1:环境准备
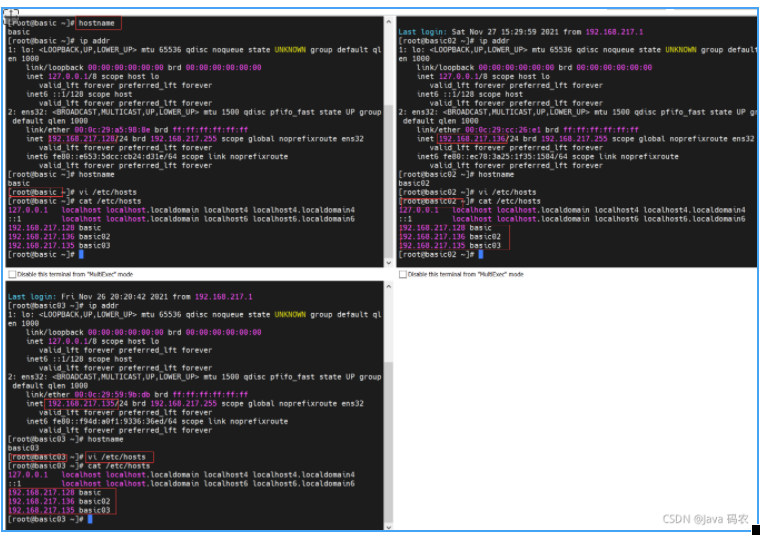
使用 hostnamectl 在三台机器上修改主机名 分别为 basic basic02 basic03
vi /etc/hosts 在三台机器上分别添加如下内容
192.168.217.128 basic
192.168.217.136 basic02
192.168.217.135 basic03
在生产环境需要开端口
4369 Erlang端口
25672 集群通信端口
15672 Rabbitmq管理控制台端口
5672 Rabbitmq服务端口
8100 HAProxy 配置监控页面绑定端口
5671 HAProxy rabbitmq_cluster集群通信端口
学习的时候只需要关闭防火墙
同时还需要关闭 selinux ,关闭selinux如果不关闭,会阻止其他的应用执行shell脚本
SELINUX=enforcing
#此项定义selinux状态。
#enforcing—是强制模式系统受selinux保护,违反了策略将无法继续操作
#permissive—是提示模式系统不会受到selinux保护,只是收到警告信息
permissive就是Selinux有效,但是即使你违反了策略任然可以继续操作
但是会把违反安全的内容记录下来(警告信息)
#disabled—禁用selinux
SELINUXTYPE=targeted
#此项定义selinux使用哪个策略模块保护系统。targeted只对apache,sendmail,bind,postgresql,nfs,cifs等网络服务保护。
以上策略配置都放置在/etc/selinux目录中,目录和策略名称相同
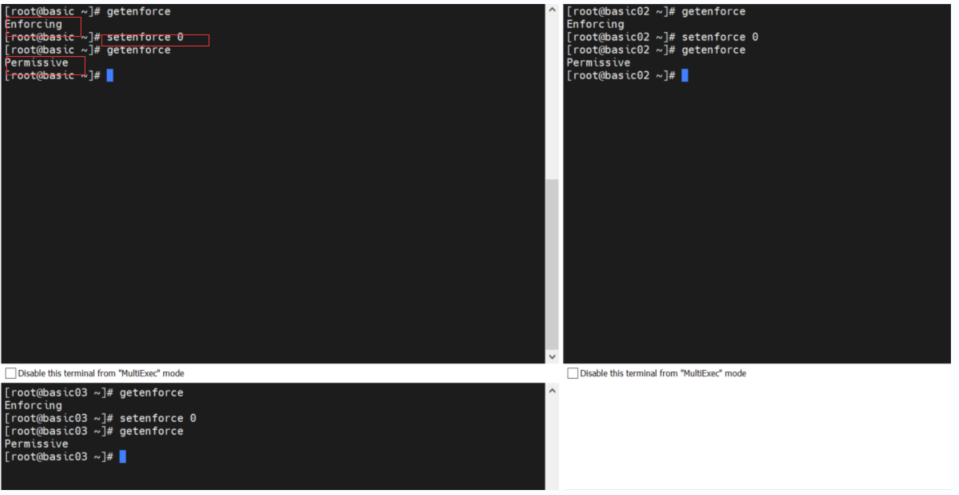
getenforce 查看 selinux 状态
setenforce 临时禁用 sudo setenforce 0 状态变为 Permissive
永久关闭SELINUX
修改方式1: vim /etc/selinux/config
修改 SELINUX=enforcing 为 SELINUX=disabled
reboot
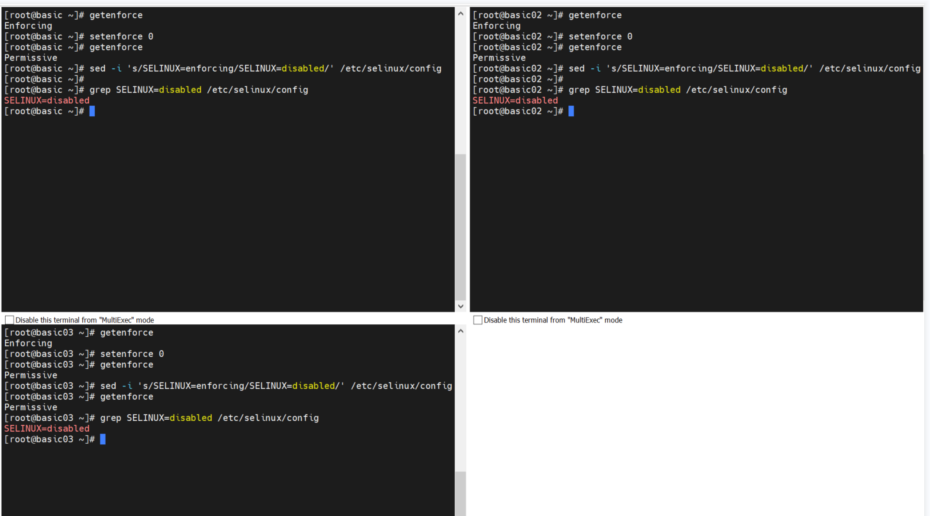
修改方式2:
sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
grep SELINUX=disabled /etc/selinux/config
reboot
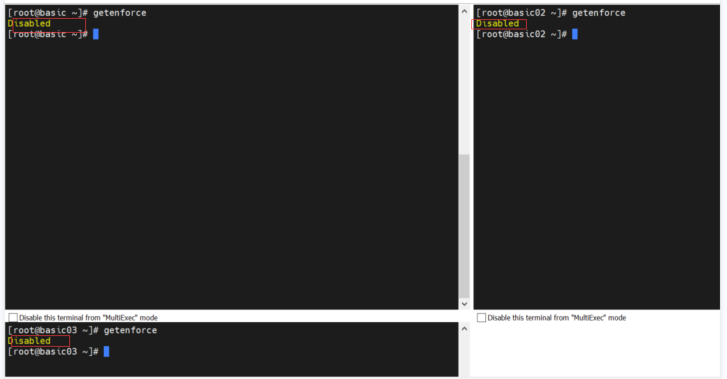
修改完成之后 查看状态
getenforce
2:Rabbitmq 安装
在三台机器都安装 Erlang 环境,因为 RabbitMQ 运行需要Erlang支持
安装步骤请参考 RabbitMQ 实战_Java 码农的博客-CSDN博客
3: 集群安装
当单台 RabbitMQ 服务器的处理消息的能力达到瓶颈时,此时可以通过 RabbitMQ 集群来进行扩展,从而达到提升吞吐量的目的。集群还有可以解决单点问题当节点挂掉以后,集群中的其他节点可以继续提供服务,当出现问题的几点修复后小虹心加入集群可以继续提供服务,节点间信息是相互同步的, RabbitMQ 集群是一个或多个节点的逻辑分组,集群中的每个节点都是对等的,每个节点共享所有的用户,虚拟主机,队列,交换器,绑定关系,运行时参数和其他分布式状态等信息.
3.1: 普通集群
在完成三台机器上的 Erlang 和 RabbitMq之后 ,将basic上的 .erlang.cookie文件拷贝到其他两台主机上(basic02,basic03) ,cookie文件相当于密钥令牌,集群中的RabbitMQ节点需要通过交换密钥令牌以获得相互认证,否则在搭建过程中会出现 Authentication Fail错误。RabbitMQ服务启动时,erlangVM会自动创建该cookie文件.
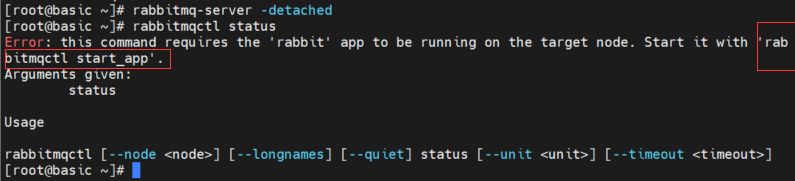
启动 rabbitmq 的时候 报错
rabbitmq-server -detached 会同时启动 Erlang 和 Rabbitmq
rabbitmqctl start_app 开启 rabbitmqctl start_app 关闭 (这两个只启动或关闭 Rabbitmq)
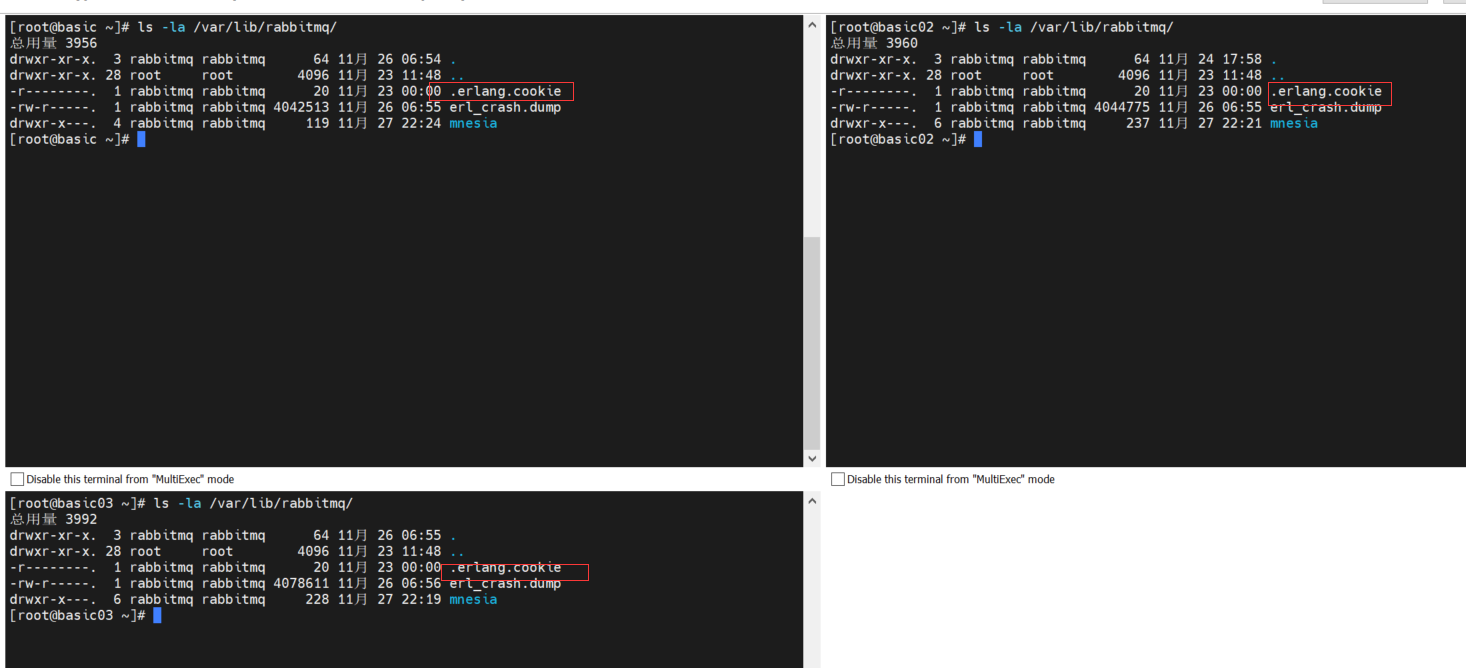
查看.erlang.cookie文件目录 默认的存储路径为 /var/lib/rabbitmq/.erlang.cookie
ls -la /var/lib/rabbitmq/
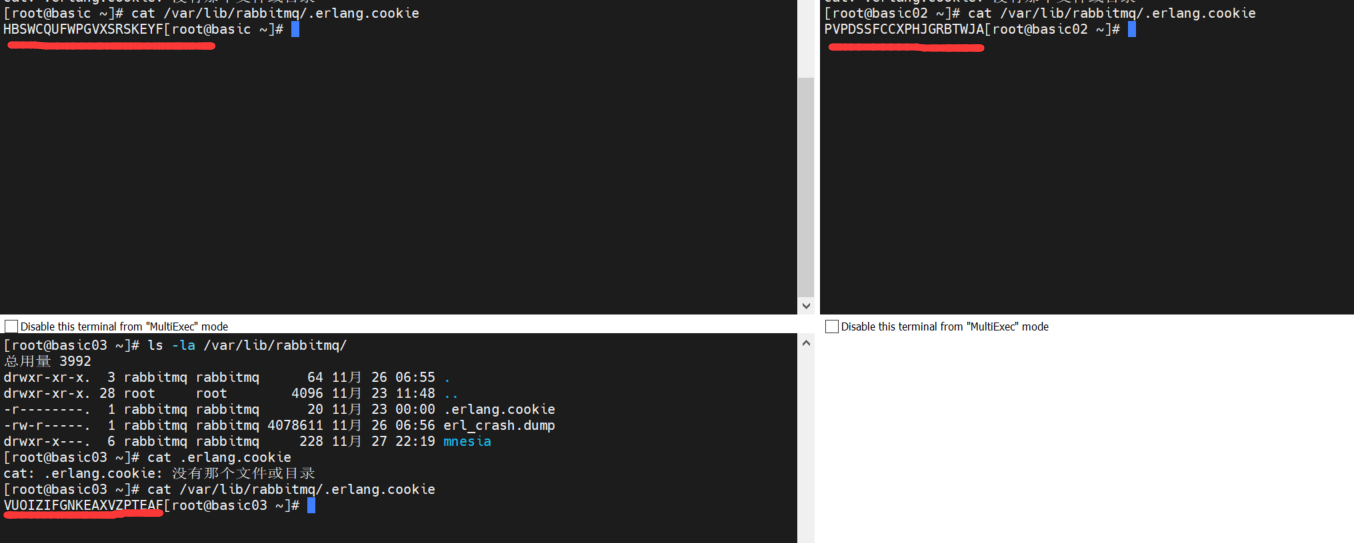
cat .erlang.cookie
查看 .erlang.cookie 的内容
关闭三个机器上的服务 rabbitmqctl stop
在basic 执行拷贝命令将.erlang.cookie 拷贝到basic02,basic03的/var/lib/rabbitmq/目录下
scp /var/lib/rabbitmq/.erlang.cookie root@basic02:/var/lib/rabbitmq/
scp /var/lib/rabbitmq/.erlang.cookie root@basic03:/var/lib/rabbitmq/
cookie文件原来的权限改为 400
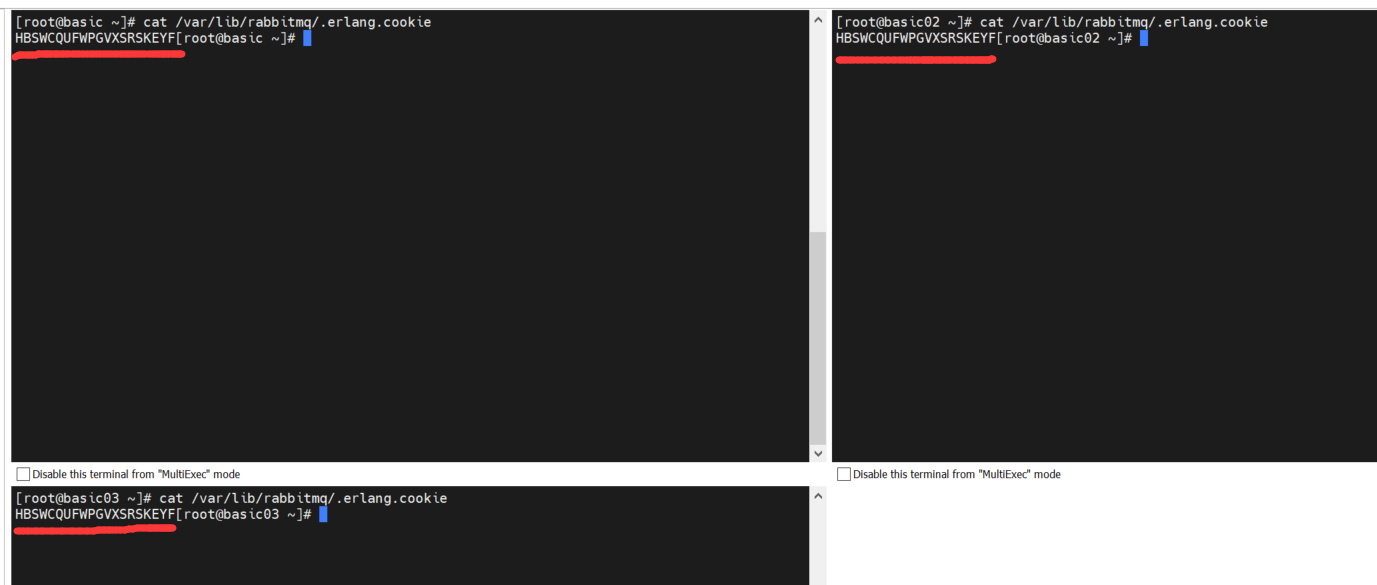
再次查看.erlang.cookie 的内容,cookie 一致了
cat /root/.erlang.cookie
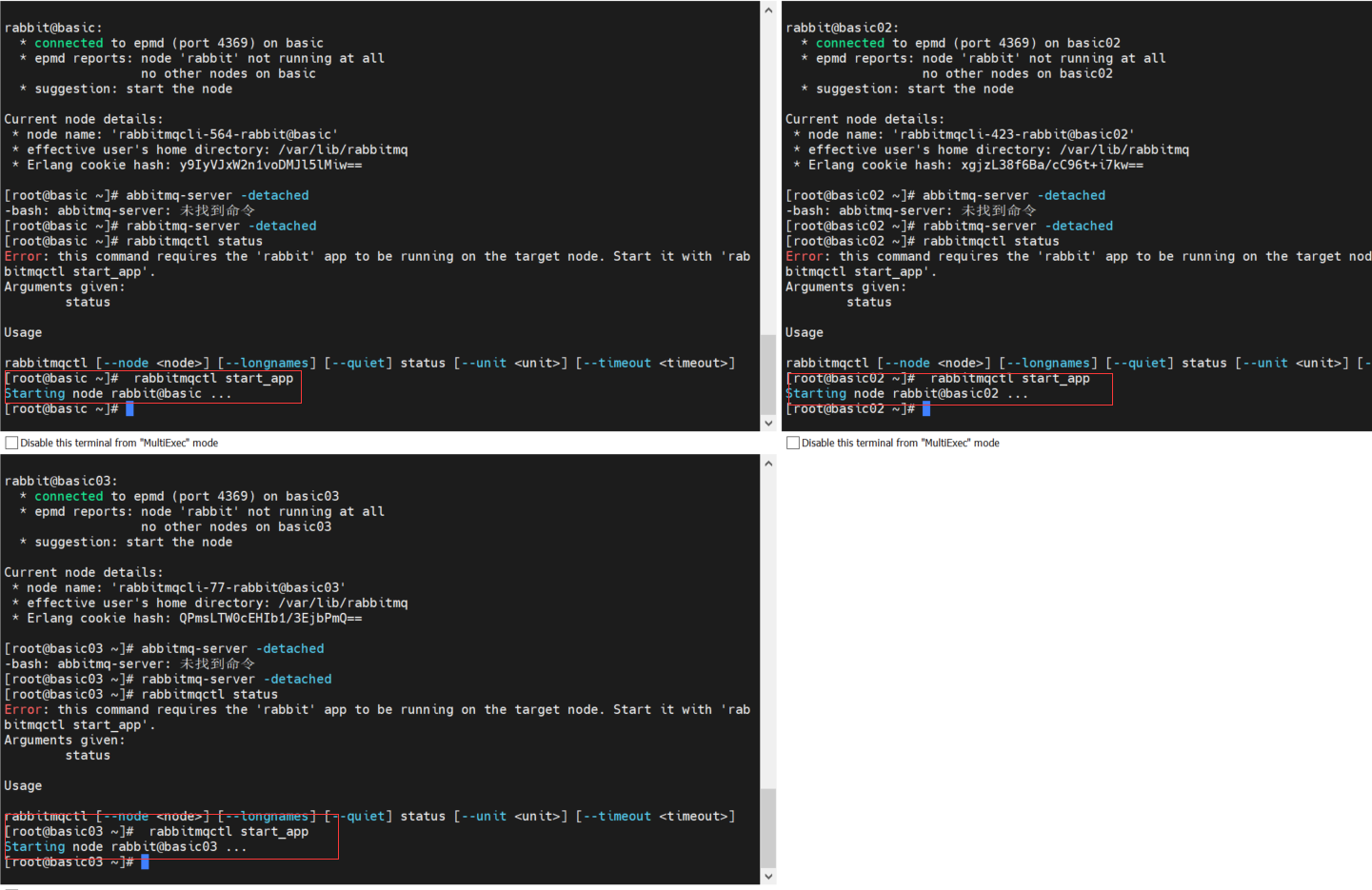
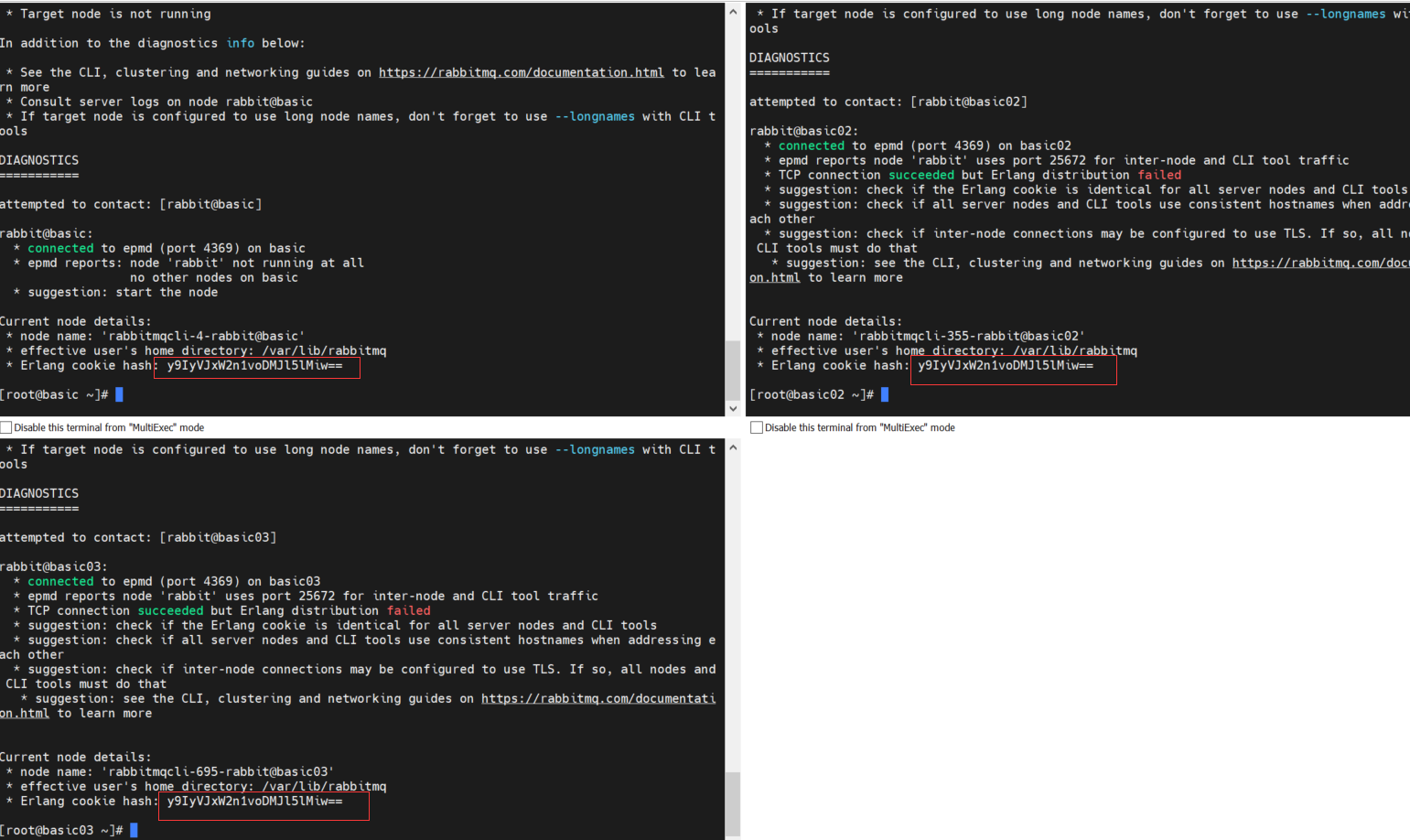
在三台主机上均执行以下命令,启动 RabbitMQ 服务
rabbitmqctl start_app
启动的时候可以看到三台机器的 hash 都是相同的了,说明 .erlang.cookie 一致并且生效了
rabbitmq-server -detached 命令会同时启动 Erlang 虚拟机和 RabbitMQ 应用服务而
rabbitmqctl start_app 只会启动 RabbitMQ 应用服务, rabbitmqctl stop_app 只会停止 RabbitMQ 服务
RabbitMQ 集群的搭建需要选择其中任意一个节点为基准
将其它节点逐步加入,这里我们以basic为基准节点将basic02 和 basic03 加入集群
在basic02 和 basic03 上执行以下命令:
basic02 上执行
# .启动服务
rabbitmqctl start_app
在basic03 上执行以下命令:
# .停止服务
rabbitmqctl stop_app
# .重置状态
rabbitmqctl reset
# .节点加入
rabbitmqctl join_cluster --disc rabbit@basic
# .启动服务
rabbitmqctl start_app
basic03 上执行
# .启动服务
rabbitmqctl start_app
在basic03 上执行以下命令:
# .停止服务
rabbitmqctl stop_app
# .重置状态
rabbitmqctl reset
# .节点加入
rabbitmqctl join_cluster --ram rabbit@basic02
# .启动服务
rabbitmqctl start_app
不要把两个节点都 往 basic 上挂 否者会报异常
Starting node rabbit@basic03 ...
Error:
{:rabbit, {{:timeout_waiting_for_tables, [:rabbit@basic02, :rabbit@basic, :rabbit@basic03], [:rabbit_delayed_messagerabbit@basic03, :rabbit_delayed_messagerabbit@basic03_index]}, {:rabbit, :start, [:normal, []]}}}

如果出现了这个异常 需要做如下步骤 (重要)
rabbitmqctl stop_app
rm -rf /var/lib/rabbitmq/mnesia/*
rabbitmqctl forget_cluster_node rabbit@basic03
在发生错误的节点执行
rabbitmqctl stop_app
删除 rm -rf /var/lib/rabbitmq/mnesia/* 删除 文件
主节点中将该节点移除集群: rabbitmqctl forget_cluster_node rabbit@发生错误的主机名basic03
然后 重启该节点
rabbitmqctl start_app
再此执行
# .停止服务
rabbitmqctl stop_app
# .重置状态
rabbitmqctl reset
# .节点加入
rabbitmqctl join_cluster --ram rabbit@basic02 把Basic03加入到Basic02 ,而不是 Basic
# .启动服务
rabbitmqctl start_app
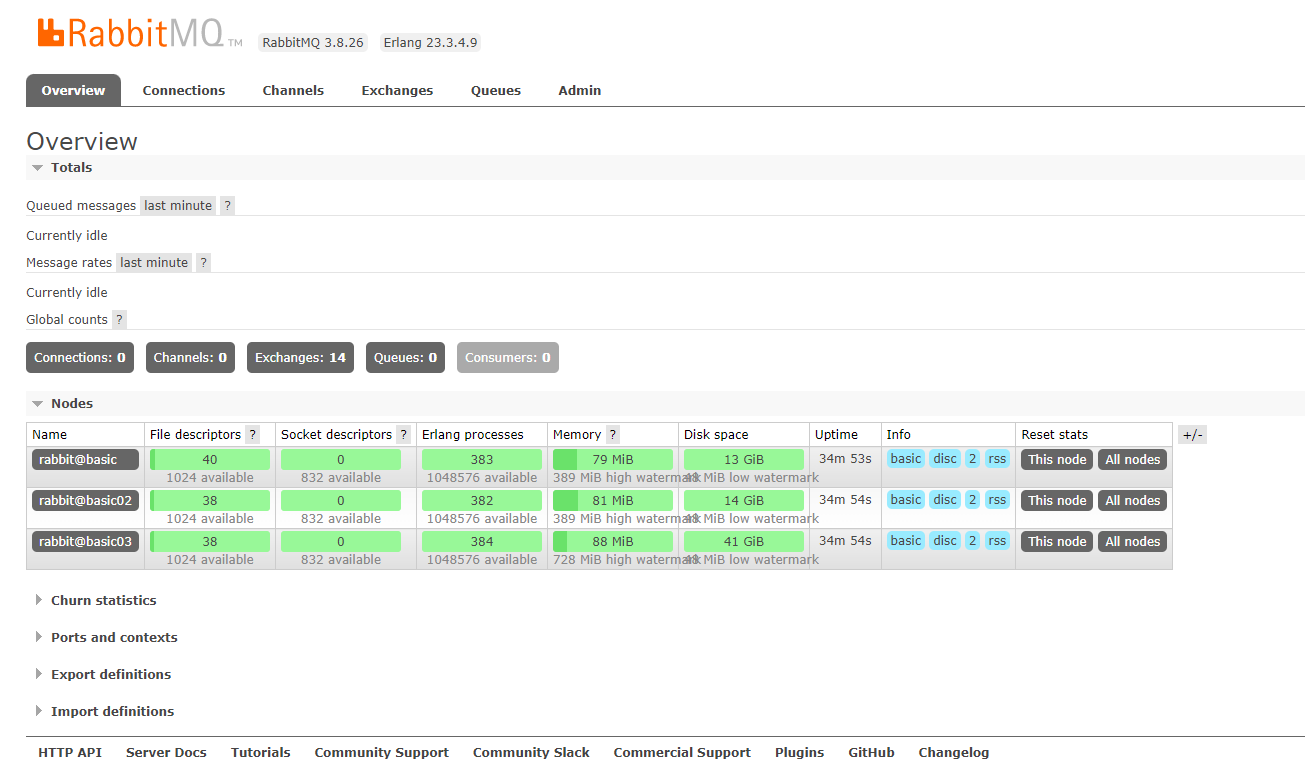
此时一个普通集群就搭建起来了,我们可以查看管理控制台,
其他节点:
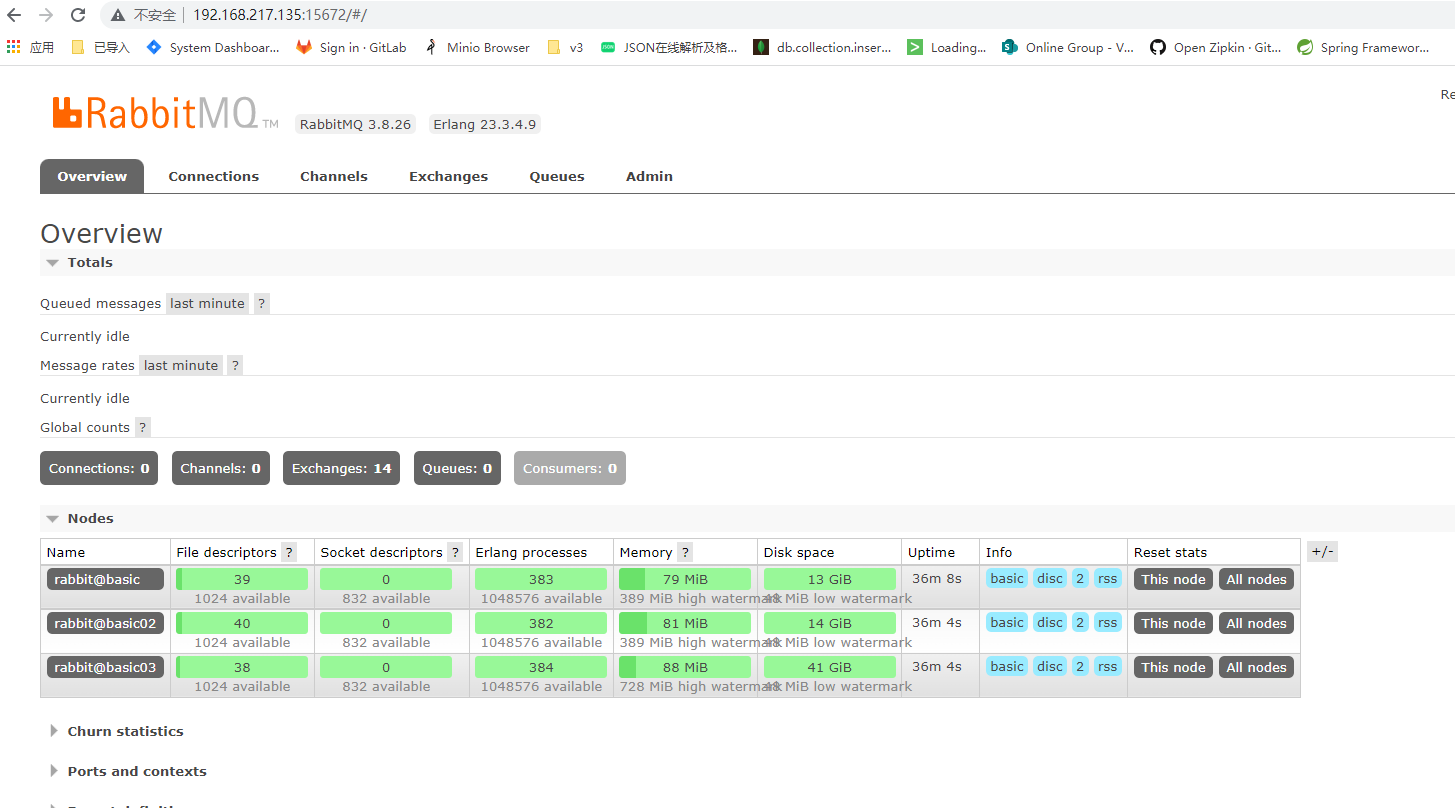
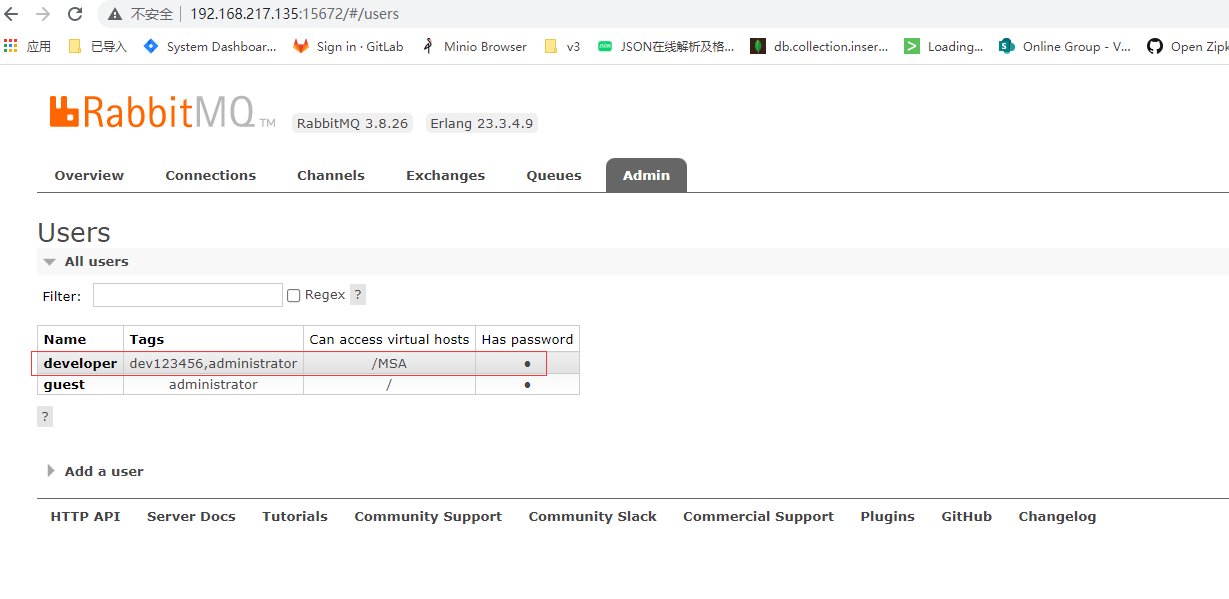
rabbitmqctl cluster_status 在任意一个节点查看集群状态
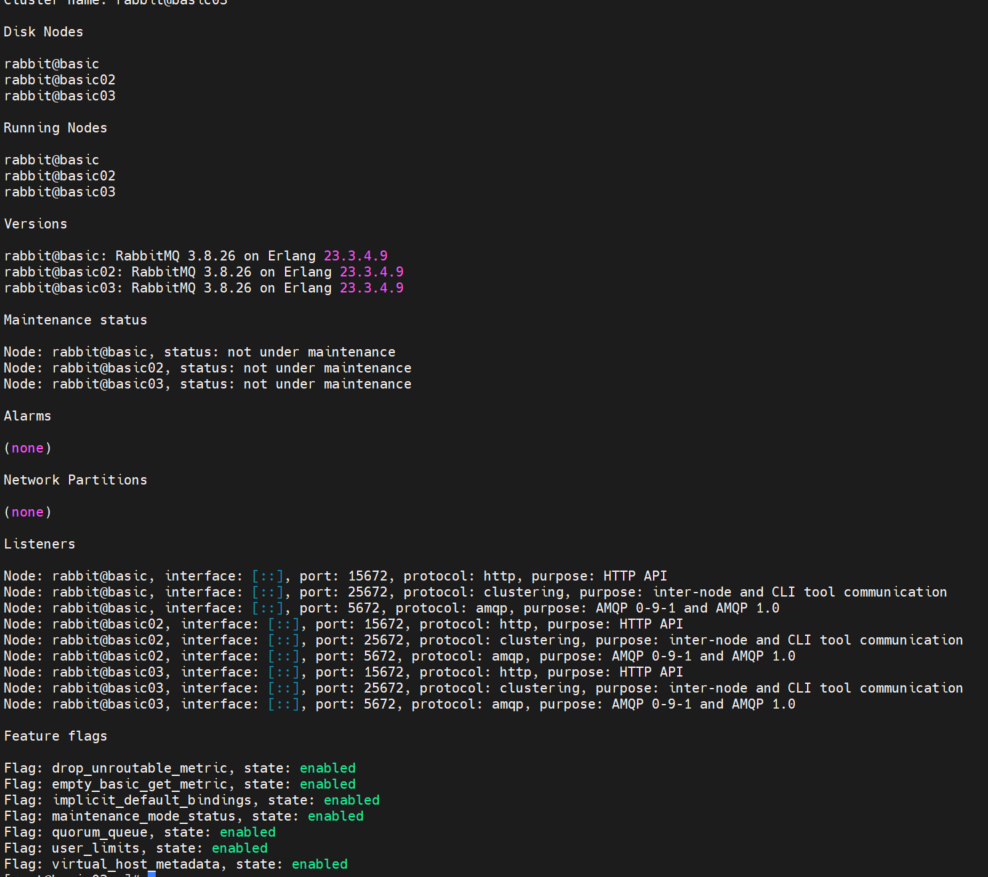
但是默认的这种集群,是无法在各个节点之间保存数据的,数据只会保存在接受到消息的节点上
当 ram 的节点挂了之后 数据会丢失
3.2: 镜像集群
开启镜像集群,这里我们为所有队列开启镜像配置,高可用策略,其语法如下:
rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}' 表示开启HA模式 适用于所有的队列
在上面我们指定了 ha-mode 的值为 all ,代表消息会被同步到所有节点的相同队列中。这里我们之所以这样配置,因为我们本身只有三个节点,因此复制操作的性能开销比较小。如果你的集群有很多节点,那么此时复制的性能开销就比较大,此时需要选择合适的复制系数。通常可以遵循过半写原则,即对于一个节点数为 n 的集群,只需要同步到 n/2+1 个节点上即可。此时需要同时修改镜像策略为 exactly,并指定复制系数 ha-params,示例命令如下:
给默认的 所有的 添加高可用策略
rabbitmqctl set_policy ha-two "^" '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'
给指定的 /MSA 添加高可用策略
rabbitmqctl set_policy ha-two "/MSA" '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'
![]()
官网的 镜像高可用配置
Classic Queue Mirroring — RabbitMQ
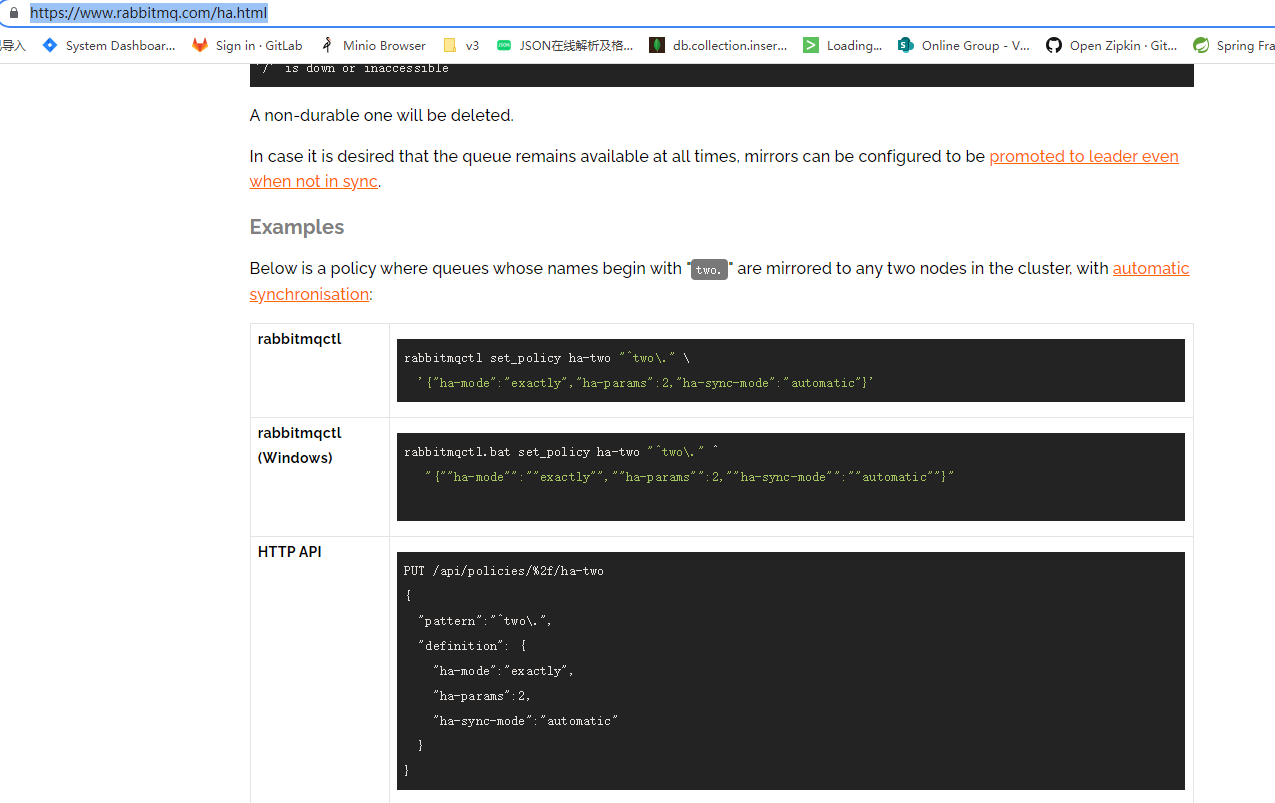
其他策略配置
官网路径 Parameters and Policies — RabbitMQ
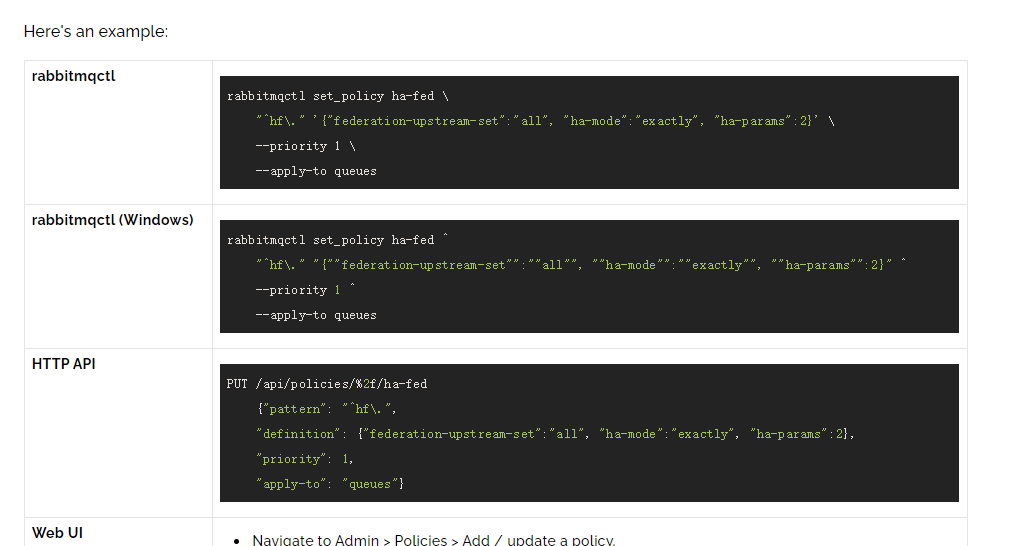
除此之外,RabbitMQ 还支持使用正则表达式来过滤需要进行镜像操作的队列,示例如下:
rabbitmqctl set_policy ha-all "^ha." '{"ha-mode":"all"}'
节点下线
以上介绍的集群搭建的过程就是服务扩容的过程,如果想要进行服务缩容,即想要把某个节点剔除集群,有两种可选方式:
第一种:可以先使用 rabbitmqctl stop 停止该节点上的服务,然后在其他任意一个节点上执行 forget_cluster_node 命令。
这里以剔除 basic03 上的服务为例,此时可以在 basic01 或 basic02 上执行下面的命令:
rabbitmqctl forget_cluster_node rabbit@basic03
第二种方式:先使用 rabbitmqctl stop 停止该节点上的服务,然后再执行 rabbitmqctl reset 这会清空该节点上所有历史数据,并主动通知集群中其它节点它将要离开集群。
没有一个直接的命令可以关闭整个集群,需要逐一进行关闭。但是需要保证在重启时,最后关闭的节点最先被启动。如果第一个启动的不是最后关闭的节点,那么这个节点会等待最后关闭的那个节点启动,默认进行 10 次连接尝试,超时时间为 30 秒,如果依然没有等到,则该节点启动失败
使用镜像集群的代码 后面还会贴上来:
依赖:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<!-- 必须的依赖 -->
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.2.RELEASE</version>
<relativePath/>
</parent>
<groupId>org.rsp</groupId>
<artifactId>rabbitMQ-sp</artifactId>
<version>1.0-SNAPSHOT</version>
<name>rabbitMQ-sp</name>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<!-- 必须的依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.amqp</groupId>
<artifactId>spring-amqp</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.amqp</groupId>
<artifactId>spring-rabbit</artifactId>
</dependency>
<!-- https://mvnrepository.com/artifact/org.springframework.amqp/spring-rabbit-test -->
<dependency>
<groupId>org.springframework.amqp</groupId>
<artifactId>spring-rabbit-test</artifactId>
<version>2.3.10</version>
<scope>test</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.projectlombok/lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.22</version>
<scope>provided</scope>
</dependency>
<!--swagger图形化接口 開始-->
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger2</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger-ui</artifactId>
<version>2.9.2</version>
</dependency>
<!--swagger图形化接口結束-->
<!-- https://mvnrepository.com/artifact/commons-io/commons-io -->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.9.0</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
配置类
package org.rsp.config;
import lombok.extern.slf4j.Slf4j;
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.DirectExchange;
import org.springframework.amqp.core.Queue;
import org.springframework.amqp.rabbit.connection.CachingConnectionFactory;
import org.springframework.amqp.rabbit.connection.ConnectionFactory;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.beans.factory.config.ConfigurableBeanFactory;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Scope;
/**
Broker:它提供一种传输服务,它的角色就是维护一条从生产者到消费者的路线,保证数据能按照指定的方式进行传输,
Exchange:消息交换机,它指定消息按什么规则,路由到哪个队列。
Queue:消息的载体,每个消息都会被投到一个或多个队列。
Binding:绑定,它的作用就是把exchange和queue按照路由规则绑定起来.
Routing Key:路由关键字,exchange根据这个关键字进行消息投递。
vhost:虚拟主机,一个broker里可以有多个vhost,用作不同用户的权限分离。
Producer:消息生产者,就是投递消息的程序.
Consumer:消息消费者,就是接受消息的程序.
Channel:消息通道,在客户端的每个连接里,可建立多个channel.
*/
@Slf4j
@Configuration
public class RabbitConfig2 {
@Value("${spring.rabbitmq.addresses}")
private String addresses;
@Value("${spring.rabbitmq.username}")
private String username;
@Value("${spring.rabbitmq.password}")
private String password;
public static final String EXCHANGE_A = "my-mq-exchange_A";
public static final String EXCHANGE_B = "my-mq-exchange_B";
public static final String EXCHANGE_C = "my-mq-exchange_C";
public static final String QUEUE_A = "QUEUE_A";
public static final String QUEUE_B = "QUEUE_B";
public static final String QUEUE_C = "QUEUE_C";
public static final String ROUTINGKEY_A = "spring-boot-routingKey_A";
public static final String ROUTINGKEY_B = "spring-boot-routingKey_B";
public static final String ROUTINGKEY_C = "spring-boot-routingKey_C";
//使用自定义工厂类的方式 ,这种方式适合于 要区别 不同的 vitural host 的时候
//需要将工厂类和模板类区根据业务别开的时候使用
@Bean
public ConnectionFactory connectionFactory() {
CachingConnectionFactory connectionFactory = new CachingConnectionFactory();
connectionFactory.setAddresses(addresses);
connectionFactory.setUsername(username);
connectionFactory.setPassword(password);
connectionFactory.setVirtualHost("/MSA");
connectionFactory.setPublisherConfirms(true); //开启发布确认
return connectionFactory;
}
@Bean
@Scope(ConfigurableBeanFactory.SCOPE_PROTOTYPE)
//必须是prototype类型
public RabbitTemplate rabbitTemplate() {
RabbitTemplate template = new RabbitTemplate(connectionFactory());
return template;
}
//定义交换机 队列 路由 和绑定关系
/**
* 针对消费者配置
* 1. 设置交换机类型
* 2. 将队列绑定到交换机
FanoutExchange: 将消息分发到所有的绑定队列,无routingkey的概念
HeadersExchange :通过添加属性key-value匹配
DirectExchange:按照routingkey分发到指定队列
TopicExchange:多关键字匹配
*/
@Bean
public DirectExchange defaultExchange() {
return new DirectExchange(EXCHANGE_A);
}
/**
* 获取队列A
* @return
*/
@Bean
public Queue queueA() {
return new Queue(QUEUE_A, true); //队列持久
}
@Bean
public Binding binding() {
return BindingBuilder.bind(queueA()).to(defaultExchange()).with(RabbitConfig2.ROUTINGKEY_A);
}
}
配置文件:
spring:
rabbitmq:
addresses: 192.168.217.128:5672,192.168.217.135:5672,192.168.217.136:5672
username: developer
password: dev123456
virtual-host: /MSA
server:
port: 8888
生产者:
package org.rsp.producer;
import lombok.extern.slf4j.Slf4j;
import org.rsp.config.RabbitConfig2;
import org.springframework.amqp.rabbit.connection.CorrelationData;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.util.UUID;
@Slf4j
@Component
public class MsgProducer implements RabbitTemplate.ConfirmCallback {
//由于rabbitTemplate的scope属性设置为ConfigurableBeanFactory.SCOPE_PROTOTYPE,所以不能自动注入
private RabbitTemplate rabbitTemplate;
/**
* 构造方法注入rabbitTemplate
*/
@Autowired
public MsgProducer(RabbitTemplate rabbitTemplate) {
this.rabbitTemplate = rabbitTemplate;
rabbitTemplate.setConfirmCallback(this); //rabbitTemplate如果为单例的话,那回调就是最后设置的内容
}
public void sendMsg(String content) {
CorrelationData correlationId = new CorrelationData(UUID.randomUUID().toString());
//把消息放入ROUTINGKEY_A对应的队列当中去,对应的是队列A
rabbitTemplate.convertAndSend(RabbitConfig2.EXCHANGE_A, RabbitConfig2.ROUTINGKEY_A, content, correlationId);
}
/**
* 回调
*/
@Override
public void confirm(CorrelationData correlationData, boolean ack, String cause) {
log.info(" 回调id:" + correlationData);
if (ack) {
log.info("消息成功消费");
} else {
log.info("消息消费失败:" + cause);
}
}
}
消费者:
package org.rsp;
import lombok.extern.slf4j.Slf4j;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.stereotype.Component;
@Slf4j
@Component
public class TestConsumer {
@RabbitListener(queues = "spring-queue")
public void test(Message message){
log.info("收到下消息:"+message);
}
@RabbitListener(queues = "QUEUE_A")
public void test2(String content){
log.info("收到下消息:"+content);
}
}
发送消息的接口
package org.rsp;
import lombok.extern.slf4j.Slf4j;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.stereotype.Component;
@Slf4j
@Component
public class TestConsumer {
@RabbitListener(queues = "spring-queue")
public void test(Message message){
log.info("收到下消息:"+message);
}
@RabbitListener(queues = "QUEUE_A")
public void test2(String content){
log.info("收到下消息:"+content);
}
}
执行发送消息查看管理控制台
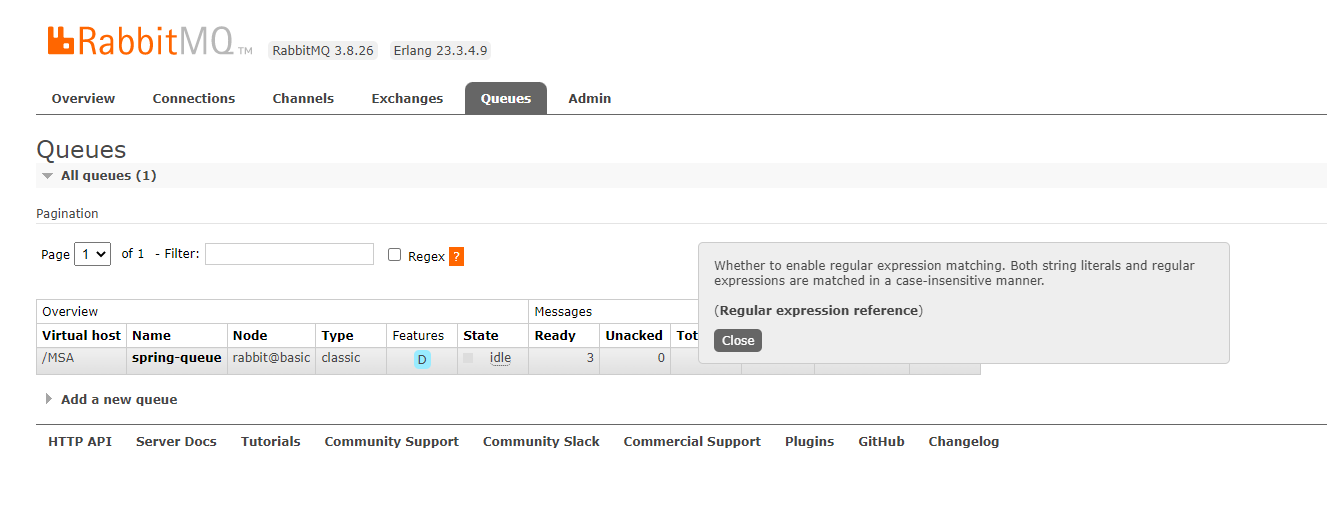
再查看 消费端的 控制台信息可以看到信息已经被消费了
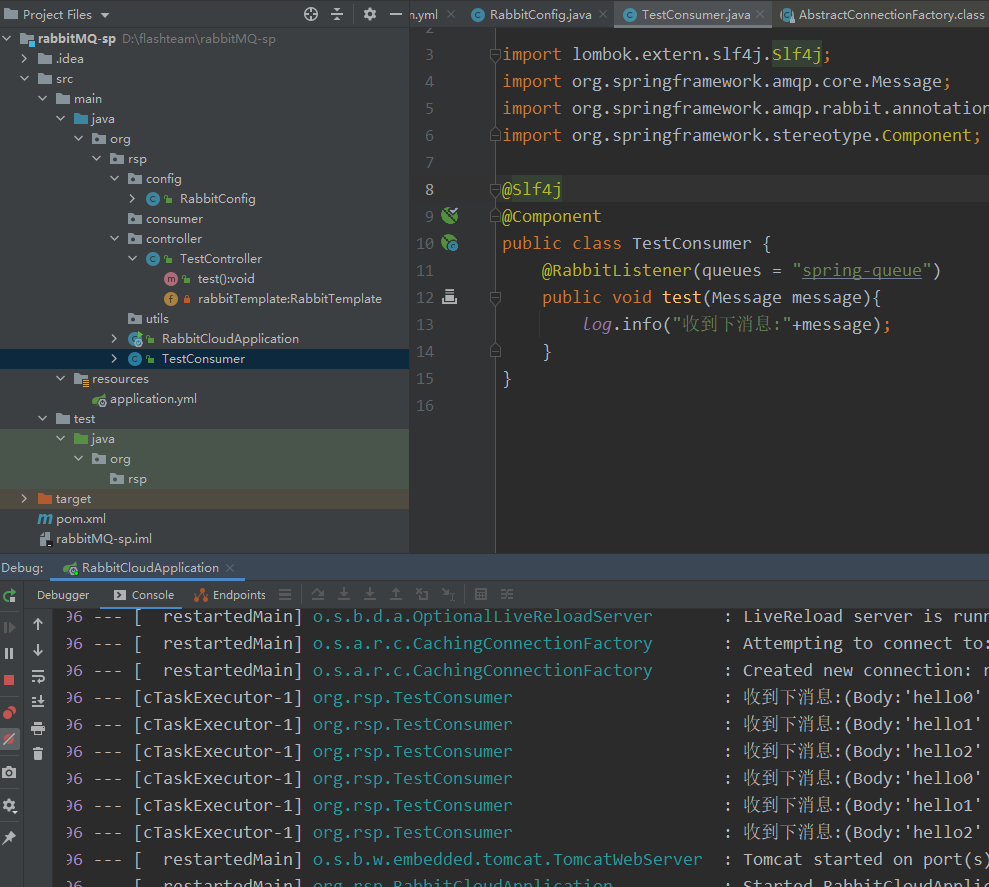
至此 镜像集群的安装 链接 以及简单的代码演示完成
完整代码路径
https://github.com/wanglei111000/rabbitMqMirrorQueen
3.3 高可用集群
借鉴的网图,能说明我们想要搭建的高可用集群就可以了
在3.2中这种集群还有缺点 ,就是当我们的集群节点很多的时候,在做代码开发的时候,需要要在代码中写很多链接的IP信息,然而在很多大型的公司里面 这是不可取的,我们只想在代码里面写一个ip ,由负载均Haproxy 和 keppalived 来实现 ip 的漂移和故障转移.
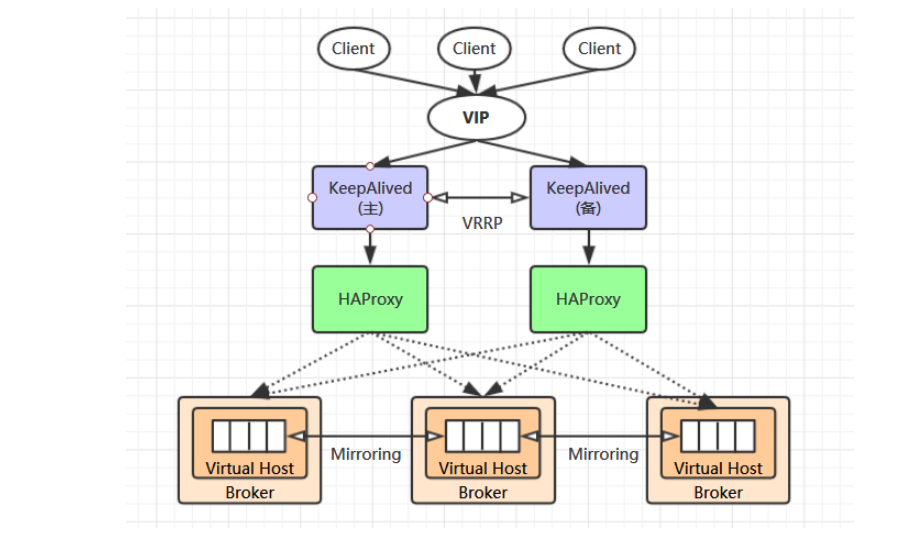
按照架构图 三个镜像队列我们已经准备好了 ,还需要 两个 haproxy 和keepalive
3.3.1Haproxy 安装
https://www.haproxy.org/#down HAProxy 官网
https://src.fedoraproject.org/repo/pkgs/haproxy/ 镜像网站
tar -zxvf haproxy-2.4.8.tar.gz -C /usr/local
进入解压后根目录,执行下面的编译命令:
cd /usr/local
mkdir haproxy
cd haproxy-2.4.8
make TARGET=linux-glibc PREFIX=/usr/local/haproxy
make install PREFIX=/usr/local/haproxy
配置环境变量:vim /etc/profile
export HAPROXY_HOME=/usr/local/haproxy
export PATH=$PATH:$HAPROXY_HOME/sbin
使得配置的环境变量立即生效
source /etc/profile
新建配置文件 haproxy.cfg,位置为:/etc/haproxy/haproxy.cfg,文件内容如下
# 全局配置
global
# 日志输出配置、所有日志都记录在本机,通过 local0 进行输出
log 127.0.0.1 local0 info
# 最大连接数
maxconn 4096
# 改变当前的工作目录
chroot /usr/local/haproxy
# 以指定的 UID 运行 haproxy 进程
uid 99
# 以指定的 GID 运行 haproxy 进程
gid 99
# 以守护进行的方式运行
daemon
# 当前进程的 pid 文件存放位置
pidfile /usr/local/haproxy/haproxy.pid
# 默认配置
defaults
# 应用全局的日志配置
log global
# 使用4层代理模式,7层代理模式则为"http"
mode tcp
# 日志类别
option tcplog
# 不记录健康检查的日志信息
option dontlognull
# 3次失败则认为服务不可用
retries 3
# 每个进程可用的最大连接数
maxconn 2000
# 连接超时
timeout connect 5s
# 客户端超时
timeout client 120s
# 服务端超时
timeout server 120s
# 绑定配置
listen rabbitmq_cluster
bind :5671
# 配置TCP模式
mode tcp
# 采用加权轮询的机制进行负载均衡
balance roundrobin
# RabbitMQ 集群节点配置
server node1 basic:5672 check inter 5000 rise 2 fall 3 weight 1
server node2 basic02:5672 check inter 5000 rise 2 fall 3 weight 1
server node3 basic03:5672 check inter 5000 rise 2 fall 3 weight 1
# 配置监控页面
listen monitor
bind :8100
mode http
option httplog
stats enable
stats uri /stats
stats refresh 5s
查看 配置 cat /etc/haproxy/haproxy.cfg
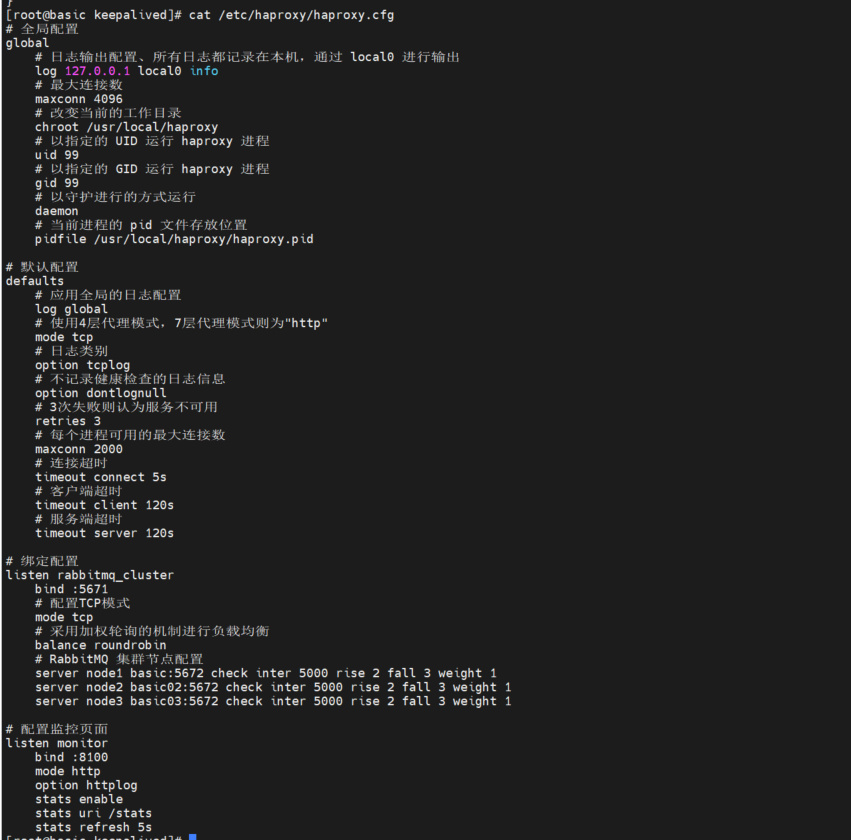
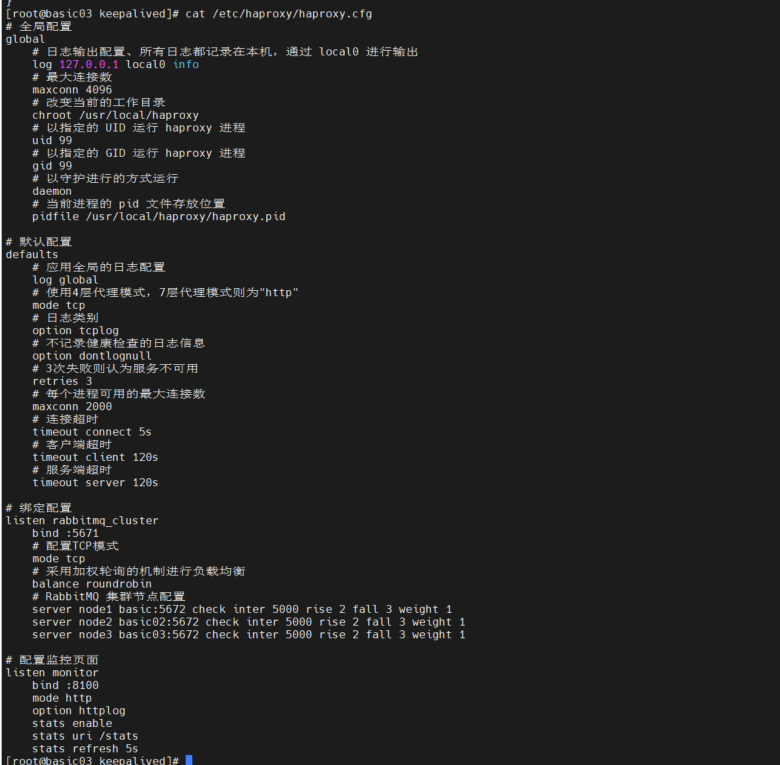
负载均衡的主要配置在 listen rabbitmq_cluster 下,这里指定负载均衡的方式为加权轮询,同时定义好健康检查机制:
server node1 basic:5672 check inter 5000 rise 2 fall 3 weight 1
以上配置代表对地址为 basic:5672 的 node1 节点每隔 5 秒进行一次健康检查,如果连续两次的检查结果都是正常,则认为该节点可用,此时可以将客户端的请求轮询到该节点上;如果连续 3 次的检查结果都不正常,则认为该节点不可用。weight 用于指定节点在轮询过程中的权重
启动haproxy服务
haproxy -f /etc/haproxy/haproxy.cfg
查看 Haproxy 启动状态

http://192.168.217.128:8100/stats
http://192.168.217.135:8100/stats
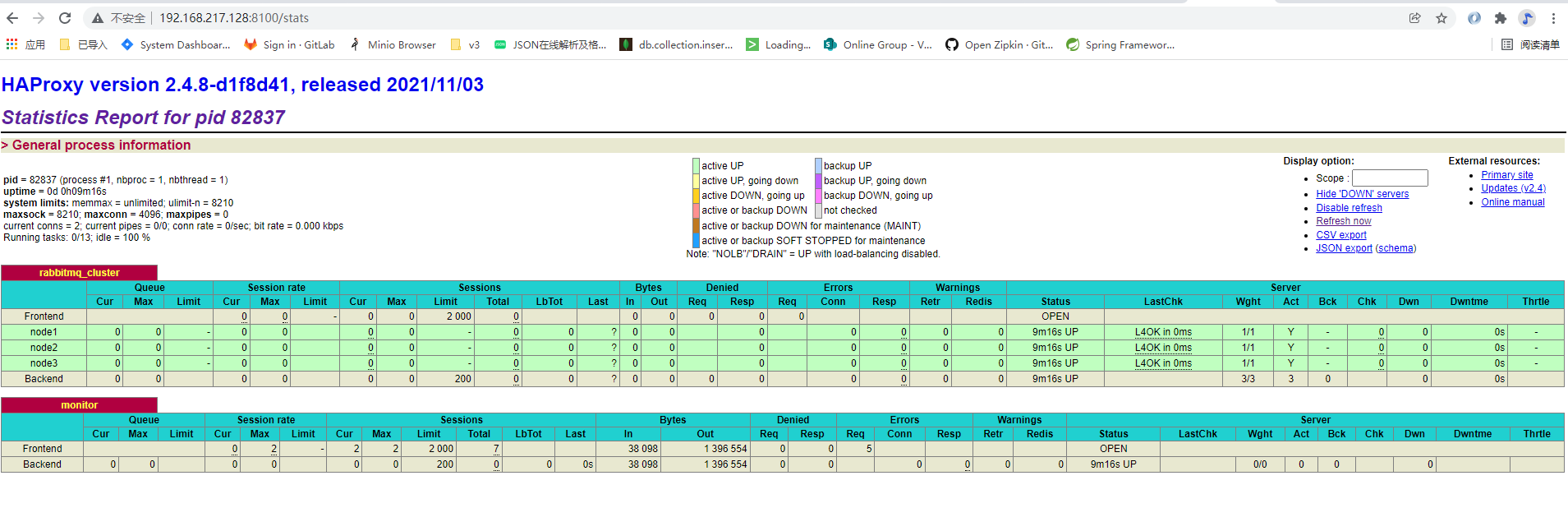
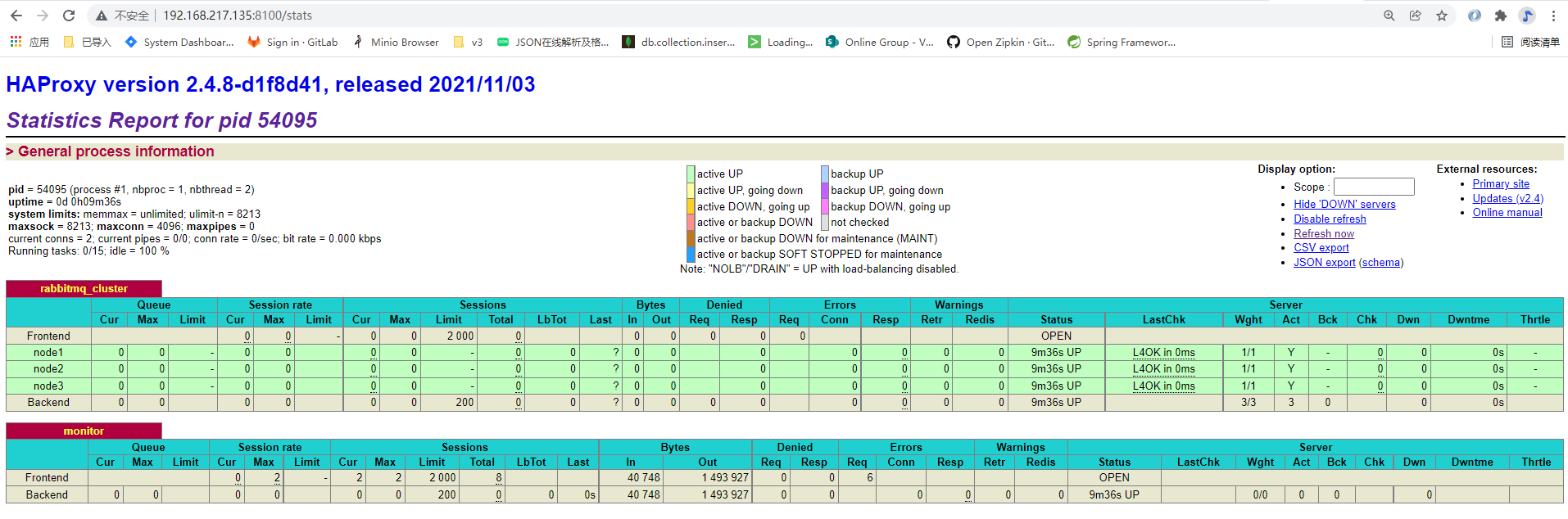
可以看到发送消费消息数量已经被监控到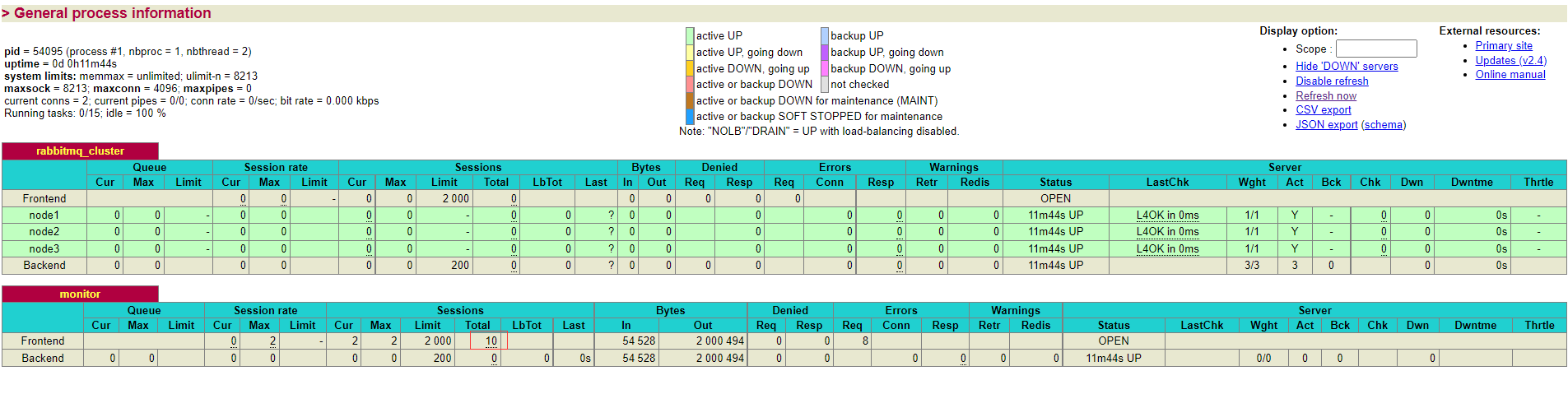
haProxy 安装完成
3.3.2: keepalive 安装配置
yum install -y keepalived
rpm -ql keepalived 查看 安装配置位置
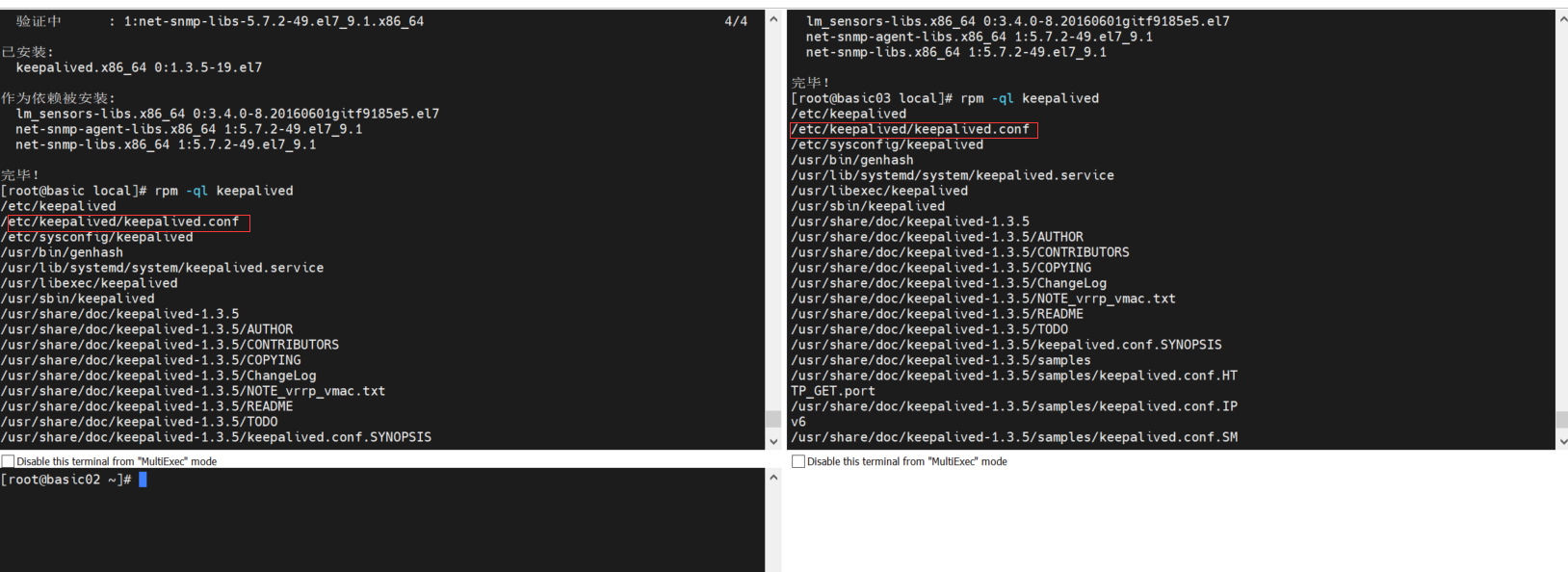
cp /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf.bak 备份配置文件
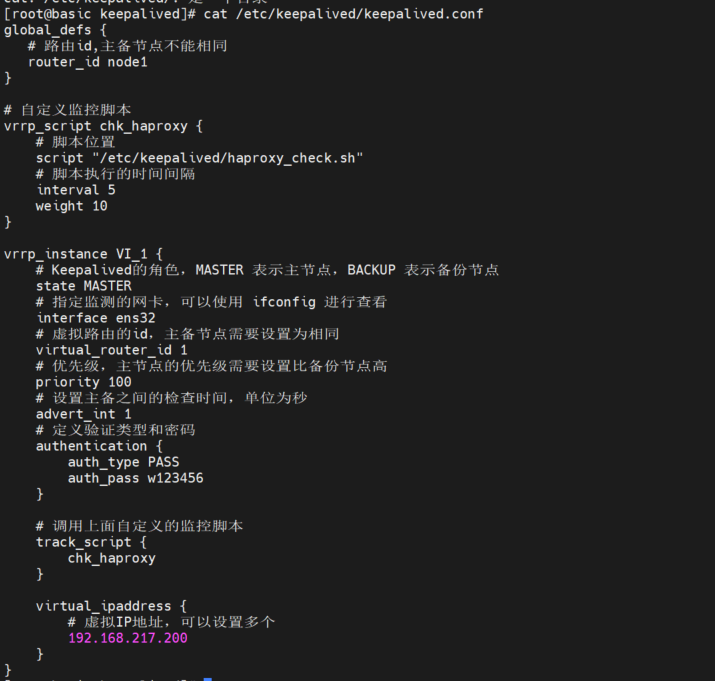
修改 basic 中的 keepalived.conf
echo "" > keepalived.conf
vim keepalived.conf 添加如下内容
global_defs {
# 路由id,主备节点不能相同
router_id node1
}
# 自定义监控脚本
vrrp_script chk_haproxy {
# 脚本位置
script "/etc/keepalived/haproxy_check.sh"
# 脚本执行的时间间隔
interval 5
weight 10
}
vrrp_instance VI_1 {
# Keepalived的角色,MASTER 表示主节点,BACKUP 表示备份节点
state MASTER
# 指定监测的网卡,可以使用 ifconfig 进行查看
interface ens32
# 虚拟路由的id,主备节点需要设置为相同
virtual_router_id 1
# 优先级,主节点的优先级需要设置比备份节点高
priority 100
# 设置主备之间的检查时间,单位为秒
advert_int 2
# 定义验证类型和密码
authentication {
auth_type PASS
auth_pass w123456
}
# 调用上面自定义的监控脚本
track_script {
chk_haproxy
}
virtual_ipaddress {
# 虚拟IP地址,可以设置多个
192.168.217.200
}
}
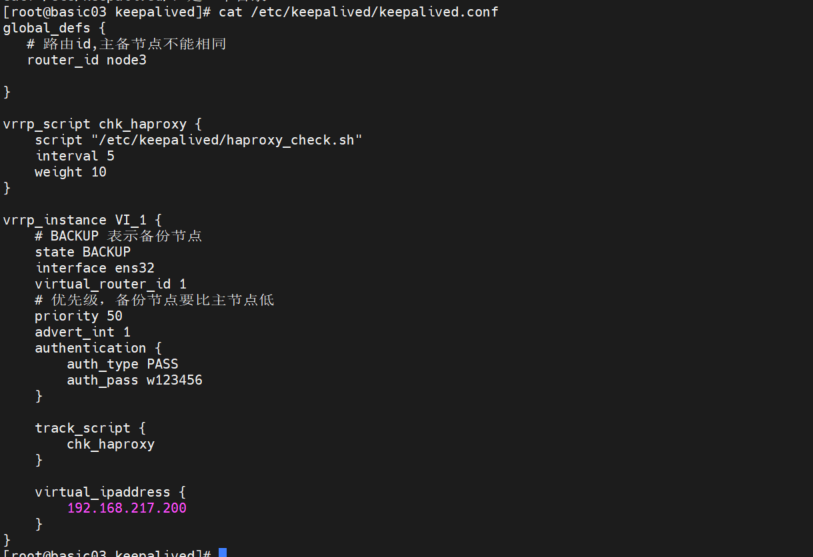
修改 basic03 中的 keepalived.conf
echo "" > keepalived.conf
vim keepalived.conf 添加如下内容
global_defs {
# 路由id,主备节点不能相同
router_id node3
}
vrrp_script chk_haproxy {
script "/etc/keepalived/haproxy_check.sh"
interval 5
weight 10
}
vrrp_instance VI_1 {
# BACKUP 表示备份节点
state BACKUP
interface ens32
virtual_router_id 1
# 优先级,备份节点要比主节点低
priority 50
advert_int 2
authentication {
auth_type PASS
auth_pass w123456
}
track_script {
chk_haproxy
}
virtual_ipaddress {
192.168.217.200
}
}
cd /etc/keepalived/ 进入文件夹
分别在 basic 和 basic03 机器的 /etc/keepalived/ 编写一个文件haproxy_check.sh 内容是一致的
#!/bin/bash
# 判断haproxy是否已经启动
if [ ${ps -C haproxy --no-header |wc -l} -eq 0 ] ; then
#如果没有启动,则启动
haproxy -f /etc/haproxy/haproxy.cfg
fi
#睡眠3秒以便haproxy完全启动
sleep 3
#如果haproxy还是没有启动,此时需要将本机的keepalived服务停掉,以便让VIP自动漂移到另外一台haproxy
if [ ${ps -C haproxy --no-header |wc -l} -eq 0 ] ; then
systemctl stop keepalived
fi
创建后为其赋予执行权限: chmod +x /etc/keepalived/haproxy_check.sh
分别在 basic 和 basic03 上启动 KeepAlived 服务
service keepalived start 开启服务
systemctl stop keepalived 关闭服务
使用 ip a 命令查看到虚拟 IP 的情况
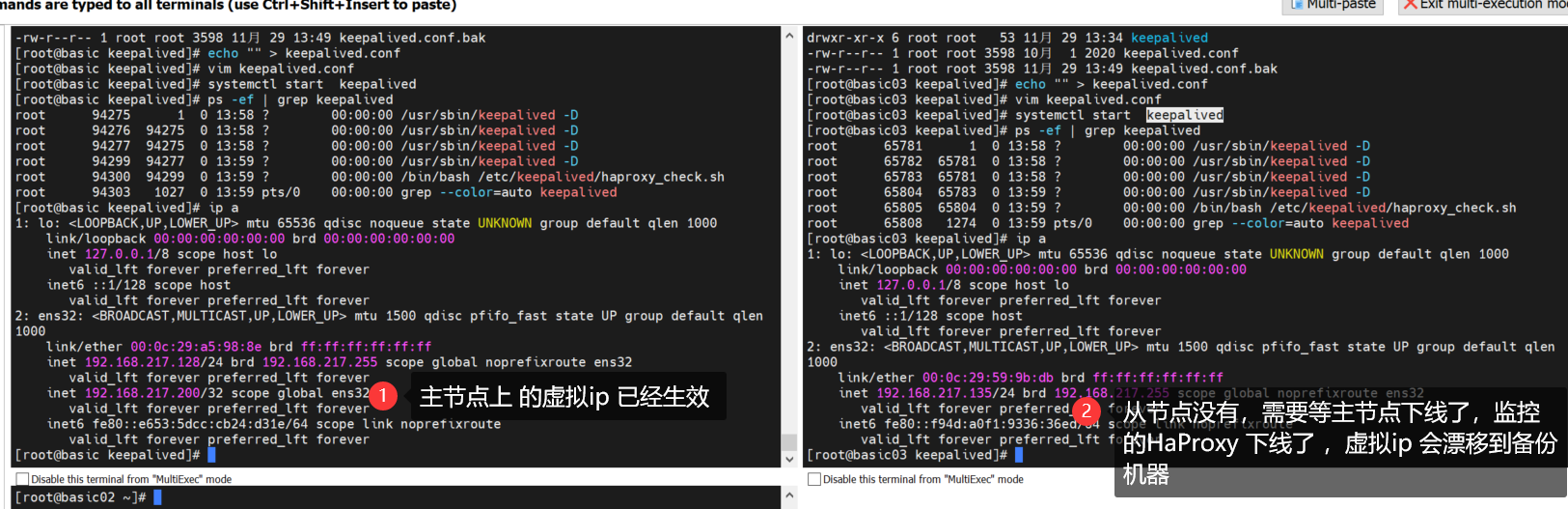
模拟basic 下线 ,虚拟ip 转移到basic03

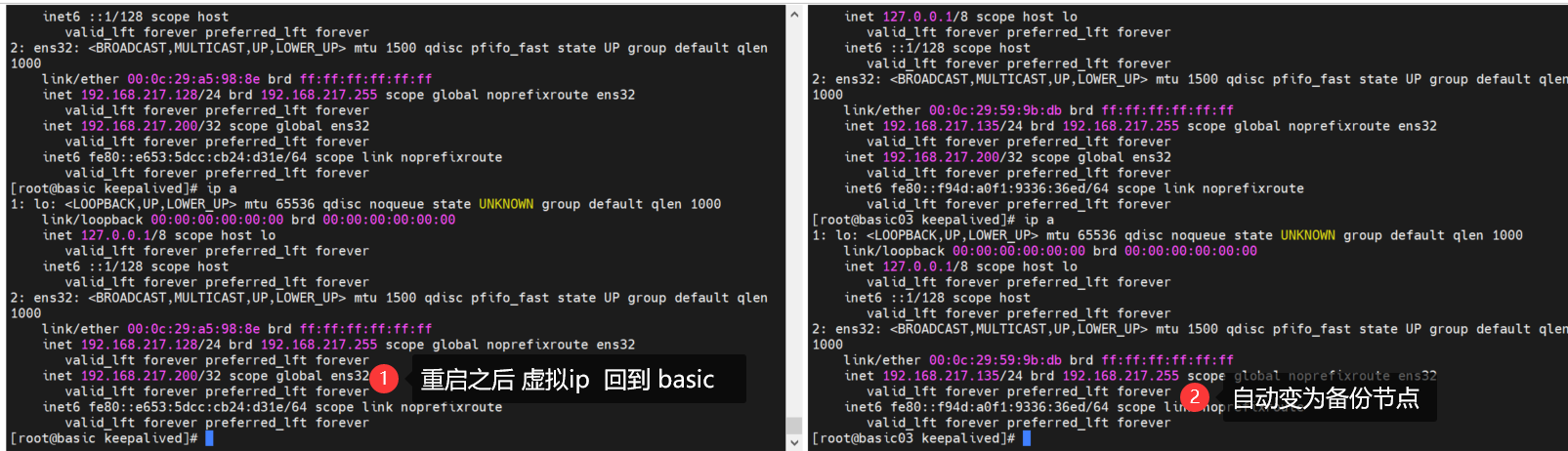
重启 basic 和观察状态 会自动将虚拟ip 切回 ,而basic03 将自动切换为备份节点状态
自此 keepalived + haproxy + rabbitmq 高可用集群 搭建完成
3.3.3: 代码验证高可用集群
将我们之前直接连接镜像集群的代码 稍微做一点更改,然后启动服务 ,不停的发送消息
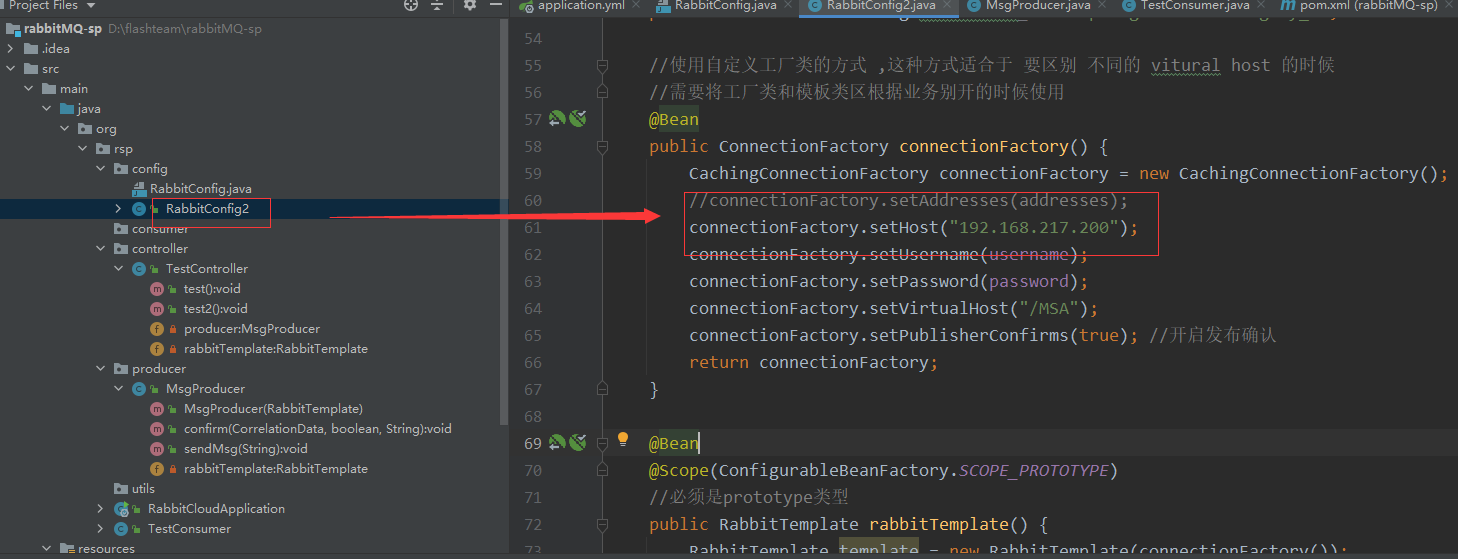
启动日志中可以发现 连接上了虚拟节点
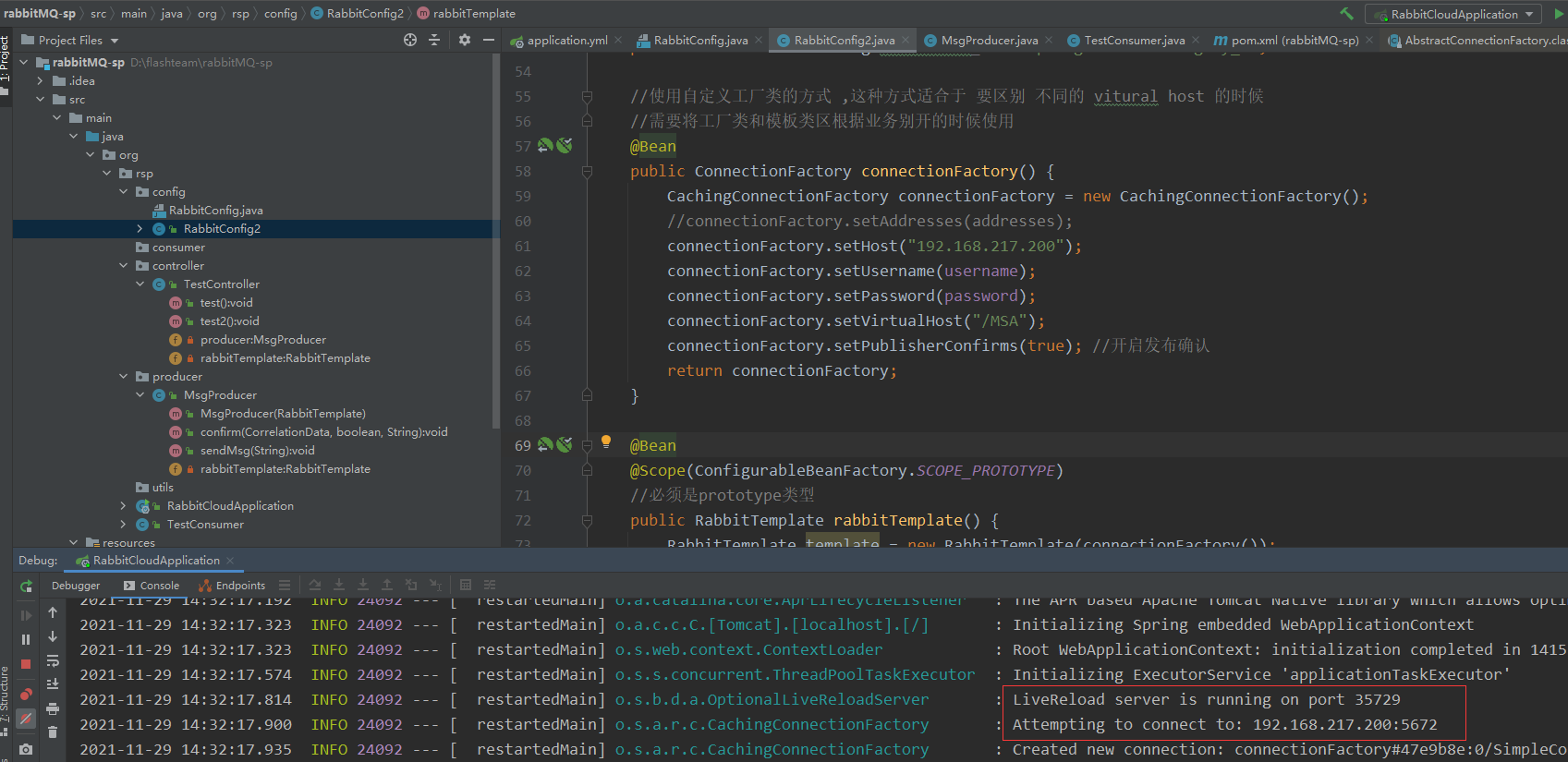
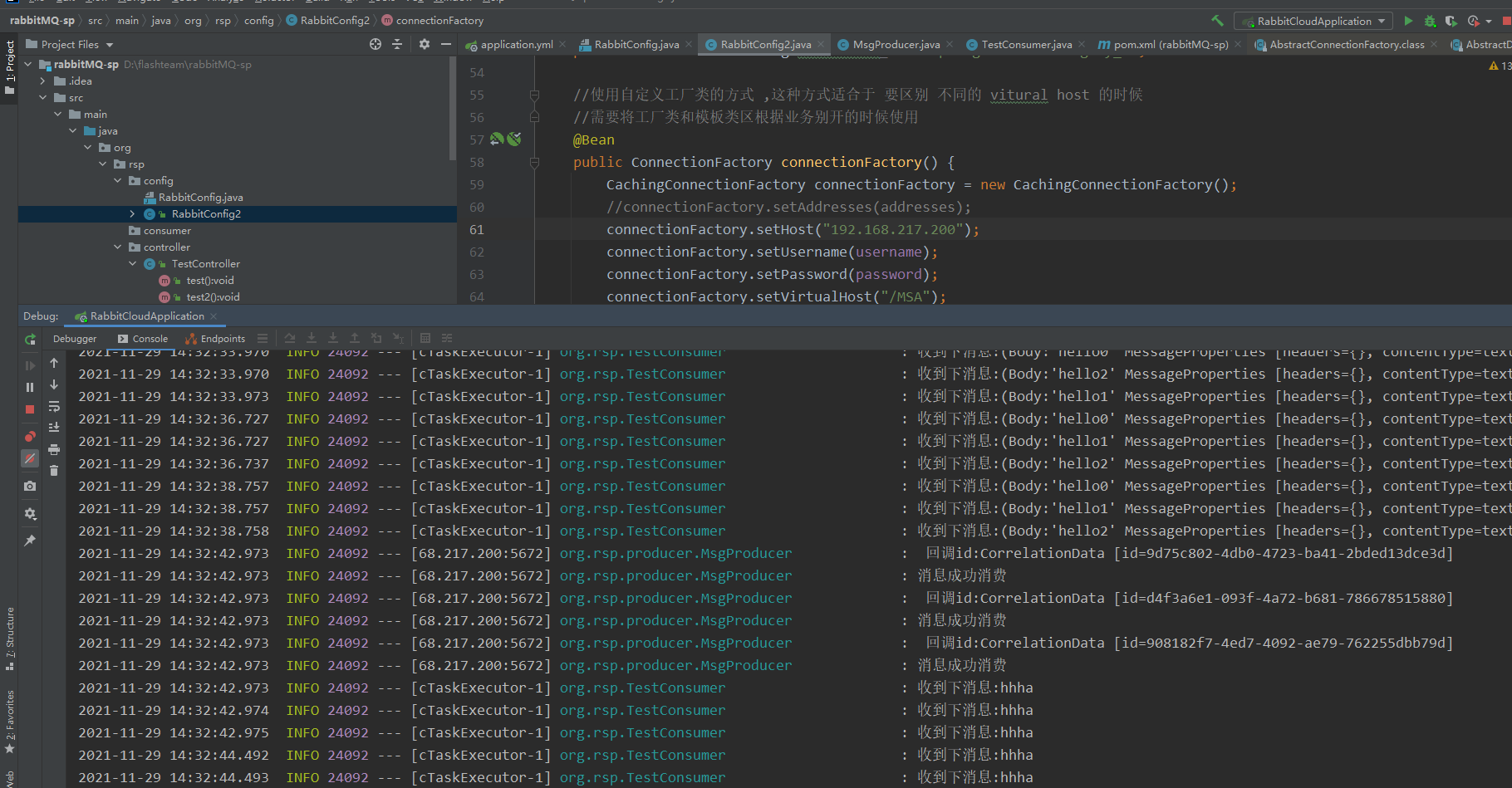
可以看到 消息可以正常发送和接受
再查看 Haproxy 发现两个 haproxy 的节点上 收到了 不同的请求次数,说明负载均衡已经生效
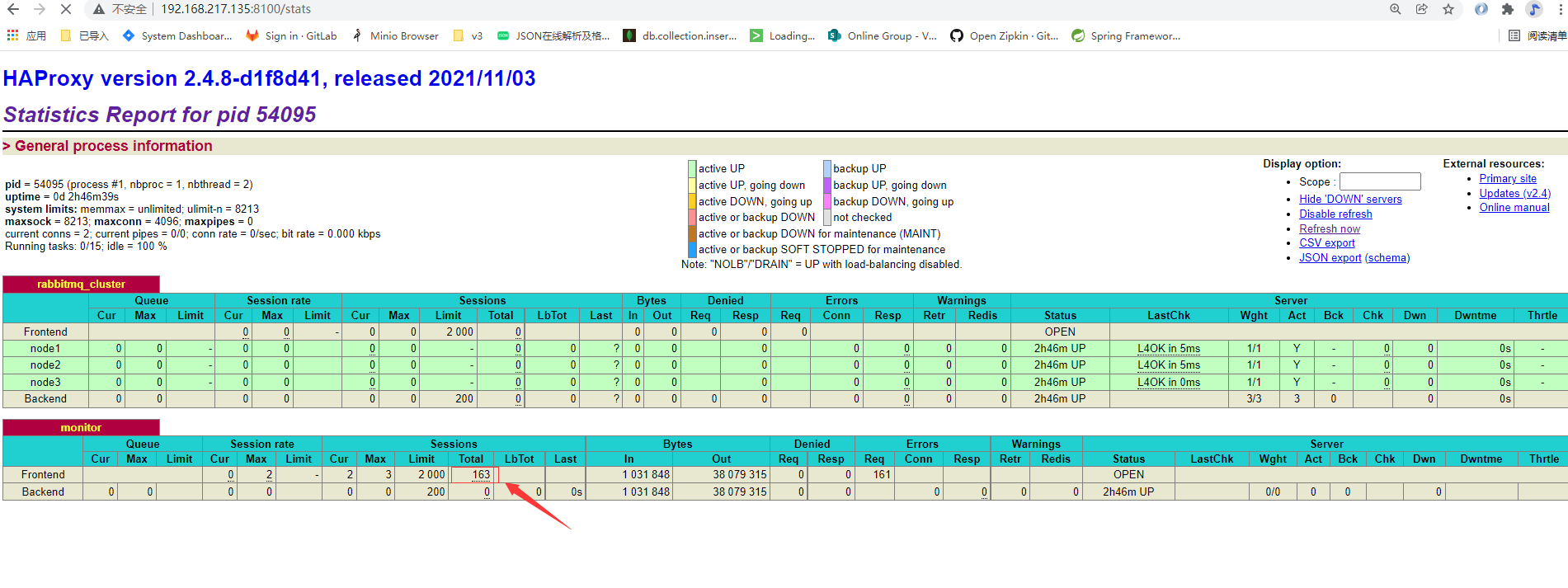
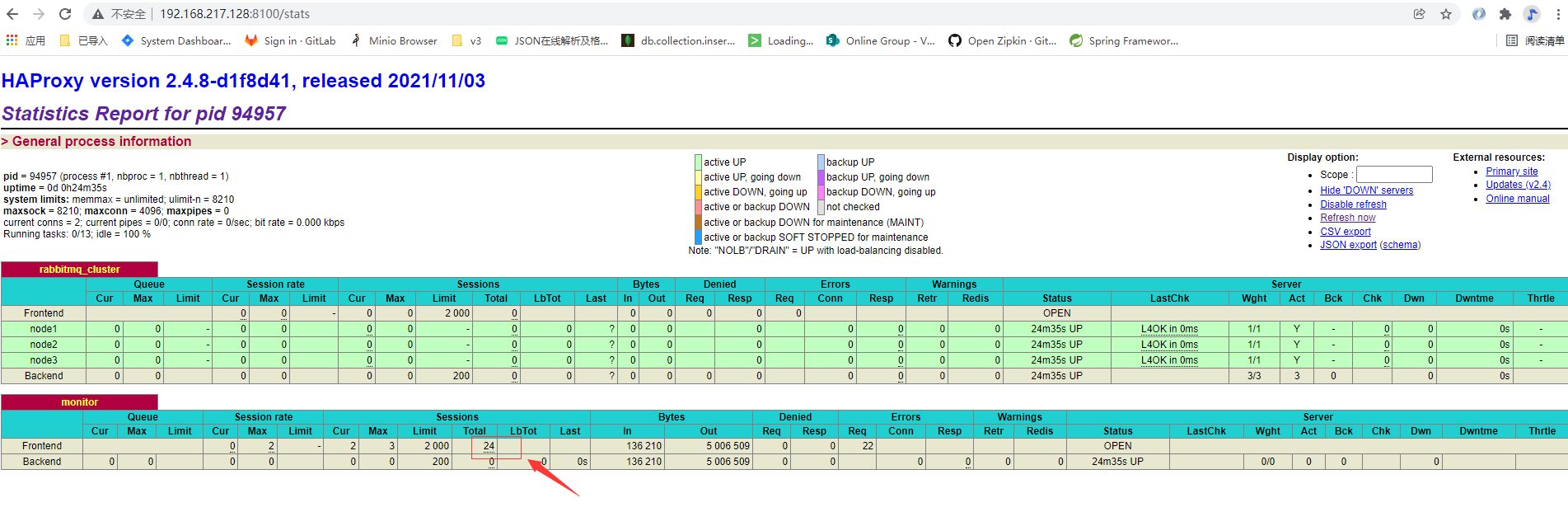
现在将 basic 的节点 keepalived 下线 验证 是否可以正常发送和接受消息
service keepalived stop
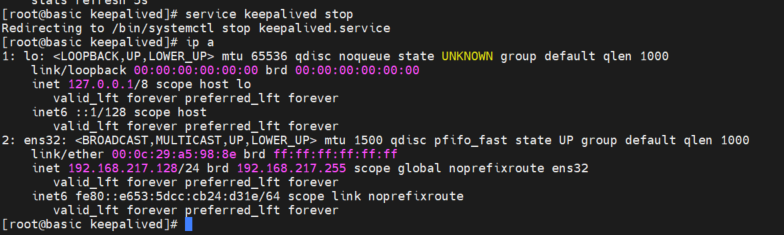
查看 basic03 状态 ,虚拟节ip 转移 了
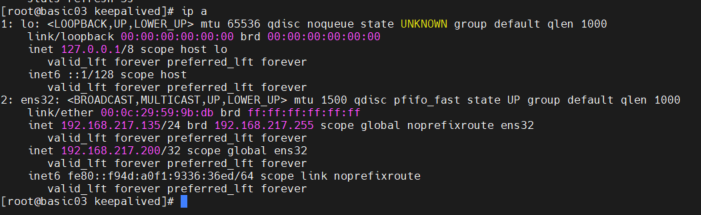
发消息 检查结果 ,发现 任然可以访问
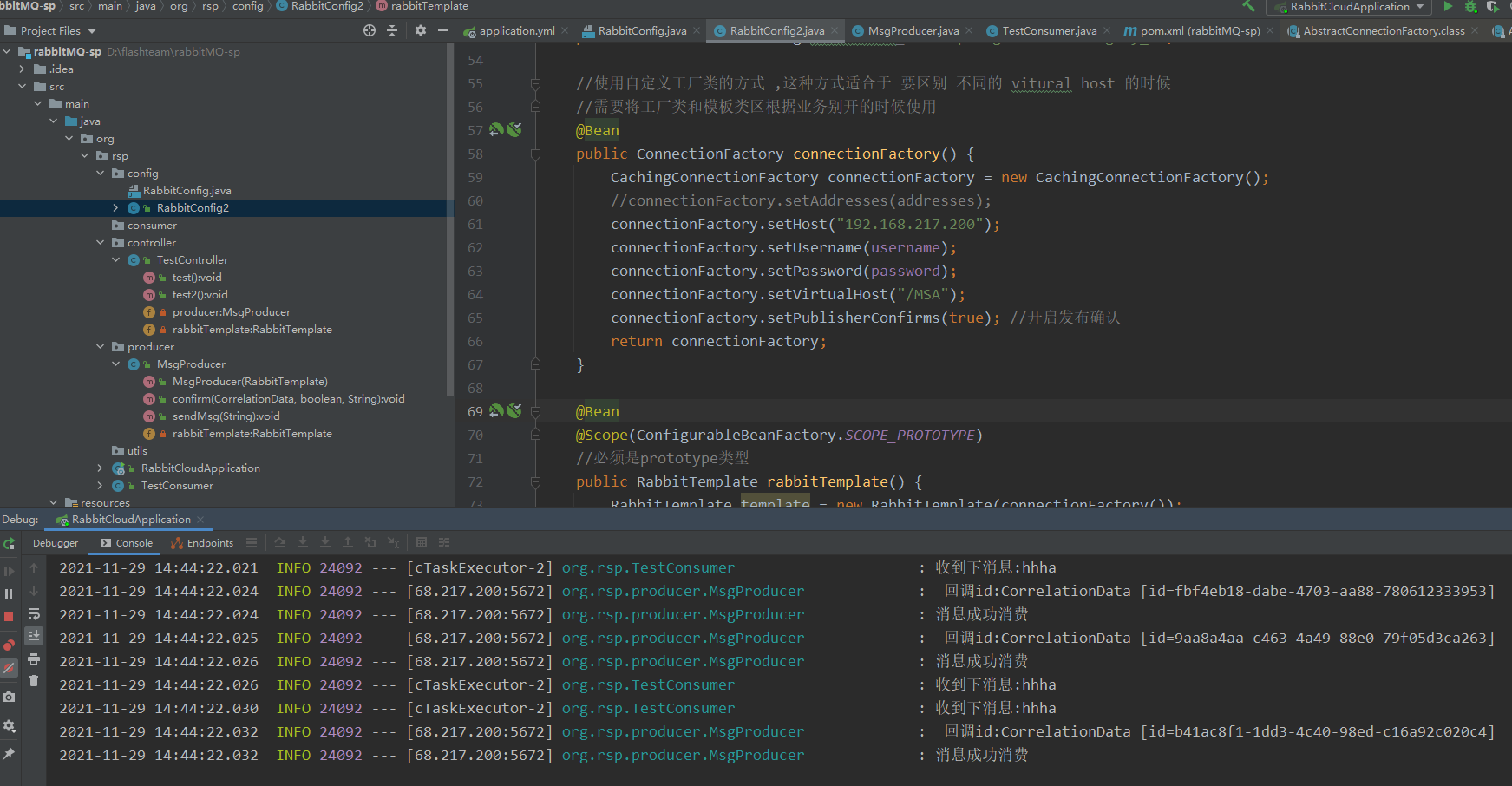
其他情况 请自行验证 ,到此 高可用集群 搭建验证完毕
最后
以上就是飘逸项链最近收集整理的关于RabbitMQ HAProxy +Keepalived 高可用集群1:环境准备 2:Rabbitmq 安装3: 集群安装的全部内容,更多相关RabbitMQ内容请搜索靠谱客的其他文章。








发表评论 取消回复