算法思想:
Q学习是一种强化学习算法,Q即为Q(s,a),在状态s下,选择一个动作a,执行后能获得的最大回报,环境会根据a的动作来反馈相应的奖赏
公式:
Q(s,a)←Q(s,a)+α[r+γargmaxa′Q(s′,a′)−Q(s,a)]
实例:
import numpy as np
import random
Q = np.zeros((6, 6))
Q = np.matrix(Q)
# 回报矩阵
R = np.matrix([[-1, -1, -1, -1, 0, -1],
[-1, -1, -1, 0, -1, 100],
[-1, -1, -1, 0, -1, -1],
[-1, 0, 0, -1, 0, -1],
[0, -1, -1, 0, -1, 100],
[-1, 0, -1, -1, 0, 100]])
γ = 0.9
for i in range(3000):
state = random.randint(0, 5)
while True:
# 选择当前状态下的可能动作
r_pos_action = []
for action in range(6):
if R[state, action] >= 0:
r_pos_action.append(action)
next_state = r_pos_action[random.randint(0, len(r_pos_action) - 1)]
Q[state, next_state] = R[state, next_state] + γ * (Q[next_state]).max() # 更新
state = next_state
if state == 5:
break
print(Q)执行结果:
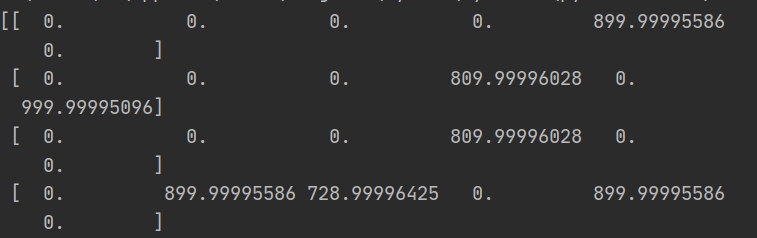
最后
以上就是安静机器猫最近收集整理的关于初识Q学习的全部内容,更多相关初识Q学习内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复