘了点什么?对了,还有输入输出重定向没有讲。输入输出重定向是 Shell 中又一个伟大的发明,它的存在有着它独特的哲学意义。这个请看下一节。
输入输出重定向
Unix 世界有一个伟大的哲学:一切皆是文件。(这个扯得有点远。) Unix 世界还有一个伟大的哲学:创建进程比较方便。(这个扯得也有点远。)而且,每一个进程一创建,就会自动打开三个文件,它们分别是标准输入、标准输出、标准错误输出,普通情况下,它们连接到用户的控制台。在 Shell 中,使用数字来标识一个打开的文件,称为文件描述符,而且数字 0、 1、 2 分别代表标准输入、标准输出和标准错误输出。在 Shell 中,可以通过>、<将命令的输入、输出进行重定向。结合 exec 命令,可以非常方便地打开和关闭文件。需要注意的是,当文件描述符出现在>、<右边的时候,前面要使用&符号,这可能是为了和数学表达式中的大于和小于进行区别吧。使用&-可以关闭文件描述符。
> < & 数字 exec -,这就是输入输出重定向的全部。下面的公式中,我使用 n 代表数字,如果是两个不同的数字,则使用 n1、n2,使用 [...] 代表可选参数。输入输出重定向的语法如下:
[n]> file
#重定向标准输出(或 n)到file。
[n]>> file
#重定向标准输出(或 n)到file,追加到file末尾。
[n]< file
#将file重定向到标准输入(或 n)。
[n1]>&n2
#重定向标准输出(或 n1)到n2。
2> file >&2
#重定向标准输出和错误输出到file。
| command
#将标准输出通过管道传递给command。
2>&1 | command
#将标准输出和错误输出一起通过管道传递给command,等同于|&。请注意,数字和>、<符号之间是没有空格的。结合 exec,可以非常方便地使用一个文件描述符来打开、关闭文件,如下:
echo Hello >file1
exec 3<file1 4>file2
#打开文件
cat <&3 >&4
#重定向标准输入到 3,标准输出到 4,相当于读取file1的内容然后写入file2
exec 3<&- 4>&-
#关闭文件
cat file2
#显示结果为 Hello
#还可以暂存和恢复文件描述符,如下:
exec 5>&2
#把原来的标准错误输出保存到文件描述符5上
exec 2> /tmp/$0.log
#重定向标准错误输出
...
exec 2>&5
#恢复标准错误输出
exec 5>&-
#关闭文件描述符5,因为不需要了还可以将<>一起使用,表示打开一个文件进行读写。
除了 exec,输入输出重定向和 read 命令配合也很好用,read 命令每次读取文件的一行。但是要注意的是,输入输出重定向放到 for、while 等循环的循环体和循环外,效果是不一样的。如下图: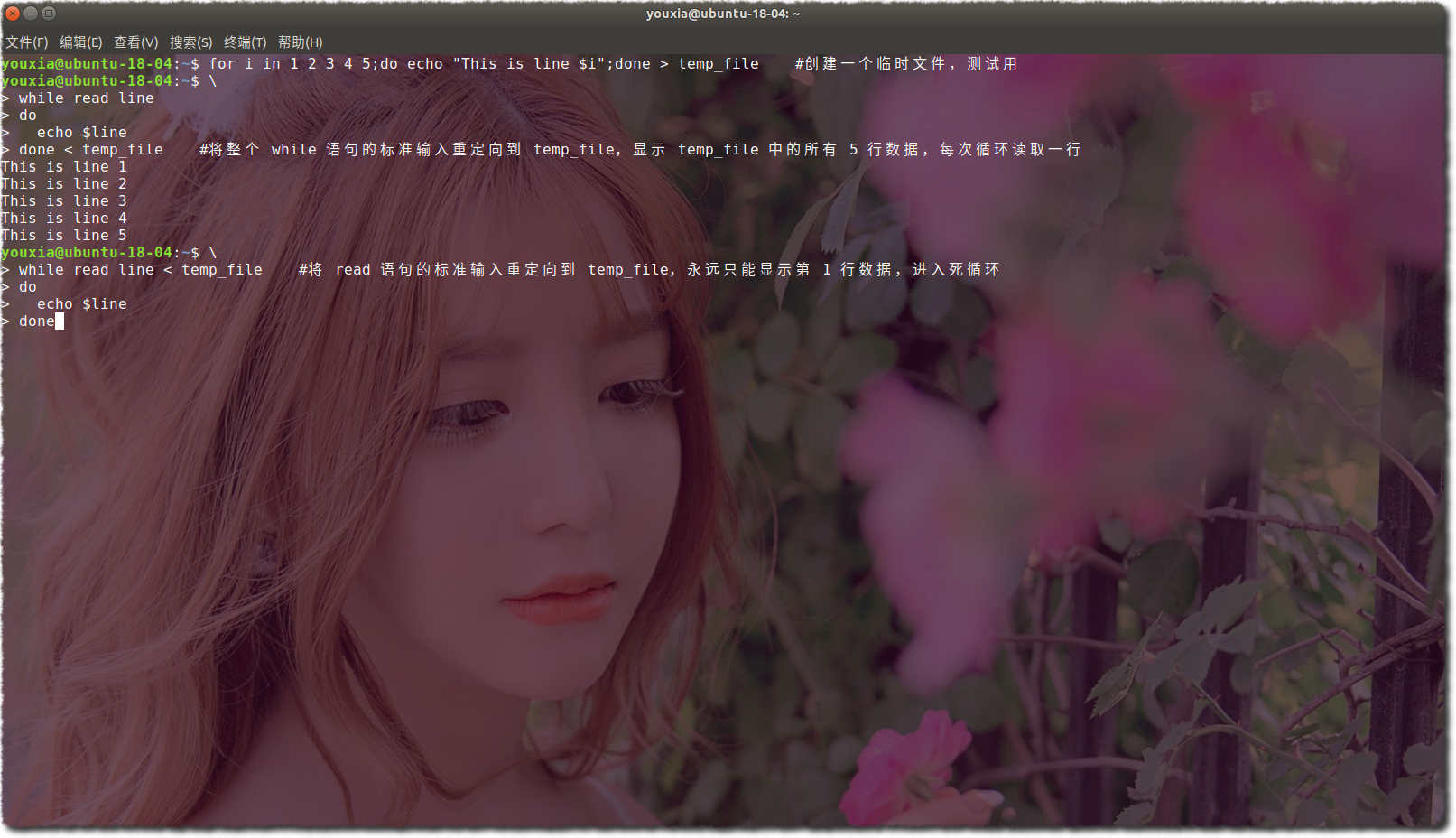

另外,输入输出重定向符号>、<还可以和()一起使用,表示进程替换(Process substitution),如>(list)、<(list)。结合前面提到的<、>、(list)的含义,进程替换的作用是很容易猜到的哦。
Bash 脚本编程语言的美学:大道至简
如果你问我 Bash 脚本语言哪里美?我会回答:简洁就是美。请看下面逐条论述:
1.使用了简洁的抽象的符号。Bash 脚本语言几乎使用到了键盘上能够找到的所有符号,$用作字符串展开,|用作管道,<、>用作输入输出重定向,一点都不浪费;
2.只使用了 9 个元字符、10 个控制操作符和 22 个关键字,就构建了一个完整的、面向字符串编程的语言;
3.概念上具有很好的一致性;例如 (list) 复合命令的功能是执行括号内的命令序列,而$用于引导字符串展开,所以 $(list) 用于命令替换(所以我前面说$()形式的命令替换比`...`形式的命令替换更加具有一致性)。再例如 ((expresion)) 用于数学表达式求值,所以 $((expression)) 代表算术展开。再例如{}和,配合使用,且中间没有空格时,代表大括号展开,但是当需要使用{ }来定义复合命令时,必须把{ }当关键字,它们和它里面的内容必须以空格隔开,而且}和它前面的一条命令之间必须有一个;或者<newline>。这些概念上的一致性设计得非常精妙,使用起来自然而然可以让人体会到一种美感;
4.完美解决了一个命令执行时的输出和运行状态的分离。有其它编程语言经历的人也经常会遇到这样的问题:当我们调用一个函数的时候,函数可能会产生两个结果,一个是函数的返回值,一个是函数调用是否成功。在 C# 和 Java 等高级语言中,往往使用 try...catch 等捕获异常的方式来判断函数调用是否成功,但仍然有程序员让函数返回 null 代表失败,而 C 语言这种没有异常机制的语言,实在是难以判断一个函数的返回值究竟如何表示该函数调用是否成功(比如就有很多 API 让函数返回 -1 代表失败,而有的函数运行失败是会设置 errno 全局变量)。在 Bash 中,命令运行的状态和命令的标准输出区分很明确,如果你需要命令的标准输出,使用命令替换来生成字符串,如果你只需要命令的运行状态,直接将命令写在 if 语句之中即可,或者使用 $? 特殊变量来检查上一条命令的运行状态。如果不想在检查命令运行状态的时候让命令的标准输出影响用户,可以把它重定向到 /dev/null,像这样:
if cat /etc/passwd | grep youxia > /dev/null; then echo 'youxia is exist'; fi5.使用管道和输入输出重定向让文件的读写变得简单。想一想在 C 语言中怎么读文件吧,除了麻烦的 open、close 不说,每读一个字符串还得先准备一个 buffer,准备长了怕浪费空间,准备短了怕缓冲区溢出,虐心啦。使用 Bash,那真的是太方便了。
6.它还有邪恶的 eval 哦,eval 命令实在是太强大了,请看下图,模拟指针进行查表: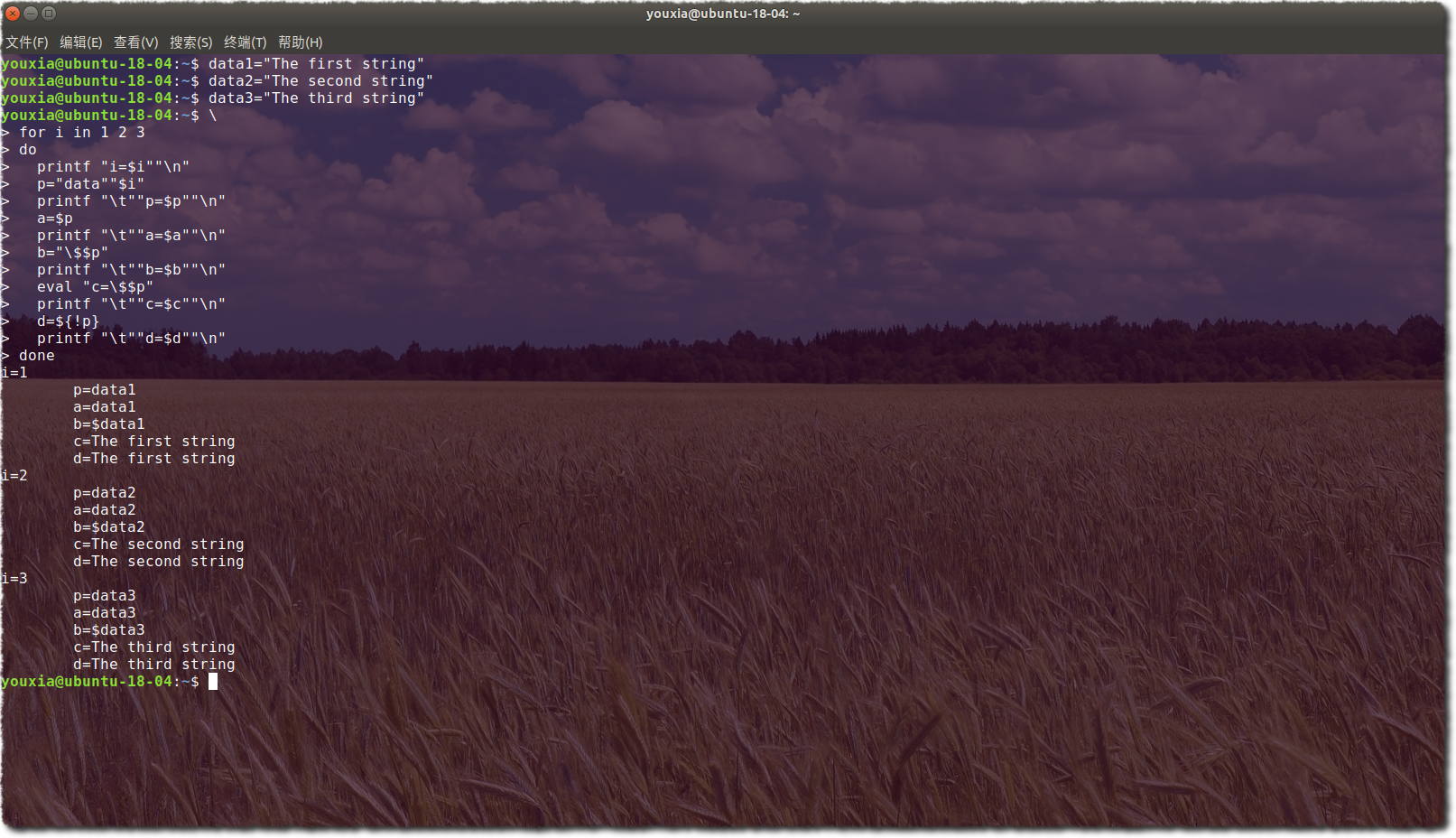
当然,自从 Bash 3 之后,Bash 本身就提供了间接引用的功能(使用“${!var}”)。
例外:
Bash 语言也并不是在所有的方面都是完美的,还存在几个特别的例外,像前面说的=。除了=之外,()也有一个使用不一致的地方,那就是对数组的初始化,例如 array=(a b c d e f) ,这和前面讲的()用于在子 Shell 中执行命令序列还真的是不一致。
总结
以上内容是我的胡言乱语,因为以上内容即无法教会大家完整的 Bash 语法,也无法教会大家用 Bash 做任何一点有意义的工作。如果想用 Bash 干点实事,建议大家阅读 O'Reilly 出的《Shell脚本学习指南》。
求打赏
我对这次写的这个系列要求是非常高的:首先内容要有意义、够充实,信息量要足够丰富;其次是每一个知识点要讲透彻,不能模棱两可含糊不清;最后是包含丰富的截图,让那些不想装 Linux 系统的朋友们也可以领略到 Linux 桌面的风采。如果我的努力得到大家的认可,可以扫下面的二维码打赏一下:
版权申明
该随笔由京山游侠在2018年10月04日发布于博客园,引用请注明出处,转载或出版请联系博主。QQ邮箱:1841079@qq.com
转载于:https://www.cnblogs.com/lonelyxmas/p/10499549.html
最后
以上就是追寻人生最近收集整理的关于Linux 桌面玩家指南:06. 优雅地使用命令行及 Bash 脚本编程语言中的美学与哲学...的全部内容,更多相关Linux内容请搜索靠谱客的其他文章。








发表评论 取消回复