本文不详细介绍各种神经网络的细节和具体流程,主要在于归纳其特点并加以比较,希望让大家对一阶目标检测的发展过程和改进方法有个比较清晰的认知。
目录
- 一阶目标检测和二阶目标检测的区别
- 常见模型
- YOLO
- SSD
- YOLOv2 / YOLO9000
- YOLOv3
- YOLOv4
- YOLOv5
- 总结
一阶目标检测和二阶目标检测的区别
二阶目标检测的整理概要请看我之前写的文章
- 一阶目标检测输入是原始图片,输出是目标检测框和分类
- 二阶目标检测输入是原始图片,中间步骤会选出候选框,最后再对候选框做分类和回归
- 从这个区别我们可以看出,一般来说,一阶目标检测的模型处理速度会比二阶的快很多,适合工业用,但是检测精度会略微低一点
常见模型
- YOLO(You Only Look Once)系列:YOLO,YOLOv2 / YOLO9000,YOLOv3,YOLOv4,YOLOv5
- SSD(Single-Shot Multibox Detector)
YOLO
论文:You Only Look Once: Unified, Real-Time Object Detection
详细解释可以看这里
放两张图

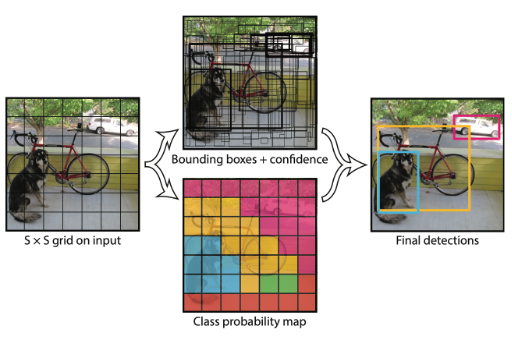
特点:
- 用单元格(grid)来代替二阶目标检测模型中的候选框(proposal)概念,直接在原图上分割成SxS个单元格,每个单元格负责检测中心在单元格内部的物体,而不是直接提取出候选框。每个单元格B个预测框,每个预测框都有参数(x, y, w, h)和置信度c,同时单元格还包含不同类别的置信度,所以每个单元格的维度是B*5+C。 C是类型数量。
- YOLO采用的是全图信息来进行预测,对背景的误判率会比Faster RCNN小很多。
缺点:
- 每个单元格都只能预测一个物体,如果存在两个物体的中心点在同一个单元格,就会出现漏判。
- 对小物体的识别率很低。
Loss Function:
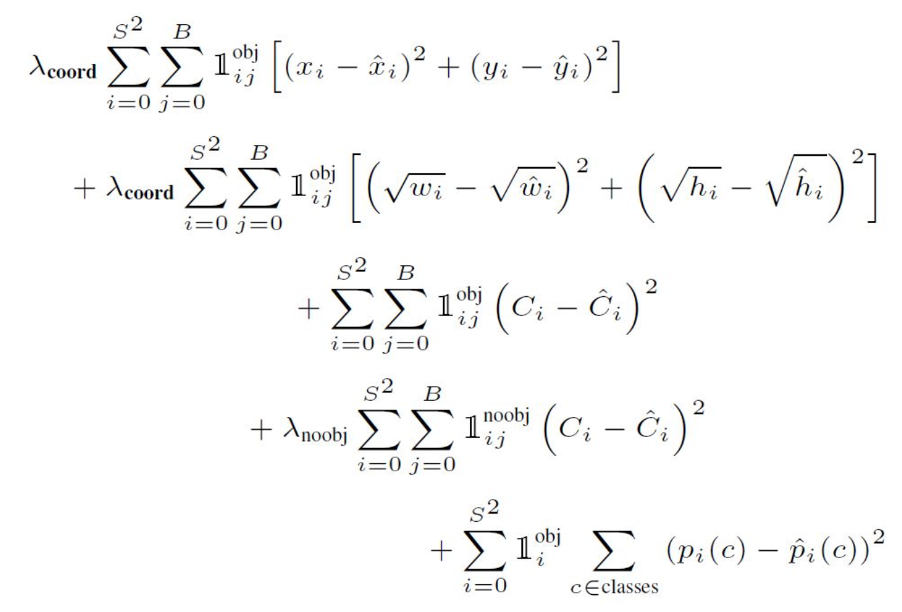
很有意思的损失函数设计
- 第一行是检测框中心偏移的loss
- 第二行是检测框长宽误差的loss
- 第三行是检测框包含物体置信值的loss
- 第四行是检测框是背景的置信值的loss
- 第五行是检测框内物体分类的loss
SSD
我们先提SSD的原因是SSD(2016)在YOLO(2015)之后提出,早于YOLOv2。SSD相较于YOLO还是有一些创新点的。
论文:SSD: Single Shot MultiBox Detector
详细解释请看这里
放一张图
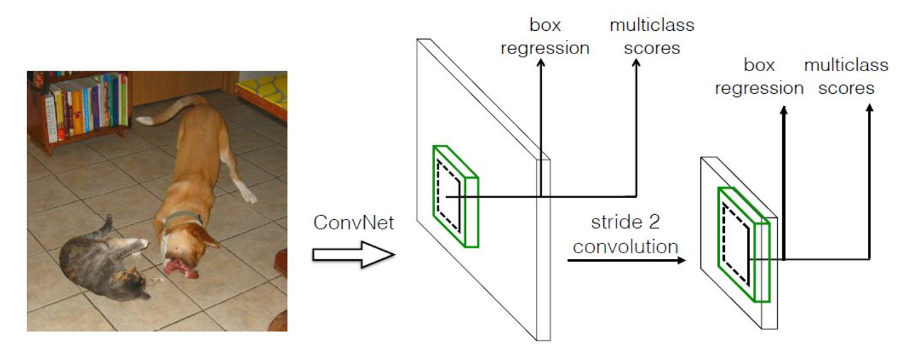
特点:
- 采用了不同尺寸的特征图进行检测,这样大尺寸的特征图对小物体的检测比较友好,稍微改进了YOLO对小物体检测的缺陷(采用方法Pyramid feature hierarchy)。
- 采用了和Faster RCNN相同的想法,提出不同比例和大小的先验框(Prior Box,相当于Faster RCNN中的Anchor)可以进一步的提升回归速率以及检测框的准确性。
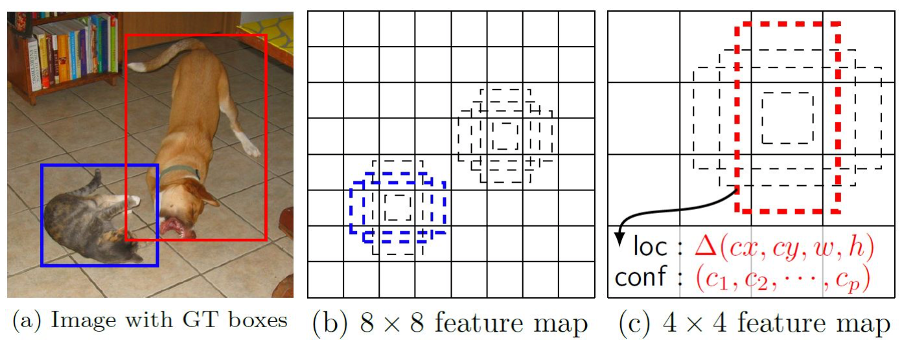
- 由于正样本相对于负样本来说数量较少,所以对负样本进行抽样,抽样时按照置信度误差(预测背景的置信度越小,误差越大)进行降序排列,选取误差的较大的top-k作为训练的负样本,以保证正负样本比例接近1:3。
缺点:
- 虽然比YOLO对小物体的检测略有提升,但是相对于Faster RCNN还是差距不小
YOLOv2 / YOLO9000
论文:YOLO9000: Better, Faster, Stronger
详细解释请看这里
放图
这回我们把特点分成两部分来看
模型特点:
- 每层卷机和激活函数直接都加了batch normalization层,提升精度和速度。
- 用Darknet代替了YOLO的VGG作为Backbone,提高运行速率,同时提高输入分辨率,提升准确度。
- 借鉴Faster RCNN的想法,也采用Anchor,提高召回率。文章通过k-means聚类得出5个不同的anchor比较合适的结论。
训练特点:
- YOLO9000采用联合训练的方式,在COCO和ImageNet上同时训练,可以预测9000种类别的物体
- 每经过十次训练,都会改变输入图像大小,能更好的预测不同尺寸的图片
YOLOv3
大佬发完YOLOv3同年便宣布推出CV界
论文:YOLOv3: An Incremental Improvement
详细解释请看这里
放图
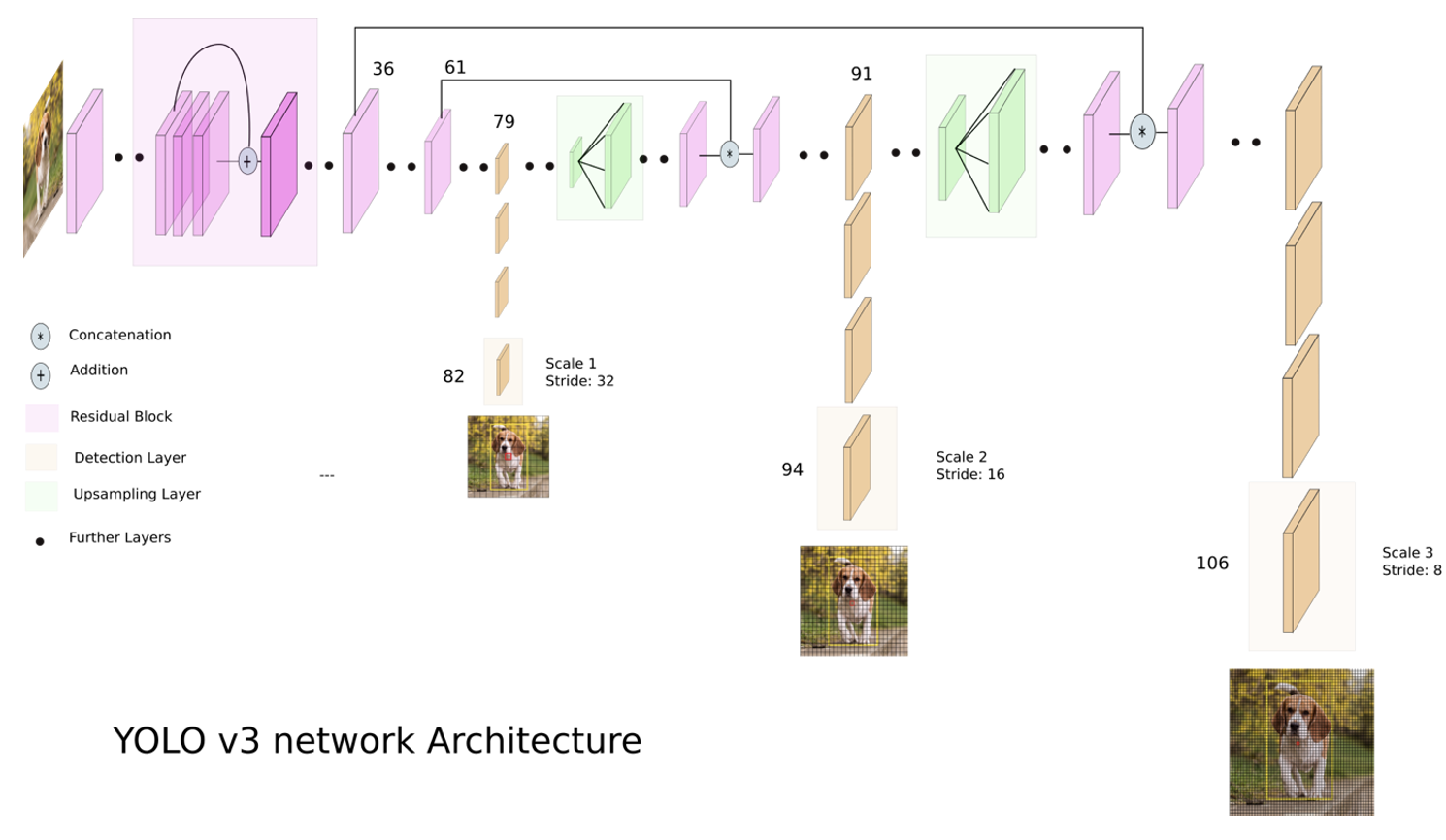
模型特点:(改进点不是非常多,但是效果不错)
- 使用了一个全卷积网络,没有池化层。用Darknet-53网络代替,速度快很多。
- 借鉴ResNet,加入residual/shortcut层,实现残差网络,提高网络深度。
- upsample层可以让网络在不同尺寸的特征图上训练检测不同大小的物体,类似于SSD的思想。
YOLOv4
论文:YOLOv4: Optimal Speed and Accuracy of Object Detection
详细解释请看这里
结构特点:
- 用CSPDarknet53代替原有backbone
- 采用PANet的FPN
- 使用Mish激活函数
- 用CmBN代替BN(效果不明显)
- 改进SAM和PAN(不清楚SAM的看这里,不清楚PAN的看这里)
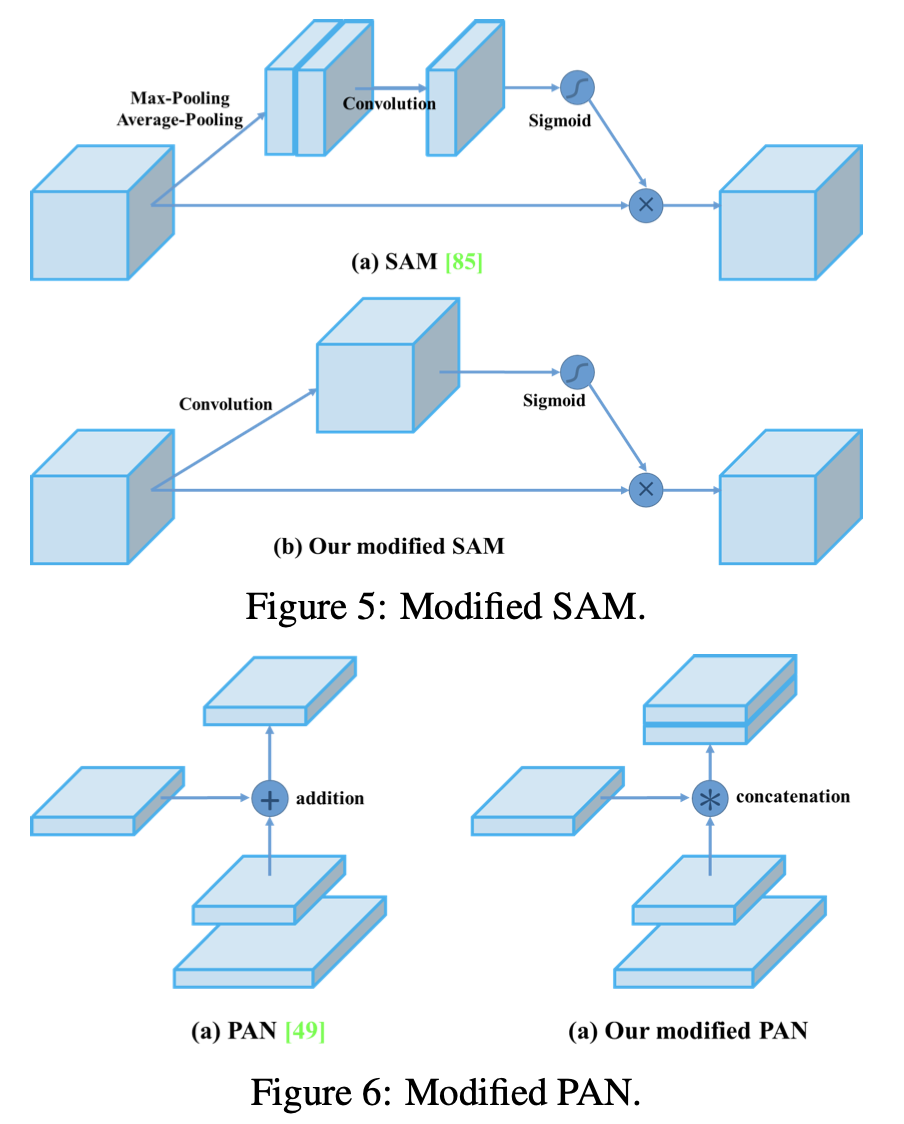
训练特点:
- 使用了Mosaic方法进行数据增强。把四张图片拼接成一张作为输入图片,可以让网络检测上下文之外的物体,增强鲁棒性(跑过代码的朋友们就知道这个神奇的Mosaic数据增强方法有多‘变态’)
- 自对抗训练(不是很懂,网上也没有详细说明)
文章并没有非常多的创新点,主要在于归纳各种已有的方法,并对他们进行比较,最后挑选合适的方法组成了YOLOv4
YOLOv5
论文(OMG竟然没有论文)
详细解释请看这里
特点:(虽然创新点不多,但是非常适用于工业用)
- 有四种不同大小的预训练模型,使用不同量级的设备使用
- 沿用了YOLOv4的部分方法,比方说Mosaic方法进行数据增强
- 自适应anchor计算。针对不同的数据集计算不同的初始anchor长宽比
- 在测试时,对原始图片添加最少的边框,提高推理速度
- Backbone用Focus结构替代
- 在Neck阶段也使用了CSP结构
- 改进损失函数GIOU_Loss和预测框筛选的DIOU_NMS
总结
一阶目标检测的发展主要在于:
- 单元格/候选框/先验框的提出和改进
- FPN的采用和改进
- 借鉴并融合各种最新方法和思想
最后
以上就是小巧未来最近收集整理的关于一阶目标检测(one-stage object detection)整理归纳一阶目标检测和二阶目标检测的区别常见模型总结的全部内容,更多相关一阶目标检测(one-stage内容请搜索靠谱客的其他文章。


![[深度学习 - 目标检测总结] one-stage 目标检测算法](https://www.shuijiaxian.com/files_image/reation/bcimg7.png)





发表评论 取消回复