写在前面的废话:索引问题已经是老生常谈的问题,虽然被经常说起,但作为我来说,至今没有用过索引(很可怕吧),我作为MS-BI实施工程师居然没用过索引,说话自然没底气。之前对索引的了解停留在“知道”的地步上,随着时间的流逝感觉不真正将索引应用起来简直是渣渣!废话到此为止,开始索引专题,为了彻彻底底(我不是DBA,能将索引理解达到熟练使用即可,所以并不彻底)搞懂索引,从数据页学习吧!本篇主要来源MS的联机文档!
-
页和区系统结构
页:SQL Server中数据存储的基本单元便是页。为数据库中的数据文件分配的磁盘空间可以从逻辑上划分成页(从0到N连续编号)。磁盘的I/O操作在页级别执行。也就是说SQLSERVER读取或写入所有数据页。
怎样理解呢?作为存储单位,这里给个不恰当的比喻:一个养猪场,有很多猪圈,每个猪圈看作存储数据的页。作为饲养员的我,假设我对养猪场的猪进行买卖,我的操作对象是猪没错,但是,其实我们也是在猪圈的基础上进行买卖,首先,我会对猪圈进行编号,然后,去买卖不同编号里的猪。所以可以理解为:我把猪(数据)养在不同编号(磁盘空间从逻辑上划分成0到N连续编号)的猪圈(页)里面,我买卖(I/O操作)这些猪,都是来自各个猪圈的。
页的大小为8K。每页的开头是96字节的标头,用于存储有关页的信息。此信息包括:页码,页类型,页的可用空间以及拥有该页的对象的分配单元ID。
这句话好理解:每个猪圈能养几头猪(8k),每个猪圈有个猪圈牌,猪圈牌上写点啥呢?当然要写:几号猪圈,是公猪圈、母猪圈、还是猪崽圈,已经养了几头猪以及这个猪圈的负责人联系方式。
下面列出MSSQL中数据页的种类(公猪圈、母猪圈、还是猪崽圈):
页类型
内容
Data
当 text in row 设置为 ON 时,包含除 text、 ntext、image、nvarchar(max)、varchar(max)、varbinary(max) 和 xml 数据之外的所有数据的数据行。
Index
索引条目。
Text/Image
大型对象数据类型:
· text、 ntext、image、nvarchar(max)、varchar(max)、varbinary(max) 和 xml 数据。
数据行超过 8 KB 时为可变长度数据类型列:
· varchar、nvarchar、varbinary 和 sql_variant
Global Allocation Map、Shared Global Allocation Map
有关区是否分配的信息。
Page Free Space
有关页分配和页的可用空间的信息。
Index Allocation Map
有关每个分配单元中表或索引所使用的区的信息。
Bulk Changed Map
有关每个分配单元中自最后一条 BACKUP LOG 语句之后的大容量操作所修改的区的信息。
Differential Changed Map
有关每个分配单元中自最后一条 BACKUP DATABASE 语句之后更改的区的信息。
在下来看看猪圈的样子吧:

上面是一个页的示例图:注意,在数据页上,数据行紧接着标头按顺序放置,页的末尾是行偏移表,对于页中的每一行,每个行偏移表都包含一个条目,每个条目记录对应行的第一个字节与页首的距离(行偏移量之前一直不理解,现在我理解的就是,假设每头猪不会动的按照行排列在猪圈中,每头猪距离猪圈门口的距离就是偏移量,当然这个距离-行偏移量也像猪圈牌一样是记录在另一个“牌子”上的,只不过它不按照123的顺序记录,是倒叙的)。行偏移表中的条目的顺序与页中行的顺序相反(至于为什么是相反的顺序,我猜是从数据结构等等高深的角度考虑吧,暂且理解为写这个行偏移量猪牌的人,站在猪圈尾端,先看到了最后一头猪,所以倒着记录了,没准MS就是这么设计的,哈哈!)。
至此,MS的这个猪圈看似可以养猪了,但是,一种极端的情况呢?这头猪,变异了,猪腿超级大,一个猪圈养不下怎么办!注意力,注意了,看MS怎办了:行不能跨页,但是行的部分可以移出行所在的页,因此行实际可能非常大(看到一头没有腿的小猪,不要嫌弃它小,没准的腿比大象的还粗!)。对了,将猪腿切下来,单独放……下面是MS的具体做法:页的单个行中的最大数据量和开销是8060字节(8K);但是不包括用Text/Image页类型存储的数据(为什么不包括这些类型的页呢?原因很简单,有些猪圈是经过特别设计的专门存放超大猪的,是整个猪,不是一个猪腿。),包括varchar ,nvarchar,varbinary或sql_variant列的表不受此限制的约束。当表中的所有固定列和可变列的行的总大小超过限制的8k时,SQL SERVER将从最大的列开始动态将一个或者多个可变长度列移动到 ROW_OVERFLOW_DATA分配单元中的页。(自述:将表中列移动到其他页)。每当插入或更新操作将行的总大小增大到超过限制的 8,060 字节时,将会执行此操作。将列移动到 ROW_OVERFLOW_DATA 分配单元中的页后,将在 IN_ROW_DATA 分配单元中的原始页上维护 24 字节的指针。如果后续操作减小了行的大小,SQL Server 会动态将列移回到原始数据页。
区:区是管理空间的基本单位。是八个物理上连续的页集合,用来有效的管理页,所有的页都存在区中。为了使空间分配更有效,SQL Server 不会将所有区分配给包含少量数据的表。这个好理解:8个猪圈就是一个大猪圈。一两头猪,MS是不会把它放在一个大猪圈中的。SQL Server 有两种类型的区:统一区,由单个对象所有。区中的所有8页只能由所属对象使用。混合区,最多可由八个对象共享。区中八页的每页可由不同的对象所有。统一区相当于猪圈的猪来自同一家农户。混合区相当于猪来自不同农户。

-
管理区分配和可用空间
大多数分配信息不是链在一起的。这就简化了对分配信息的维护。可以快速执行每个页的分配或释放。这将减少需要分配页或释放页的并发任务之间的争用。
管理区的分配 SQL SERVER使用两种类型的分配映射表来记录区的分配(下面的就好理解了一个养猪场怎么管好大量的猪圈呢,肯定想法设法记录有用信息来合理使用猪圈):
全局分配映射表(GAM):GAM 页记录已分配的区。每个 GAM 包含 64,000 个区,相当于近 4 GB的数据。GAM 用一个位来表示所涵盖区间内的每个区的状态。如果位为 1,则区可用;如果位为 0,则区已分配。
共享全局分配映射表 (SGAM):SGAM 页记录当前用作混合区且至少有一个未使用的页的区。每个 SGAM 包含 64,000 个区,相当于近 4 GB 的数据。SGAM 用一个位来表示所涵盖区间内的每个区的状态。如果位为 1,则区正用作混合区且有可用页。如果为 0,则区未用作混合区,或者虽然用作混合区但其所有页均在使用中。
跟踪可用空间 页可用空间 (PFS) 页记录每页的分配状态,是否已分配单个页以及每页的可用空间量。PFS 对每页都有一个字节,记录该页是否已分配。如果已分配,则记录该页是为空、已满 1% 到 50%、已满 51% 到 80%、已满 81% 到 95% 还是已满 96% 到 100%。将区分配给对象后,数据库引擎将使用 PFS 页来记录区中的哪些页已分配或哪些页可用。数据库引擎必须分配新页时,将使用此信息。保留的页中的可用空间量仅用于堆和 Text/Image 页。数据库引擎必须找到一个具有可用空间的页来保存新插入的行时,使用此信息。索引不要求跟踪页的可用空间,因为插入新行的点是由索引键值设置的。
在数据文件中,PFS 页是文件头页之后的第一页(页码为 1)。接着是 GAM 页(页码为 2),然后是 SGAM 页(页码为 3)。第一个PFS 页之后是一个大小大约为 8,000 页的 PFS 页。在第 2 页的第一个 GAM 页之后还有另一个 GAM 页(包含 64,000 个区),在第 3 页的第一个 SGAM 页之后也有另一个 SGAM 页(包含 64,000 个区)。下图显示了数据库引擎用来分配和管理区的页顺序。

下面的几段话不好理解:我的理解,估计是错的!
(IAM:是用来记录区中的页哪些来自同一对象,比如统一区中的猪都来在A农户,这样的数据就记录在IAM页中。)
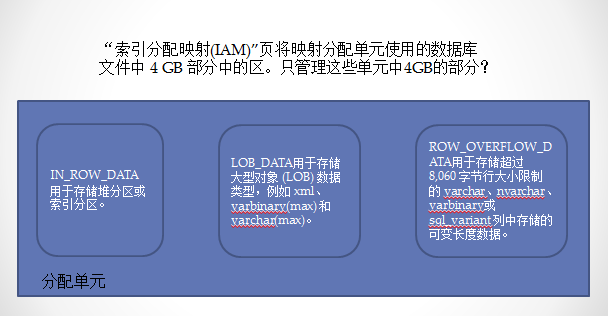
“索引分配映射(IAM)”页将映射分配单元使用的数据库文件中 4 GB 部分中的区。分配单元有下列三种类型:
IN_ROW_DATA用于存储堆分区或索引分区。
LOB_DATA用于存储大型对象 (LOB) 数据类型,例如 xml、varbinary(max) 和varchar(max)。
ROW_OVERFLOW_DATA用于存储超过 8,060 字节行大小限制的 varchar、nvarchar、varbinary或 sql_variant 列中存储的可变长度数据。

-
跟踪已修改的区
SQL Server 使用两个内部数据结构跟踪被大容量复制操作修改的区,以及自上次完整备份后修改的区。这些数据结构极大地加快了差异备份的速度。当数据库使用大容量日志恢复模式时,这些数据结构也可以加快将大容量复制操作记录至日志的速度。与全局分配图 (GAM) 和共享全局分配图 (SGAM) 页相同,这些结构也是位图,其中的每一位代表一个单独的区。
差异更改映射表 (DCM)
这样便可以跟踪自上次执行 BACKUP DATABASE 语句后更改过的区。如果扩展盘区的位是 1,则自上次执行 BACKUP DATABASE 语句后扩展盘区已被修改。如果位是 0,则扩展盘区没有被修改。差异备份只读取 DCM 页便可以确定已修改的区。这样大大减少了差异备份必须扫描的页数。运行差异备份所需的时间与自上次执行 BACKUP DATABASE 语句之后修改的区数成正比,而不是与整个数据库的大小成正比。
大容量更改映射表 (BCM)
跟踪自上次执行 BACKUP LOG 语句后,被大容量日志记录操作修改的区。如果某个扩展盘区的位是 1,表明自上次执行 BACKUP LOG 语句后,该扩展盘区已经被有日志记录的大容量复制操作修改 。如果位是 0,则该扩展盘区未被有日志记录的大容量复制操作修改。尽管所有数据库中都显示 BCM 页,但只有在数据库使用大容量日志记录恢复模式时,才会与 BCM 页有关。在此恢复模式中 ,当执行 BACKUP LOG 时,备份进程将扫描 BCM 查找已经修改的区。然后将那些区包括在日志 备份中。如果数据库从数据库备份和一系列事务日志备份恢复,便可以恢复大容量日志记录操作。在使用简单恢复模式的数据库中,BCM 页是不相关的,因为大容量日志记录操作不记入日志。在使用完整恢复模式的数据库中,BCM页同样不相关,因为该恢复模式将大容量日志记录操作视为有完整日志记录的操作。 DCM 页和 BCM 页的间隔与 GAM 和SGAM 页的间隔相同都是 64,000 个 区。在物理文件中,DCM 和 BCM 页位于 GAM 和 SGAM 页之后。

下面写一些附带的知识!
文件和文件组体系结构
SQL Server 将数据库映射为一组操作系统文件。数据和日志信息绝不会混合在同一个文件,而且一个文件只由一个数据库使用。文件组是命名的文件集合,用于帮助数据布局和管理任务。
SQL Server数据库具有三种类型的文件:
主数据文件:是数据库的起点,指向数据库中的其他文件。每个数据库都有一个主数据文件(。mdf)
次要数据文件:除主数据文件,其他的都是次要数据文件。有些数据库可能不含有次要数据文件(.ndf)。
日志文件:主要用于恢复数据库的所有信息。每个数据库必须有一个日志文件,当然也可以有多个(.ldf)。
在SQL Servcer中,数据库中所有的文件的位置都记录在数据库主文件和master数据库中。
大多时候,SQLSERVER数据库使用master数据库中的文件位置,但是在下面情况下,数据库引擎使用主文件的文件位置信息初始化master数据库中的文件位置项:
1. 使用带有FORATTACHE或FOR ATTACH_REBUILD_LOG选项的CREATE DATADASE语句来附加数据库时。
2. 从SQLSERVER2000版7.0版升级时。
3. 还原master数据库。
数据文件页:SQLSERVER数据文件中的页按顺序编号,文件的首页以0开始。数据库的每个文件都有一个唯一的文件ID号。若要唯一标识数据库中的页,需要同时使用文件ID和页码。
事务日志体系结构
1 事务日志逻辑体系结构
SQLSERVER事务日志按逻辑运行,就好像事务日志是一串日志记录一样。每条日志记录由一个日志序列号(LSN)标识。每条新日志记录均写入日志的逻辑结尾处,并使用一个比前面记录的LSN更高的LSN。日志记录按创建时的串行序列存储。每条日志记录都包含其所属事务的ID。对于每个事务,与事务相关的所有日志记录通过使用可提高事务回滚速度的向指针挨个链接在一个链中。
2 事务日志物理体系结构
从概念上讲,日志文件是一系列日志记录。从物理上讲,日志记录序列被有序的存储在实现事务日志的物理文件集中。SQLSERER数据库引擎在内部将每一个物理日志文件分成多个虚拟日志文件。事务日志是一种回绕文件。例如:一个数据库,它包含一个分成四个虚拟日志文件的物理文件。当创建数据库的时候,逻辑日志文件从物理日志文件的始端开始。新日志记录被添加到逻辑日志的末端,然后向物理日志的末端扩张。日志截断将释放记录全部在最小恢复日志序列号(MInLSN)之前的所有虚拟日志。“MInLSN”是成功进行数据库范围内回滚所需的最早日志记录的日志序列号。当逻辑日志的末端到达物理日志文件的末端时,新的日志记录将回绕到日志文件的始端。这个循环不断重复,只要逻辑日志的末端不到达逻辑日志的始端。
* 检查点将脏数据页从当前数据库的缓冲区高速缓存刷新到磁盘上。这最大限度地减少了数据库完整恢复时必须处理的活动日志部分。
转载于:https://www.cnblogs.com/java-oracle/p/4814546.html
最后
以上就是寂寞长颈鹿最近收集整理的关于Sql Server专题一:索引(上)的全部内容,更多相关Sql内容请搜索靠谱客的其他文章。
![【Oracle篇】触发器的使用 [上]](https://www.shuijiaxian.com/files_image/reation/bcimg21.png)







发表评论 取消回复