基本网络结构:
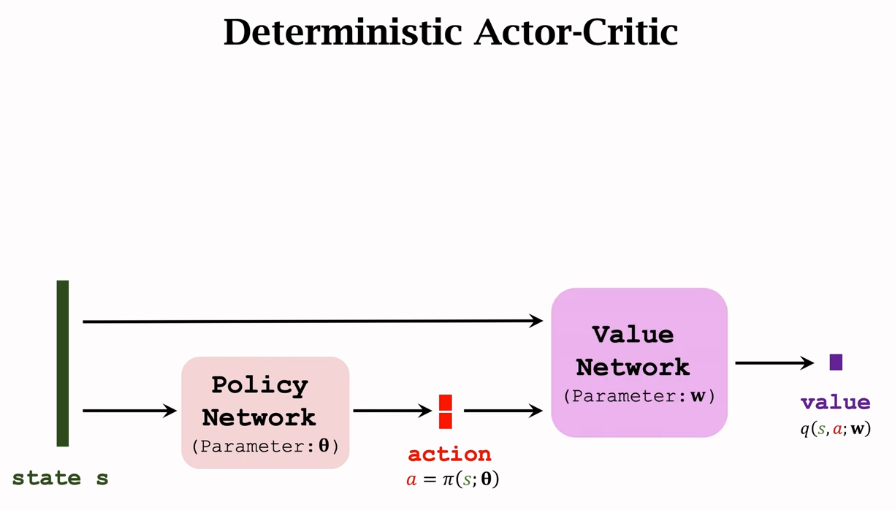
还是基于Actor-critic网络的一种结构,包含策略网络和价值网络。
这里的策略网络为![]() ,但输出不再是概率分布,而是一个确定的实数或向量,输出的动作a是确定的,没有随机性,在机械臂的例子中,输出的是二维向量,因为机械臂有两个动作维度。
,但输出不再是概率分布,而是一个确定的实数或向量,输出的动作a是确定的,没有随机性,在机械臂的例子中,输出的是二维向量,因为机械臂有两个动作维度。
这里的价值网络有两个输入,分别是状态s和动作a,输出的是一个实数,即对动作的评价。
我们要做的就是训练这两个网络,让策略函数选取动作越来越好,让价值函数打分越来越准确。
价值网络的训练:

1.观测到一个四元组。
2.根据观测到的t时刻的动作和状态,预测t时刻的价值。
3.预测t+1时刻的价值,这里用到的![]() 是把
是把![]() 输入到策略网络预测出来的,但是这个
输入到策略网络预测出来的,但是这个![]() 并不是要去执行的动作,只是为了代入
并不是要去执行的动作,只是为了代入![]() 。
。
4.计算TD error,括号里的部分为TD target。
5.进行梯度下降更新参数w。
策略网络的训练:

更新策略网络要依赖于价值网络,价值网络可以评价动作a的好坏,从而指导策略网络进行改进,策略网络自己不知道动作的好坏,要靠价值网络的输出,价值网络的输出越大,就代表评价越好,动作越好,所以我们要改变策略网络的参数θ,让价值网络的输出越大越好。
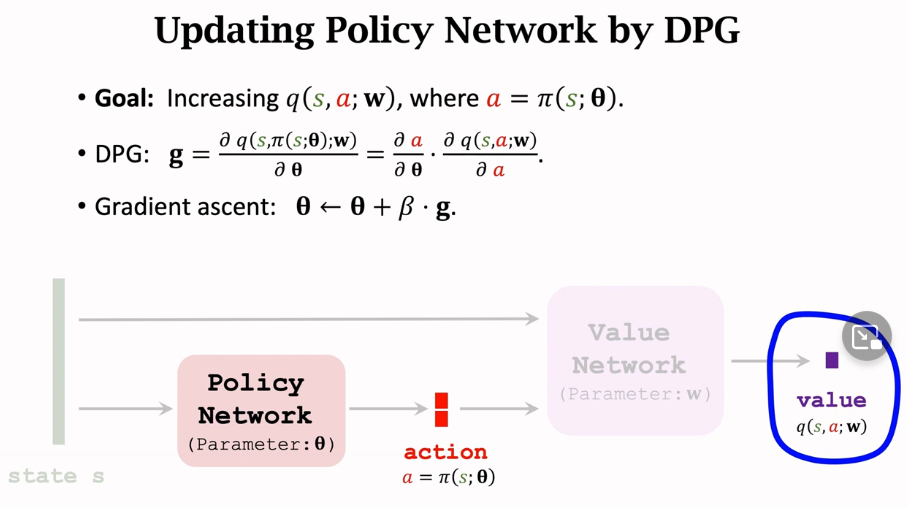
目标就是增加价值网络的输出,而价值网络中的a是由策略网络得出的,所以这里的DPG(确定策略梯度)就是价值网络关于θ求导,然后最后一步做梯度上升,来更新参数θ。使得θ的值更好,选取的动作的价值评分更高。
小的改进(用target network):

第四步计算![]() 时,用的不再是策略网络和价值网络,而是用新的target network,target network的结构和前者一模一样,但是参数略有不同。
时,用的不再是策略网络和价值网络,而是用新的target network,target network的结构和前者一模一样,但是参数略有不同。
其他的改进方法如下:

随机策略和确定策略的区别:
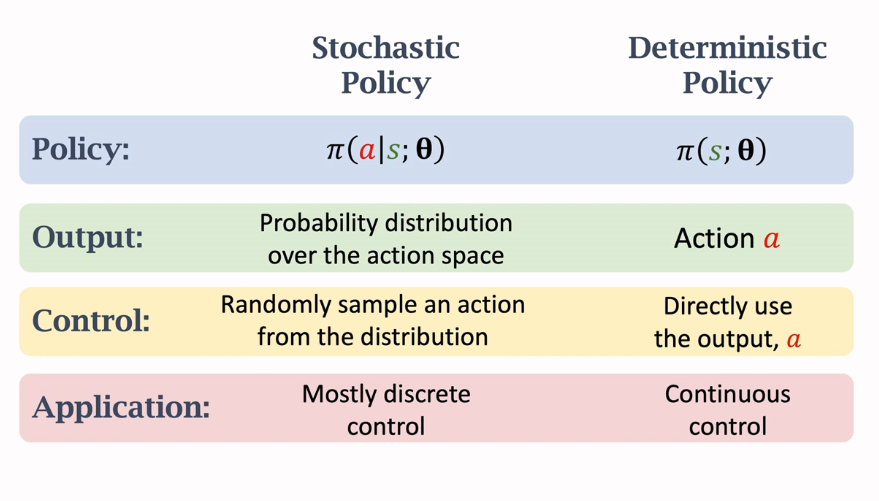
最后
以上就是体贴冬日最近收集整理的关于DPG(确定策略梯度)基本网络结构:价值网络的训练:策略网络的训练: 随机策略和确定策略的区别:的全部内容,更多相关DPG(确定策略梯度)基本网络结构:价值网络内容请搜索靠谱客的其他文章。








发表评论 取消回复