小伙伴们,你们好,我是老寇
目录
一、前提条件
二、准备工作
三、ELK介绍
四、Kafka介绍
五、日志监控架构图
六、微服务集成
一、前提条件
- 搭建kafka集群
- 搭建elasticsearch集群
- 搭建微服务环境
二、准备工作
192.168.1.1(启动Elasticsearch集群 + Kafka集群)
192.168.1.2(启动Elasticsearch集群 + Kafka集群)
192.168.1.3(启动Elasticsearch集群 + Kafka集群)
三、ELK介绍
ELK由Elasticsearch、LogStash、Kibana三部分组成,应用于实时数据检索和分析
springboot 2.0 集成elk 7.6.2
Elasticsearch
简介
- 开源分布式搜索引擎,基于Lucene(全文检索引擎)开发的
- Java开发,通过RESTful Web接口,让用户通过浏览器与Elasticsearch通信
- 对大量的数据进行接近实时的存储,搜索和分析
特点
- 配置简单易上手,采用JSON接口
- 处理方式灵活
- 集群支持线性扩展
- 检索性能高效
功能
- 实时全文搜索数据
- 分析数据
- 存储数据
概念
NRT(近实时)
- 在进行搜索时,从索引的一个文档到这个文档被搜索出来,有一个轻微的延迟(通常1秒延迟)
shards(分片)
- 在实际情况下,索引存储的数据可能超过单个节点的硬件限制。如20亿的文档需要2TB,不适合存储在单节点的磁盘上,或单节点搜索请求太慢。因此,为了解决这个问题,elasticsearch提出将索引分成多个分片的功能。当创建索引时,可以定义想要分片的数量,每一个分片就是一个全功能独立的索引,可以存储在集群的任何节点上。分片的两个最主要的原因:水平分割扩展,增加存储量;分布式并行跨分片操作,提供性能和吞吐量
replicas(副本)
- 网络问题或其他问题都有可能造成数据丢失,为了数据的健壮性,需要有一个故障切换机制,防止发生任何故障导致分片或节点不可用,因此,需要将索引分片复制一份或多份,称为副本或分片副本。副本的两个主要原因:高可用行,以应对分片或节点故障,出于这个原因,分片副本要在不同的节点上面;高性能,增大吞吐量,搜索可以并行在所有副本上执行
index(索引)
- 索引是拥有几分相似特征的文档集合,类似数据库中的表,如一个客户数据索引、一个订单数据索引。对索引中的文档进行搜索、更新和删除,都要用到这个名字
document(文档)
- 文档是索引的基础信息单元,类似于数据库中的某条记录,如一条用户信息文档。文档以JSON格式来表示,索引中可以存储任何多的文档
cluster(集群)
- 由一个或多个节点组织在一起(集群也可以只有一个节点),它们共同持有你的整个数据,并一起提供索引和搜索功能。其中有一个节点为主节点,主节点可以通过选举产生,并提供跨节点的联合索引和搜索功能。每个节点加入集群都是基于集群名称加入的,因此,确保不同的环境中使用不同集群名称
node(节点)
- 节点是单一的服务器,是集群的一部分,存储数据并参与集群的索引和搜索功能,节点名称需要是唯一的,在集群中用于识别服务器对应的节点
type(类型)
- 一个索引可以定义一种或多种类型,用于对一组共同字段的文档定义一个类型,elasticsearch 7之后的版本废除该type
elasticsearch 7.6.2 单机搭建
elasticsearch 7.6.2 集群搭建
elasticsearch 索引管理
springboot 2.0集成elasticsearch 7.6.2
springboot 2.0集成elasticsearch 7.6.2 关键字高亮显示
mysql 5.7同步数据到es 7.6.2
Logstash
简介
- 用来收集、分析、过滤日志的开源工具,几乎支持任何类型的日志(系统日志、业务日志)
- 支持多种数据源接收日志(Mysql、Kafka),以多种方式输出数据(Elasticsearch、邮件)
windows安装logstash 7.6.2
Kibana
简介
- 开源工具,为Elasticsearch的日志分析提供友好的web界面
- 用于搜索、分析和可视化存在Elasticsearch指标中的日志数据
- 利用Elasticsearch的RESTful 接口来检索数据,不仅可以创建数据的定制仪表盘,还能以特殊的方式查询和过滤数据
windows安装kibana 7.6.2
四、Kafka介绍
Kafka是分布式的基于发布/订阅模式的消息队列,主要应用于大数据实时处理领域
Kafka
简介
- 分布式、支持分区(partition)、多副本(replica)基于Zookeeper协调的分布式消息中间件
- 使用scala语言编写,实时处理大量数据
特性
时效性
- 每秒可处理几十万条消息,延迟最低只有几毫秒;每个topic可以分多个分区(partition),Consumer Group对Partition进行消费,提高负载均衡和消费的能力,具备高吞吐,低延迟的特性
拓展性
- kafka集群支持热扩展
持久性
- 消息持久到本地磁盘,支持数据备份防止数据丢失
读写性能
- 支持数千个客户端同时读写
集群
- 一个kafka节点就是一个broker,消息由topic来承载,并且可以存储在1个或多个partition中,发布消息的应用是producer,消费消息的应用是consumer,多个consumer可以促成consumer group来共同消息一个topic中的消息
kafka 2.6.2 单机搭建
kafka 2.6.2 集群搭建
五、日志监控架构图
之前搭建ELK环境中,日志的处理流程为 logstash > elasticsearch,但是随着业务量的增长,需要对日志监控的架构进一步扩展,引入kafka集群。因此,日志的处理流程变为 kafka > logstash > elasticsearch
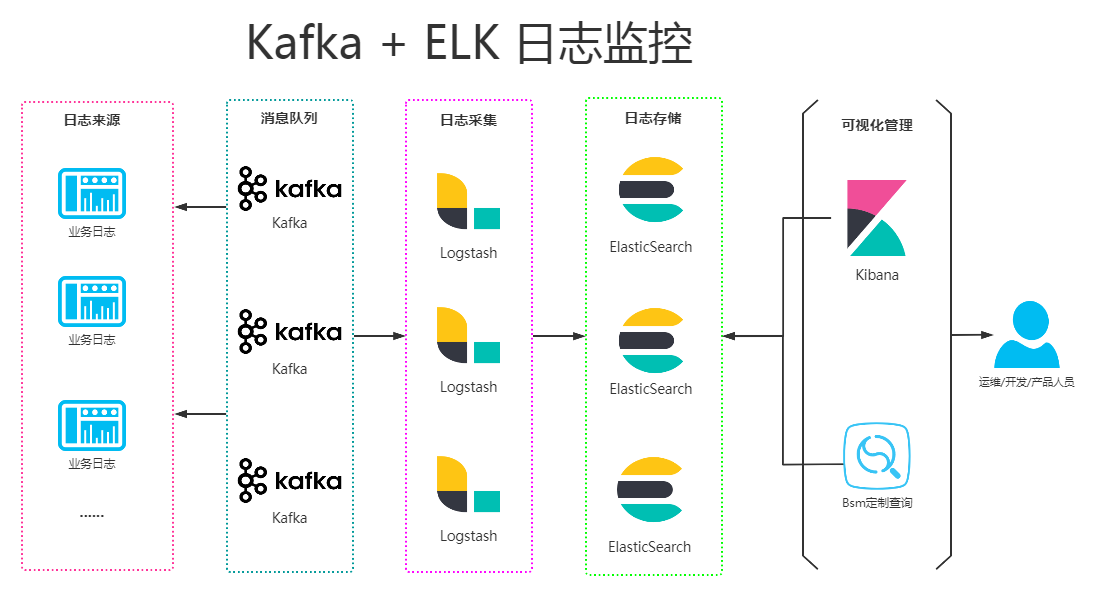
思考:ELK加入Kafka有什么好处?
- logstash client和logstash server之间没有消息缓存,如果server宕机不可用,会有消息丢失的风险。引入kafka消息机制,保证了即使logstash server因故障停止运行,数据也会缓存下来,避免数据丢失
- 由于在高并发环境下,数据读写特别频繁,导致logstash运行占用CPU和内存较高,kafka作为消息缓存队列解耦了处理过程,缓解系统的压力,同时提高了可扩展性,具有峰值处理能力,能够使关键组件顶住突发的访问压力,而不会因为并发的超负荷的请求而完全崩溃
六、微服务集成
请点击我,获取源码
springboot 2.0 集成elk 7.6.2
1.引入依赖
<!-- logback 推送日志文件到kafka -->
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.3</version>
</dependency>
<dependency>
<groupId>com.github.danielwegener</groupId>
<artifactId>logback-kafka-appender</artifactId>
<version>0.2.0-RC2</version>
</dependency>2.修改logback-spring.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<include resource="org/springframework/boot/logging/logback/base.xml" />
<logger name="org.springframework.web" level="INFO"/>
<logger name="org.springboot.sample" level="TRACE" />
<!-- 开发、测试环境 -->
<springProfile name="dev,test">
<logger name="org.springframework.web" level="INFO"/>
<logger name="org.springboot.sample" level="INFO" />
<logger name="io.laokou.elasticsearch" level="DEBUG" />
</springProfile>
<!-- 生产环境 -->
<springProfile name="prod">
<logger name="org.springframework.web" level="ERROR"/>
<logger name="org.springboot.sample" level="ERROR" />
<logger name="io.laokou.elasticsearch" level="ERROR" />
</springProfile>
<appender name="KAFKA" class="com.github.danielwegener.logback.kafka.KafkaAppender">
<!-- encoder负责两件事,一是把日志信息转换成字节数组,二是把字节数组写入到输出流 -->
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{35} - %msg %n</pattern>
</encoder>
<!-- 配置topic,自动创建topic -->
<topic>laokou-elasticsearch</topic>
<!-- 相关配置信息 -->
<keyingStrategy class="com.github.danielwegener.logback.kafka.keying.NoKeyKeyingStrategy" />
<deliveryStrategy class="com.github.danielwegener.logback.kafka.delivery.AsynchronousDeliveryStrategy" />
<!-- kafka集群地址 -->
<producerConfig>bootstrap.servers=192.168.1.1:9092,192.168.1.2:9092,192.168.1.3:9092</producerConfig>
<!-- acks=0 消息只要发送出去,不管那条数据有没有落在磁盘上,直接认为发送成功-->
<producerConfig>acks=0</producerConfig>
<!-- 消息量较少,过了1000ms自动发送出去 -->
<producerConfig>linger.ms=1000</producerConfig>
<!-- 消息不被阻塞 -->
<producerConfig>max.block.ms=0</producerConfig>
<appender-ref ref="CONSOLE" />
</appender>
<root level="INFO">
<appender-ref ref="KAFKA" />
</root>
</configuration>3.配置logstash.kafka.conf
input{
kafka {
#kafka服务地址
bootstrap_servers => "192.168.1.1:9092,192.168.1.2:9092,192.168.1.3:9092"
topics => "laokou-elasticsearch"
}
}
output{
elasticsearch{
hosts=>["192.168.1.1:9200","192.168.1.2:9200","192.168.1.3:9200"]
index => "laokou-elasticsearch-%{+YYYY.MM.dd}"
}
stdout{
codec => rubydebug
}
}4.启动logstash 和 kibana
logstash -f logstash.kafka.conf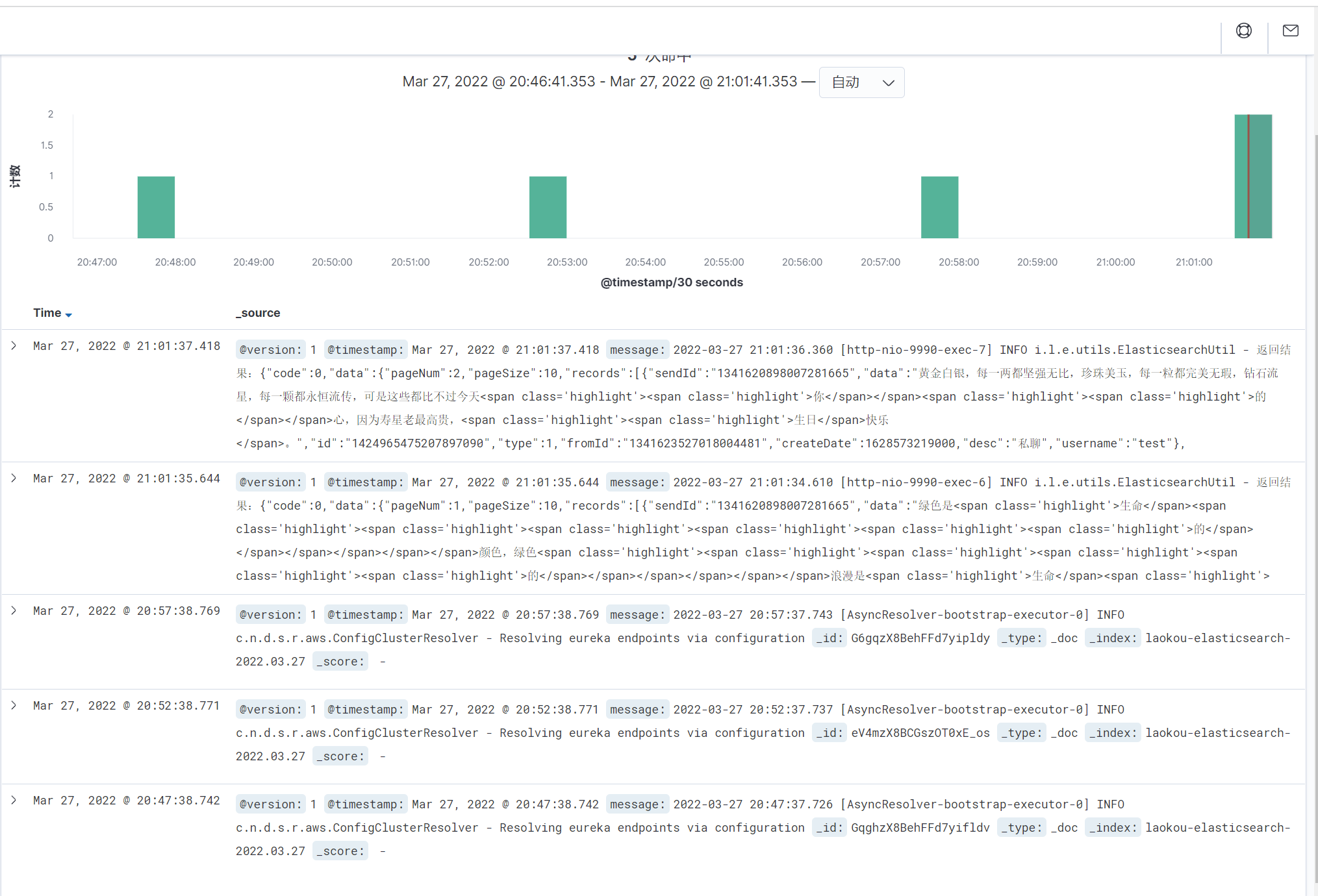
大功告成
参考博文:ELK日志分析系统(基本原理简介+ELK群集部署)
参考博文:消息队列(MQ)与kafaka概述(Filebeat+Kafka+ELK部署)
参考博文:Kafka总结(八):KafKa与ELK整合应用
参考博文:ELK-基础系列(六)-ELK加入消息队列-Kafka部署
最后
以上就是坦率纸鹤最近收集整理的关于springboot 2.0 集成 kafka 2.6.2(集群) + elk 7.6.2(集群)目录的全部内容,更多相关springboot内容请搜索靠谱客的其他文章。








发表评论 取消回复