前言
最近再看一份代码,居然已经水了三篇博客…and这是第四篇。
在说batch_sampler之前,这里不要脸的放一下之前关于dataset和dataloader的博客
正文
在自然语言处理中,由于一个batch中的句子有长有短,我们对短的做padding。但今天我遇到的fixedlengthsampler给了我另外一种思路,我们可以统计所有句子的长度,然后保证每一个batch在采样的时候,只采样句子长度相同的句子,这样就不需要padding了。这个fixedlengthsampler具体怎么实现呢?
第一步:建立length_map

这里的self.data_source是已经定义好的,集成了torch.utils.data.Dataset的dataset。假设我们这里的self.data_source.dataset是形似:[[单词1,单词2,…], [单词1,单词2,…], …]这样的句子列表。
我们遍历这个句子列表,记录长度,并以句子长度为length_map的键,而对应的值是一个列表,里面是句子在句子列表中对应的下标。也就是说:length_map形如下(随便举个例子):
{9:[10,9,11,1,2,3,4,5,6,7,8], 17:[18,20]}
第二步:建立state
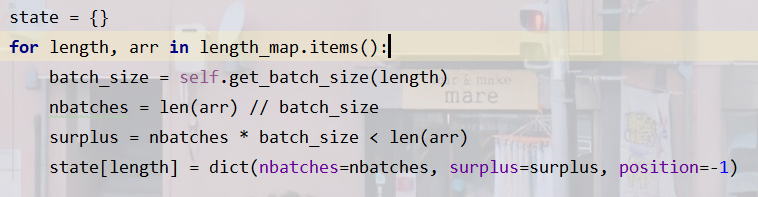
遍历上述的length_map字典,每当取出一个length(句子长度)和arr(对应句子长度的句子下标列表)的时候,我们通过self.get_batch_size得到当前这个length对应的,我们设置的batch_size,这一步的意义我目前理解为: 对于一些句子长度很长的,那么batch_size可以调小一点,这样就不容易让显存爆掉,不管这么多,我们这里假设所有长度对应的batch_size都是10!
然后计算nbatches, 并用surplus标识是否有剩下的,不是完整的一个batch的句子,后续我们可以把它加上。
这个postion在后续会体现,可以看到它一开始是-1,那么对于某一个句子长度,我第一次对你取一个batch的时候,我先position+=1,就可以通过 句子下标列表[position*batch_size: (position+1)*batch_size]来取了。每一次取,我都给它+1。
好了,state的形式如下:
{9:{“nbatches”:1, “surplus”:True, “position”:-1}, 17:{“nbatches”:0, “surplus”:True, “position”:-1 }}
因为可以看第一步中的例子,长度为9的句子有11个,那么第一个batch可以取10个(nbatches=10),还剩下了1个(surplus=True); 而长度为17的句子只有2个,nbatches=len(arr)//10=0(nbatch=0), 还剩下了2个(surplus=True)…
第三步:建立order,确定访问次序
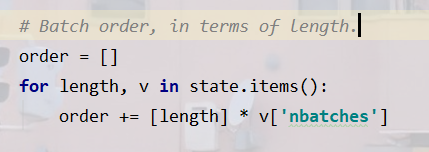
order是一个次序列表,里面放的是句子长度。
具体创建方式是:遍历state,假设当前length=9,那么根据上面,它的nbatches就是1,order里面就放一个9。可以看到遍历完state的order中是没有17的。我们可以接下来进行补充(是否补充最后一个不足batch_size的句子,这个选择也可以设置成一个参数(就比如下面的self.include_partial))
我们的order现在长这样:
[9]
第四步:补全不足batch_size的样本

这个不多讲。
如果include_partial=True,那我们的order现在长这样:
[9,9,17]
建立完这些东西,我们就可以根据order列表给定的次序,进行迭代生成了。
第五步:迭代生成


我不知道为什么这里的len(self)居然跟上面的order列表的长度一样!太神奇了。既然一样,就可以遍历所有的order里面的length。
上面已经说过关于position什么的细节了,所以get_next_batch的过程应该能看懂。
我们把这个sampler类定义为FixedLengthBatchSampler,那它的完整代码如下:
完整代码
from torch.utils.data import Sampler
class FixedLengthBatchSampler(Sampler):
def __init__(self, data_source, batch_size, include_partial=False, rng=None, maxlen=None,
length_to_size=None):
self.data_source = data_source
self.active = False
if rng is None:
rng = np.random.RandomState(seed=11)
self.rng = rng
self.batch_size = batch_size
self.maxlen = maxlen
self.include_partial = include_partial
self.length_to_size = length_to_size
self._batch_size_cache = { 0: self.batch_size }
self.logger = get_logger()
def get_batch_size(self, length):
if self.length_to_size is None:
return self.batch_size
if length in self._batch_size_cache:
return self._batch_size_cache[length]
start = max(self._batch_size_cache.keys())
batch_size = self._batch_size_cache[start]
for n in range(start+1, length+1):
if n in self.length_to_size:
batch_size = self.length_to_size[n]
self._batch_size_cache[n] = batch_size
return batch_size
def reset(self):
"""
Create a map of {length: List[example_id]} and maintain how much of
each list has been seen.
If include_partial is False, then do not provide batches that are below
the batch_size.
If length_to_size is set, then batch size is determined by length.
"""
# Record the lengths of each example.
length_map = {}
for i in range(len(self.data_source)):
x = self.data_source.dataset[i]
length = len(x)
if self.maxlen is not None and self.maxlen > 0 and length > self.maxlen:
continue
length_map.setdefault(length, []).append(i)
# Shuffle the order.
for length in length_map.keys():
self.rng.shuffle(length_map[length])
# Initialize state.
state = {}
for length, arr in length_map.items():
batch_size = self.get_batch_size(length)
nbatches = len(arr) // batch_size
surplus = nbatches * batch_size < len(arr)
state[length] = dict(nbatches=nbatches, surplus=surplus, position=-1)
# Batch order, in terms of length.
order = []
for length, v in state.items():
order += [length] * v['nbatches']
## Optionally, add partial batches.
if self.include_partial:
for length, v in state.items():
if v['surplus']:
order += [length]
self.rng.shuffle(order)
self.length_map = length_map
self.state = state
self.order = order
self.index = -1
def get_next_batch(self):
index = self.index + 1
length = self.order[index]
batch_size = self.get_batch_size(length)
position = self.state[length]['position'] + 1
start = position * batch_size
batch_index = self.length_map[length][start:start+batch_size]
self.state[length]['position'] = position
self.index = index
return batch_index
def __iter__(self):
self.reset()
for _ in range(len(self)):
yield self.get_next_batch()
def __len__(self):
return len(self.order)
把这个类传给torch.utils.data.Dataloader的batch_sampler参数就好了。
sampler = FixedLengthBatchSampler(dataset, batch_size=batch_size, rng=rng,
maxlen=filter_length, include_partial=include_partial, length_to_size=length_to_size)
loader = torch.utils.data.DataLoader(dataset, shuffle=(sampler is None), num_workers=workers, pin_memory=pin_memory,batch_sampler=sampler, collate_fn=collate_fn)
当然,如果使用默认的sampler也是可以的,无非就是shuffle=False和shuffle=True的区别。
后记
如果之前的我再hard一点,现在的我是不是会更好过。
最后
以上就是结实火最近收集整理的关于自定义dataloader里的batch_sampler,你就不需要再做padding了!前言正文完整代码后记的全部内容,更多相关自定义dataloader里内容请搜索靠谱客的其他文章。


![[Pytorch] Sampler, DataLoader和数据batch的形成1. 简介2. 整体流程3. Sampler和BatchSampler4. DataLoader](https://www.shuijiaxian.com/files_image/reation/bcimg8.png)





发表评论 取消回复