备份方法:
1.热备:在数据库运行中直接备份,对正在运行的数据库没有任何影响,这种方式在MySQL官方手册中称为Online Backup。
2.冷备:在数据库停止的情况下备份,这种备份最简单,一般只需拷贝相关的数据库物理文件即可,这种方式在MySQL官方手册中称为Offline Backup。
3.温备:在数据库运行时进行备份,但对当前数据库操作有影响,如加一个全局读锁保证备份数据的一致性。
按备份后的文件内容,可将备份分为:
1.逻辑备份:指备份后的文件内容可读,通常是文本文件,内容一般是SQL语句,或表内的实际数据,如mysqldump和SELECT * INTO OUTFILE的方法。好处是可以看到导出文件的内容,一般用于数据库升级、迁移等工作,但恢复时间较长。
2.裸文件备份:指拷贝数据库的物理文件,数据库既可以处于运行状态(如ibbackup、xtrabackup这类工具),也可以处于停止状态。这类备份的恢复时间较短。
按备份数据库的内容可将备份分为:
1.完全备份:对数据库进行一个完整备份。
2.增量备份:在上次完全备份基础上,对更新的数据进行备份。
3.日志备份:主要指对MySQL的二进制日志备份,通过对一个完全备份进行二进制日志的重做来完成数据库的point-in-time的恢复工作。MySQL数据库复制的原理就是异步实时进行二进制日志重做。
对于MySQL,官方没有提供真正的增量备份方法,大部分是通过二进制日志实现,与真正的增量备份相比,效率比较低。如果通过二进制日志完成增量备份,可能同一个页需要多次执行SQL来完成重做,但真正的增量备份只需要记录当前每个页最后的检查点LSN,如果大于之前完全备份时的LSN,则备份该页,否则不用备份,这也是xtrabackup增量备份的原理。
数据库备份还需要在备份的时间点上数据是一致的(如购买操作的花钱和给东西必须是原子的,如果备份结果是花了钱但没有给东西,则数据是不一致的),对于InnoDB引擎,因为其支持MVCC,因此实现备份一致比较容易,可以先开启一个事务,然后导出一组相关的表,最后提交,当然事务隔离级别必须是REPEATABLE READ的。但此办法的前提是需要正确设计应用程序,如购买过程的花钱和获得物品不能分为两个事务完成,如果备份发生在这两个事务之间,备份出的数据依然是不一致的。
对于mysqldump备份工具,可通过添加-single-transaction选项获得InnoDB引擎的一致性备份(一般必加,没理由不加),原理与上述相同,这种备份是在一个执行时间很长的事务中完成的。
对InnoDB引擎表的冷备只需要备份数据库的frm文件、共享表空间文件、独立表空间文件、重做日志文件。建议定期备份MySQL的配置文件my.cnf,有利于恢复操作。
冷备优点:
1.备份简单,只要拷贝相关文件即可。
2.备份文件易于在不同操作系统、不同MySQL版本上恢复。
3.恢复简单,只需将文件恢复到指定位置即可。
4.恢复速度快,不需执行任何SQL语句,不需要重建索引。
冷备缺点:
1.InnoDB引擎冷备文件通常比逻辑文件大很多,因为表空间中存放着很多其他数据,如Undo段、插入缓冲等信息。
2.冷备不总可以轻易跨平台,操作系统、MySQL版本、文件大小写敏感和浮点数格式都会成为问题。
mysqldump备份工具用来完成转存数据库的备份和不同数据库之间的移植,是逻辑备份工具。
mysqldump语法:
mysqldump [arguments] > file_name
备份所有数据库:
mysqldump --all-databases > dump.sql
备份指定数据库:
mysqldump --database db1 db2 db3 > dump.sql
仅对一个库备份,使用了–single-transaction选项保证备份的一致性:
mysqldump --single-transaction test > test_backup.sql
备份出的test_backup.sql是文本文件,其中存放的是SQL语句表示的表结构和数据。其中的开始和结束处的注释是MySQL的各项参数,一般用来使还原工作能更有效和准确地进行。
mysqldump命令的比较重要的选项:
1.–single-transaction:备份开始前,会先执行START TRANSACTION命令,来获取备份的一致性。此参数只对InnoDB引擎有效,启用此参数备份时,要确保没有其他DDL语句,因为一致性读不隔离DDL语句。
2.–lock-tables(-l):在备份过程中,依次锁住每个库中所有表,一般用于MyISAM引擎表,备份时只能对数据库进行读取操作,由于此选项只能依次锁定每个库中的所有表,因此只能保证一个库中的备份的一致性,而不能保证所有库中备份的一致性。对于InnoDB引擎表,不需要使用此选项,使用–single-transaction即可,且这两个选项是互斥的。如果库中既有InnoDB引擎表,又有MyISAM引擎表,就只能使用–lock-tables选项了。
3.–lock-all-tables(-x):在备份过程中,对所有库中所有表上锁。
4.-add-drop-database:导出的备份会在CREATE DATABASE语句前加上DROP DATABASE语句。此参数需要和-all-databases或-databases选项一起使用,默认,导出的备份中不会有CREATE DATABASE语句,除非使用了-all-databases或-databases选项。使用–lock-all-tables选项时导出的备份内容:
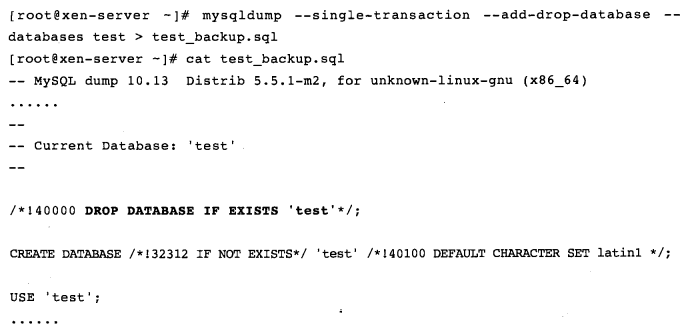
上图中/*!40000 DROP DATABASE IF EXISTS 'test'*/1看似是个注释,其实注释开头带感叹号的注释是会被执行的,感叹号后面的数字表示版本,只有在此版本后的数据库中该注释才会被执行。
5.–master-data[=value]:使用此选项产生的备份文件主要用来建立一个slave replication。指定此选项时会自动关闭–lock-tables选项,且如果没有指定–single-transaction选项时会自动指定–lock-all-tables选项。当value值为1时,转存文件中会记录CHANGE MASTER语句;当value值为2时,CHANGE MASTER语句会被写为SQL注释;默认value的值为1。当value为1时,备份文件中的内容:
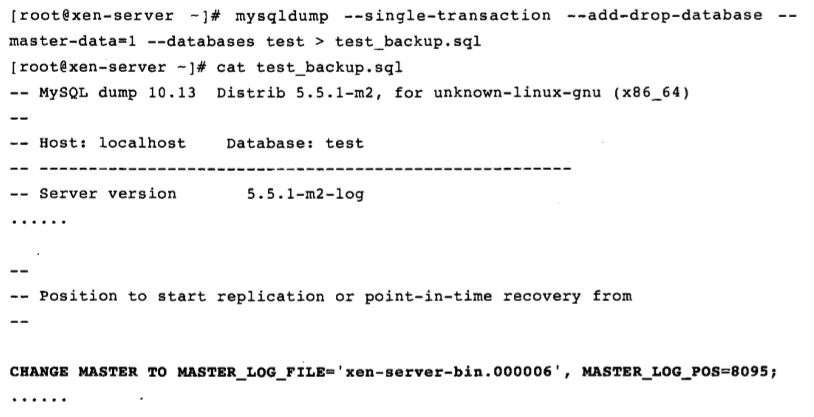
上图中的CHANGE MASTER TO语句指定了slave从master的哪个二进制文件和文件中的哪个位置开始复制。
6.–events(-E):备份事件调度器。
7.–triggers:备份触发器。
8.–hex-blob:将BINARY、VARBINARY、BLOG、BIT列类型备份为十六进制的格式,mysqldump导出的文件一般是文本文件,但如果导出的数据中有上述类型,在文本模式下可能有些字符不可见,如果添加此选项,则这些列的内容会以十六进制方式显示。
9.–tab=path(-T path):产生制表符分隔的备份文件到path目录下,对于每张表,会创建一个包含CREATE TABLE语句的table_name.sql文件和包含以制表符分隔的表内数据(表中的每行数据在备份文件中对应一行)的table_name.txt文件。
10.–where=‘where_condition’(-w ‘where_condition’):导出给定条件的数据:
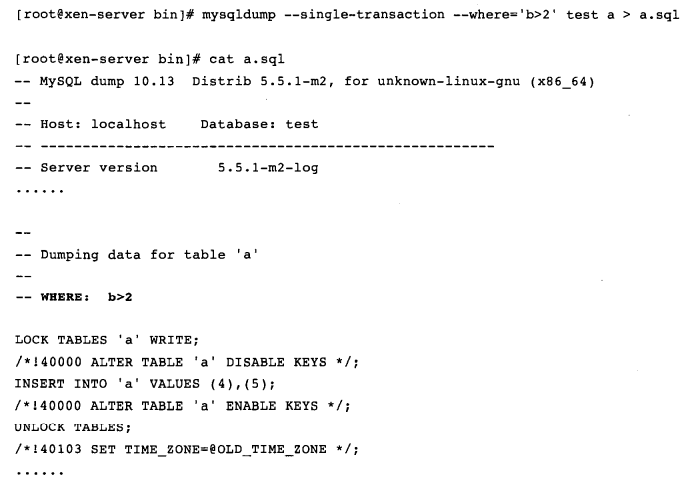
SELECT … INTO OUTFILE也是一种逻辑备份方法,它一次只能导出一张表中的数据,不能像mysqldump一样导出多张表来保证多张表的备份一致性,它的语法如下:
SELECT [column 1], [column 2] ...
INTO
OUTFILE 'file_name' # 该文件所在路径权限必须是mysql(用户权限):mysql(组权限),否则命令会报错,如果此文件已存在,也会报错
[
{FIELDS | COLUMNS}
[TERMINATED BY 'string'] # 每个列之间以string为分隔符,默认为't'
[[OPTIONALLY] ENCLOSED BY 'char'] # 每个字段两端被char括起来,默认为空
[ESCAPED BY 'char'] # 以char为转义符,默认为'\'(第一个反斜杠为转义符)
]
[
[STARTING BY 'string'] # 每行以string开头,默认为空
[TERMINATED BY 'string'] # 每行以string结尾,默认为'n'
]
FROM TABLE
WHERE ...
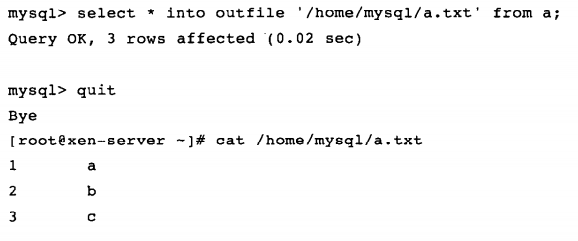
查看导出的文件:
将导出的表的列以逗号分隔:


上图中mysql命令的-e选项表示执行其后的SQL语句。
由于在Windows下,换行符是’rn’,因此导出时可能需要指定行分隔符:

od命令默认以八进制查看文件,-c选项会打印出ASCII字符。
mysqldump备份的文件中是SQL语句,因此直接执行此文件即可:

如上图,如果在备份文件中有创建和删除数据库的SQL语句,需要确保删除库时,该库所在目录(一般是datadir/databaseName)下没有与此库无关的文件,否则可能出错。
在MySQL命令行下直接执行mysqldump导出的逻辑备份文件:

mysqldump可以导出存储过程、触发器、事件、数据,但不能导出视图,视图可以通过备份视图定义的frm文件,并在恢复时导入。
如果逻辑备份是通过mysqldump --tab或SELECT INTO OUTFILE产生的,恢复时需要使用LOAD DATA INFILE命令,语法如下:
LOAD DATA [LOW_PRIORITY | CONCURRENT] [LOCAL] INFILE 'file_name' # LOW_PRIOTITY适用于只有表级锁的引擎,写入时如果有读请求,则先执行读请求再继续写入;CONCURRENT表示在写入过程中允许读请求
[REPLACE | IGNORE] # 当插入会破坏某列的唯一约束时,如果是REPLACE,则用新插入的行代替表中原来的行,如果是IGNORE会忽略要插入的行
INTO TABLE tbl_name
[CHARACTER SET charset_name]
[
{FIELDS | COLUMNS}
[TERMINATED BY 'string']
[[OPTIONALLY] ENCLOSED BY 'char'] # 每个字段两端被char包围
[ESCAPE BY 'char']
]
[
LINES
[STARTING BY 'string']
[TERMINATED BY 'string']
]
[IGNORE number LINES] # 忽略导入的前number行
[(col_name_or_user_var, ...)]
[SET col_name = expr, ...]
为了加快InnoDB引擎下的导入,可在导入过程忽略对外键的检查:

在导入时可进行计算,如在新表中增加一列,新列值为其他两列的和:

LOAD DATA INFILE命令还可监视Linux系统情况,如想监控CPU使用情况,可通过/proc/stat(保存关于系统内核的活动信息)文件完成,首先建立一张监控CPU的表:
CREATE TABLE IF NOT EXISTS cpu_stat(
id BIGINT AUTO_INCREMENT PRIMARY KEY,
value CHAR(25) NOT NULL,
user BIGINT,
nice BIGINT,
system BIGINT,
idle BIGINT,
iowait BIGINT,
irq BIGINT,
softirq BIGINT,
steal BIGINT,
quest BIGINT,
other BIGINT,
time DATETIME
);
之后可加载/proc/stat文件中的值,需要对其中一些值进行计算:
LOAD DATA INFILE '/proc/stat'
IGNORE INTO TABLE cpu_stat
FIELDS TERMINATED BY ' '
(@value, @val1, @val2 ,@val3, @val4, @val5, @val6, @val7, @val8, @val9, @val10)
SET
value = @value,
user = IF(@value NOT LIKE 'cpu%', NULL, IF(@value != 'cpu', IFNULL(@val1, 0), IFNULL(@val2, 0))),
nice = IF(@value NOT LIKE 'cpu%', NULL, IF(@value != 'cpu', IFNULL(@val2, 0), IFNULL(@val3, 0))),
system = IF(@value NOT LIKE 'cpu%', NULL, IF(@value != 'cpu', IFNULL(@val3, 0), IFNULL(@val4, 0))),
idle = IF(@value NOT LIKE 'cpu%', NULL, IF(@value != 'cpu', IFNULL(@val4, 0), IFNULL(@val5, 0))),
iowait = IF(@value NOT LIKE 'cpu%', NULL, IF(@value != 'cpu', IFNULL(@val5, 0), IFNULL(@val6, 0))),
irq = IF(@value NOT LIKE 'cpu%', NULL, IF(@value != 'cpu', IFNULL(@val6, 0), IFNULL(@val7, 0))),
softirq = IF(@value NOT LIKE 'cpu%', NULL, IF(@value != 'cpu', IFNULL(@val7, 0), IFNULL(@val8, 0))),
steal = IF(@value NOT LIKE 'cpu%', NULL, IF(@value != 'cpu', IFNULL(@val8, 0), IFNULL(@val9, 0))),
guest = IF(@value NOT LIKE 'cpu%', NULL, IF(@value != 'cpu', IFNULL(@val9, 0), IFNULL(@val10, 0))),
other = IF(@value NOT LIKE 'cpu%', user + nice + system + idle + iowait + irq + softirq + steal + guest, @val1),
time = now();
执行结果:
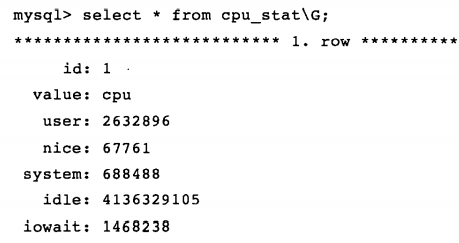
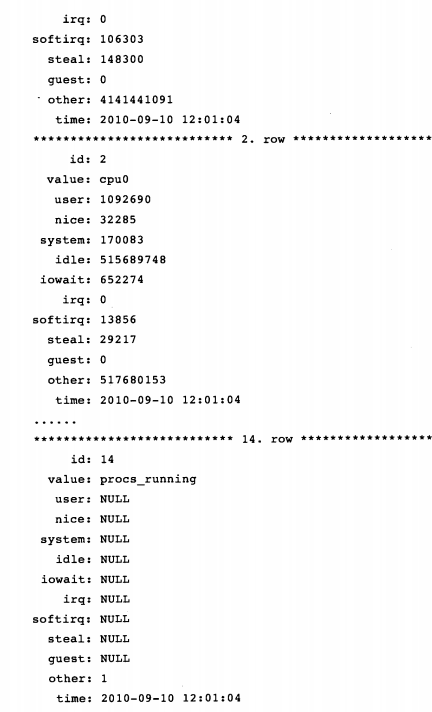
也可对/proc/diskstat文件执行以上操作以监控磁盘使用情况。
mysqlimport是MySQL提供的命令行程序,本质上说,是LOAD DATA INFILE的命令接口,且大多选项都和LOAD DATA INFILE语法相同,语法如下:
mysqlimport [option] db_name textfile1 [textfile2 ...]
mysqlimport与LOAD DATA INFILE不同的是,它可以一次导入多张表,并且可以通过–use-thread选项并发导入不同的文件,通过mysqlimport并发导入两张表:
mysqlimport --use-thread=2 test /home/mysql/t.txt /home/mysql/s.txt
运行上述命令时,MySQL的数据库线程列表可看到以下内容:


可见mysqlimport同时执行了两条LOAD DATA INFILE语句完成并发导入。
二进制日志可用来完成point-in-time恢复工作,MySQL数据库的复制也需要二进制日志,默认MySQL不开启二进制日志,启用二进制日志需要在配置文件中进行如下配置:
[mysqld]
log-bin
只简单启用二进制日志是不够的,还需启用一些其他参数保证安全和正确地记录二进制日志,推荐的配置是:
[mysqld]
log-bin
sync_binlog = 1 # 每次事务提交都做一次类似fsync二进制文件的操作
innodb_support_xa = 1 # 开启两段式事务提交,如果不开启此选项,可能出现写入二进制日志的顺序与commit的顺序不同的情况
备份二进制日志文件前,可通过FLUSH LOGS命令生成一个新的二进制日志文件,然后再备份之前的二进制日志。
恢复二进制日志,如要还原binlog.0000001:
mysqlbinlog binlog.0000001 | mysql -uroot -p test
如果需要恢复多个二进制日志:
mysqlbinlog binlog.[0-10]* | mysql -uroot -p test
也可以将要恢复的二进制日志导入到一个文件,然后再通过SOURCE命令导入,这样的好处是可以对导出的文件进行修改后再导入:
mysqlbinlog binlog.000001 > /tmp/statements.sql
mysqlbinlog binlog.000002 >> /tmp/statements.sql
mysql -u root -p -e "source /tmp/statements.sql"
mysqlbinlog的–start-position和–stop-position选项可以指定从二进制日志的某个偏移量进行恢复,这样可以跳过某些不正确的语句:
mysqlbinlog --start-position=107856 binlog.0000001 | mysql -uroot -p test
mysqlbinlog的–start-datetime和–stop-datetime选项可用来从指定的时间点进行恢复。
ibbackup是InnoDB引擎官方提供的热备工具,可同时备份MyISAM引擎表和InnoDB引擎表,备份InnoDB引擎表时的原理如下:
1.记录备份开始时,InnoDB引擎重做日志文件的检查点LSN。
2.拷贝共享表空间文件和独立表空间文件。
3.记录拷贝完表空间文件后,InnoDB引擎重做日志文件的检查点的LSN。
4.拷贝在备份时产生的重做日志。
事务型的数据库,如SQLserver、Oracle的热备原理与上述大致相同,备份期间的操作只是拷贝数据库文件,因此任何对数据库的操作都是允许的,不会出现阻塞情况,因此ibbackup的优点如下:
1.在线备份,不阻塞SQL语句。
2.备份性能好,实质是复制数据库文件和重做日志文件。
3.支持压缩备份,通过选项可实现不同级别的压缩。
4.跨平台支持,ibbackup可运行在Linux、Windows、主流unix系统上。
ibbackup恢复InnoDB引擎表的过程如下:
1.恢复表空间文件。
2.应用重做日志文件恢复InnoDB引擎表。
ibbackup是收费的,XtraBackup热备工具免费、开源,它可以实现ibbackup的所有功能,并且还支持真正的增量备份。
Xtrabackup在GPL v2开源协议下发布。
Xtrabackup增量备份原理:
1.首先完成一个完全备份,并记录下此时的检查点的LSN。
2.进行增量备份时,比较表空间中每个页的LSN是否大于上次备份时的LSN,如果是,则备份该页,同时记录下当前检查点的LSN。
MySQL本身不支持快照功能,快照备份是指通过文件系统支持的快照功能对数据库进行备份,快照备份的前提是将所有数据库文件放在同一文件分区中,然后对该分区执行快照工作。支持快照功能的文件系统和设备包括FreeBSD的UFS文件系统、Solaris的ZFS文件系统、GNU/Linux的逻辑卷管理器(Logical Volume Manager,LVM)等。
以LVM为例介绍快照备份:LVM是Linux系统下对磁盘分区进行管理的一种机制,LVM在硬盘和分区之上建立一个逻辑层提供磁盘分区管理的灵活性,管理员可以将若干个磁盘分区连接为一个整块的卷组,形成一个存储池,可以在卷组上随意创建逻辑卷,并进一步在逻辑卷上创建文件系统。总之可以通过LVM由物理块设备创建物理卷,一个或多个物理卷组成卷组,最后从卷组中创建任意数量的逻辑卷(不超过卷组大小):
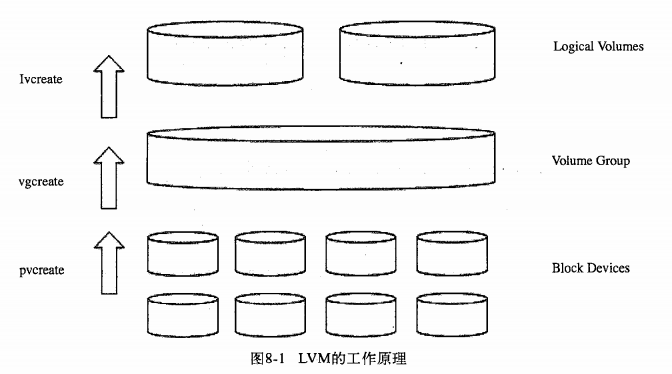
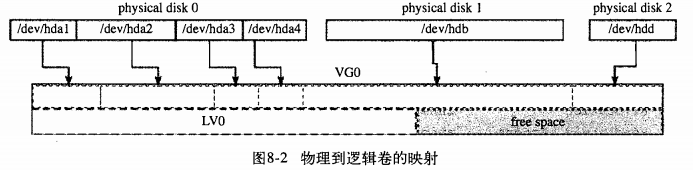
查看系统中的卷组:

查看系统中有哪些逻辑卷:


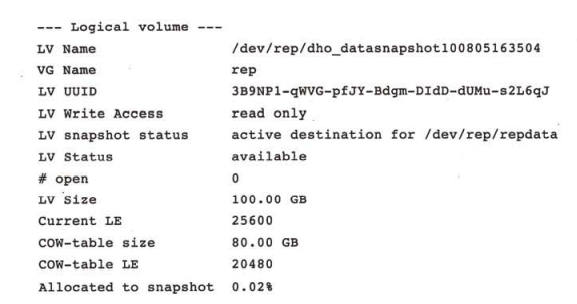

可见有三个逻辑卷,都属于卷组rep,每个逻辑卷的大小为100GB,后两个逻辑卷是第一个的只读快照,并且当前都是激活的。
LVM使用了写时复制创建快照,创建快照时仅拷贝原始卷里数据的元数据,因此快照的创建过程非常快,快照创建完成后,原始卷上有写操作时,将要改变的数据在改变前拷贝到快照预留的空间里。对于快照的读取操作,如果读取的数据块是创建快照后没有修改过的,则读操作会直接重定向到原始卷上,如果要读取的是已经修改过的块,则会读取保存在快照中的数据。
使用lvcreate命令在卷组/dev/rep/repdata中创建一个逻辑卷快照,–permission r选项表示快照是只读的,-n datasnapshot选项给创建的逻辑卷命名为datasnapshot:
lvcreate --size 100G --snapshot --permission r -n datasnapshot /dev/rep/repdata
查看创建的作为快照的逻辑卷:
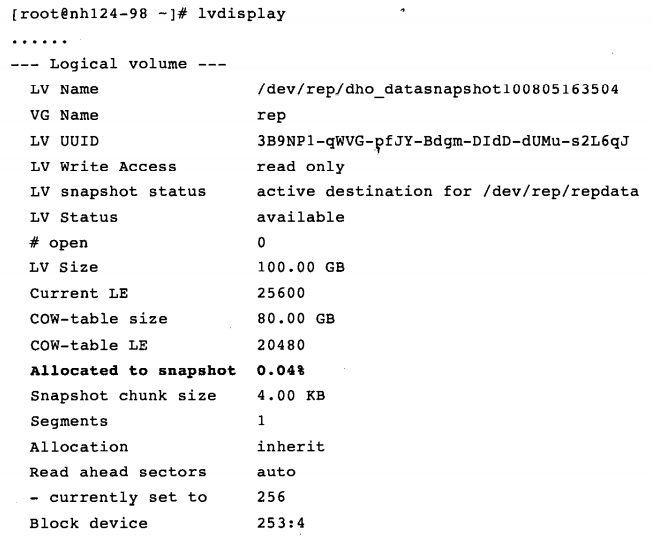
上图中Allocated to snapshot字段表示该快照当前空间使用情况,快照最初创建时总是很小的,随着源数据卷的修改,数据才会放入快照空间使得快照大小慢慢变大。
用LVM快照备份InnoDB引擎表很简单,只需要将于InnoDB引擎相关文件如共享表空间、独立表空间、重做日志文件等放在同一逻辑卷中,然后对这个逻辑卷进行备份即可。对InnoDB引擎文件做快照时,数据库无需关闭。
启用LVM快照时需要规划的方面:
1.快照空间大小:如果源逻辑卷大小100G,快照最大可能产生的大小是100G,但如果每4小时生成一次快照,则无需划分100G的空间给快照逻辑卷,只需要判断4小时内最多产生的快照空间即可。
2.快照启用后的磁盘性能必定会下降。
LVM快照不能当完全备份使用,当源数据卷发生故障时,LVM快照备份不能恢复,LVM快照备份更偏向于对误操作的防范,可将数据库迅速恢复到快照产生的时间点。
复制是MySQL提供的一种高可用、高性能的解决方案,复制工作原理:
1.主服务器把数据更新记录到二进制日志中。
2.从服务器把主服务器的二进制日志拷贝到自己的中继日志(Relay Log)中。
3.从服务器用中继日志,将更新应用到自己的数据库上。
复制的原理相当于异步地实时进行二进制日志的还原操作。
从服务器上有两个线程:一个是IO线程,负责读取主服务器的二进制日志,并将其保存为中继日志;另一个是SQL进程,执行中继日志来复制主数据库。
MySQL 4.0之前,从服务器只有一个线程,既负责读取二进制日志,又负责执行二进制日志中的SQL语句,这种方式性能低,已被淘汰。

复制时查看从服务器状态:


上图中ID为1的线程就是IO线程,目前状态是等待主服务器发送二进制日志;ID为2的线程是SQL线程,负责读取中继日志并执行,目前状态是已读取所有中继日志,等待中继日志被IO线程更新。
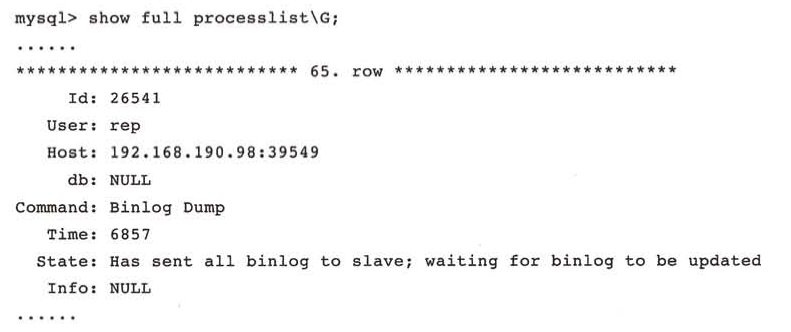
在复制的主服务器上可以看到一个负责发送二进制日志的线程:
分别运行SHOW SLAVE STATUS、SHOW MASTER STATUS命令查看主从库之间的延迟:
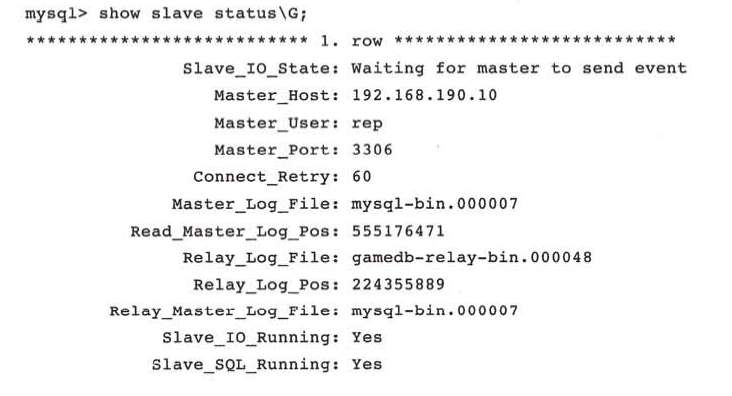

上图中的主要参数有:
1.Slave_IO_State:当前IO线程的状态 ,上图状态是等待主服务器发送二进制日志。
2.Master_Log_File:同步的主数据库的二进制日志名。
3.Read_Master_Log_Pos:当前已经同步到从服务器上的主服务器的二进制日志的偏移量位置,单位是字节。
4.Relay_Master_Log_File:当前中继日志正在同步的日志名(主服务器上的二进制日志名)。
5.Relay_Log_File:当前写入的中继日志名。
6.Relay_Log_Pos:当前执行到的中继日志的偏移量。
7.Slave_IO_Running:从服务器中IO线程的运行状态,YES表示运行正常。
8.Slave_SQL_Running:从服务器中SQL线程的运行状态,YES表示运行正常。
9.Exec_Master_Log_Pos:当前执行到从服务器上主服务器的二进制日志的偏移量位置,单位是字节。3减9表示当前SQL线程运行的延迟量,上例显示当前主从服务器是完全同步的。
查看主服务器中二进制日志的状态:
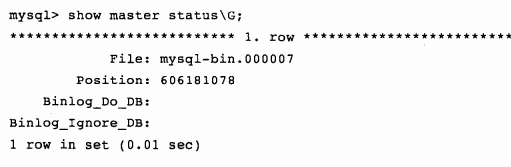
可见当前二进制日志记录到606181078的位置,该值减去这一时间点上从服务器上的Read_Master_Log_Pos,就可以得到IO线程的延时。
好的数据库复制监控还应监控主从复制延迟,确保主从状态接近。
复制除了可用来备份,还有以下功能:
1.数据分布:MySQL提供的复制不需要很大的带宽,可在不同的数据中心之间实现数据的拷贝。
2.读取的负载平衡:建立多个从服务器,从而将读取平均地分布到这些服务器中,一般可通过DNS的Round-Robin和Linux的LVS(Linux Virtual Server,Linux虚拟服务器)功能实现。
3.数据库备份:从服务器不是备份,不能完全代替备份。
4.高可用性和故障转移:从服务器有助于故障转移,减少故障的停机时间和恢复时间。
假设从服务器用作备份,而有一个误操作被执行,从服务器也跟着执行了,此时最好的解决方法是提前对从数据库所在分区做快照,误操作后,只需恢复从服务器上的快照,然后再进行二进制日志的point-in-time恢复即可,备份架构如下:
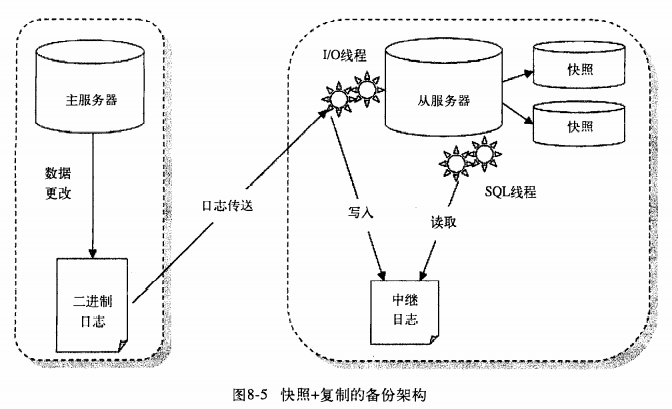
另一个解决方法是采用延时复制,间歇性地开启从服务器上的同步功能,保证一段时间的延迟。
从服务器上可以启动read-only选项:
[mysqld]
read-only
这样从服务器上用户如果没有SUPER权限,对从服务器上的任何修改都会抛出一个错误。
最后
以上就是干净纸飞机最近收集整理的关于MySQL技术neimu InnoDB存储引擎 学习笔记 第八章 备份与恢复的全部内容,更多相关MySQL技术neimu内容请搜索靠谱客的其他文章。








发表评论 取消回复