我在今年6月份参加了百度的强化学习7日打卡营。我把这几天来的学习简要总结一下。
强化学习(RL)分为两部分:agent、enviroment,有三要素:state、action、reward。RL应用于游戏、机器人、推荐、金融、交通等领域。监督学习处理认知问题,强化学习处理决策问题。强化学习有两种学习方案:基于价值(value-based)、基于策略(policy-based)。强化学习环境有算法库PARL和环境库GYM。
Sarsa全称是state-action-reward-state'-action',目的是学习特定的state下,特定action的价值Q,最终建立和优化一个Q表格,以state为行,action为列,根据与环境交互得到的reward来更新Q表格,更新公式为:
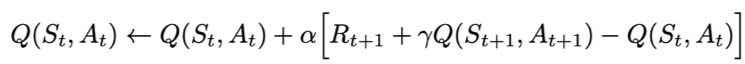
Sarsa在训练中为了更好的探索环境,采用ε-greedy方式来训练,有一定概率随机选择动作输出。
Q-learning也是采用Q表格的方式存储Q值(状态动作价值),决策部分与Sarsa是一样的,采用ε-greedy方式增加探索。Q-learning跟Sarsa不一样的地方是更新Q表格的方式。Sarsa是on-policy的更新方式,先做出动作再更新。Q-learning是off-policy的更新方式,更新learn()时无需获取下一步实际做出的动作next_action,并假设下一步动作是取最大Q值的动作。
Q-learning的更新公式为:
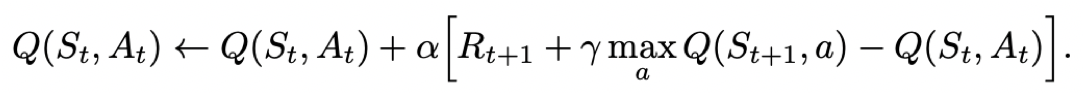
DQN使用神经网络来近似替代Q表格。本质上DQN还是一个Q-learning算法,同样的也采用ε-greedy方法训练。在Q-learning的基础上,DQN提出了两个技巧使得Q网络的更新迭代更稳定。经验回放 Experience Replay:主要解决样本关联性和利用效率的问题。使用一个经验池存储多条经验s,a,r,s',再从中随机抽取一批数据送去训练。固定Q目标 Fixed-Q-Target:主要解决算法训练不稳定的问题。复制一个和原来Q网络结构一样的Target Q网络,用于计算Q目标值。
在强化学习中,有两大类方法,一种基于值(Value-based),一种基于策略(Policy-based)
Value-based的算法的典型代表为Q-learning和SARSA,将Q函数优化到最优,再根据Q函数取最优策略。
Policy-based的算法的典型代表为Policy Gradient,直接优化策略函数。
采用神经网络拟合策略函数,需计算策略梯度用于优化策略网络。
优化的目标是在策略π(s,a)的期望回报:所有的轨迹获得的回报R与对应的轨迹发生概率p的加权和,当N足够大时,可通过采样N个Episode求平均的方式近似表达。

优化目标对参数θ求导后得到策略梯度:
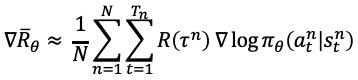
DDPG(Deep Deterministic Policy Gradient)是DQN的扩展版,借鉴了DQN的技巧,可以扩展到连续控制动作空间。
最后
以上就是淡淡小甜瓜最近收集整理的关于强化学习7日打卡营-学习小结的全部内容,更多相关强化学习7日打卡营-学习小结内容请搜索靠谱客的其他文章。








发表评论 取消回复