通过FileSystem API 读取数据
Hadoop文件系统通过Hadoop Path对象(而非java.io.File对象表示,因为它的语义与本地文件系统联系太过紧密)来代表文件。
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import java.net.URI;
public class FileSystemDoubleCat{
public static void main(String[] args) throws Exception{
String uri=args[0];
Configuration conf =new Configuration();
FileSystem fs =FileSystem.get(URI.create(uri),conf);
FSDataInputStream in =null;
try{
in=fs.open(new Path(uri));
IOUtils.copyBytes(in,System.out,4096,false);
in.seek(0);
IOUtils.copyBytes(in,System.out,4096,false);
}finally {
IOUtils.closeStream(in);
}
}
}
FileSystem是一个通用的文件系统API,所以第一步是检测我们使用的系统实例,这里是HDFS。Configuration对象封装了客户端或者服务器的配置,通过设置配置文件路径来实现(如etc/hadoop/core-site.xml)。
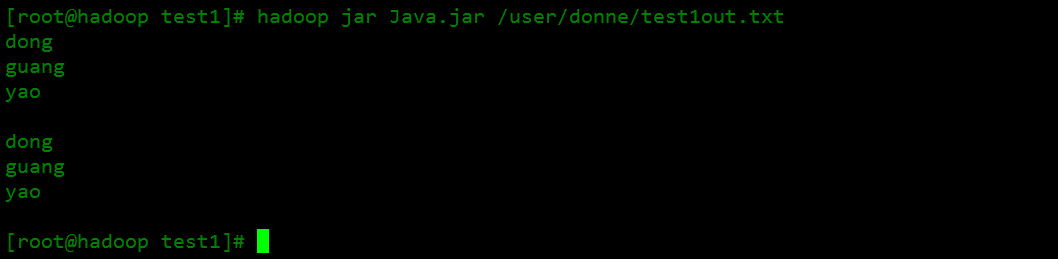
上述代码有几点解释:
- FileSystem对象中的open()方法返回的是FSDataIputStream对象,而不是标准的java.io.类对象。
- seek()来定位大于文件长度的位置会引发IOException异常。
- copyBytes的第三四个参数分别表示设置复制的缓冲区大小和设置复制结束之后是否关闭数据流。
最后
以上就是怕孤独毛巾最近收集整理的关于Hadoop文件系统— 通过FileSystem API 读取数据的全部内容,更多相关Hadoop文件系统—内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复