Q Learning是一种很好的方法,但是q learning很难处理连续动作的情况。因为q学习是基于值得,如果动作连续,q表太大,则很难计算。

但是凡是问题都有解决的方法,如何解决Q Learning难以应对连续动作得问题呢!
解决方法一:在连续得动作中,我们sample采样出一部分n个,将其变成有限动作的问题。但是这种方法的缺点就是采样不完整,可能会造成以后的问题
解决方法二:我们用梯度增加的方法来使Q值变大,梯度上升,更新参数,但是这样做的缺点使计算量过大。
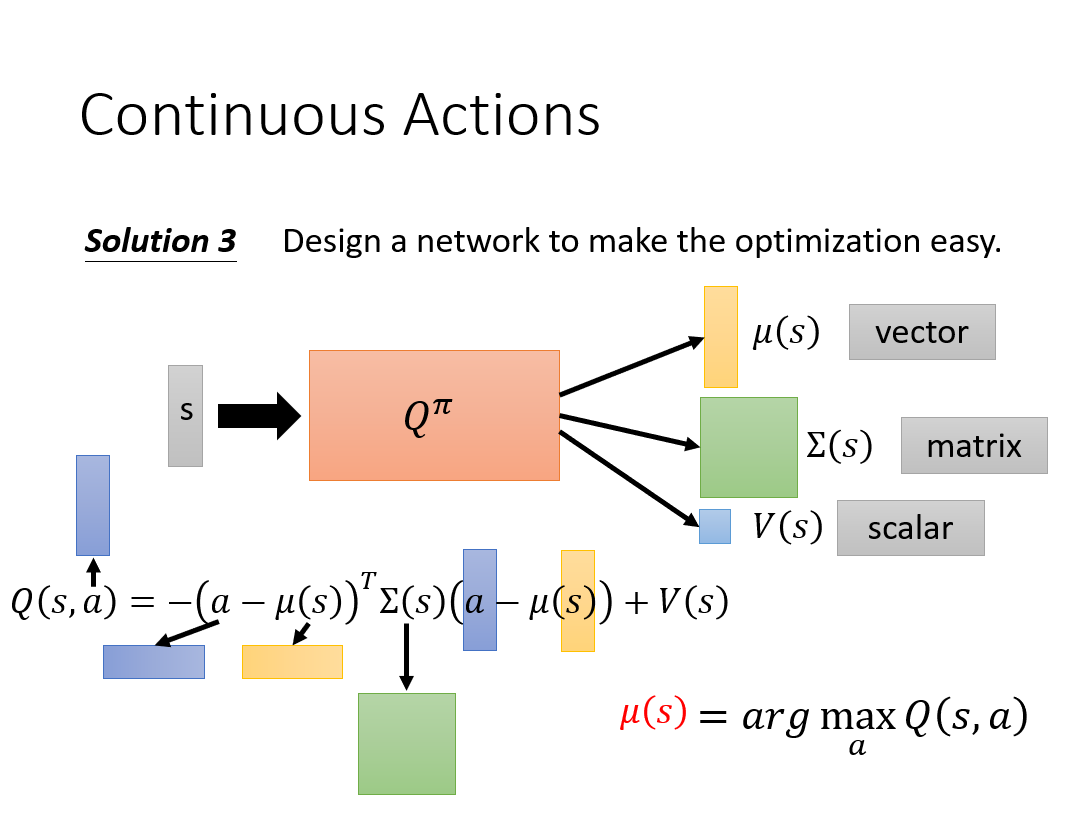
第三种解决方法:我么设计一个神经网络,可以有三个输出μ(s),Σ(s),V(s),再用矩阵运算的方法将他们算到一起
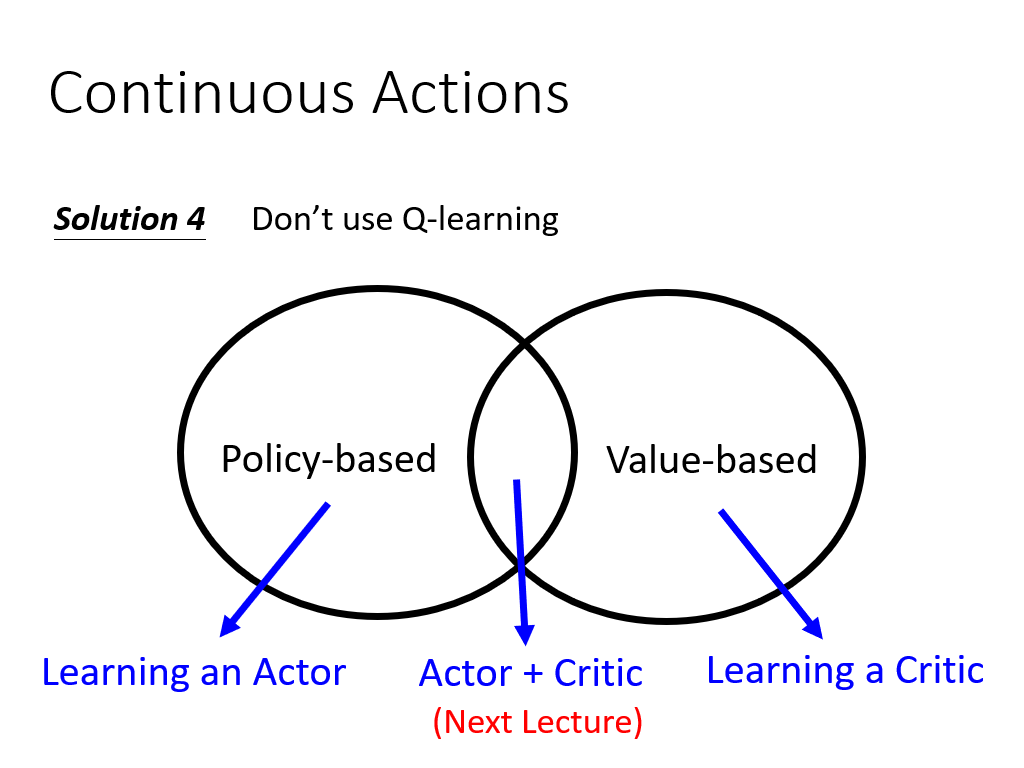
第四种方法,就是不适用Q Learning,还会有别的方法来解决连续动作的问题。
最后
以上就是漂亮钥匙最近收集整理的关于【李弘毅深度强化学习】 5.Q-learning (Continuous Action)的全部内容,更多相关【李弘毅深度强化学习】内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。

![[密码学基础][每个信息安全博士生应该知道的52件事][Bristol Cryptography][第19篇]Shamir密钥交换场景](https://www.shuijiaxian.com/files_image/reation/bcimg23.png)






发表评论 取消回复