DPG、DDPG
- 一、DPG算法新理解
- 1、确定性策略
- 2、与随机策略梯度的区别
- 二、DDPG(Deep Deterministic Policy Gradient)算法
- 三、DDPG算法流程
- 四、DDPG算法新理解
- 1、与DPG的不同之处
- 2、与DQN不同
- 3、有几个关键点
- 五、额外收获
- 1、重要性采样
- 参考链接:
越往后面学感觉越陌生,极度怀疑自己之前到底看过这些算法没有。举步维艰啊!
Paper:
DPG:Deterministic policy gradient algorithms
DDPG:Continuous Control with Deep Reinforcement Learning
Github:https://github.com/xiaochus/Deep-Reinforcement-Learning-Practice
一、DPG算法新理解
这种算法主要应用于off-policy(on-policy也适用)
1、确定性策略
确定性策略:在状态St时,每次采取的动作都是一个确定的action,
a
=
μ
(
s
)
a=mu(s)
a=μ(s);
随机策略:在状态St时,每次采取的动作很可能不一样,随机选择动作,
π
(
a
∣
s
)
=
P
(
a
∣
s
)
pi(a|s)=P(a|s)
π(a∣s)=P(a∣s) 。
2、与随机策略梯度的区别
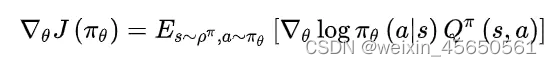
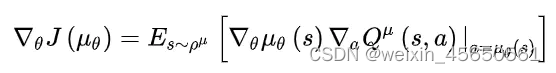
从梯度更新的公式上来看:确定性策略少了对action的积分,多了reward对action的导数。
这个不同造就了确定性策略相比于随机策略在高维动作空间的时候更容易训练。
二、DDPG(Deep Deterministic Policy Gradient)算法

三、DDPG算法流程
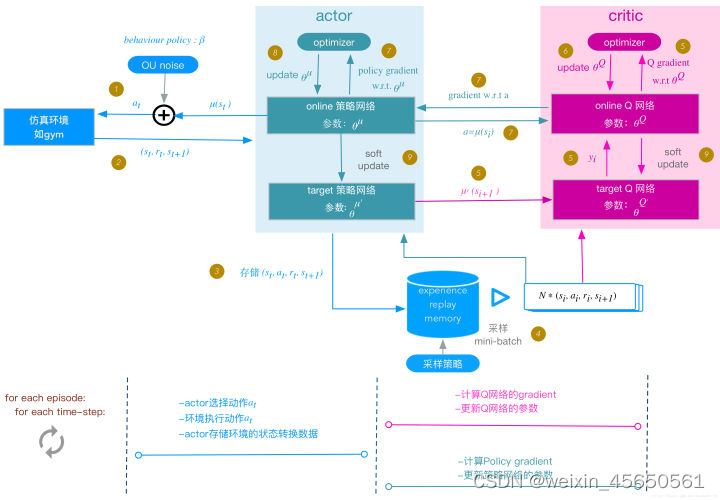
四、DDPG算法新理解
这种算法采用AC框架,可用于解决连续动作空间上的深度强化学习问题。
采用莫烦的一句话来概括DDPG:Google deepmind提出的一种使用actor-critic结构,但是输出的不是行为发概率,而是具体的行为,用于连续动作(continuous action)的预测,DDPG结合了之前获得成功的DQN结构,提高了actor-critic是的稳定性和收敛性。
1、与DPG的不同之处
(1)采用卷积神经网络作为策略函数 μ 和Q函数的近似,即策略网络和Q网络;然后使用深度学习的方法来训练上述神经网络。
(2)网络结构和个数不同
从DPG到DDPG的过程,可以类比于DQN到DDQN的过程。除了经验回放之外,还有双网络,即当前网络和目标网络的概念。而由于现在本就有actor和critic两个网络,那么双网络就变成了4个网络,分别是:actor当前网络、actor目标网络、critic当前网络、critic目标网络。
DDPG 4个网络的功能:
-
Actor当前网络:负责策略网络参数????的迭代更新,负责根据当前状态s选择当前动作a,用于和环境交互生成s’,r,。
-
Actor目标网络:负责根据经验回放池中采样的下一状态s’选择最优下一动作a’。网络参数θ′定期从θ复制。
-
Critic当前网络:负责价值网络参数w的迭代更新,负责计算负责计算当前Q值Q(s,a,w)。目标Q值 y ′ = r + γ Q ′ ( s ′ , a ′ , w ′ ) y'=r+γQ'(s',a',w') y′=r+γQ′(s′,a′,w′)。
-
Critic目标网络:负责计算目标Q值中的Q’(s’,a’,w’)部分。网络参数w’定期从w复制。
2、与DQN不同
(1)目标网络的参数更新方式不同
DDPG从当前网络到目标网络的网络参数复制与DQN不同,DQN中是直接把当前Q网络的参数复制到目标Q网络中,也就是w’=w,DDPG中没有使用这话硬更新,而是选择了软更新,即每次参数只更新一点点:
w
′
←
τ
w
+
(
1
−
τ
)
w
′
w'leftarrowtau w+(1-tau)w'
w′←τw+(1−τ)w′
θ
′
←
τ
θ
+
(
1
−
τ
)
θ
′
theta'leftarrowtautheta+(1-tau)theta'
θ′←τθ+(1−τ)θ′
其中
τ
tau
τ是更新系数,一般取的比较小,比如为0.1或者0.001这样的值。
(2)增加随机性操作
为了学习过程中可以增加一些随机性,增加学习的覆盖,DDPG会对选择出来的动作A增加一定的噪声N,即最终和环境交互的动作A的表达式为: A = π θ ( S ) + N A=pi_{theta}(S)+N A=πθ(S)+N
(3)损失函数
critic当前网络的损失函数还是均方误差,没有变化,但是actor当前网络的损失函数改变了。
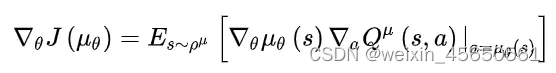 actor的损失可以简单的理解为得到的反馈Q值越大损失越小,得到的反馈Q值越小损失越大,因此只要对状态估计网络返回的Q值取个负号即可,即:
actor的损失可以简单的理解为得到的反馈Q值越大损失越小,得到的反馈Q值越小损失越大,因此只要对状态估计网络返回的Q值取个负号即可,即:
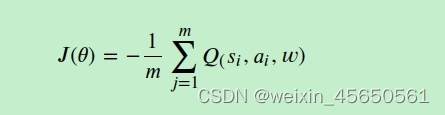
3、有几个关键点
(1)critic部分的输入为states和action;
(2)actor网络不再使用自己的loss函数和reward进行更新,而是使用DPG的思想,使用critic网络计算的Q值对action的梯度来对actor进行更新;
(3)使用了DQN的思想,加入了经验池、随机抽样和目标网络,real Q值是使用两个target网络共同计算;
(4)将 ε − g r e e d y varepsilon-greedy ε−greedy 探索的方法使用在连续值采样上,通过Ornstein-Uhlenbeck process为action添加噪声。
(5)target网络更新改为软更新,在每个batch缓慢更新target网络的参数。
五、额外收获
1、重要性采样
重要性采样是用简单的概率分布去估计复杂的概率分布
参考链接:
Keras深度强化学习–DPG与DDPG实现
强化学习(十六) 深度确定性策略梯度(DDPG)
Deep Deterministic Policy Gradient (DDPG)
最后
以上就是可爱书本最近收集整理的关于强化学习-07--DPG、DDPG一、DPG算法新理解二、DDPG(Deep Deterministic Policy Gradient)算法三、DDPG算法流程四、DDPG算法新理解五、额外收获参考链接:的全部内容,更多相关强化学习-07--DPG、DDPG一、DPG算法新理解二、DDPG(Deep内容请搜索靠谱客的其他文章。








发表评论 取消回复