本系列将 Java 17 之前的随机数 API 以及 Java 17 之后的统一 API 都做了比较详细的说明,并且将随机数的特性以及实现思路也做了一些简单的分析,帮助大家明白为何会有这么多的随机数算法,以及他们的设计思路是什么。
本系列会分为两篇,第一篇讲述 Java 随机数算法的演变思路以及底层原理与考量,之后介绍 Java 17 之前的随机算法 API 以及测试性能,第二篇详细分析 Java 17 之后的随机数生成器算法以及 API 和底层实现类以及他们的属性,性能以及使用场景,如何选择随机算法等等,并对 Java 的随机数对于 Java 的一些未来特性的适用进行展望
这是第一篇。
如何生成随机数
我们一般使用随机数生成器的时候,都认为随机数生成器(Pseudo Random Number Generator, PRNG)是一个黑盒:
这个黑盒的产出,一般是一个数字。假设是一个 int 数字。这个结果可以转化成各种我们想要的类型,例如:如果我们想要的的其实是一个 long,那我们可以取两次,其中一次的结果作为高 32 位,另一次结果作为低 32 位,组成一个 long(boolean,byte,short,char 等等同理,取一次,取其中某几位作为结果)。如果我们想要的是一个浮点型数字,那么我们可以根据 IEEE 标准组合多次取随机 int 然后取其中某几位组合成浮点型数字的整数位以及小数位。
如果要限制范围,最简单的方式是将结果取余 + 偏移实现。例如我们想取范围在 1 ~ 100 之间,那么我们就将结果先对 99 取余,然后取绝对值,然后 +1 即可。当然,由于取余操作是一个性能消耗比较高的操作,最简单的优化即检查这个数字 N 与 N-1 取与运算,如果等于 0 即这个书是 2 的 n 次方(2 的 n 次方 2 进制表示一定是 100000 这样的,减去 1 之后 为 011111,取与肯定是 0);对于 2 的 n 次方取余相当于对 2 的 n 次方减一取与运算。这是一个简单的优化, 实际的优化要比这个复杂多。
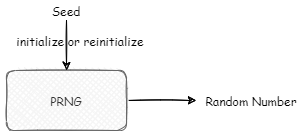
初始化这个黑盒的时候,一般采用一个 SEED 进行初始化,这个 SEED 的来源可能多种多样,这个我们先按下不表,先来看一些这个黑盒中的一些算法。
线性同余算法
首先是最常见的随机数算法:线性同余(Linear Congruential Generator)。即根据当前 Seed 乘以一个系数 A,然后加上一个偏移 B,最后按照 C 进行取余(限制整体在一定范围内,这样才能选择出合适的 A 和 B,为什么要这么做后面会说),得出随机数,然后这个随机数作为下次随机的种子,即:
X(n+1) = ( A * X(n) + B ) % C
这种算法的优势在于,实现简单,并且性能算是比较好的。 A,B 取值必须精挑细算,让在 C 范围内的所有数字都是等可能的出现的。例如一个极端的例子就是 A = 2, B = 2, C = 10,那么 1,3,5,7,9 这些奇数在后续都不可能出现。为了能计算出一个合适的 A 和 B,要限制 C 在一个比较可控的范围内。一般为了计算效率,将 C 限制为 2 的 n 次方。这样取余运算就可以优化为取与运算。不过好在,数学大师们已经将这些值(也就是魔法数)找到了,我们直接用就好了。
这种算法生成的随机序列,是确定的,例如 X 下一个是 Y, Y 下一个是 Z,这可以理解成一个确定环(loop)。
 。
。
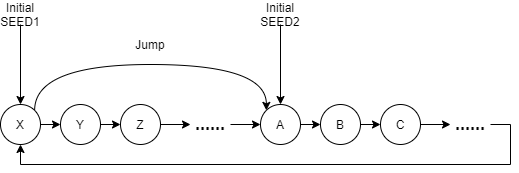
这个环的大小,即 Period。由于 Period 足够大,初始 SEED 一般也是每次不一样的,这样近似做到了随机。但是,假设我们需要多个随机数生成器的时候,就比较麻烦了,因为我们虽然能保证每个随机生成器的初始 SEED 不一样,但是在这种算法下,无法保证某个随机数生成器的初始 SEED 就是另一个随机数生成器初始 SEED 的下一个(或者很短步骤内的) SEED。举个例子,假设某个随机数生成器的初始 SEED 是 X,另一个是 Z,虽然 X 和 Z 可能看上去差距很大,但是他们在这个算法的随机序列中仅隔了一个 Y。这样的不同的随机数生成器,效果不好。
那么如何能保证不同的随机数生成器之间间隔比较大呢?也就是,我们能通过简单计算(而不是计算 100w 次从而调到 100w 次之后的随机数)直接使另一个随机数生成器的初始 SEED 与当前这个的初始 SEED,间隔一个比较大的数,这种性质叫做可跳跃性。 基于线性反馈移位寄存器算法的 Xoshiro 算法给我们提供了一种可跳跃的随机数算法。
线性反馈移位寄存器算法
线性反馈移位寄存器(Linear feedback shift register,LFSR)是指给定前一状态的输出,将该输出的线性函数再用作输入的移位寄存器。异或运算是最常见的单比特线性函数:对寄存器的某些位进行异或操作后作为输入,再对寄存器中的每个 bit 进行整体移位。
但是如何选择这些 Bit,是一门学问,目前比较常见的实现是 XorShift 算法以及在此基础上进一步优化的
Xoshiro 的相关算法。Xoshiro 算法是一种比较新的优化随机数算法,计算很简单并且性能优异。同时实现了可跳跃性。
这种算法是可跳跃的。假设我们要生成两个差距比较大的随机数生成器,我们可以使用一个随机初始 SEED 创建一个随机数生成器,然后利用算法的跳跃操作,直接生成一个间隔比较大的 SEED 作为另一个随机数生成器的初始 SEED。
还有一点比较有意思的是,线性同余算法并不可逆,我们只能通过 X(n) 推出 X(n + 1),而不能根据 X(n + 1) 直接推出 X(n)。这个操作对应的业务例如随机播放歌单,上一首下一首,我们不需要记录整个歌单,而是仅根据当前的随机数就能知道。线性反馈移位寄存器算法能实现可逆。
线性反馈移位寄存器算法在生成不同的随机序列生成器也有局限性,即它们还是来自于同一个环,即使通过跳跃操作让不同的随机数生成器都间隔开了,但是如果压力不够均衡,随着时间的推移,它们还是有可能 SEED,又变成一样的了。那么有没有那种能生成不同随机序列环的随机算法呢?
DotMix 算法
DotMix 算法提供了另一种思路,即给定一个初始 SEED,设置一个固定步长 M,每次随机,将这个 SEED 加上步长 M,经过一个 HASH 函数,将这个值散列映射到一个 HASH 值:
X(n+1) = HASH(X(n) + M)
这个算法对于 HASH 算法的要求比较高,重点要求 HASH 算法针对输入的一点改变则造成输出大幅度改变。基于 DotMix 算法的 SplitMix 算法使用的即 MurMurHash3 算法,这个即 Java 8 引入的 SplittableRandom 的底层原理。
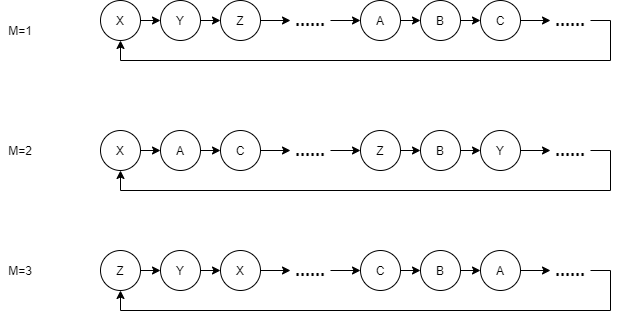
这种算法好在,我们很容易能明确两个不同参数的随机生成器他们的生成序列是不同的,例如一个生成的随机序列是 1,4,3,7,… 另一个生成的是 1,5,3,2。这点正是线性同余算法无法做到的,他的序列无论怎么修改 SEED 也是确定的,而我们有不能随意更改算法中的 A、B、C 的值,因为可能会导致无法遍历到所有数字,这点之前已经说过了。Xoshiro 也是同理。而 SplitMix 算法不用担心,我们指定不同的 SEED 以及不同的步长 M 就可以保证生成的序列是不同的。这种可以生成不同序列的性质,称为可拆分性
这也是 SplittableRandom 比 Random (Random 基于线性同余)更适合多线程的原因:
- 假设多线程使用同一个
Random,保证了序列的随机性,但是有 CompareAndSet 新 seed 的性能损失。 - 假设每个线程使用 SEED 相同的
Random,则每个线程生成的随机序列相同。 - 假设每个线程使用 SEED 不相同的
Random,但是我们不能保证一个Random的 SEED 是否是另一个RandomSEED 的下一个结果(或者是很短步长以内的结果),这种情况下如果线程压力不均匀(线程池在比较闲的时候,其实只有一部分线程在工作,这些线程很可能他们私有的 Random 来到和其他线程同一个 SEED 的位置),某些线程也会有相同的随机序列。
使用 SplittableRandom 只要直接使用接口 split 就能给不同线程分配一个参数不同的 SplittableRandom ,并且参数不同基本就可以保证生成不了相同序列。
思考:我们如何生成 Period 大于生成数字容量的随机序列呢?
最简单的做法,我们将两个 Period 等于容量的序列通过轮询合并在一起,这样就得到了 Period = 容量 + 容量 的序列:
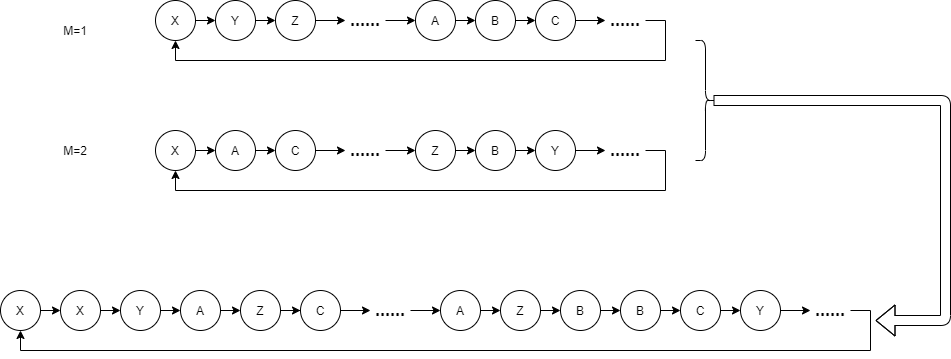
我们还可以直接记录两个序列的结果,然后将两个序列的结果用某种运算,例如异或或者散列操作拼到一起。这样,Period = 容量 * 容量。
如果我们想扩展更多,都可以通过以上办法拼接。用一定的操作拼接不同算法的序列,我们可以得到每种算法的随机优势。 Java 17 引入的 LXM 算法就是一个例子。
LXM 算法
这是在 Java 17 中引入的算法 LXM 算法(L 即线性同余,X 即 Xoshiro,M 即 MurMurHash)的实现较为简单,结合线性同余算法和 Xoshiro 算法,之后通过 MurMurHash 散列,例如:
- L34X64M:即使用一个 32 位的数字保存线性同余的结果,两个 32 位的数字保存 Xoshiro 算法的结果,使用 MurMurHash 散列合并这些结果到一个 64 位数字。
- L128X256M:即使用两个 64 位的数字保存线性同余的结果,4 个 64 位的数字保存 Xoshiro 算法的结果,使用 MurMurHash 散列合并这些结果到一个 64 位数字。
LXM 算法通过 MurMurhash 实现了分割性,没有保留 Xoshiro 的跳跃性。
SEED 的来源
由于 JDK 中所有的随机算法都是基于上一次输入的,如果我们使用固定 SEED 那么生成的随机序列也一定是一样的。这样在安全敏感的场景,不够合适,官方对于 cryptographically secure 的定义是,要求 SEED 必须是不可预知的,产生非确定性输出。
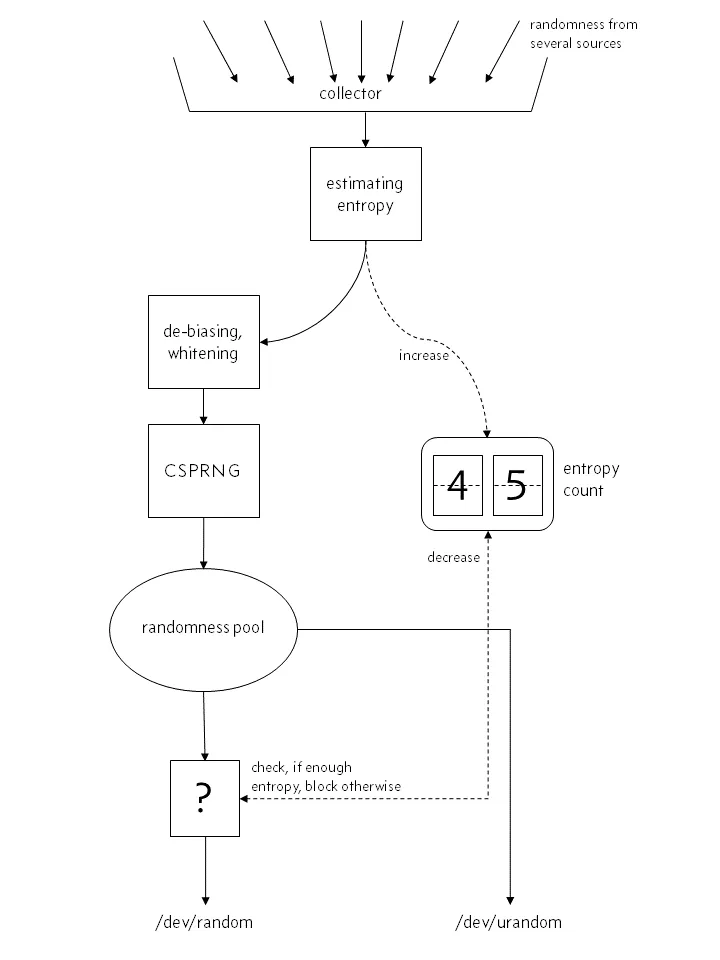
在 Linux 中,会采集用户输入,系统中断等系统运行数据,生成随机种子放入池中,程序可以读取这个池子获取一个随机数。但是这个池子是采集一定数据后才会生成,大小有限,并且它的随机分布肯定不够好,所以我们不能直接用它来做随机数,而是用它来做我们的随机数生成器的种子。这个池子在 Linux 中被抽象为两个文件,这两个文件他们分别是:/dev/random 和 /dev/urandom。一个是必须采集一定熵的数据才放开从池子里面取否则阻塞,另一个则是不管是否采集够直接返回现有的。
在 Linux 4.8 之前:
在 Linux 4.8 之后:
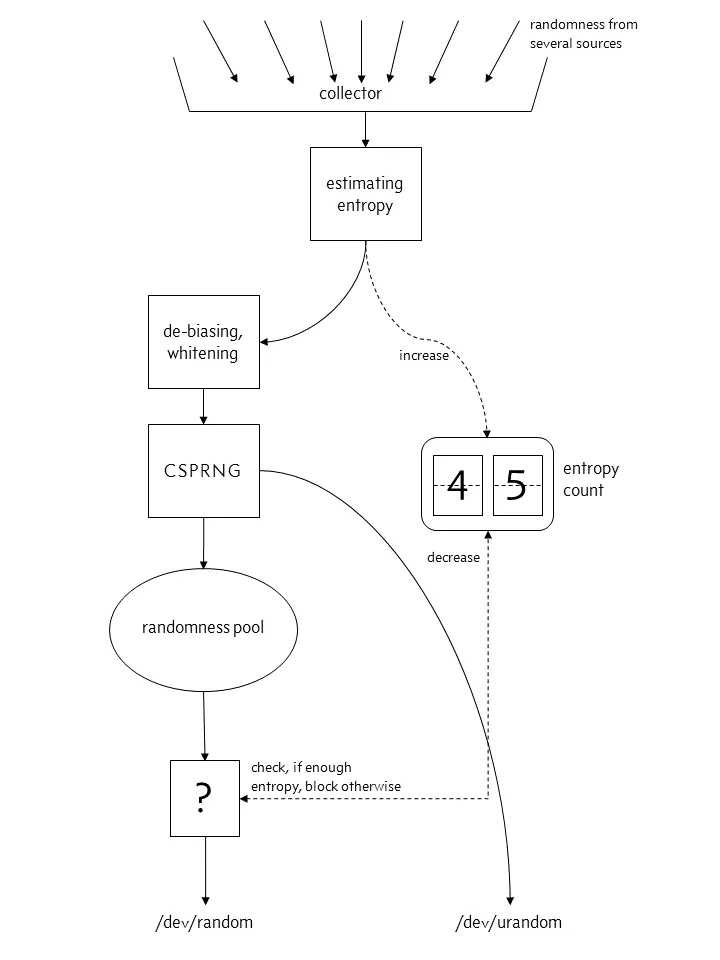
在熵池不够用的时候,file:/dev/random会阻塞,file:/dev/urandom不会。对于我们来说,/dev/urandom 一般就够用,所以一般通过-Djava.security.egd=file:/dev/./urandom设置 JVM 启动参数,使用 urandom 来减少阻塞。
我们也可以通过业务中的一些特性,来定时重新设置所有 Random 的 SEED 来进一步增加被破解的难度,例如,每小时用过去一小时的活跃用户数量 * 下单数量作为新的 SEED。
测试随机算法随机性
以上算法实现的都是伪随机,即当前随机数结果与上一次是强相关的关系。事实上目前基本所有快速的随机算法,都是这样的。
并且就算我们让 SEED 足够隐秘,但是如果我们知道算法,还是可以通过当前的随机输出,推测出下一个随机输出。或者算法未知,但是能从几次随机结果反推出算法从而推出之后的结果。
针对这种伪随机算法,需要验证算法生成的随机数满足一些特性,例如:
- period 尽可能长:a full cycle 或者 period 指的是随机序列将所有可能的随机结果都遍历过一遍,同时结果回到初始 seed 需要的结果个数。这个 period 要尽可能的长一些。
- 平均分布(equidistribution),生成的随机数的每个可能结果,在一个 Period 内要尽可能保证每种结果的出现次数是相同的。否则,会影响在某些业务的使用,例如抽奖这种业务,我们需要保证概率要准。
- 复杂度测试:生成的随机序列是否够复杂,不会有那种有规律的数字序列,例如等比数列,等差数列等等。
- 安全性测试:很难通过比较少的结果反推出这个随机算法。
目前,已经有很多框架工具用来针对某个算法生成的随机序列进行测试,评价随机序列结果,验证算法的随机性,常用的包括:
- testU01 随机性测试:https://github.com/umontreal-simul/TestU01-2009/
- NIST 随机性测试:https://nvlpubs.nist.gov/nistpubs/legacy/sp/nistspecialpublication800-22r1a.pdf
- DieHarder Suite 随机性测试
Java 中内置的随机算法,基本都通过了 testU01 的大部分测试。目前,上面提到过的优化算法都或多或少的暴露出一些随机性问题。目前, Java 17 中的 LXM 算法是随机性测试中表现最好的。注意是随机性表现,而不是性能。
Java 中涉及到的所有随机算法(不包括 SecureRandom)
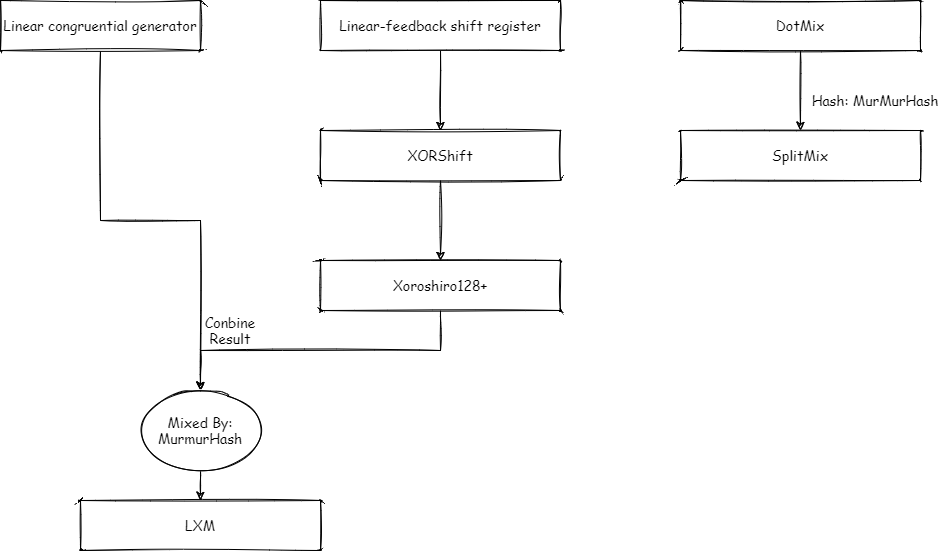
- Linear Congruential generator: https://doi.org/10.1093%2Fcomjnl%2F1.2.83
- Linear-feedback shift register: https://www.ams.org/journals/mcom/1965-19-090/S0025-5718-1965-0184406-1/S0025-5718-1965-0184406-1.pdf
- XORShift: https://doi.org/10.18637%2Fjss.v008.i14
- Xoroshiro128+: https://arxiv.org/abs/1805.01407
- LXM: https://dl.packetstormsecurity.net/papers/general/Google_Chrome_3.0_Beta_Math.random_vulnerability.pdf
- SplitMix: http://gee.cs.oswego.edu/dl/papers/oopsla14.pdf
为什么我们在实际业务应用中很少考虑随机安全性问题
主要因为,我们一般做了负载均衡多实例部署,还有多线程。一般每个线程使用不同初始 SEED 的 Random 实例(例如 ThreadLocalRandom)。并且一个随机敏感业务,例如抽奖,单个用户一般都会限制次数,所以很难采集够足够的结果反推出算法以及下一个结果,而且你还需要和其他用户一起抽。然后,我们一般会限制随机数范围,而不是使用原始的随机数,这就更大大增加了反解的难度。最后,我们也可以定时使用业务的一些实时指标定时设置我们的 SEED,例如:,每小时用过去一小时的(活跃用户数量 * 下单数量)作为新的 SEED。
所以,一般现实业务中,我们很少会用 SecureRandom。如果我们想初始 SEED 让编写程序的人也不能猜出来(时间戳也能猜出来),可以指定随机类的初始 SEED 源,通过 JVM 参数 -Djava.util.secureRandomSeed=true。这个对于所有 Java 中的随机数生成器都有效(例如,Random,SplittableRandom,ThreadLocalRandom 等等)
对应源码:
static {
String sec = VM.getSavedProperty("java.util.secureRandomSeed");
if (Boolean.parseBoolean(sec)) {
//初始 SEED 从 SecureRandom 中取
// SecureRandom 的 SEED 源,在 Linux 中即我们前面提到的环境变量 java.security.egd 指定的 /dev/random 或者 /dev/urandom
byte[] seedBytes = java.security.SecureRandom.getSeed(8);
long s = (long)seedBytes[0] & 0xffL;
for (int i = 1; i < 8; ++i)
s = (s << 8) | ((long)seedBytes[i] & 0xffL);
seeder.set(s);
}
}
所以,针对我们的业务,我们一般只关心算法的性能以及随机性中的平均性,而通过测试的算法,一般随机性都没啥大问题,所以我们只主要关心性能即可。
针对安全性敏感的业务,像是 SSL 加密,生成加密随机散列这种,则需要考虑更高的安全随机性。这时候才考虑使用 SecureRandom。SecureRandom 的实现中,随机算法更加复杂且涉及了一些加密思想,我们这里就不关注这些 Secure 的 Random 的算法了。
Java 17 之前一般如何生成随机数以及对应的随机算法
首先放出算法与实现类的对应关系:
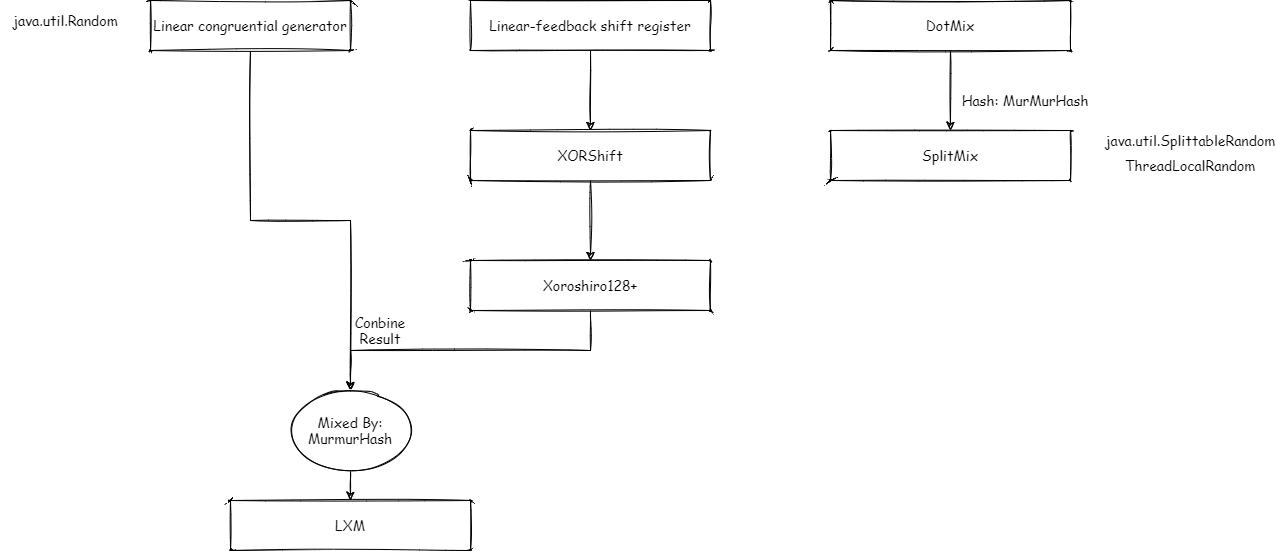
使用 JDK 的 API
1.使用 java.util.Random 和基于它的 API:
Random random = new Random();
random.nextInt();
Math.random() 底层也是基于 Random
java.lang.Math:
public static double random() {
return RandomNumberGeneratorHolder.randomNumberGenerator.nextDouble();
}
private static final class RandomNumberGeneratorHolder {
static final Random randomNumberGenerator = new Random();
}
Random 本身是设计成线程安全的,因为 SEED 是 Atomic 的并且随机只是 CAS 更新这个 SEED:
java.util.Random:
protected int next(int bits) {
long oldseed, nextseed;
AtomicLong seed = this.seed;
do {
oldseed = seed.get();
nextseed = (oldseed * multiplier + addend) & mask;
} while (!seed.compareAndSet(oldseed, nextseed));
return (int)(nextseed >>> (48 - bits));
}
同时也看出,Random 是基于线性同余算法的
2.使用 java.util.SplittableRandom 和基于它的 API
SplittableRandom splittableRandom = new SplittableRandom();
splittableRandom.nextInt();
前面的分析我们提到了,SplittableRandom 基于 SplitMix 算法实现,即给定一个初始 SEED,设置一个固定步长 M,每次随机,将这个 SEED 加上步长 M,经过一个 HASH 函数(这里是 MurMurHash3),将这个值散列映射到一个 HASH 值。
SplittableRandom 本身不是线程安全的:
java.util.SplittableRandom:
public int nextInt() {
return mix32(nextSeed());
}
private long nextSeed() {
//这里非线程安全
return seed += gamma;
}
ThreadLocalRandom 基于 SplittableRandom 实现,我们在多线程环境下使用 ThreadLocalRandom:
ThreadLocalRandom.current().nextInt();
SplittableRandom 可以通过 split 方法返回一个参数全新,随机序列特性差异很大的新的 SplittableRandom,我们可以将他们用于不同的线程生成随机数,这在 parallel Stream 中非常常见:
IntStream.range(0, 1000)
.parallel()
.map(index -> usersService.getUsersByGood(index))
.map(users -> users.get(splittableRandom.split().nextInt(users.size())))
.collect(Collectors.toList());
但是由于没有做对齐性填充以及其他一些多线程性能优化的东西,导致其多线程环境下的性能表现还是比基于 SplittableRandom 的 ThreadLocalRandom 要差。
3. 使用 java.security.SecureRandom 生成安全性更高的随机数
SecureRandom drbg = SecureRandom.getInstance("DRBG");
drbg.nextInt();
一般这种算法,基于加密算法实现,计算更加复杂,性能也比较差,只有安全性非常敏感的业务才会使用,一般业务(例如抽奖)这些是不会使用的。
测试性能
单线程测试:
Benchmark Mode Cnt Score Error Units
TestRandom.testDRBGSecureRandomInt thrpt 50 940907.223 ± 11505.342 ops/s
TestRandom.testDRBGSecureRandomIntWithBound thrpt 50 992789.814 ± 71312.127 ops/s
TestRandom.testRandomInt thrpt 50 106491372.544 ± 8881505.674 ops/s
TestRandom.testRandomIntWithBound thrpt 50 99009878.690 ± 9411874.862 ops/s
TestRandom.testSplittableRandomInt thrpt 50 295631145.320 ± 82211818.950 ops/s
TestRandom.testSplittableRandomIntWithBound thrpt 50 190550282.857 ± 17108994.427 ops/s
TestRandom.testThreadLocalRandomInt thrpt 50 264264886.637 ± 67311258.237 ops/s
TestRandom.testThreadLocalRandomIntWithBound thrpt 50 162884175.411 ± 12127863.560 ops/s
多线程测试:
Benchmark Mode Cnt Score Error Units
TestRandom.testDRBGSecureRandomInt thrpt 50 2492896.096 ± 19410.632 ops/s
TestRandom.testDRBGSecureRandomIntWithBound thrpt 50 2478206.361 ± 111106.563 ops/s
TestRandom.testRandomInt thrpt 50 345345082.968 ± 21717020.450 ops/s
TestRandom.testRandomIntWithBound thrpt 50 300777199.608 ± 17577234.117 ops/s
TestRandom.testSplittableRandomInt thrpt 50 465579146.155 ± 25901118.711 ops/s
TestRandom.testSplittableRandomIntWithBound thrpt 50 344833166.641 ± 30676425.124 ops/s
TestRandom.testThreadLocalRandomInt thrpt 50 647483039.493 ± 120906932.951 ops/s
TestRandom.testThreadLocalRandomIntWithBound thrpt 50 467680021.387 ± 82625535.510 ops/s
结果和我们之前说明的预期基本一致,多线程环境下 ThreadLocalRandom 的性能最好。单线程环境下 SplittableRandom 和 ThreadLocalRandom 基本接近,性能要好于其他的。SecureRandom 和其他的相比性能差了几百倍。
测试代码如下(注意虽然 Random 和 SecureRandom 都是线程安全的,但是为了避免 compareAndSet 带来的性能衰减过多,还是用了 ThreadLocal。):
package prng;
import java.security.NoSuchAlgorithmException;
import java.security.SecureRandom;
import java.util.Random;
import java.util.SplittableRandom;
import java.util.concurrent.ThreadLocalRandom;
import org.openjdk.jmh.annotations.Benchmark;
import org.openjdk.jmh.annotations.BenchmarkMode;
import org.openjdk.jmh.annotations.Fork;
import org.openjdk.jmh.annotations.Measurement;
import org.openjdk.jmh.annotations.Mode;
import org.openjdk.jmh.annotations.Scope;
import org.openjdk.jmh.annotations.State;
import org.openjdk.jmh.annotations.Threads;
import org.openjdk.jmh.annotations.Warmup;
import org.openjdk.jmh.infra.Blackhole;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
//测试指标为吞吐量
@BenchmarkMode(Mode.Throughput)
//需要预热,排除 jit 即时编译以及 JVM 采集各种指标带来的影响,由于我们单次循环很多次,所以预热一次就行
@Warmup(iterations = 1)
//线程个数
@Threads(10)
@Fork(1)
//测试次数,我们测试50次
@Measurement(iterations = 50)
//定义了一个类实例的生命周期,所有测试线程共享一个实例
@State(value = Scope.Benchmark)
public class TestRandom {
ThreadLocal<Random> random = ThreadLocal.withInitial(Random::new);
ThreadLocal<SplittableRandom> splittableRandom = ThreadLocal.withInitial(SplittableRandom::new);
ThreadLocal<SecureRandom> drbg = ThreadLocal.withInitial(() -> {
try {
return SecureRandom.getInstance("DRBG");
}
catch (NoSuchAlgorithmException e) {
throw new IllegalArgumentException(e);
}
});
@Benchmark
public void testRandomInt(Blackhole blackhole) throws Exception {
blackhole.consume(random.get().nextInt());
}
@Benchmark
public void testRandomIntWithBound(Blackhole blackhole) throws Exception {
//注意不取 2^n 这种数字,因为这种数字一般不会作为实际应用的范围,但是底层针对这种数字有优化
blackhole.consume(random.get().nextInt(1, 100));
}
@Benchmark
public void testSplittableRandomInt(Blackhole blackhole) throws Exception {
blackhole.consume(splittableRandom.get().nextInt());
}
@Benchmark
public void testSplittableRandomIntWithBound(Blackhole blackhole) throws Exception {
//注意不取 2^n 这种数字,因为这种数字一般不会作为实际应用的范围,但是底层针对这种数字有优化
blackhole.consume(splittableRandom.get().nextInt(1, 100));
}
@Benchmark
public void testThreadLocalRandomInt(Blackhole blackhole) throws Exception {
blackhole.consume(ThreadLocalRandom.current().nextInt());
}
@Benchmark
public void testThreadLocalRandomIntWithBound(Blackhole blackhole) throws Exception {
//注意不取 2^n 这种数字,因为这种数字一般不会作为实际应用的范围,但是底层针对这种数字有优化
blackhole.consume(ThreadLocalRandom.current().nextInt(1, 100));
}
@Benchmark
public void testDRBGSecureRandomInt(Blackhole blackhole) {
blackhole.consume(drbg.get().nextInt());
}
@Benchmark
public void testDRBGSecureRandomIntWithBound(Blackhole blackhole) {
//注意不取 2^n 这种数字,因为这种数字一般不会作为实际应用的范围,但是底层针对这种数字有优化
blackhole.consume(drbg.get().nextInt(1, 100));
}
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder().include(TestRandom.class.getSimpleName()).build();
new Runner(opt).run();
}
}
微信搜索“我的编程喵”关注公众号,每日一刷,轻松提升技术,斩获各种offer:

最后
以上就是儒雅跳跳糖最近收集整理的关于硬核 - Java 随机数相关 API 的演进与思考(上)如何生成随机数Java 17 之前一般如何生成随机数以及对应的随机算法的全部内容,更多相关硬核内容请搜索靠谱客的其他文章。








发表评论 取消回复