通过这个链接????进行复习学习。https://github.com/scutan90/DeepLearning-500-questions
目标检测
上一节讲了two-stage目标检测算法;
主要代表就是Faster R-CNN,但它存在一些问题。
对小目标检测效果很差;(只在一个特征层进行预测,特征层较高,细节信息较少,对小目标检测效果不好。)
模型大,检测速度较慢。(网络经过两步走)
One-stage
单次目标检测算法(包括SSD系列和YOLO系列等算法)
单次目标检测算法使用神经网络作为特征提取器,后面接一个卷积层,并在之后添加自定义卷积层(根据输出的类别数和anchor),并在最后直接采用卷积进行检测。
通过图像金字塔在多个尺寸的特征图上进行检测,靠前的大尺度特征图可以捕捉到小物体的信息,而靠后的小尺度特征图能捕捉到大物体的信息,从而提高检测的准确性和定位的准确性。
(1)SSD
SSD网络结构如下图,截取至官方论文SSD
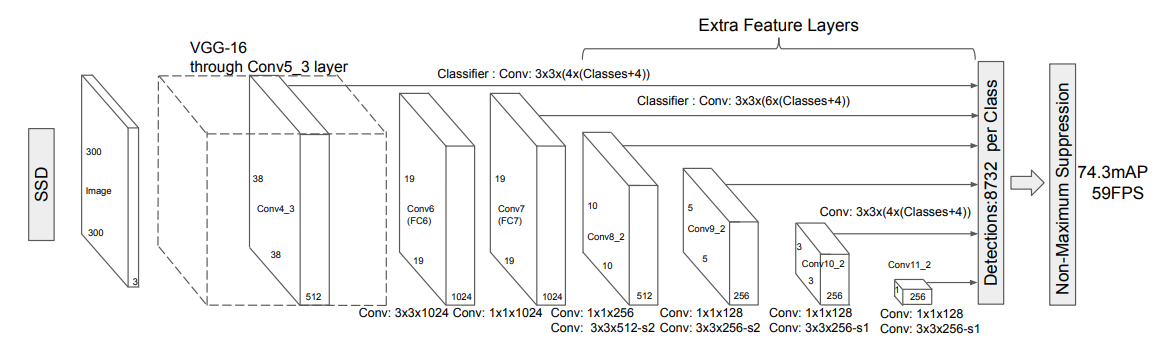
首先将图像缩放至300*300尺寸,然后放入VGG-16。这里的VGG-16模型和原VGG-16模型上不同。(在池化层的步长和核大小,以及卷积层上核和padding上的不同,主要为了输出不同大小的特征图)
从上图上看SDD,可以看到最终侦测包括了六个部分网络的输出(不同的特征图)。每个输出负责不同大小的物体检测。
特征图较大检测较小的目标,特征图较小检测较大的目标。
(抽象程度越深,细节信息越少,感受野越大。)
DSSD
- Backbone:将ResNet替换SSD中的VGG网络,增强了特征提取能力
- 添加了Deconvolution层,增加了大量上下文信息
(2)yolo
yolo特点:
- 将整张图作为网络的输入,直接在输出层回归bounding box的位置和所属的类别
- 速度快,one stage detection的开山之作
YOLO创造性的将物体检测任务直接当作回归问题(regression problem)来处理,将候选区和检测两个阶段合二为一。只需一眼就能知道每张图像中有哪些物体以及物体的位置。
yoloV1
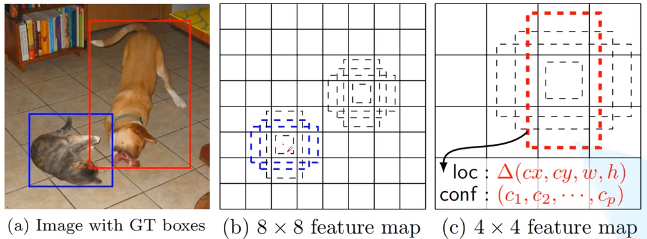
实际上yolo也是需要提取候选框,只是提取候选框的方法在网络内部自己实现。yolo将输入图片划分成7 * 7(49)个网格,每个网格要回归两个预测框,也就是说,一张图要选取49 * 2(98)个预测框,然后通过最终网络进行分类和回归。
最后采用非极大值抑制(NMS)算法从输出结果中提取最有可能的对象和其对应的边界框。
由于输出层使用全连接层进行输出,所以这就规定yolo必须要求输入图像有固定的大小,论文中作者设计的输入尺寸为448 * 448。
yoloV1的损失函数:置信度loss + 坐标loss + 类别loss。
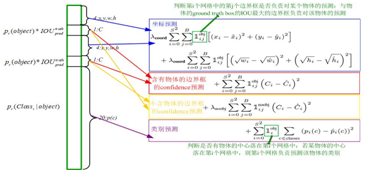
主要步骤:
第一步,先将原图划分为S * S的格子。(7*7)每个格子都有自己的置信度,通过置信度判断格子有无目标,并且进行分类。如果格子有目标,则进入第二步。
第二步,每个格子根据其中心点都可以得到两个建议框,(提前设置以中心点为原点的两个框/实质就是anchor框)即中心点固定,建议框和实际框做偏移。
存在的问题:
- 由于每个各自只有一个类别输出,但是一个各自会预测两个建议框。因此这两个建议框只能预测出一个类别,导致加入一个各自有多个目标的时候无法被检测到。
- 由于输出只有一层特征图 7 * 7,因此当存在大物体或者小物体的时候,很难检测到。
yoloV2
针对yoloV1存在的问题,yoloV2做出了几种改进策略。
- 引入预训练模型
- 主干网络换成:Darknet-19
- 引入anchor机制(类似于yoloV1每个格子有两个建议框的思想)
- 在每个卷积层后加入BatchNorm层,去掉dropout。(使训练时,模型收敛速度得到提升,防止模型过拟合。)
- YOLOv2借鉴SSD使用多尺度的特征图做检测,提出pass through层将高分辨率的特征图与低分辨率的特征图联系在一起,从而实现多尺度检测。
- YOLOv2中使用的Darknet-19网络结构中只有卷积层和池化层,所以其对输入图片的大小没有限制。
(1)预训练:
yoloV2在分类网络上先在ImageNet上做预训练,作为它的特征提取器。(预训练模型输入图片:448 * 448)
(2)YOLOv2采用了Darknet-19作为主干网络,模型的mAP值没有显著提升,但计算量减少了。
(3)anchor:首先根据数据集的真实框位置,通过聚类(Kmeans)得到五个anchor框,作为每个格子的建议框。(yoloV2每个格子有5个anchor中心,每个中心通过格子大小都可以反算得到实际位置。)
(4) 损失函数区别与yoloV1,这里每个anchor都有自己的类别标签。(输出13 * 13 * 5 * (5 + 20))
yoloV3
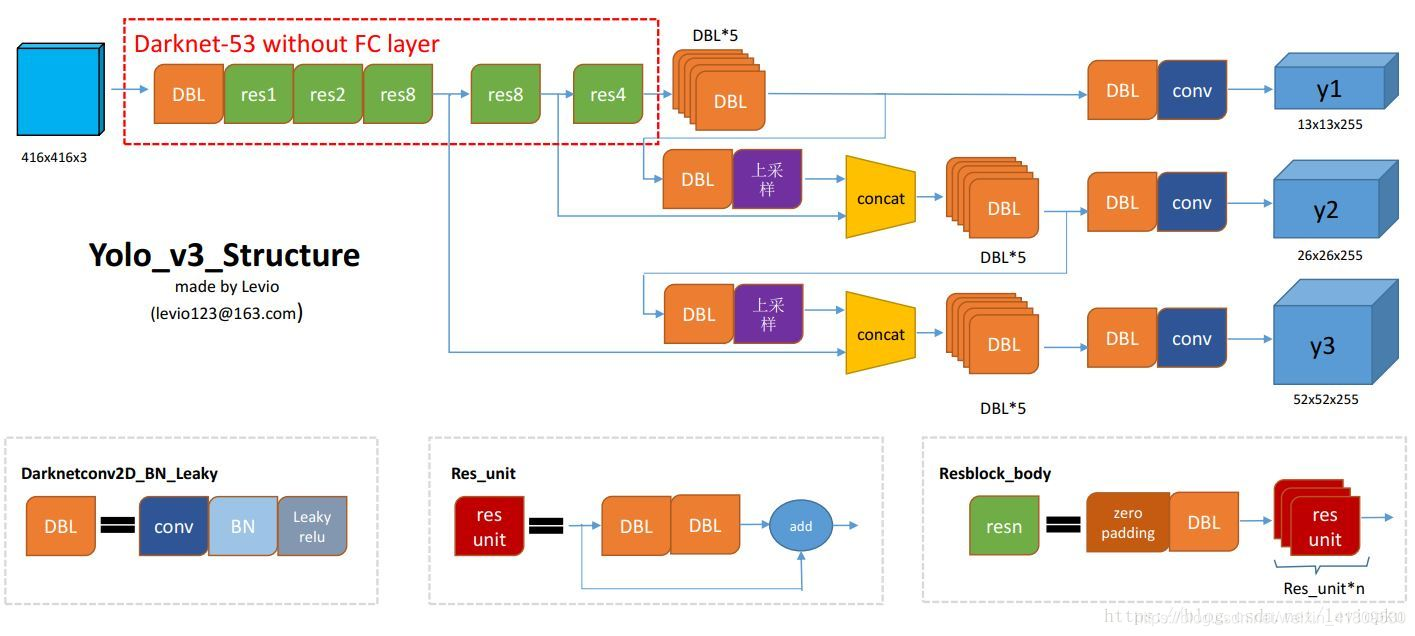
yoloV3在yoloV2的基础上增加了一些改进。提升模型性能。
- 主干网络由DarkNet-19替换成DarkNet-53。(由于增加了层数,所以加入残差模型。)
- 结合FPN模型,实现多尺度检测。
- 用逻辑回归代替softmax作为分类器。
(1)主干网络结构中,最后三次下采样得到的特征图都会作为预测。(分别是13 * 13、 26 * 26、 52 * 52 大小的特征图)每个格子都有三个anchor框,根据特征图的尺寸不同,预测的物体小大也不同。
(2)结合FPN(上图上采样和concat部分):将不同尺寸的特征图,通过上采样进行融合,融合最后三层下采样的特征图。增加检测小目标的特征图(较大的特征图)的细腻度,从而提高对于小目标检测的效果。
(3)anchor:由yoloV2的5个anchor box 变为9个(由K-means聚类算法根据数据集生成。)每个尺寸特征图分配3个anchor box。
yoloV4
(1)结构改进:(CSPDarkNet53+SPP+PANet+YoloV3-head)
- 主干网络:CSPDarkNet53(选择具有更大感受野、更大参数的模型。)
- SPP层:使用空间池化金字塔,对特征图分别进行三次池化,最后通过concat进行拼接。(增大感受野)
- PANet代替FPN,进行参数聚合以适用于不同level的目标检测。(YoloV3使从下层通过上采样到上层做拼接输出,yoloV4是从上层到下,通过concat拼接输出。)
- 对图像特征进行预测,生成边界框和并预测类别仍然和yoloV3的结构一致。
- 残差块采用两个CBM(conv+bn+mish)
- 特征拼接上的改进:加法更加注重防止过拟合(增加信息传输);concat更加注重保留特征细腻度信息。(PANet中的PAN结构是用加号拼接,yoloV4改成concat)
- 激活函数采用mish函数。(CBM结构)
(2)损失改进:
主要对iou损失进行改进;
- 普通IOU损失:不会判断框的方向性和距离。
- GIOU损失:根据不同方向框重叠后的最小外接矩形大小不同,给iou提供方向性。(缺点:当预测框在真实框内部,没有方向感。)
- DIOU损失:引入对角线来判断方向。(当预测框在真实框内部,无法作比较。)
- CIOU损失:引入对角线的角度来判断方向性。(YoloV4采用CIOU损失)
(3)训练改进:
数据增强
- RandomErase:随机遮挡;
- cutout:随机去除;
- hide-and-seek:随机隐藏;
- GridMask:等份格子进行间隔遮挡;
- 正则化遮挡:dropout,随机去除像素点(神经网络能力大,随机去除像素,影响不大。);dropblock,随机去除像素块;
- Mosaic:将正样本裁剪出来拼接在一起;
策略
- 引入学习率调度。
最后
以上就是专注火车最近收集整理的关于[深度学习 - 目标检测总结] one-stage 目标检测算法的全部内容,更多相关[深度学习内容请搜索靠谱客的其他文章。




![[深度学习 - 目标检测总结] one-stage 目标检测算法](https://www.shuijiaxian.com/files_image/reation/bcimg7.png)



发表评论 取消回复