强化学习相关的Sarsa算法的介绍。此处笔记根据B站课程,王树森老师的强化学习记录而来。7.Sarsa算法 (TD Learning 1_3)(Av374239425,P7)_哔哩哔哩_bilibili
Sarsa算法是TD算法的一种,名字来源于 需要观测的五元组(s(t), a(t), r(t), s(t+1), a(t+1)),即 State-Action-Reward-State-Action ,简称SARSA
1.TD target的推导
U(t)是折扣回报率,根据下面的推导,可以得到U(t)=R(t)+γ*U(t+1), 反映两个相邻回报之间的关系。
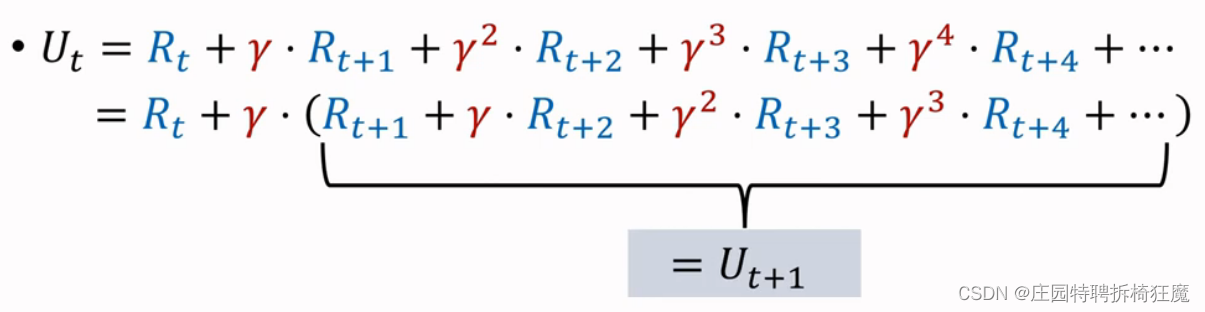
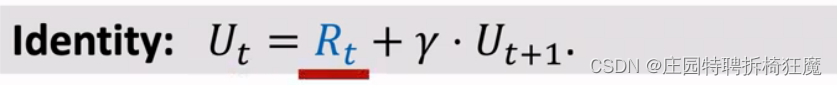 假设R(t)依赖于(S(t), A(t), S(t+1))
假设R(t)依赖于(S(t), A(t), S(t+1))
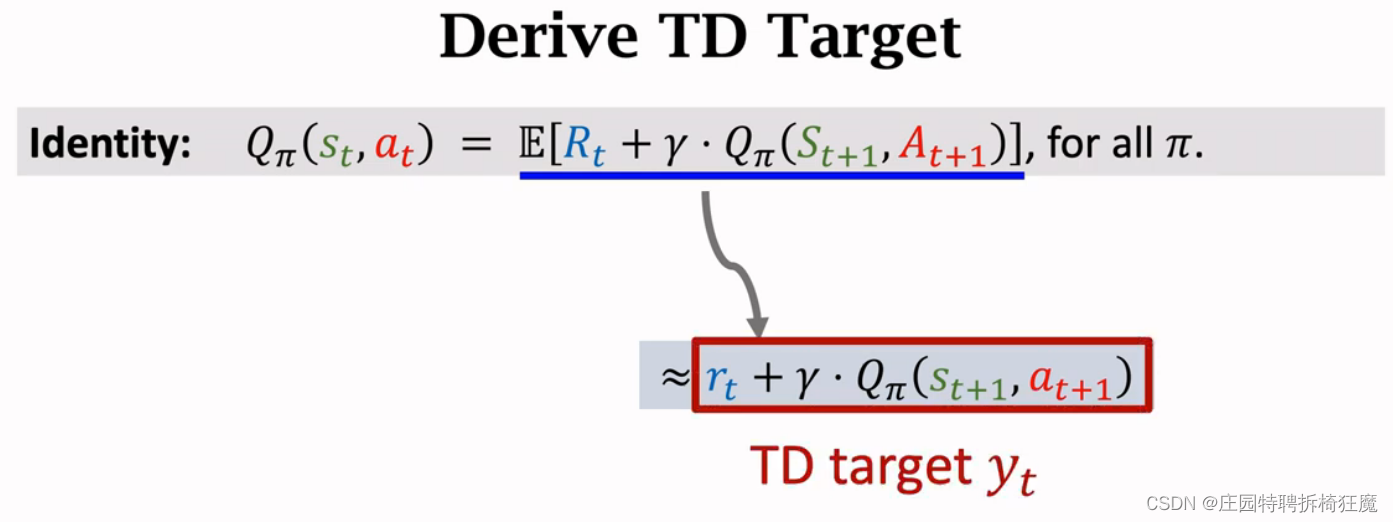
QΠ(s(t),a(t))=E(U(t)|s(t),u(t)) 是U(t)的的期望,根据下面的推导可以得到下面的公式。
 QΠ可以用r(t)+γ*QΠ(s(t+1),a(t+1)),其中QΠ是估计值,r(t)+γ*QΠ(s(t+1),a(t+1))是TD target y^,r(t)是观测到的奖励,QΠ(s(t+1),a(t+1))是QΠ的预测。r(t)+γ*QΠ(s(t+1),a(t+1))比QΠ更加贴近真实值。
QΠ可以用r(t)+γ*QΠ(s(t+1),a(t+1)),其中QΠ是估计值,r(t)+γ*QΠ(s(t+1),a(t+1))是TD target y^,r(t)是观测到的奖励,QΠ(s(t+1),a(t+1))是QΠ的预测。r(t)+γ*QΠ(s(t+1),a(t+1))比QΠ更加贴近真实值。

2.表格型的SARSA: Tabular Version
适用于状态s和动作a有限的情况,绘制如下所示的表格,每个单元格表示对应动作的价值,用saras算法每次更新一个单元格。观测值( s(t), a(t), r(t), s(t+1)),根据Π(.|s(t+1))搜集抽样动作a(t+1),计算TD target y^,计算误差,更新。使QΠ逐渐接近真实值。


3.网络型SARSA: Sarsa Neural Network Version
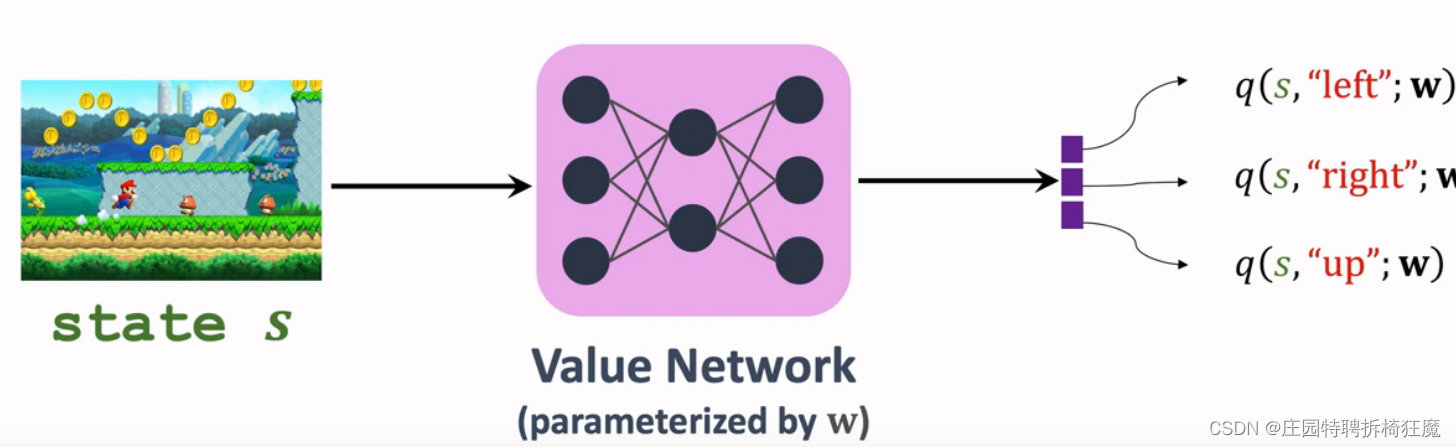
使用神经网络近似,适用于状态s和动作a过多,无法使用表格的情况。需要训练一个价值网络q(s,a;w)近似QΠ(s,a),网络q随机初始化,学习参数w,根据观测到的reward,使用梯度下降更新w.

 Summary:
Summary:

最后
以上就是寂寞春天最近收集整理的关于【Saras算法】TD Learning的一种1.TD target的推导2.表格型的SARSA: Tabular Version3.网络型SARSA: Sarsa Neural Network Version Summary:的全部内容,更多相关【Saras算法】TD内容请搜索靠谱客的其他文章。








发表评论 取消回复