感想
1 介绍
为了进行加速,研究者提出了基于单个神经网络的方法,它直接预测边界框而没有进行区域提议(region proposals)。YOLO是一个基于回归的方法,它返回许多目标的边界,然后直接赋予他们识别置信度。由于它重定义了网络的结构,在在GPU上可以实现实时的目标检测处理。可是,这个方法有着不精确定位的问题。WeiLiu等人提出了SSD(Single
Shot Multi-Box Detector)的方法,它是基于Faster R-CNN的Anchor的方法。它使用了传统的分类网络VGG,并且引入了额外的几层作为特征提取层。额外几层比例的改变是明显的,于是他可以检测多比例的目标(multi-scale objects)。可是,在检测小目标的方面,它的表现不是非常满意。
为了解决上述提到的SSD的问题,我们提出了一个改进的SSD方法,叫做I-SSD。受GoogleNet 的Inception block和深度残差网络的启发,我们重新设计了SSD的网络结构,他在定位方面更准确。据了解,当网络越深,它的抽象特征的能力就变得更强,但他也会带来一些训练的问题,例如梯度消失和过拟合。考虑到性能和速度的折衷,我们在VGG后面的额外层引入了Inception结构,增加卷积核的类型。因而,接收域的范围得到了拓展,这增加了模型对小目标的敏感性,并且不会丢失大目标。
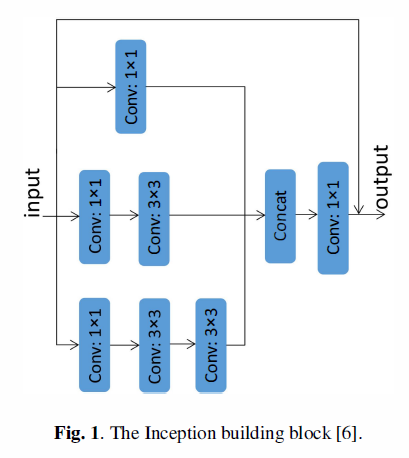
2 贡献
1. 我们在SSD的结构中引入了Inception building block来提升它的性能表现,在不增加其复杂度的情况下,它能够捕获更多的信息。
2. 我们改进了非最大抑制方法,计算边界框的权重均值来考虑作为相同的目标来产生最后的输出。
3 算法
3.1 Inception SSD
和传统的方法相比,深度神经网络有一个更复杂的模型结构,它用大量的数据去获取相对较高的性能。大体上,我们可以通过增加其深度和宽度来提升网络的性能。可是,这会导致参数的增多,参数一多,计算量就会增加,产生过拟合。
Inception的主要思想就是使用稠密组件来近似最优化局部稀疏结构(optimal local sparse structure)。Inception结构不尽能利用稠密矩阵的良好性能,也会保留网络的稀疏性,GoogLeNet Inception v1的观点是,解决两个问题(参数增加引起的)的基本方法是把全连接层或者半连接层转换成稀疏的链接(sparse links)。因此,我们相信Inception 块在不增加网络复杂度的情况下能够捕获更多的信息。
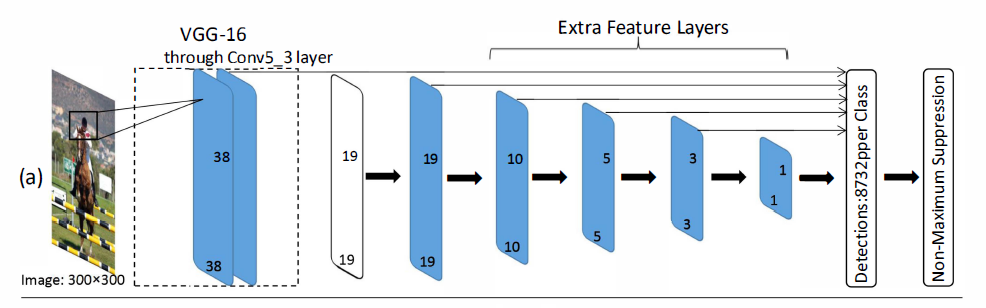
如上图,SSD使用VGG网络作为基底,增加了额外层(extra layers)去捕获目标,额外层的SSD仅仅使用一种类型的卷积核,即3*3的卷积核。通过卷积操作,额外层的特征图会产生目标的位置偏移和置信度。在目标检测中,大的卷积核倾向于捕获大的目标,小的接收域可以定位小目标。因此,顶部的特征图可能丢失目标的细节。因此,我们修改SSD少数几层,把这几层替换为Inception块。
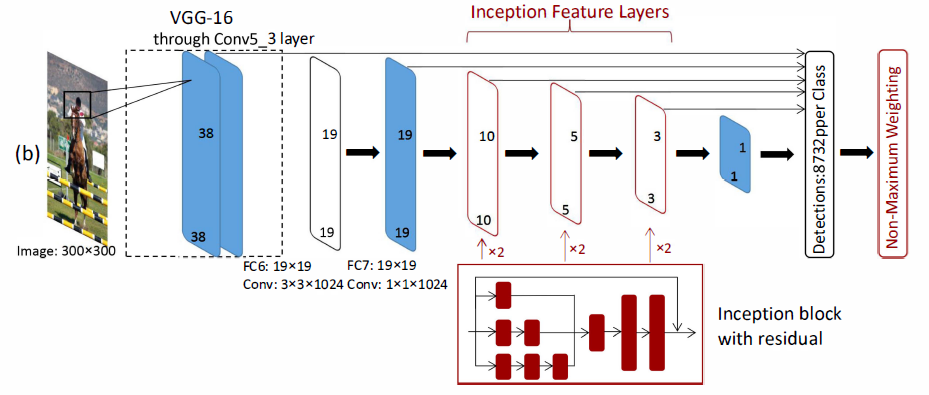
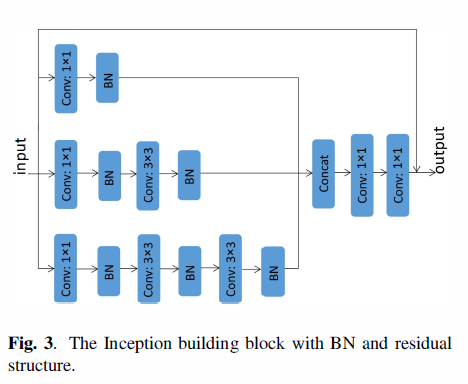
这里,不同大小的卷积核是堆叠的,它们有不同的接受域。特别地,我们堆叠1*1卷积层,3*3的卷积层,5*5的卷积层,代替原来的3*3的卷积层。5*5的卷积层用了一串两个3*3的卷积层代替。这样,我们可以获得更多的目标细节。我们减少了Inceptionblock上每层的特征图的数量,使得与原来的特征图的总数保持一致。为了能反应不同比例的接受域,我们对每种类型的卷积(conv1x1,conv3x3,conv5x5)的输出赋予不同的权重,权重w={1,2,1}。我们对3*3的卷积层设置w=2,为其它得卷积层赋予权重w=1,我们对Inception 块的每一个卷积层使用BN,使用两个1x1的卷积层在顶部。我们修改后的Inception块如图3.
我们用Inception块替换了conv6,conv7, conv8,每一层都用三个卷积塔(three convolutional towers)来替换,我们使用conv4_3, fc7,conv6_2res,conv7_2_res,conv8_2_res和conv9_2层作为目标检测的特征提取层。这是,随着网络变得更深,网络变得很难收敛。为了克服这个问题,我们在额外成引入了残差的结构,我们把输入和conv6_2_res层的输出拼接起来作为conv7_1的输入。
3.2 边界框选择方法
SSD方法是基于一个前馈卷积网络的,后面接一个非最大抑制(non-maximum suppression)步骤去产生最终的检测。当IoU的值高于一个阈值的时候,一组边界框(bounding boxes,b-boxes)就被认为是相同的目标。让B表示为b-boxes集合, Ci表示第i个b-boxes的置信度,非最大抑制可以表示为:
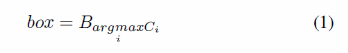
其中,box代表有着最高置信度的b-box,我们选择这些boxes作为最后的输出。可是,可能非最大检测结果包含特征的最大值,直接忽略非最大检测结果是不合适的。
设想一下,所有的b-boxes来自于同一个目标,我们通过考虑非最大的结果来最佳的利用目标信息,而不是简单的保留有最高置信度的b-boxes。因此,我们设想了一个新的b-box 选择方法,叫做Non-Maximum Weighting(NMW):
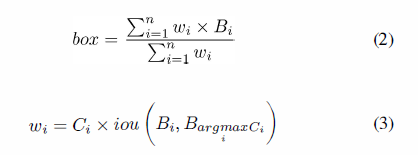
其中,n是b-boxes的重量,iou(B_i,B_(arg max┬i〖C_i 〗 ))是第i个b-box的IoU和具有最大置信度的b-box, w是每个b-box的权重。
IoU这里解释一下:在目标检测的评价体系中,有一个参数叫做 IoU ,简单来讲就是模型产生的目标窗口和原来标记窗口的交叠率。具体我们可以简单的理解为: 即检测结果(DetectionResult)与 Ground Truth 的交集比上它们的并集,即为检测的准确率 IoU :
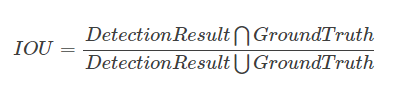
4 实验
我们在两个数据集上做了实验,包括PASCAL VOC2007和VOC2012,以及我们搜集的户外目标检测(Outdoor ObjectDetection,OOD)数据集。我们使用Caffe去创建网络,在NVIDIA Telsa K20c GPU上训练模型。至于网络的初始化,我们使用了ILSVRCCLS-LOC数据集上预训练VGG16的参数,对于Inception创建块(Inception building block)使用了“xavier”方法。在所有的实验中,我们使用SGD,初始的学习率为0.005,batch size设置的为32.我们设置的输入分辨率为300*300.
这里解释一下xavier:“Xavier”初始化方法是一种很有效的神经网络初始化方法,方法来源于2010年的一篇论文, 为了使得网络中信息更好的流动,每一层输出的方差应该尽量相等。具体初始化公式如下:
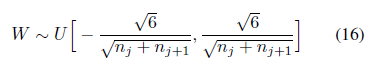
其中nj代表第j层的的大小(第j层权重W的列数),nj+1代表第j+1层的大小。
4.1. PASCAL VOC dataset
PASCAL VOC数据集包含16551张trainval 图片(PASCAL VOC2007 trainval, VOC2012trainval and test))和4952张测试图片(VOC2007test),20个类别。为了证明算法的有效性,我们使用了和SSD算法一样的训练策略,首先,模型的学习率为0.001,迭代次数为80000次,之后继续训练 20 000次,学习率为0.0001,又以学习率0.000 01迭代20 000次。

表1显示了我们实验方法的mAPs,使用的是PASCAL VOC2007数据集,Fast R-CNN使用Selective Search去产生提议,把整张图片和提议作为VGG16的输入用于识别和回归。Faster R-CNN使用一个更高效的区域提议算法,叫做RPN网络。Fast和Faster R-CNN都使用分别率为1000*600的图片为输入图片。而I-SSD和SSD使用一个单个网络,输入的大小为300*300.
这些算法的结果显示,I-SSD在18个类别的上取得了最高的分数。尤其,对于bottle, chair, COW, table, mbike, sofa和train,效果提升明显。
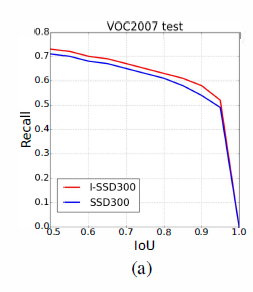
上图,我们列举了SSD的recall,当IoU是0.5的时候,I-SSD的recall是72.8%,而SSD只有71.0%。随着IoU的增加,I-SSD的recall比SSD的相对高一点。


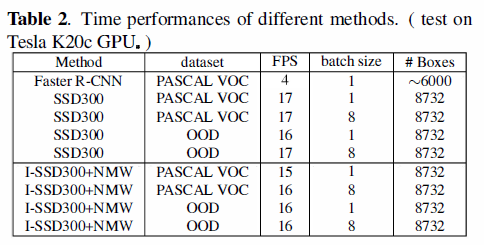
上图是I-SSD和SSD在VOC 2007测试集上的样例,不同颜色的框框代表不同的类别,置信阈值为0.6,第(a)列显示的是I-SSD的检测结果,第(b)列显示的是SSD的检测结果。I-SSD在小目标的识别上具有很强的能力,另外,我们的模型测试速度仍然很快,在Tesla k20c GPU上是16FPS, SSD是17FPS.如表2.
4.2 户外目标检测数据集
OOD数据集是为我们的无人飞行器项目(unmannedvehicles project)建造的,无人飞行器应当有能力自动避免树,汽车,石头,楼梯和导入上的人,我们从三个源上筹集图片,即真实世界照片,PASCAL VOC数据集和互联网图片。总共有12338张照片,包含5个类别(tree, people, car, stone, stair),我们选择图片的1/10作为测试集合。
在这个实验中,我们首先用的学习率迭代80 000次,随后以的学习率迭代20000次。
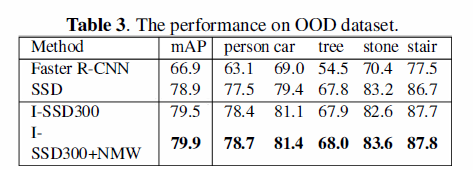
表3的结果显示,I-SSD在每一个类别上的精度都超过了SSD.

图6为OOD的数据集的一些样本。
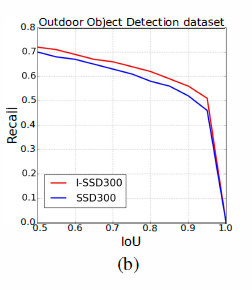
上图(b)显示了在OOD数据集上的recall,当I0U是0.5的时候,I-SSD的recall是71.8%,当IoU增加的时候,I-SSD的recall比SSD相对高一点,I-SSD的精度更高,因为它使用了更多类型的卷积核,这些卷积核包含更多的目标信息。仍然,I-SSD在这些数据集上能够达到实时,结果见上表2。
5 参考文献
[1] 检测评价函数intersection-over-union ( IOU ).
http://blog.csdn.net/eddy_zheng/article/details/52126641
[2] ChengchengNing, Huajun Zhou, Yan Song, Jinhui Tang: Inception Single Shot MultiBoxDetector for object detection. ICME Workshops 2017: 549-554
[3] XavierGlorot, Yoshua Bengio: Understanding the difficulty of training deep feedforwardneural networks. AISTATS 2010: 249-256
[4] 深度学习——Xavier初始化方法. http://blog.csdn.net/shuzfan/article/details/51338178
最后
以上就是满意手链最近收集整理的关于论文笔记:Inception Single Shot MultiBox Detector for object detection感想1 介绍2 贡献3 算法4 实验5 参考文献的全部内容,更多相关论文笔记:Inception内容请搜索靠谱客的其他文章。



![[转]SSD:Single Shot Detector详解Review: SSD — Single Shot Detector (Object Detection)What Are CoveredReferences](https://www.shuijiaxian.com/files_image/reation/bcimg19.png)

![SSD: Single Shot MultiBox Detector布置安装与测试[亲测]](https://www.shuijiaxian.com/files_image/reation/bcimg21.png)


发表评论 取消回复