JPA数据批量存储
一、测试环境准备
1、测试工程搭建
测试工程为 springboot
测试表结构

2、测试结果验证工具
阿里的 Druid 数据库连接池sql监控功能

3、配置文件
druid 配置:
@Bean
public ServletRegistrationBean statViewServlet() {
// 创建servlet注册实体
ServletRegistrationBean servletRegistrationBean = new ServletRegistrationBean(new StatViewServlet(),
"/druid/*");
// 设置ip白名单
servletRegistrationBean.addInitParameter("allow", "127.0.0.1");
// 设置ip黑名单,如果allow与deny共同存在时,deny优先于allow
servletRegistrationBean.addInitParameter("deny", "192.168.0.1");
// 设置控制台管理用户
servletRegistrationBean.addInitParameter("loginUsername", "admin");
servletRegistrationBean.addInitParameter("loginPassword", "123456");
// 是否可以重置数据
servletRegistrationBean.addInitParameter("resetEnable", "false");
return servletRegistrationBean;
}
@Bean
public FilterRegistrationBean statFilter() {
// 创建过滤器
FilterRegistrationBean filterRegistrationBean = new FilterRegistrationBean(new WebStatFilter());
// 设置过滤器过滤路径
filterRegistrationBean.addUrlPatterns("/*");
// 忽略过滤的形式
filterRegistrationBean.addInitParameter("exclusions", "*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*");
return filterRegistrationBean;
}
jpa数据源配置
spring:
datasource:
url: 数据库地址
username: 账号
password: 密码
driver-class-name: com.mysql.jdbc.Driver
platform: mysql
type: com.alibaba.druid.pool.DruidDataSource
# 下面为连接池的补充设置,应用到上面所有数据源中
# 初始化大小,最小,最大
initialSize: 1
minIdle: 3
maxActive: 20
# 配置获取连接等待超时的时间
maxWait: 60000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
timeBetweenEvictionRunsMillis: 60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
minEvictableIdleTimeMillis: 30000
validationQuery: select 'x'
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
# 打开PSCache,并且指定每个连接上PSCache的大小
poolPreparedStatements: true
maxPoolPreparedStatementPerConnectionSize: 20
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
filters: stat,wall,log4j
# 通过connectProperties属性来打开mergeSql功能;慢SQL记录
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
# 合并多个DruidDataSource的监控数据
#useGlobalDataSourceStat: true
jpa:
# 配置 DBMS 类型
database: MYSQL
# 配置是否将执行的 SQL 输出到日志
show-sql: true
properties:
hibernate:
hbm2ddl:
# 配置开启自动更新表结构
auto: update
# 批次处理参数
order_inserts: true
order_updates: true
generate_statistics: true 生成统计信息
jdbc.batch_size: 4 开启批次储存,一批次储存量为10,如有100条数据则储存十次
具体大小视情况而定
二、测试
1、测试代码
public void get() {
// 生成四个测试对象
User user1 = new User();
user1.setId(44L);
user1.setName("44");
User user2 = new User();
user2.setId(55L);
user2.setName("55");
User user3 = new User();
user3.setId(66L);
user3.setName("66");
User user4 = new User();
user4.setId(77L);
user4.setName("77");
List<User> users = new ArrayList<>();
users.add(user1);
users.add(user2);
users.add(user3);
users.add(user4);
// 批次量存储 此时批次配置文件 jdbc.batch_size: 4 sql应执行一次
userDao.saveAll(users);
}
2、执行测试代码
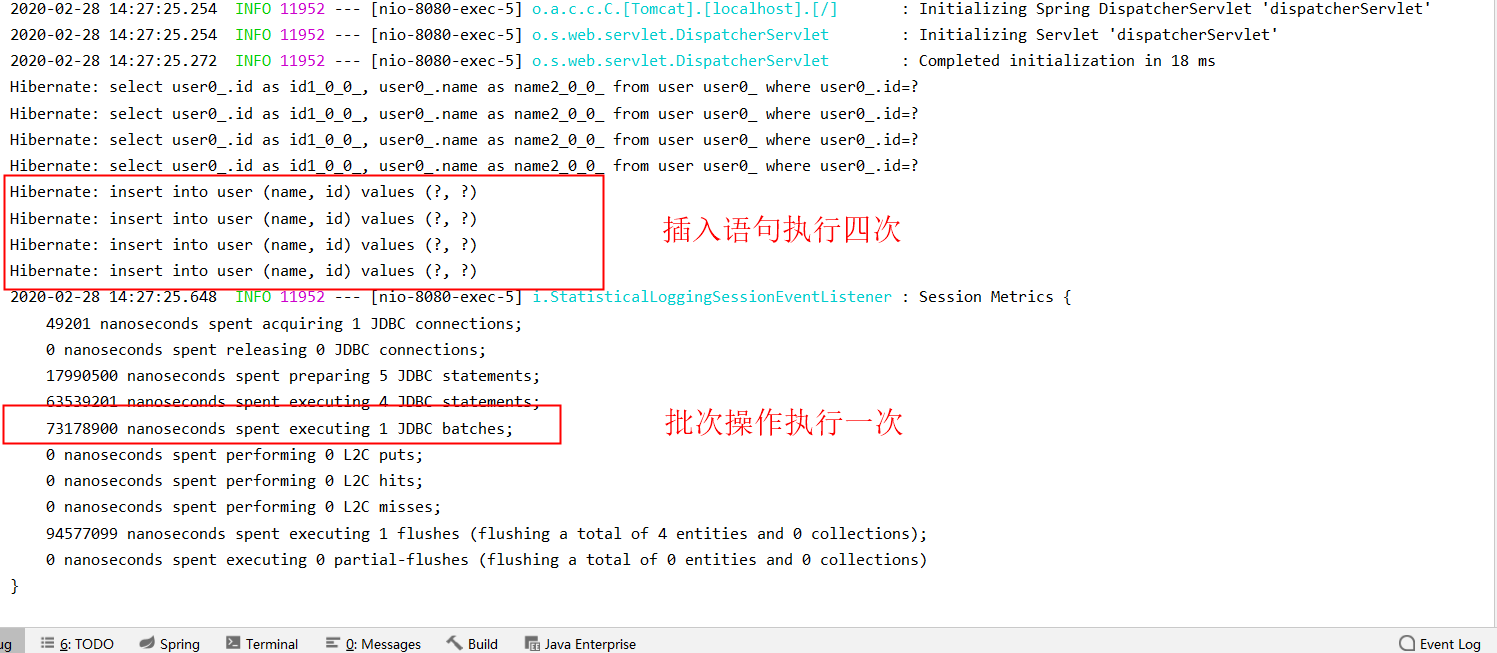
此时控制台输出信息、已经开启批次插入,应当生成一条sql才对。但是根据generate_statistics输出信息看批次操作是执行了一次,此处可能为日志打印问题。此时可以根据druid sql监控查看sql执行情况判断。
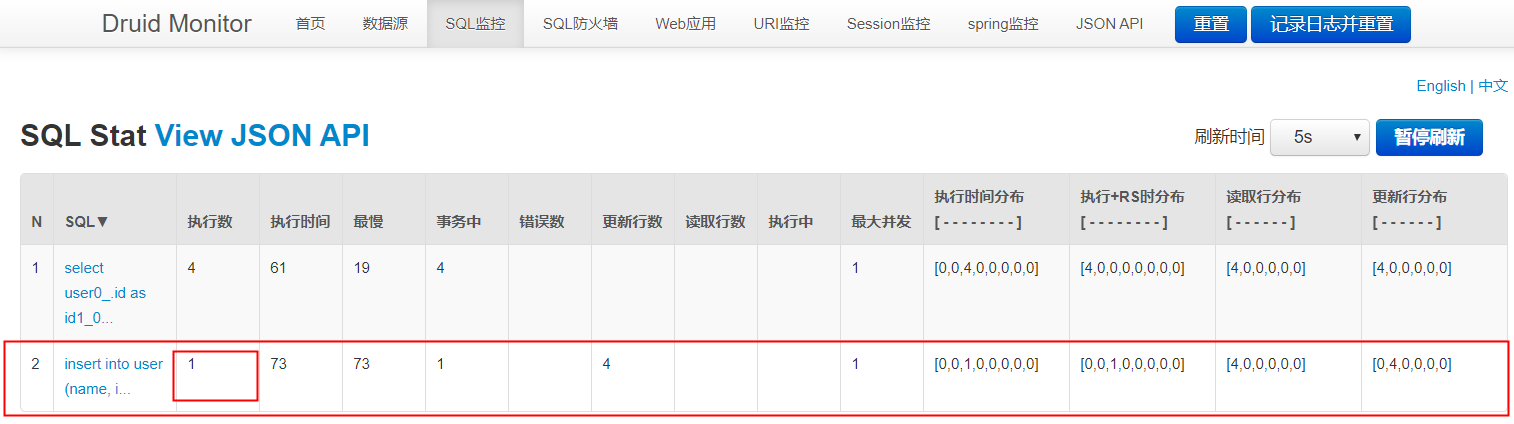
可以看到插入语句确实执行一次,查看数据库存储情况,也没有问题

3、更改配置信息再次测试
此处测试数据依旧是四条,批次配置信息更改为 jdbc.batch_size: 2 四条需两次插入
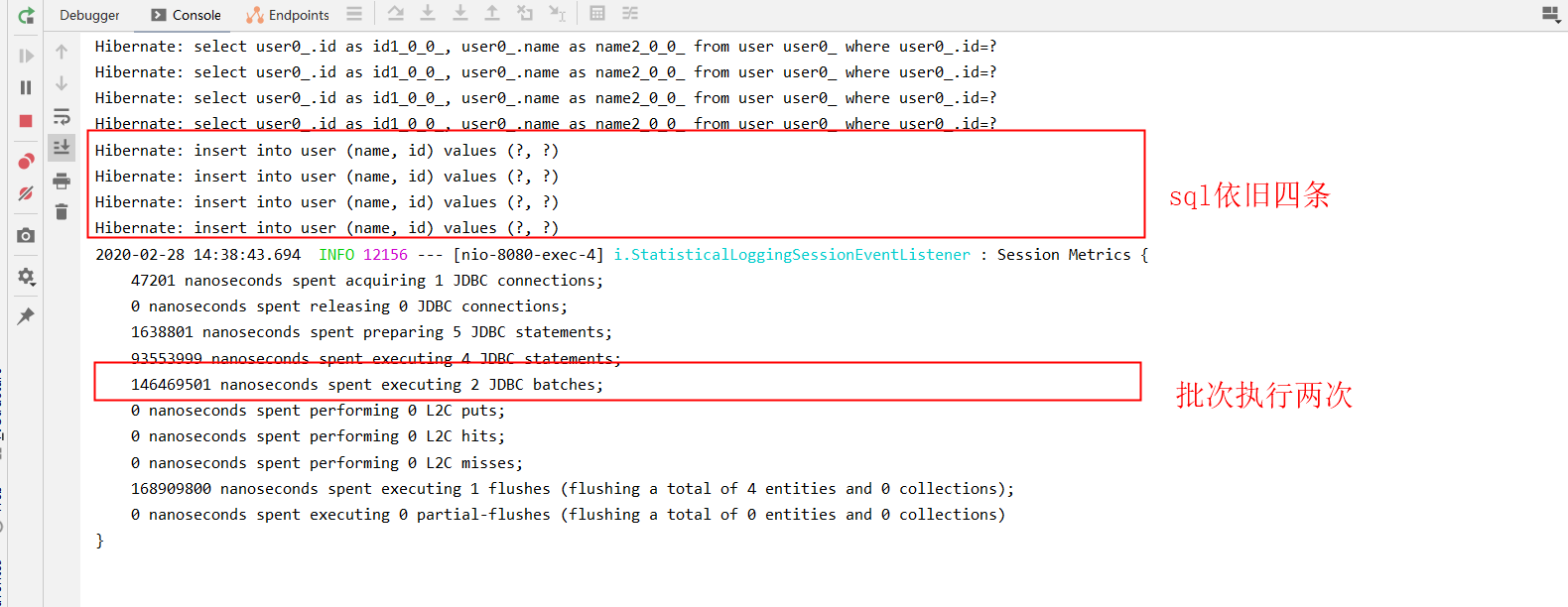
此时sql打印依旧为四次,但generate_statistics输出信息批次操作为两次

druid sql监控执行次数为两次
三、总结
关键配置
order_inserts: true
order_updates: true
generate_statistics: true 生成统计信息
jdbc.batch_size: 4 开启批次储存,一批次储存量为10,如有100条数据则储存十次
具体大小视情况而定
工程下载地址:https://download.csdn.net/download/qq_37813031/12198290
最后
以上就是幸福小霸王最近收集整理的关于记JPA数据批量存储JPA数据批量存储的全部内容,更多相关记JPA数据批量存储JPA数据批量存储内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复