前言
今天学习SSD目标检测算法,SSD,全称Single Shot MultiBox Detector,是2016年提出的算法,今天我们还是老规矩,最简单的做算法解析,力求让像我一样的小白也可以看得懂。
算法初识
1》算法能干什么?
答:可以检测图片中的目标,并且画框并予以分类,21类(其实是20类,为什么后面会说)。
2》算法有什么优点?
答:SSD是one—stage算法,比Faster RCNN比YOLO准确。但是缺点也很明显,首先很多参数需要手工设置,调试需要依赖经验,其次对小目标不敏感,特征提取不充分导致精度下降。
算法框架
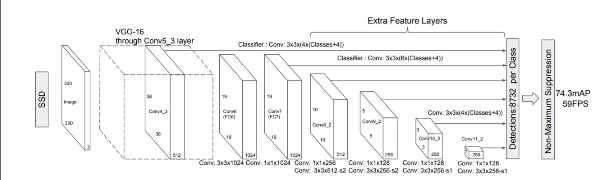
下面我么说一下SSD的基本结构和特点吧,首先SSD仍然用VGG16提取特征,其次SSD采用金字塔结构,即利用了conv4-3/conv-7/conv6-2/conv7-2/conv8_2/conv9_2这些大小不同的feature maps,在多个feature maps上同时进行softmax分类和位置回归。SSD还加入了Prior box,这个词大家可能有点陌生但是如果把他放到Faster RCNN中他就叫anchors,所以其实他就是先验框。这里我们先说一下Prior Box吧。
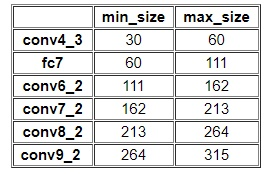
SSD按照如下规则生成prior box:以feature map上每个点的中点为中心,生成一些列同心的prior box,正方形prior box最小边长为和最大边长为:
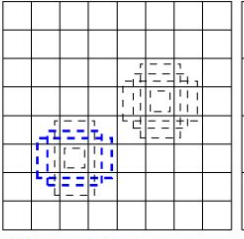
prior box形状如下:
然后我们看一下prior box的预计的输出:
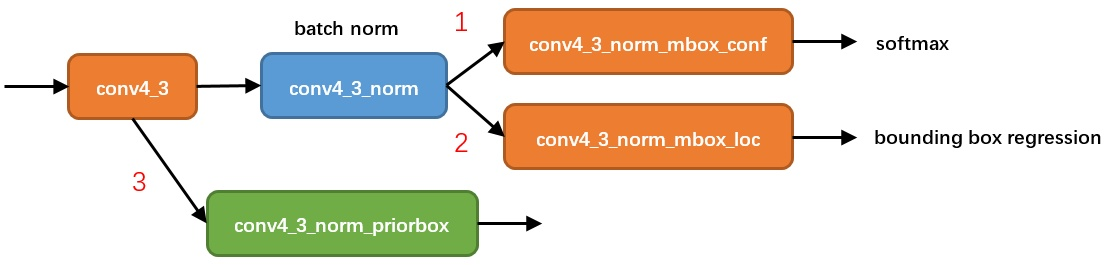
我们可以看出最终的输出有三个:
1)softmax分类目标,目标分类一共21种,其实是20种因为SSD把非目标也当做一种类别。
2)bounding box regression就是回归的目标。
3)variance这相当于对bounding box regression的补充参数,其实就是bounding box regression的权重。
这里大概的结构就差不多了,我们在看一下结构图:
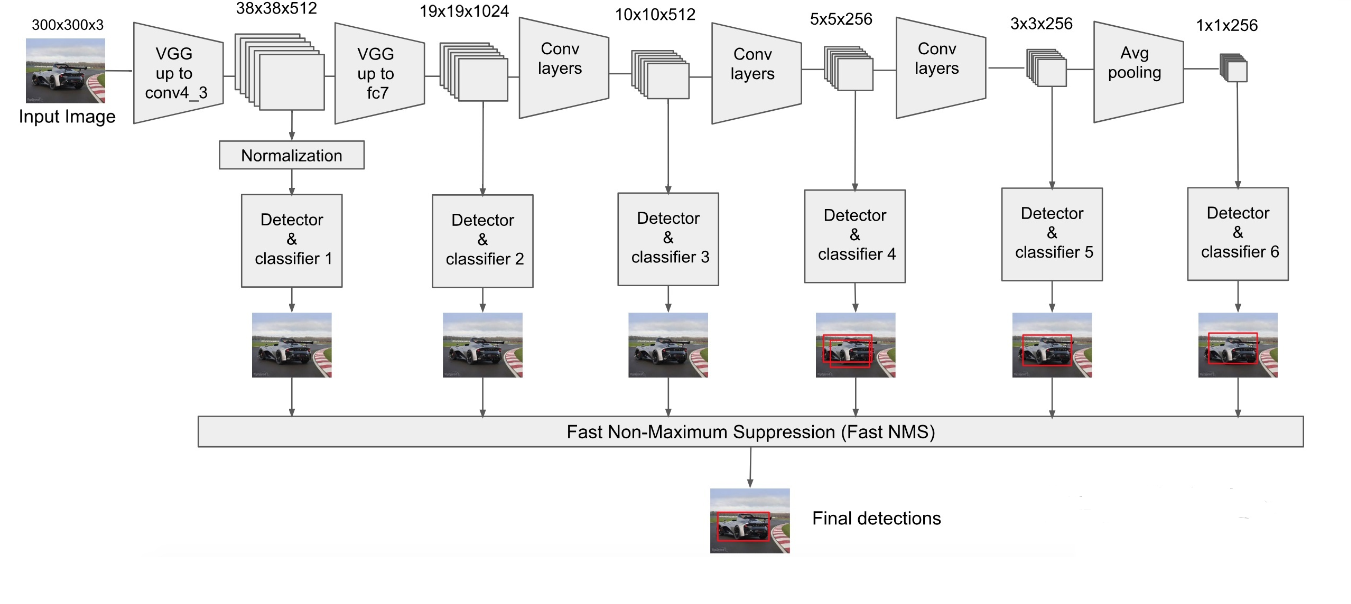
SSD的网络结构并不复杂,但是有一点需要解决,就是如何把6个尺寸的特征图合并为一个。下面我们以conv4_3和fc7为例分析SSD是如何将不同尺寸的特征图合并的。
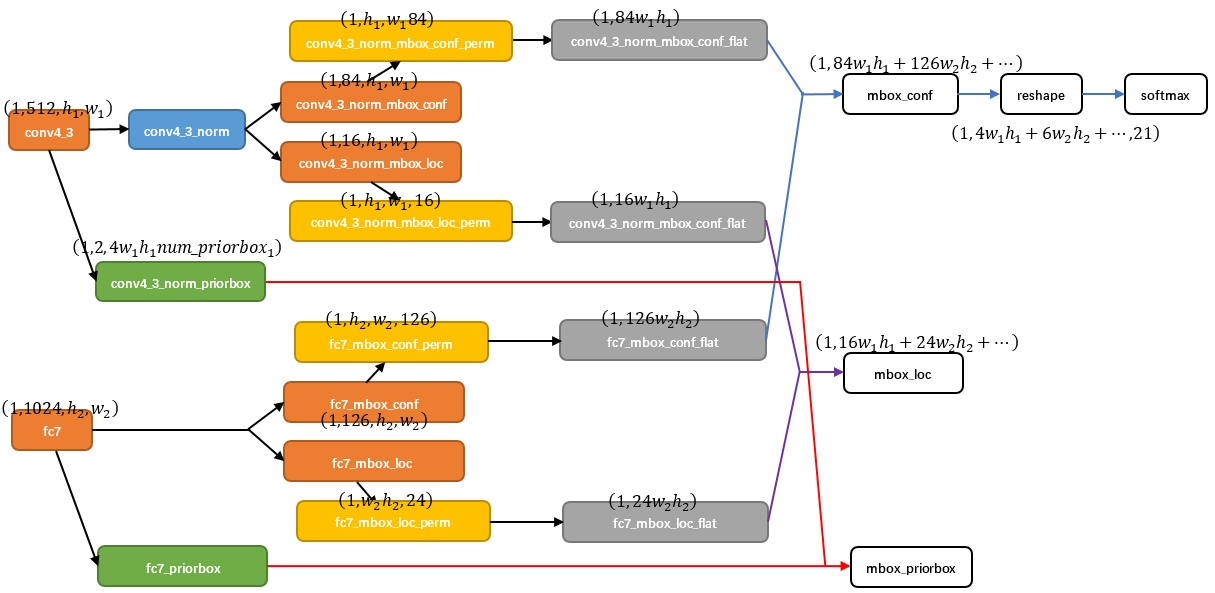
对于conv4_3 feature map,conv4_3_norm_priorbox(priorbox层)设置了每个点共有4个prior box。由于SSD 300共有21个分类,所以conv4_3_norm_mbox_conf的channel值为num_priorbox * num_class = 4 * 21 = 84;而每个prior box都要回归出4个位置变换量,所以conv4_3_norm_mbox_loc的caffe blob channel值为4 * 4 = 16。fc7每个点有6个prior box,其他feature map同理。经过一系列图7展示的caffe blob shape变化后,最后拼接成mbox_conf和mbox_loc。而mbox_conf后接reshape,再进行softmax(为何在softmax前进行reshape,Faster RCNN有提及)。最后这些值输出detection_out_layer,获得检测结果。依照这种法则,我们就可以完成多尺度检测。
最后我们这里有额外两点来说:
1)般情况下negative default boxes数量>>positive default boxes数量,直接训练会导致网络过于重视负样本,从而loss不稳定。所以需要采取:所以SSD在训练时会依据confidience score排序default box,挑选其中confidence高的box进行训练,正负比例1:3。
2)SSD同样会对数据进行处理扩充裁剪方法:旋转、放大、缩小、裁剪。
损失函数
老规矩,由于是简单解析所以我们并不细讲损失函数,略讲:
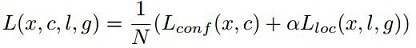
我们可以看到损失分为两种:confidence loss和location loss,confidence loss是典型的softmax loss、location loss是典型的smooth L1 loss。而参数N是prior box数量,α是权重。
最后
SSD就简单的说完了,写的不怎麽好,但是本人已经尽力了,只想能帮助一下我这样的小白。在此向各位前辈致以诚挚敬意。
最后
以上就是传统音响最近收集整理的关于SSD算法简单解析的全部内容,更多相关SSD算法简单解析内容请搜索靠谱客的其他文章。








发表评论 取消回复