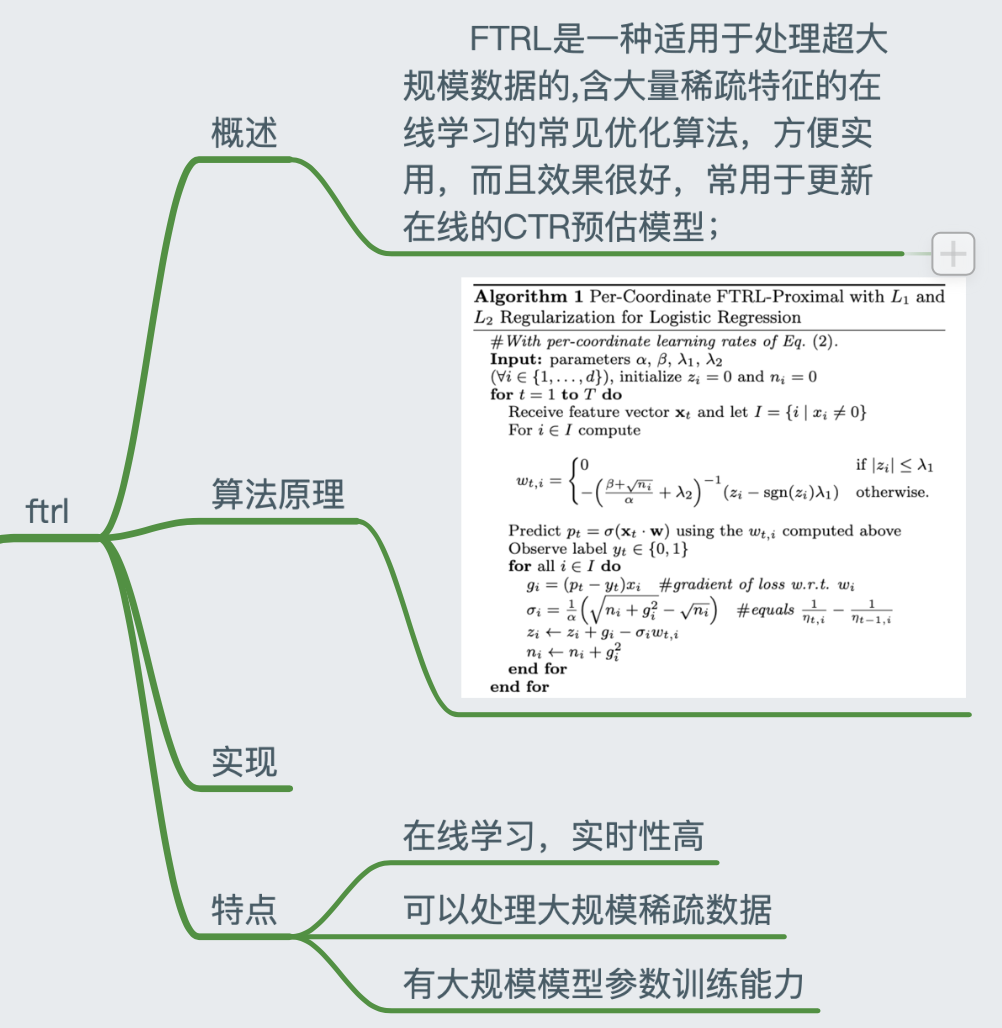
脑图
代码实现
'''
DO WHAT THE FUCK YOU WANT TO PUBLIC LICENSE
Version 2, December 2004
Copyright (C) 2004 Sam Hocevar <sam@hocevar.net>
Everyone is permitted to copy and distribute verbatim or modified
copies of this license document, and changing it is allowed as long
as the name is changed.
DO WHAT THE FUCK YOU WANT TO PUBLIC LICENSE
TERMS AND CONDITIONS FOR COPYING, DISTRIBUTION AND MODIFICATION
0. You just DO WHAT THE FUCK YOU WANT TO.
'''
from datetime import datetime
from csv import DictReader
from math import exp, log, sqrt
# TL; DR, the main training process starts on line: 250,
# you may want to start reading the code from there
##############################################################################
# parameters #################################################################
##############################################################################
# A, paths
# path to training file
train = '/Users/avazu/avazu-ctr-prediction/train'
# path to testing file
test = '/Users/avazu/avazu-ctr-prediction/test'
# path of to be outputted submission file
submission = '/Users/avazu/avazu-ctr-prediction/sampleSubmission_myself'
# B, model
alpha = .1 # learning rate
beta = 1. # smoothing parameter for adaptive learning rate
L1 = 1. # L1 regularization, larger value means more regularized
L2 = 1. # L2 regularization, larger value means more regularized
# C, feature/hash trick
D = 2 ** 20 # Hash分桶的数量 number of weights to use
interaction = False # whether to enable poly2 feature interactions
# D, training/validation
epoch = 1 # learn training data for N passes
holdafter = 22 # data after date N (exclusive) are used as validation
holdout = None # use every N training instance for holdout validation
##############################################################################
# class, function, generator definitions #####################################
##############################################################################
# ftrl实现逻辑
class ftrl_proximal(object):
''' Our main algorithm: Follow the regularized leader - proximal
In short,
this is an adaptive-learning-rate sparse logistic-regression with
efficient L1-L2-regularization
Reference:
http://www.eecs.tufts.edu/~dsculley/papers/ad-click-prediction.pdf
'''
def __init__(self, alpha, beta, L1, L2, D, interaction):
# parameters
self.alpha = alpha
self.beta = beta
self.L1 = L1
self.L2 = L2
# feature related parameters
self.D = D
self.interaction = interaction
# model
# n: squared sum of past gradients
# z: weights
# w: lazy weights
self.n = [0.] * D
self.z = [0.] * D
self.w = {}
def _indices(self, x):
''' A helper generator that yields the indices in x
The purpose of this generator is to make the following
code a bit cleaner when doing feature interaction.
'''
# first yield index of the bias term
yield 0
# then yield the normal indices
for index in x:
yield index
# now yield interactions (if applicable)
if self.interaction:
D = self.D
L = len(x)
x = sorted(x)
for i in range(L):
for j in range(i+1, L):
# one-hot encode interactions with hash trick
yield abs(hash(str(x[i]) + '_' + str(x[j]))) % D
def predict(self, x):
''' Get probability estimation on x
INPUT:
x: features
OUTPUT:
probability of p(y = 1 | x; w)
'''
# parameters
alpha = self.alpha
beta = self.beta
L1 = self.L1
L2 = self.L2
# model
n = self.n
z = self.z
w = {}
# wTx is the inner product of w and x
wTx = 0.
for i in self._indices(x):
sign = -1. if z[i] < 0 else 1. # get sign of z[i]
# build w on the fly using z and n, hence the name - lazy weights
# we are doing this at prediction instead of update time is because
# this allows us for not storing the complete w
if sign * z[i] <= L1:
# w[i] vanishes due to L1 regularization
w[i] = 0.
else:
# apply prediction time L1, L2 regularization to z and get w
w[i] = (sign * L1 - z[i]) / ((beta + sqrt(n[i])) / alpha + L2)
wTx += w[i]
# cache the current w for update stage
self.w = w
# bounded sigmoid function, this is the probability estimation
# 做SIGMOD函数
return 1. / (1. + exp(-max(min(wTx, 35.), -35.)))
#反向传导计算
def update(self, x, p, y):
''' Update model using x, p, y
INPUT:
x: feature, a list of indices
p: click probability prediction of our model
y: answer
MODIFIES:
self.n: increase by squared gradient
self.z: weights
'''
# parameter
alpha = self.alpha
# model
n = self.n
z = self.z
w = self.w
# gradient under logloss
g = p - y
# update z and n
for i in self._indices(x):
sigma = (sqrt(n[i] + g * g) - sqrt(n[i])) / alpha
z[i] += g - sigma * w[i]
n[i] += g * g
def logloss(p, y):
''' FUNCTION: Bounded logloss
INPUT:
p: our prediction
y: real answer
OUTPUT:
logarithmic loss of p given y
'''
p = max(min(p, 1. - 10e-15), 10e-15)
return -log(p) if y == 1. else -log(1. - p)
def data(path, D):
''' GENERATOR: Apply hash-trick to the original csv row
and for simplicity, we one-hot-encode everything
INPUT:
path: path to training or testing file
D: the max index that we can hash to
YIELDS:
ID: id of the instance, mainly useless
x: a list of hashed and one-hot-encoded 'indices'
we only need the index since all values are either 0 or 1
y: y = 1 if we have a click, else we have y = 0
'''
for t, row in enumerate(DictReader(open(path))):
# process id
ID = row['id']
del row['id']
# process clicks
y = 0.
if 'click' in row:
if row['click'] == '1':
y = 1.
del row['click']
# extract date
date = int(row['hour'][4:6])
# turn hour really into hour, it was originally YYMMDDHH
row['hour'] = row['hour'][6:]
# build x
x = []
for key in row:
value = row[key]
# one-hot encode everything with hash trick
index = abs(hash(key + '_' + value)) % D
x.append(index)
yield t, date, ID, x, y
##############################################################################
# start training #############################################################
##############################################################################
start = datetime.now()
# initialize ourselves a learner
learner = ftrl_proximal(alpha, beta, L1, L2, D, interaction)
# start training
for e in range(epoch):
loss = 0.
count = 0
for t, date, ID, x, y in data(train, D): # data is a generator
# t: just a instance counter
# date: you know what this is
# ID: id provided in original data
# x: features
# y: label (click)
# step 1, get prediction from learner
p = learner.predict(x)
if (holdafter and date > holdafter) or (holdout and t % holdout == 0):
# step 2-1, calculate validation loss
# we do not train with the validation data so that our
# validation loss is an accurate estimation
#
# holdafter: train instances from day 1 to day N
# validate with instances from day N + 1 and after
#
# holdout: validate with every N instance, train with others
loss += logloss(p, y)
count += 1
else:
# step 2-2, update learner with label (click) information
learner.update(x, p, y)
print('Epoch %d finished, validation logloss: %f, elapsed time: %s' % (
e, loss/count, str(datetime.now() - start)))
##############################################################################
# start testing, and build Kaggle's submission file ##########################
##############################################################################
with open(submission, 'w') as outfile:
outfile.write('id,clickn')
for t, date, ID, x, y in data(test, D):
p = learner.predict(x)
outfile.write('%s,%sn' % (ID, str(p)))
最后
以上就是默默月亮最近收集整理的关于【深度学习】优化算法-Ftrl脑图代码实现的全部内容,更多相关【深度学习】优化算法-Ftrl脑图代码实现内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复