python有道翻译功能简单的爬取
首先点开有道翻译官网,审查元素查看Network一栏,输入翻译内容获取translate信息(真正用到翻译功能的就是这个URL)
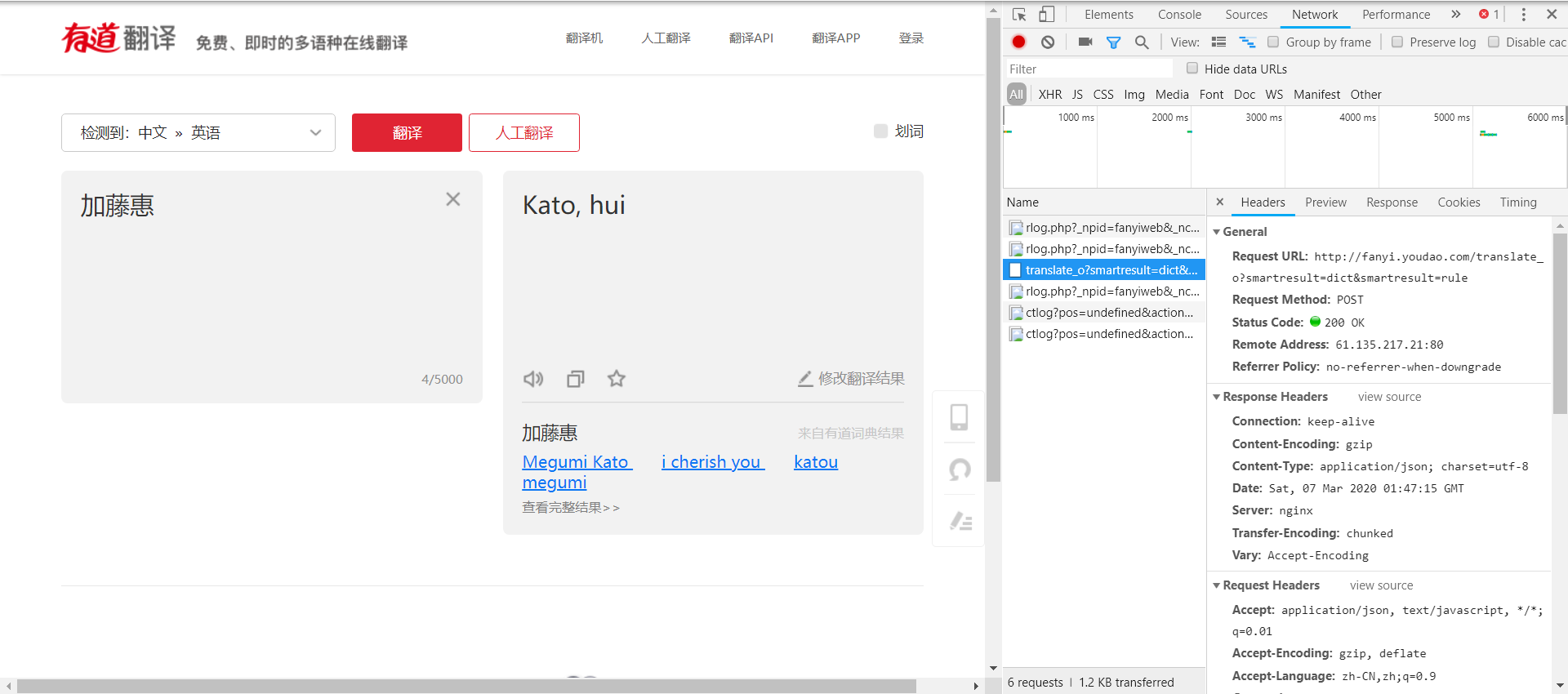
添加headers信息,代码如下
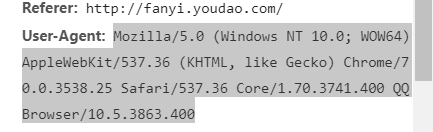
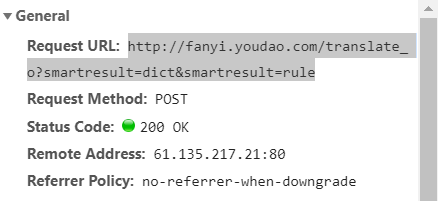
url = 'http://fanyi.youdao.com/translate?_osmartresult=dict&smartresult=rule'
'''head = {}
head['User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3722.400 QQBrowser/10.5.3751.400'
'''
##添加Form Data表单数据到爬虫的字典Data中
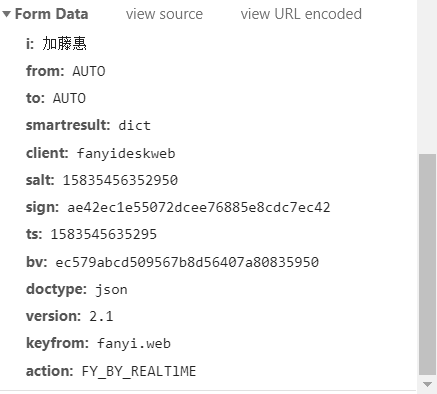
这里有两个参数是变化的,第一个是时间戳,第二个是时间戳+翻译内容返回的加密信息
salt: 15835456352950
sign: ae42ec1e55072dcee76885e8cdc7ec42
这里涉及到网页加密的方法,有很多解决方法,这里采用最简单的方法,删除URL中的_o,可以将对应的这两个参数删除,实现绕过反爬虫机制
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'//将url中的_o删除,以此来删除salt和sign两个参数,来绕过反爬虫
'''head = {}
head['User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3722.400 QQBrowser/10.5.3751.400'
'''
data = {}
data['i'] = content
data['from'] = 'AUTO'
data['to'] = 'AUTO'
data['smartresult'] = 'dict'
data['client'] = 'fanyideskweb'
data['doctype'] = 'json'
data['version'] = '2.1'
data['keyfrom'] = 'fanyi.web'
data['action'] = 'FY_BY_CL1CKBUTTON'
data = urllib.parse.urlencode(data).encode('utf-8')
调用python的urllib库方法,最后加上循环功能实现多次输入
完整代码如下:
import urllib.request
import urllib.parse
import json
import time
while True:
content = input('请输入需要翻译的内容(输入"57K"退出程序):')
if content == '57K':
break
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
'''head = {}
head['User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3722.400 QQBrowser/10.5.3751.400'
'''
data = {}
data['i'] = content
data['from'] = 'AUTO'
data['to'] = 'AUTO'
data['smartresult'] = 'dict'
data['client'] = 'fanyideskweb'
data['doctype'] = 'json'
data['version'] = '2.1'
data['keyfrom'] = 'fanyi.web'
data['action'] = 'FY_BY_CL1CKBUTTON'
data = urllib.parse.urlencode(data).encode('utf-8')
request = urllib.request.Request(url,data,)
request.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3722.400 QQBrowser/10.5.3751.400')
response = urllib.request.urlopen(request)
html = response.read().decode('utf-8')
target = json.loads(html)
print("翻译结果是:%s" % (target['translateResult'][0][0]['tgt']))
time.sleep(1)
实现界面如下
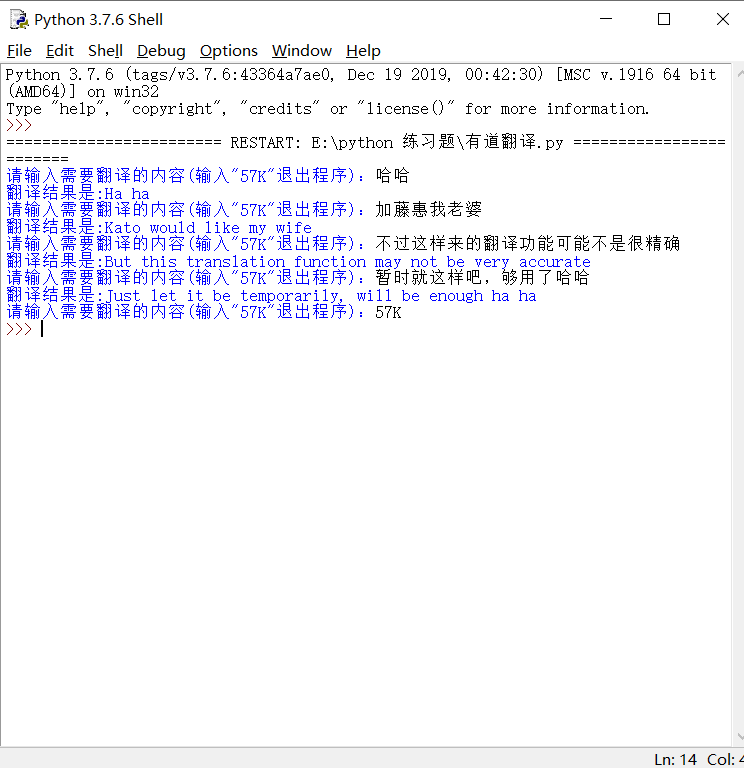
最后
以上就是细腻雨最近收集整理的关于使用Python爬取简单的有道翻译功能的全部内容,更多相关使用Python爬取简单内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复