HDFS 的新颖功能特性
1.HDFS 视图文件系统
1)ViewFileSystem :视图文件系统
ViewFileSystem不是一个新的文件系统,只是逻辑上的一个视图文件系统,在逻辑上是唯一的。总的理解是:将各个集群的真实文件路径与ViewFileSystem内新定义的路径进行关联映射。
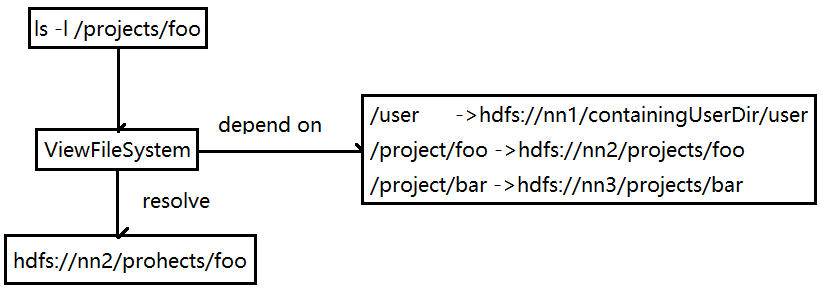
图 ViewFileSystem 的路由解析
2)ViewFileSystem 内部实现原理
1.目录挂载点(MountPoint)
主要有两个全局变量
//源路径
private Path src;
//目录指向路径,可以有多个
private URI[] targets;目前挂载点是一对一的。不同集群有相同名称的目录情况(一对多)在Hadoop中叫MergeCount,这个功能还未完成,相关JIRA: HADOOP-8298(ViewFs merge mounts).
2.挂载点的解析与存放
挂载点的解析和存放是在ViewFileSystem类下面的变量中进行的:
InodTree<FileSystem> fsState; //此对象可理解为挂载表
在InodeTree#createLink()方法中主要是INodeDir这个类的添加路径操作,该类有以下几个全局变量:
final Map<String,INode<T>> children = new HashMap<String,INode<T>>();
T InodeDirFs = null;

图 挂载点的解析与存放
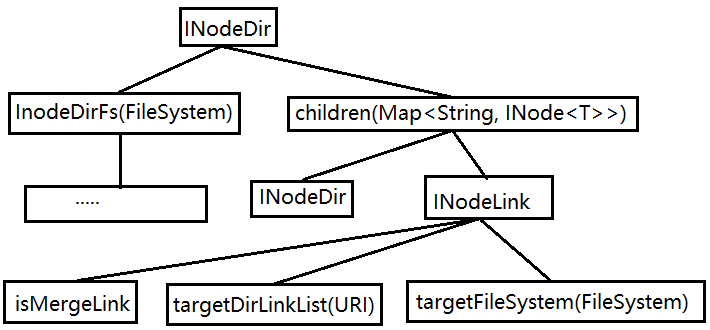
图 INodeDir 存储结构
3.ViewFileSystem 的请求处理
fsState.resolve会到挂载点树中进行逐层寻找,找到对应的文件系统后,把真实的路径传入真实的文件系统中。
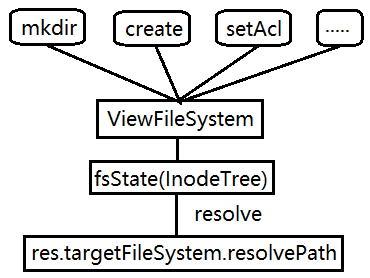
图 ViewFs 的路径解析
4.ViewFileSystem 的路径包装
比如:挂载的信息为 /project/viewFsTmp -> hdfs://nn1/projects/Tmp
真实路径下有一个文件/projects/Tmp/child
然后用户利用hadoop fs -ls /project/viewFsTmp 命令查出信息如下:
/projects/viewFsTmp/child.
这里只修改路径信息,其他信息不做修改(大小、修改时间、权限等)

图 ViewFsFileStatus 的继承关系
ViewFsFileStatus类是对路径进行包装的类,其中两个全局变量:
//原FileStatus信息
final FileStatus myFs;
//修改后的路径信息
Path modifiedPath;5.ViewFileSystem 性能优化
目前ViewFileSystem通过将路径进行拆分,保存到一个树形的结构中,解析时同样需要拆分路径,进行逐层解析;当挂载表数据量很少的情况下,效率不高,进行频繁的拆分、合并字符串本身不是高效的操作。可以直接保存到一个map的关系结构中,直接做字符串的简单比较。如果改进的话,添加Link和解析路径的逻辑也都需要改变。
3)ViewFileSystem 的使用
配置使用,二个步骤:
第一步,创建Viewfs名称
<property>
<name>fs.defaultFS</name>
<value>viewfs://MultipleCluster</value>
</property>
第二步,添加挂载关系
<property>
<name>fs.viewfs.mounttable.MultipleCluster.link./viewfstmp</name>
<value>hdfs://nn1/tmp</value>
</property>
注意:这两个步骤的MultipleCluster这个名称需要一致。
这些挂载信息是维护在客户端的内存中,不需要重启NN和DN.
2.HDFS 的Web文件系统:WebHdfsFileSystem
1)WebHdfsFileSystem REST 的 API 操作
通过Web REST API的形式对文件系统进行操作,也就是用户可以通过http请求url的形式对HDFS做操作。
所有的方法分为4类:GET/PUT/POST/DELETE
1.GET方式
获取文件目录信息相关
OPEN
GET_FILE_STATUS
LIST_STATUS
GET_CONTENT_SUMMARY
GET_FILE_CHECKSUM
GET_HOME_DIRECTORY
GET_BLOCK_LOCATIONS
获取属性、ACL访问相关
GET_DELEGATION_TOKEN
GET_XATTRS
LIST_XATTRS
GET_ACL_STATUS
CHECK_ACCESS
2.PUT方式
文件目录设置相关:
CREATE
MKDIRS
CREATE_SYMLINK
RENAME
SET_REPLICATION
SET_OWNER
SET_PERMISSION
SET_TIMES
ACL 访问属性相关
RENEW_DELEGATION_TOKEN
CANCEL_DELEGATION_TOKEN
MODIFY_ACL_ENTRIES
REMOVE_ACL_ENTRIES
REMOVE_DEFAULT_ACL
REMOVE_ACL
SET_ACL
SET_XATTR
REMOVE_XATTR
快照操作相关:
CREATE_SNAPSHOT
RENAME_SNAPSHOT
3.POST方式
APPEND:文件追加操作
CONCAT:文件拼接操作
TRUNCATE:文件截断操作
4.DELETE方式
DELETE:文件/目录删除操作
DELETE_SNAPSHOT:快照删除操作
2)WebHdfsFileSystem的流程调用
以rename操作为例,调用命令如下:
curl -i -X PUT “<HOST>:<POST>/webhdfs/v1/<PATH>?op=RENAME&destination=<PATH>”
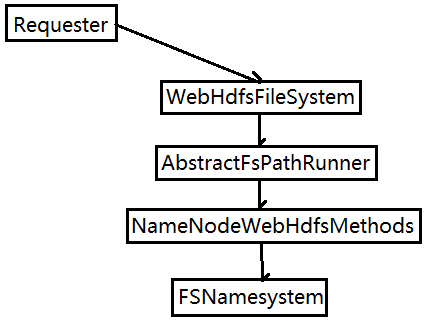
图 WebHdfsFileSystem执行过程
3)WebHdfsFileSystem执行器调用
前面rename命令的调用会经过FsPathBooleanRunner执行器的处理,FsPathBooleanRunner是AbstractRunner的子类,AbastractRunner的内部会包括:
- 初始化http请求连接。
- 连接Server端
- 获取执行回复内容
- 执行失败重试操作
在WebHDFS的操作响应中,有4中类型的响应回复
- FsPathResPonseRunner:带json回复格式的处理执行器。一般应用于GET类型的操作。
- FsPathRunner:不带json回复格式的处理执行器,getResponse返回内容为空。
- FsPathConnectionRunner:执行器的回复是http的连接对象。
- FsPathOutPutStreamRunner:用于处理创建、追加数据流。

图 WebHdfsFlieSystem 的执行器继承关系
4)WebHDFS的OAuth2认证
1. OAuth2认证机制
3个角色
服务端:用户使用服务端提供的各个资源
用户:服务端资源的真实拥有者
客户端:要访问服务端资源的第三方应用
具体的认证步骤:
- 用户登录客户端向服务端请求一个临时令牌
- 服务端通过客户端验证后,返回其临时令牌
- 客户端获取临时令牌后,引导用户到服务端提供的授权页面
- 用户输入账号、密码后,表明用户授权此客户端访问所请求的资源
- 授权过程完成后,客户端根据临时令牌从服务端获取访问令牌
- 客户端获取访问令牌后向服务端访问受保护的资源
2.WebHdfsFileSystem的OAuth2认证调用

图 OAuth2认证调用图
5)WebHDFS的使用
如下命令:
curl -i -X PUT “<HOST>:<POST>/webhdfs/v1/<PATH>?op=RENAME&destination=<PATH>”
-X后面代表的是请求类型,如果没有设置用户,可能会报出权限拒绝的错误
可以通过user.data=<USER>参数:
curl -i -X PUT “<HOST>:<POST>/webhdfs/v1/<PATH>?user.name=<USER>&op=RENAME&destination=<PATH>”
3.HDFS 数据加密空间: Encryption zone
1)Encryption zone 原理介绍
1.每个encryption zone会与每个encryption zone key相关联,而这个key会在创建encryption zone的时候被指定。
2.每个encryption zone中的文件会有唯一的data encryption key(数据加密key),简称DEK.
3.DEK不会被HDFS直接处理,HDFS只处理经过加密的DEK,叫做encrypted data encryption key,缩写EDEK。
4.客户端请求KMS服务去解密EDEK,然后利用解密后的DEK去读、写数据。
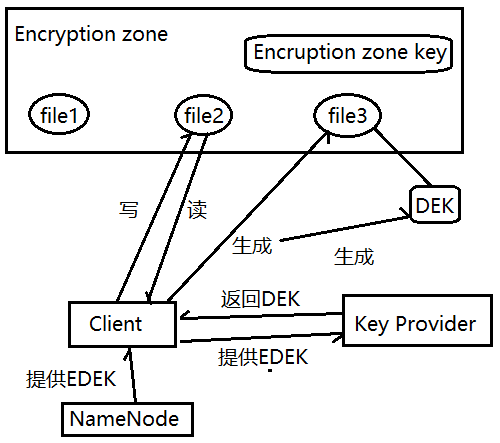
图 Encryption zone原理图
2)Encryption zone源码实现
- Encryption zone下的写文件
- Encryption zone下的读文件
- Encryption zone 的管理
3)Encryption zone的使用
需要个相关的配置项:
1.完成keyProvider的配置。将已存在的keyProvider的URL地址配置到下面的配置项中:
dfs.encryption.key.provider.uri
2.加密算法相关的配置
hadoop.security.crypto.codec.classes.EXAMPLECIPHERSUITE
hadoop.security.crypto.codec.classes.aes.ctr.nopadding
hadoop.security.crypto.cipher.suite
hadoop.security.crypto.jce.provider
hadoop.security.crypto.buffer.size
3.配置listZone响应回复的个数。
dfs.namenode.list.encryption.zones.num.responses
4.创建Encryption zone加密空间。加密空间针对的是目录级别,并且需要设置一个key名称(创建一个加密key:hadoop key create myKey)。
hdfs crypto -createZone -keyName <keyName> -path <path>
这里的path必须是已经建好的目录,此命令的作用相当于将目录作为一个加密空间,在此目录下的文件在读写的过程中被加、解密。
一些其他命令:
hdfs crypto -listZones //查看当前创建好的加密空间
hadoop fs -mkdir /zone
hdfs crypto -createZone -keyName myKey -path /zone
hadoop fs -chown myuser:myuser /zone
hadoop fs -put helloWorld /zone
hadoop fs -cat /zone/helloWorld
最后
以上就是无私芒果最近收集整理的关于HADOOP之HDFS 的新颖功能特性HDFS 的新颖功能特性的全部内容,更多相关HADOOP之HDFS内容请搜索靠谱客的其他文章。








发表评论 取消回复