文章目录
- 一、环视基础
- 二、顺序环视匹配过程
- (一)顺序肯定环视匹配过程
- (二)顺序否定环视匹配过程
- 三、逆序环视匹配过程
- (一)逆序环视基础
- (二)逆序肯定环视匹配过程
- 1. 逆序表达式的长度固定,如何匹配
- 2. 逆序表达式的长度不固定,如何匹配
- (1)匹配开始位置不确定,匹配结束位置确定
- (2)匹配开始位置确定,匹配结束位置不确定
- (三)逆序否定环视匹配过程
- 1. 逆序表达式的长度固定,如何匹配
- (1)匹配起始位置不确定,匹配结束位置确定
- (2)匹配起始位置确定,匹配结束位置不确定
- 2. 逆序表达式的长度不固定,如何匹配
一、环视基础
环视只进行子表达式的匹配,不占有字符,匹配到的内容不保存到最终的匹配结果,是零宽度的。环视匹配的最终结果就是一个位置。
环视的作用相当于对所在位置加了一个附加条件,只有满足这个条件,环视子表达式才能匹配成功。
环视按照方向划分有顺序和逆序两种,按照是否匹配有肯定和否定两种,组合起来就有四种环视。顺序环视相当于在当前位置右侧附加一个条件,而逆序环视相当于在当前位置左侧附加一个条件。
| 表达式 | 说明 |
|---|---|
| (?<=Expression) | 逆序肯定环视,表示所在位置左侧能够匹配 Expression |
| (?<!Expression) | 逆序否定环视,表示所在位置左侧不能匹配 Expression |
| (?=Expression) | 顺序肯定环视,表示所在位置右侧能够匹配 Expression |
| (?!Expression) | 顺序否定环视,表示所在位置右侧不能匹配 Expression |
环视是正则中的一个难点,对于环视的理解,可以从应用和原理两个角度理解,如果想理解得更清晰、深入一些,还是从原理的角度理解好一些,正则匹配基本原理参考《NFA引擎匹配原理》。
上面提到环视相当于对“所在位置”附加了一个条件,环视的难点在于找到这个“位置”,这一点解决了,环视也就没什么秘密可言了。
对于顺序肯定环视(?=Expression)来说,当子表达式Expression匹配成功时,(?=Expression)匹配成功,并报告(?=Expression)匹配当前位置成功。
对于顺序否定环视(?!Expression)来说,当子表达式Expression匹配成功时,(?!Expression)匹配失败;当子表达式Expression匹配失败时,(?!Expression)匹配成功,并报告(?!Expression)匹配当前位置成功。
二、顺序环视匹配过程
(一)顺序肯定环视匹配过程
顺序肯定环视的例子已在《NFA引擎匹配原理》中讲解过了,请移步参考。
(二)顺序否定环视匹配过程
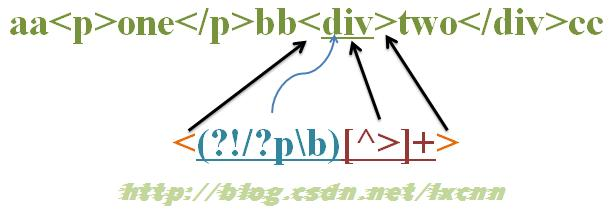
源字符串:aa<p>one</p>bb<div>two</div>cc
正则表达式:<(?!/?pb)[^>]+>
这个正则的意义就是匹配除 <p> 或 </p>之外的其余标签。/? 表示匹配正斜杠 0 次或 1 次;b 表示匹配字符边界。

首先由表达式的字符 < 取得控制权,从源字符串位置 0 开始匹配,由于 < 匹配 a 失败,在位置 0 处整个表达式匹配失败,第一次迭代匹配失败,正则引擎向前传动,由位置 1 处开始尝试第二次迭代匹配。
重复以上过程,直到位置 2,表达式的字符 < 匹配源字符串的字符 < 成功,控制权交给 (?!/?pb);(?!/?pb) 子表达式取得控制权后,进行内部子表达式的匹配。首先由 /? 取得控制权,尝试匹配 p 失败,进行回溯,不匹配,控制权交给 p;由 p 来尝试匹配 p,匹配成功,控制权交给 b;由 b 来尝试匹配位置 4,匹配成功。此时子表达式匹配完成,/?pb 匹配成功,那么环视表达式 (?!/?pb) 就匹配失败。在位置 2 处整个表达式匹配失败,新一轮迭代匹配失败,正则引擎向前传动,由位置 3 处开始尝试下一轮迭代匹配。
在位置 8 处也会遇到一轮 /?pb 匹配 /p 成功,而导致环视表达式 (?!/?pb) 匹配失败,从而导致整个表达式匹配失败的过程。
重复以上过程,直到位置 14,< 匹配 < 成功,控制权交给 (?!/?pb);/? 尝试匹配 d 失败,进行回溯,不匹配,控制权交给 p;由 p 来尝试匹配 d,匹配失败,已经没有备选状态可供回溯,匹配失败。此时子表达式匹配完成,/?pb 匹配失败,那么环视表达式 (?!/?pb) 就匹配成功。匹配的结果是位置15,然后控制权交给 [^>]+;由 [^>]+ 从位置 15 进行尝试匹配,可以成功匹配到 div,控制权交给 >;由 >来匹配 >,匹配成功。此时正则表达式匹配完成,报告匹配成功。
匹配结果为 <div>,开始位置为 14,结束位置为 19。其中 < 匹配 <,(?!/?pb) 匹配位置 15,[^>]+ 匹配字符串 div,> 匹配 >。
三、逆序环视匹配过程
(一)逆序环视基础
对于逆序肯定环视 (?<=Expression) 来说,当子表达式 Expression 匹配成功时,(?<=Expression) 匹配成功,并报告 (?<=Expression) 匹配当前位置成功。
对于逆序否定环视 (?<!Expression) 来说,当子表达式 Expression 匹配成功时,(?<!Expression) 匹配失败;当子表达式 Expression 匹配失败时,(?<!Expression)匹配成功,并报告(?<!Expression)匹配当前位置成功;
顺序环视相当于在当前位置右侧附加一个条件,所以它的匹配尝试是从当前位置开始的,然后向右尝试匹配,直到某一位置使得匹配成功或失败为止。而逆序环视的特殊处在于,它相当于在当前位置左侧附加一个条件,所以它不是在当前位置开始尝试匹配的,而是从当前位置左侧某一位置开始,匹配到当前位置为止,报告匹配成功或失败。
顺序环视尝试匹配的起点是确定的,就是当前位置,而匹配的终点是不确定的。逆序环视匹配的起点是不确定的,是当前位置左侧某一位置,而匹配的终点是确定的,就是当前位置。
所以顺序环视相对是简单的,而逆序环视相对是复杂的。这也就是为什么大多数语言和工具都提供了对顺序环视的支持,而只有少数语言提供了对逆序环视支持的原因。
JavaScript 中只支持顺序环视,不支持逆序环视。
Java 中虽然顺序环视和逆序环视都支持,但是逆序环视只支持长度确定的表达式,逆序环视中量词只支持“?”,不支持其它长度不定的量词。长度确定时,引擎可以向左查找固定长度的位置作为起点开始尝试匹配,而如果长度不确定时,就要从当前位置向左逐个位置开始尝试匹配,不成功则回溯,再向左侧位置进行尝试匹配,然后重复以上过程,直到匹配成功,或是尝试到位置0处以后,报告匹配失败,处理的复杂度是显而易见的。
目前只有.NET中支持不确定长度的逆序环视。
(二)逆序肯定环视匹配过程
1. 逆序表达式的长度固定,如何匹配
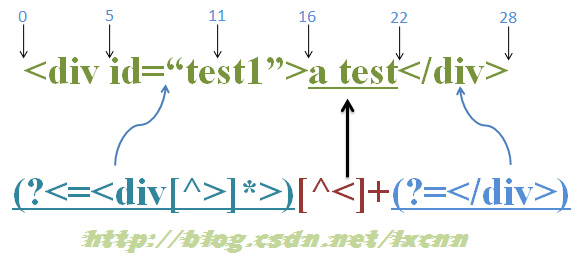
源字符串:<div>a test</div>
正则表达式:(?<=<div>)[^<]+(?=</div>)
这个正则的意义就是匹配 <div> 和 </div> 标签之间的内容,而不包括 <div> 和 </div>标签本身。

首先由逆序肯定环视表达式 (?<=<div>) 取得控制权,从位置 0 开始匹配,由于逆序肯定环视表达式中的子表达式 <div> 长度是 5,所以正则引擎会从当前位置向左侧查找 5 个字符来匹配,可是当前位置是 0,左侧没有任何内容,所以子表达式 <div> 必然匹配失败,从而逆序肯定环视表达式 (?<=<div>) 匹配失败,则整个正则表达式在字符串的位置 0 处匹配失败,即正则表达式的第 1 轮迭代匹配失败。
正则引擎向前传动,由位置 1 处开始尝试第 2 次迭代匹配,由于位置左侧的字符数量不足,所以也是匹配失败。直到传动到位置 5,正则引擎向左查找到 5 个字符,(?<=<div>) 取得控制权后,由位置 0 开始向右逐个字符匹配,结果子表达式 <div> 匹配字符串 <div> 成功,从而整个逆序肯定环视表达式 (?<=<div>) 匹配成功,匹配成功的位置是 5,控制权交给下一个子表达式 [^<]+;[^<]+ 从位置 5 向右开始逐个字符匹配,匹配字符串 a test 成功,控制权交给顺序肯定环视表达式 (?=</div>);由 </div> 匹配 </div> 成功,从而顺序肯定环视表达式 (?=</div>) 匹配成功,位置 11 匹配成功。
此时正则表达式匹配完成,报告匹配成功。匹配到的字符串为 a test,匹配开始位置为 5,匹配结束位置为 11。其中 (?<=<div>) 匹配位置 5,[^<]+ 匹配字符串 a test,(?=</div>) 匹配位置 11。
疑问:
逆序环视表达式的匹配是如何确定匹配开始位置的?如果是按照表达式的长度向左查找对应数量的字符数,从而确定匹配起点,那么当前位置左侧的字符数量不足时,匹配起点位置就无法确定,也就不会逐个字符去匹配了,因为长度都不同,匹配结果肯定是失败的。猜测,大概率是按逆序环视子表达式的长度(或者最小长度)来确定起点,如果字符数不足,就没有必要逐个字符去匹配,因为这是多余的,匹配结果肯定是失败的。
2. 逆序表达式的长度不固定,如何匹配
源字符串:<div id=“test1”>a test</div>
正则表达式:(?<=<div[^>]*>)[^<]+(?=</div>)
(1)匹配开始位置不确定,匹配结束位置确定
注:我不认可这样的匹配逻辑。
首先由“(?<=<div[^>]*>)”取得控制权,由位置 0 开始匹配,由于“<div[^>]*>”的长度不固定,可能会由逆序环视表达式的第 1 个字符从当前位置向左逐字符查找(这个可能性不大,因为太傻了!);有可能是先计算逆序表达式最小长度,然后在当前位置向前查找初始的匹配起点位置。在这里“<div[^>]*>”至少需要 5 个字符,所以由当前位置向左查找 5 个字符,然后再从左到右的方向,从这 5 个字符的第 1 个字符开始尝试匹配,但是由于此时位于位置 0处,前面没有任何字符,所以尝试匹配失败。
正则引擎传动装置向右传动,由位置 1 处开始尝试匹配,同样因为左侧的字符数不足,所以直接匹配失败,直到位置 5 处,向左查找 5 个字符,满足条件,此时把控制权交给“(?<=<div[^>]*>)”中的子表达式“<div[^>]*>”。“<div[^>]*>”取得控制权后,由位置 0 处开始向右尝试匹配,由于正则都是逐字符进行匹配的,所以这时会把控制权交给“<div[^>]*>”中的“<”,由“<”尝试匹配字符串中的“<”,匹配成功,接下来由“d”尝试匹配字符串中的“d”,匹配成功,同样的过程,由“<div[^>]*”匹配位置 0 到位置 5 之间的“<div ”成功,其中“[^>]*”在匹配“<div ”中的空格时会记录可供回溯的状态的,此时控制权交给“>”,由于已没有任何字符可供匹配,所以“>”匹配失败,此时进行回溯,由“[^>]*”让出已匹配的空格给“>”进行匹配,同样匹配失败,此时已没有可供回溯的状态,所以这一轮迭代匹配失败。
正则引擎传动装置向右传动,由位置 6 处开始尝试匹配,同样匹配失败,直到位置 16 处,此时的当前位置指的就是位置 16,向左查找到 5 个字符,把控制权交给“(?<=<div[^>]*>)”中的子表达式“<div[^>]*>”。“<div[^>]*>”取得控制权后,由位置 11 处开始向右尝试匹配, “<div[^>]*>”中的“<”尝试匹配字符串中的“s”,匹配失败;继续向左尝试,在位置 10 处由“<”尝试匹配字符串中的“e”,也匹配失败。同样的过程,直到尝试到位置 0 处,最后“<div[^>]*>”以位置 0 作为匹配起点,向右匹配,结果成功匹配到“<div id=“test1”>”,此时“(?<=<div[^>]*>)”匹配成功,控制权交给“[^>]+”,继续进行下面的匹配…
注:我认为这样的匹配规则是错误的,因为“<div[^>]*>”中的“<”匹配失败后往左尝试匹配,这样的做法很不合理,为什么?假设“<”继续向左尝试匹配,最后匹配成功了,控制权交个下个表达式,而该表达式匹配失败了,“<”会继续向左尝试匹配,可能又匹配成功了,但是下个表达式又匹配失败,这样的匹配逻辑肯定不对!!!
(2)匹配开始位置确定,匹配结束位置不确定
注:这个更符合逆序的概念,也更加合理,我认可这种匹配逻辑!
源字符串:<div>a test</div>
正则表达式:(?<=<div>)[^<]+(?=</div>)
“(?<=<div>)”获得控制权,从源字符串位置 0 开始向左匹配,首先“>” 去匹配,但是位置 0 左侧没有字符,所以匹配失败,第 1 次迭代匹配失败;接着正则引擎指针向右移动,“>” 去匹配字符串的字符“<”,匹配失败,第 2 次迭代匹配失败。
重复上述过程,直到位置 5,子表达式“<div>”中的“>” 去匹配位置 5 左边的第 1 个字符“>”,匹配成功;子表达式“<div>”中的“v”去匹配位置 5 左边第 2 个字符“v”,匹配成功…,最后子表达式“<div>”成功匹配位置 5 左边的字符串“<div>”,那么说明逆序肯定环视表达式“(?<=<div>)”匹配成功,即成功匹配位置 5;接着控制权给表达式“[^<]+”,该表达式从位置 5 开始向右逐个字符匹配,最后成功匹配到字符串“a test”,接着把控制权交个子表达式“(?=</div>)”,由它去验证字符串“a test”的结尾位置 11 是否符合正则式的要求,结果“(?=</div>)”成功匹配到了字符串“a test”后面的字符串“</div>”,说明字符串“a test”的结尾位置 11 符合要求,后续没有子表达式了,说明正则表达式迭代匹配成功 1 次,成功匹配到字符串“a test”。接着从位置 11 开始下次迭代匹配…
后面重复上述的过程,直到正则引擎的指针移到字符串的结尾处,则停止迭代匹配。
(三)逆序否定环视匹配过程
源字符串:adf<B>BerBilBlon<B>Ssdfefe</B>dfee
正则表达式:(?<!<B>)B
1. 逆序表达式的长度固定,如何匹配
(1)匹配起始位置不确定,匹配结束位置确定
当前位置是匹配终点,匹配起点在当前位置的左侧,最终的匹配起点是不确定的,初始的匹配起点可以根据逆序表达式的长度来查找。
注:我认为这样的匹配逻辑是错误的,不认可
首先由“(?<!<B>)”的子表达式“<B>”取得控制权,由位置 0 开始尝匹配,由于“<B>”的长度固定为 3,所以会从当前位置向左查找 3个字符,但是由于此时位于位置 0 处,前面没有任何字符,所以直接匹配失败,“<B>”匹配失败,那么整个逆序否定环视表达式“(?<!<B>)”则匹配成功,所以位置 0 满足逆序否定环视表达式“(?<!<B>)”,那么控制权就传给了“B”,由“B”从位置 0 开始向右匹配字符,于是“B”就去匹配字符串中的“a”,结果匹配失败,那么第 1 次迭代匹配失败。
正则引擎传动装置向右传动,你可以理解为有个指针的东西向右移动,此时指针来到位置 1 处,由位置 1 处向左查找 3 个字符,但是前面只有 1 个字符 a,所以同样和“<B>”匹配失败,则整个逆序否定环视表达式“(?<!<B>)”匹配成功,控制权传给“B”,由“B”从位置 1 开始向右匹配字符,于是“B”就去匹配字符串中的“d”,结果匹配失败,那么第 2 次迭代匹配失败。
直到位置 3 处,向左查找到 3 个字符串“abc”,字符数满足条件,此时“(?<!<B>)”中的子表达式“<B>”获得控制权。“<B>”取得控制权后,由位置 0 处开始向右逐个字符匹配字符串“abc”,既然是逐字符进行匹配的,所以这时会把控制权交给“<B>”中的“<”,由“<”尝试匹配字符串中的“a”,匹配失败,那么“<B>”就和字符串“abc”匹配失败,则整个逆序否定环视表达式“(?<!<B>)”匹配成功,控制权传给“B”,由“B”从位置 3 开始向右匹配字符,于是“B”就去匹配字符串中的“<”,结果匹配失败,那么第 4 次迭代匹配失败。
正则引擎的传动指针继续向右移动,此时来到了位置 4,那么正则引擎向左查找 3 个字符来匹配,查找到的字符串就是“df<”,接着“<B>”获得控制权,从位置 1 开始向右逐个字符匹配,那么首先由“<B>”中的“<”去匹配字符“d”,匹配失败,那么整个逆序否定环视表达式“(?<!<B>)”匹配成功,控制权传给“B”,由“B”从位置 4 开始向右匹配字符,于是“B”就去匹配位置 4 后面的“B”,结果匹配成功。
重复上述的过程直到正则引擎的指针移到字符串结尾才结束迭代匹配。
最后匹配到的“B”,如下所示(高亮部分):

(2)匹配起始位置确定,匹配结束位置不确定
当前位置是匹配起点,逆序环视是从当前位置向左开始匹配的,匹配终点在当前位置的左侧。不少人认为应该是这样的匹配规则,因为更符合逆序的概念。我也支持这个匹配逻辑。
注:需要明确的一点,无论是什么样的正则表达式,都是要从字符串的位置 0 处开始尝试匹配的,这点没有变。
逆序否定环视表达式“(?<!<B>)B”中的“<B>”先获得控制权,因为匹配从右到左,所以子表达式“<B>”中的“>”会先获得控制权,去匹配字符串当前位置左边的第 1 个字符,不过当前位置是 0,所以左侧没有字符,固然匹配失败,既然“<B>”匹配失败,那么整个逆序否定环视表达式“(?<!<B>)B”就匹配成功,也就是说位置 0 是匹配成功的,位置 0 是满足逆序否定环视表达式的,于是控制权交给“B”,由“B”从字符串位置 0 开始向右匹配字符,显然“B”匹配“a”是失败的,因此整个正则表达式的第 1 次迭代匹配失败。
重复上述的过程,直到位置 4,“<B>”从位置 4 开始向左逐个字符匹配,首先由“>”匹配位置 4 左边的第 1 个字符“<”,结果匹配失败,于是整个逆序否定环视表达式“(?<!<B>)B”匹配成功,也就是说位置 4 匹配成功,控制权交个了“B”,由“B”从位置 4 开始向右匹配字符,显示“B”与字符“B”匹配成功。
重复上述过程,直到正则引擎的指针移到位置 6 时,“<B>”逐个字符匹配位置 6 左侧的字符,首先“<B>”中的“>”先去匹配位置 6 左边的第 1 个字符“>”,匹配成功;接着“<B>”中的“B”去匹配位置 6 左边的第 2 个字符“B”,也匹配成功;接着“<B>”中的“<”去匹配位置 6 左边的第 3 个字符“<”,也匹配成功。那么最后“<B>”成功匹配到位置 6 左边的字符串“<B>”,因为是否定环视,所以整个逆序否定环视表达式匹配失败(即位置 6 不符合要求),所以整个正则表达式的迭代匹配失败,正则引擎的指针继续向后移。
重复上述过程,直到正则引擎指针移到字符串结尾处,正则迭代匹配结束。
2. 逆序表达式的长度不固定,如何匹配
略
最后
以上就是舒适天空最近收集整理的关于正则表达式的环视深度剖析一、环视基础二、顺序环视匹配过程三、逆序环视匹配过程的全部内容,更多相关正则表达式内容请搜索靠谱客的其他文章。








发表评论 取消回复