文章目录
- 1 字符编码
- 2 为什么需要字符编码
- 3 字节,字符,字符串
- 4 进程间的字符信息流动
- 5 Java 与 Unicode
- 6 Python 与 Unicode
1 字符编码
1、ASCII & ANSI:
字符码(charcter code)指的是用来代表字符的编码。读者在输入和存储文档时都要使用字符编码。
ASCII 码(单字节): 能够支持256个字符编码.
ANSI(双字节): 能够支持65000个字符编码,中文简体编码 GB2312 实际上是 ANSI 的一个代码页,不同的代码页的内码无法再其他代码中正常显示,日中文/繁体中文/简体中文使用了不同的代码页,
2、Unicode:
Unicode 也是一种字符编码方法,它是由国际组织设计,能够容纳全世界全部语言文字的编码方案。其中 UTF-16 和 Unicode 编码大致一样, UTF-8 为了节省存储空间,以 8 位为单元对 Unicode 进行编码。
BOM (byte order mark) 出现在文本文件的头部,unicode 编码中用 BOM 来标识文件采用哪种格式的编码,UTF-8 的 BOM 编码是 EF BB BF。
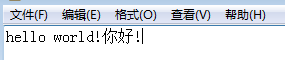
下面是使用 Binary Viewer 工具查看不同编码的文本文件,其内容为’hello world!你好!’:
utf-8

ansi

2 为什么需要字符编码
字符编码主要是为了实现字符信息(文本)在计算机系统中的存储与传输:
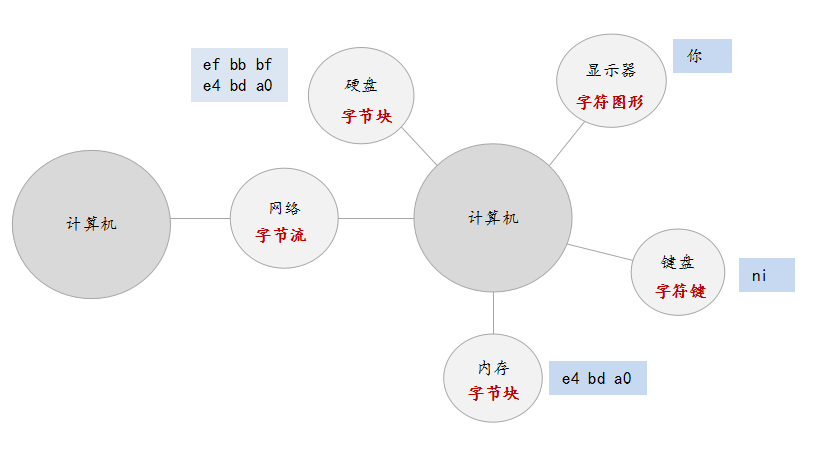
字符,不管是中文字符还是英文字符,在计算机系统中都是以字节的形式来存储的,比如保存了 hello world!你好! 的 txt 文件,指定文件为 utf-8 格式,那么在硬盘中存储的信息是 EF BB BF 68 65 6C 6C 6F 20 77 6F 72 6C 64 21 20 10 77 6F 72 6C 64 21。当我们用记事本(本质上是一个程序)打开 txt 文件,记事本会根据编码识别相应的字符,然后在记事本的内容区域显示字符对应的图形。
字符图形可以是矢量图,也可以是位图。
3 字节,字符,字符串
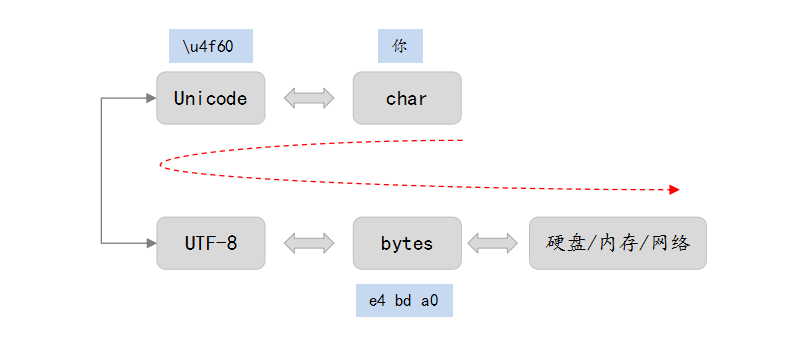
Unicode(统一码、万国码、单一码)是一套由国际组织制定的可以容纳世界上所有文字和符号的字符编码方案,可以理解为是一套规范,而不是具体的实现方案。UTF-8/UTF-16/UTF-32 是具体的将文本信息进行存储或传输的编码实现方案。
| 概念 | 层次 | 特征 |
|---|---|---|
| 字符/字符串 | 视图层/应用层 | 可读写,可理解,矢量图或位图显示 |
| Unicode | 逻辑层、语言层 | 统一性,一致性 |
| utf-8,utf-16,gbk | 物理层:内存,磁盘,网络 | 面向存储 |
特别需要注意的是 Unicode 是逻辑意义上的编码,每个字符都有自己的 Unicode 码,在程序中可以通过 u4f60 的形式来表示,与字节流无关!!!而 utf-8 才是 Unicode 在物理层的一种编码方案,对应特定的字节流。
4 进程间的字符信息流动
字符信息是如何通过键盘输入到计算机中,进而保存到磁盘上的呢?
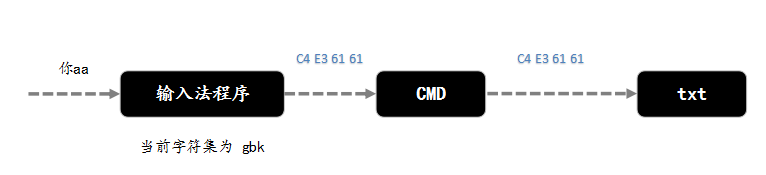
首先,打开 cmd,然后输入 echo 你aa >> a.txt。
由上图所示,当输入字符串 你aa 时,输入法程序会根据当前的本地字符集进行编码,然后作为输出给 CMD 程序,字节流为 C4 E3 61 61,然后 cmd 将字节流输出到磁盘文件 a.txt 中,通过 binary viewer 可以查看对应的编码为 C4 E3 61 61。
通过 chcp [code_page] 可以修改本地字符集,以下是几种常用的编码:
936 GBK(一般情况下为默认编码)
437 美国英语
65001 utf-8
执行 chcp 65001 将字符集更改为 utf-8,在标题栏点击右键, 打开属性面板, 会看到”选项”标签页下方显示”当前代码页”的编码. 然后选择”字体”标签页, 把字体设置为Lucia Console。
执行 echo 你aa >> b.txt,通过binary viewer 查看文件编码为 E4 BD A0 61 61
可以通过 ultra edit 将 gbk 文件转存为 utf-8 文件。
常见 ASCII 码:
OD OA = rn
20 = 空格
另外一个特别需要注意的地方:
windows 平台的 utf-8 文件总是会添加 bom 头,造成在其他编辑器中显示为乱码,比如 vs code。
5 Java 与 Unicode
char 是 Java 的基本类型(原类型) ,默认字符集为 utf-8。多个字符的序列可以是字符数组(mutable),也可以字符串(immutable)。
char 与 byte 是不同的,byte 是数据存储的基本单元,任何数据信息,比如对象,图片,程序,最终都是以 byte 的形式来存储(分为大端、小端)的。char 是字符,同一字符的不同字符编码对应的 byte 流是不一样的。
在 Java 中使用 InputStream/OutputStream 来读写字节(byte)流,使用 Reader/Writer 来读写字符(char)流。
| byte | char |
|---|---|
| DataInputStream/DataOutputStream | FileReader/FileWriter |
| ObjectInputStream/ObjectInputStream | StringReader/StringWriter |
| FileInputStream/FileOutputStream |
class HelloChar{
public static void main(String[] args) {
String s = String.valueOf(new char[]{'你', '好'});
System.out.println(s); // 你好
char c = '你';
char ni = 'u4f60'; // 你
char hao = (char)0x597d; // 好
System.out.println(c); // 你
byte[] b = s.getBytes();
bytes2HexString(b); // E4BDA0E5A5BD
}
public static void bytes2HexString(byte[] b) {
String ret = "";
for (int i = 0; i < b.length; i++) {
String hex = Integer.toHexString(b[ i ] & 0xFF);
if (hex.length() == 1) {
hex = '0' + hex;
}
ret += hex.toUpperCase();
}
System.out.print(ret);
}
}
文本文件 b.txt 内容为 u4f60u597d:
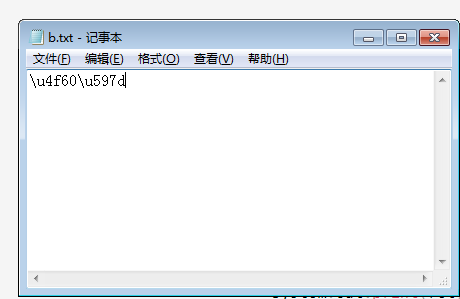
通过 Java 代码将 Unicode 与字符串进行转换:
public class unicode {
public static void main(String[] args) {
BufferedReader br = new BufferedReader(new FileReader(new File("b.txt")));
String unicodeStr = br.readLine(); // "\u4f60\u597d"
String str = unicodeToString(unicodeStr); // "你好"
String unicode = stringToUnicode(str); // "\u4f60\u597d"
}
//字符串转换unicode
public static String stringToUnicode(String string) {
StringBuffer unicode = new StringBuffer();
for (int i = 0; i < string.length(); i++) {
char c = string.charAt(i); // 取出每一个字符
unicode.append("\u" +Integer.toHexString(c));// 转换为unicode
}
return unicode.toString();
}
//unicode 转字符串
public static String unicodeToString(String unicode) {
StringBuffer string = new StringBuffer();
String[] hex = unicode.split("\\u");
for (int i = 1; i < hex.length; i++) {
int data = Integer.parseInt(hex[i], 16);// 转换出每一个代码点
string.append((char) data);// 追加成string
}
return string.toString();
}
}
6 Python 与 Unicode
Python 没有 char 类型,一个字符等同于长度为 1 的字符串,字符串与字节流的转换形式更简洁:
s = "hello world!你好!" # 默认为 utf-8
ni = 'u4f60' # '你' 的 unicode
ni2 = chr(0x4f60) # '你' 的 unicode 码十六进制整数转字符
# 方法 1
bytes(ni, encoding='utf-8') # xe4xbdxa0
u = bytes(s, encoding='utf-8') # b'hello world!xe4xbdxa0xe5xa5xbd!'
g = bytes(s, encoding='gb2312') # b'hello world!xc4xe3xbaxc3!'
# 方法 2
u2 = s.encode('utf-8')
g2 = s.encode('gb2312')
str(u, encoding='utf-8') # "hello world!你好!"
str(g, encoding='gb2312') # "hello world!你好!"
最后
以上就是认真发夹最近收集整理的关于深入理解——字节、字符/字符串、Unicode 字符集的全部内容,更多相关深入理解——字节、字符/字符串、Unicode内容请搜索靠谱客的其他文章。
![关于char[]、const char[]、const char *](https://www.shuijiaxian.com/files_image/reation/bcimg2.png)

![为什么需要public static void main(String[] args)这个方法?](https://www.shuijiaxian.com/files_image/reation/bcimg4.png)





发表评论 取消回复