文 / Google Research 学生研究员 Danijar Hafner
关于人工智能体如何选择动作来实现目标的研究,目前进展迅速,这在很大程度上得益于强化学习 (RL) 的使用。无模型 (Model-free) 强化学习方法通过试错来学习预测成功动作,让 DeepMind 的 DQN 能够玩 Atari 游戏,也让 AlphaStar 可以在星际争霸 II(Starcraft II) 游戏中击败世界冠军,不过由于这种方法需要大量的环境交互,在真实场景中的实用性也因此受到了限制。
相较之下, 基于模型的 强化学习方法能额外学习环境的简化模型。这一 世界模型 让智能体能够预测潜在动作序列的结果,能够在假设场景中的新情境中训练并做出明智决策,从而减少实现目标所必需的试错次数。过去,学习精确的世界模型并利用此类模型学习成功行为的方法一直存在挑战。虽然在近期的研究中,如我们的深度规划网络 (Deep Planning Network, PlaNet),通过从图像中学习精确世界模型的方法在该领域取得一些突破,但是基于模型的方法依然受制于规划机制,需考虑到无效或算力消耗太高等方面的,其解决复杂任务的能力也因此受阻。
今天,在与 DeepMind 的合作之下,我们推出 Dreamer,这是一种从图像中学习世界模型并使用此模型来学习长期行为的强化学习 (RL) 智能体。通过模型预测的反向传播,Dreamer 能够利用世界模型进行高效的行为学习。通过从原始图像中学习计算 压缩模型状态 (Compact Model States) ,智能体只需使用一块 GPU 即可从成千上万的预测序列中高效地并行学习。在给定原始图像输入的 20 个连续控制任务基准测试中,Dreamer 在性能、数据效率和计算时间三个方面均达到最高水准 (state-of-the-art)。为促进强化学习的进一步发展,我们正在向研究社区发布源代码。
Dreamer 的工作原理
Dreamer 包括三个非常典型的基于模型的学习方法流程:学习世界模型,从世界模型做出的预测中学习行为,以及在环境中使用学习来的行为以获取新反馈。在学习行为时,Dreamer 使用估值网络 (Value Network) 将规划范畴之外的奖励也纳入考量,同时使用行动网络 (Actor Network) 来高效地计算动作。这三个流程可并行执行,并不断重复,直至智能体实现其目标:
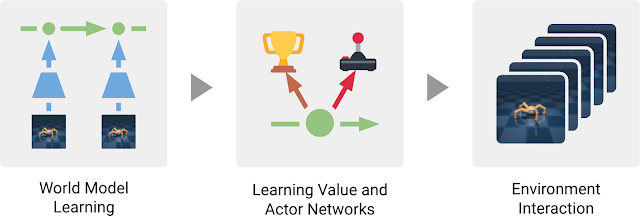
Dreamer 智能体的三个流程:智能体从过去的经验中学习得到世界模型。根据此模型的预测,智能体随后学习用于预测未来奖励的估值网络和用于选择动作的行动网络。行动网络用于与环境的交互
学习世界模型
Dreamer 使用 PlaNet 世界模型,该模型基于从输入图像计算出的一系列 压缩模型状态(Compact Model States) 来预测结果,而不是直接从一个图像来预测下一个。智能体能够自动学习生成模型状态(如物体类型、物体位置以及物体与周围环境的交互等有助于预测未来结果的概念)。根据智能体过去的经验数据集内一系列的图像、动作和奖励,Dreamer 可以学习世界模型,具体过程如下图所示:
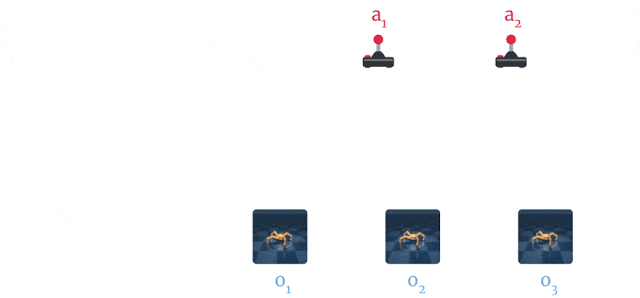
Dreamer 从经验中学习世界模型:通过使用过去的图像 (o1–o3) 和动作 (a1–a2),计算出一系列压缩模型状态(如图中绿色圆圈所示),并使用这些状态重构图像 (ô1–ô3),然后预测奖励 (r̂1–r̂3)
使用 PlaNet 世界模型的一大优势在于,通过使用压缩模型状态而非图像来预测,可显著提升计算效率。这使得模型能够在单个 GPU 上即可并行预测数千个序列。该方法还有助于实现泛化,进而实现准确的长期视频预测。为深入挖掘该模型的工作原理,我们通过将压缩模型状态解码回图像来可视化预测到的序列,如下所示,我们在 DeepMind Control Suite 与 DeepMind Lab 环境中分别执行一个任务:
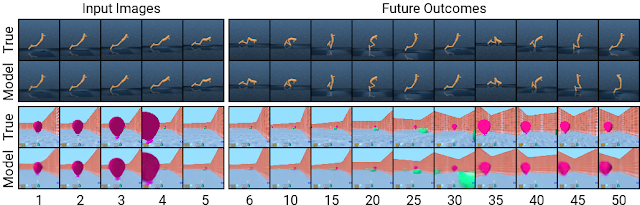
使用压缩模型状态进行提前预测可在复杂环境中实现长期预测:此处显示的两个序列为智能体以前从未遇到过的序列。在给定五个图像输入后,模型能够对其进行重构并预测出未来 50 步的图像
高效行为学习
以往开发的基于模型的智能体通常有两种选择动作的方式,一是通过多个模型预测来进行规划,二是使用世界模型代替模拟器来重用现有的无模型技术。这两种设计都需要很大的计算量,并且无法充分利用学习得到的世界模型。此外,即使是性能强大的世界模型,其精确预测未来的能力也有限,这使得以往很多基于模型的智能体都存在短视问题。Dreamer 通过对其世界模型预测的反向传播,获得估值网络与行动网络,进而克服此类限制。
Dreamer 通过预测到的状态序列对奖励梯度进行反向传播,以此高效学习行动网络来预测成功动作,而这一点在无模型的方法中是不可能实现的。这让 Dreamer 能够了解到其动作的微小变化会如何影响未来的奖励预测,使其能够朝着奖励最大化的方向优化其行动网络。为考虑超出预测范畴的奖励,估值网络会预估每个模型状态的未来奖励总和。然后,这些奖励和价值将反向传播以优化行动网络,使其选择改进后的动作:

Dreamer 从模型状态的预测序列中学习长期行为:Dreamer 会首先学习每个状态的长期值 (v̂2–v̂3),然后通过状态序列将这些值反向传播至行动网络,预测可产生高奖励和价值的动作 (â1–â2)
Dreamer 与 PlaNet 在许多方面存在不同。对于环境中的给定情境,PlaNet 在各种不同的动作序列预测中搜索最佳动作。相比之下, Dreamer 则可通过分离规划与行动以规避这一成本高昂的搜索过程。只要在预测序列上对其行动网络进行训练,Dreamer 无需额外搜索就可以计算与环境交互的动作。此外,Dreamer 使用估值函数来考虑规划范畴以外的奖励,并利用反向传播实现高效规划。
控制任务上的表现
我们已依据 20 个多样化任务组成的标准基准对 Dreamer 进行评估,任务中包含连续动作和图像输入。任务包括平衡和捕捉对象,以及各种模拟机器人的移动。这些任务设计用于对强化学习智能体提出各种挑战,包括预测碰撞的困难度、稀疏奖励、混沌动态、微小但相关的对象、高自由度和 3D 透视:

Dreamer 学习并解决了 20 个有图像输入的颇有挑战的连续控制任务(上图仅展示其中的 5 个任务)。可视化效果显示出智能体从环境中接收的相同 64x64 图像
我们将 Dreamer 与此前性能最佳的基于模型的智能体 PlaNet、目前常用的无模型智能体 A3C,以及目前在此基准上性能最佳的无模型智能体 D4PG(结合无模型强化学习的一些优势)等模型进行对比。基于模型的智能体可以实现 500 万帧以内的高效学习,对应的模拟时间为 28 小时。无模型智能体的学习速度更慢,需要 1 亿帧,对应的模拟时间为 23 天。
以 20 个任务为基准,Dreamer 的平均得分为 823 分,超过性能最佳的无模型智能体 (D4PG) 的 786分,同时学习需要的环境交互仅为 1/20。此外,在几乎所有任务上,均优于此前最佳的基于模型的智能体 (PlaNet) 的最终性能。在计算时间上,训练 Dreamer 仅需 16 个小时,而其他方法则需要 24 个小时。四个智能体的最终性能如下图所示:
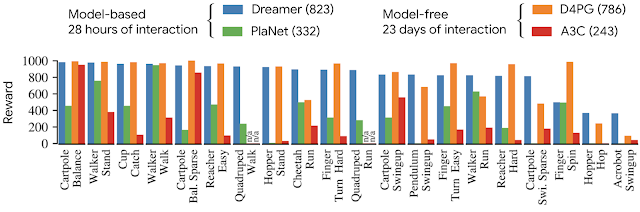
就最终性能、数据效率和计算时间而言,Dreamer 在 20 个任务基准上的表现远超之前性能最佳的无模型 (D4PG) 和基于模型的 (PlaNet) 方法
除了在连续控制任务上执行的主要实验之外,我们还将 Dreamer 应用于具有离散动作的任务,以验证其通用性。为此,我们选择 Atari 游戏和 DeepMind Lab 级别的任务,这些任务要求智能体能够兼具反应性行为和远见的行为,有空间意识,以及理解视觉效果更加多元化的场景。最终行为的可视化效果如下所示,从图中可知,Dreamer 也能高效学习以解决这些更具挑战的任务:

Dreamer 在 Atari 游戏和 DeepMind Lab 级别任务上习得成功的行为,这些任务具有离散动作和视觉差异化更大的场景,其中包括有多个目标的 3D 环境
结论
我们的研究表明,仅从世界模型预测的序列中学习行为就可以解决来自图像输入的颇具挑战的视觉控制任务,性能上也超越了此前的无模型方法。此外,Dreamer 还证明通过压缩模型状态的预测序列来反向传播价值梯度,进而学习行为的方法非常成功,且具有鲁棒性,可以解决多样化的连续和离散控制任务。我们相信,Dreamer 可为强化学习的进一步发展奠定坚实基础,包括实现更好的表征学习、不确定性预估的定向探索、时间抽象和多任务学习等。
致谢
该项目由 Timothy Lillicrap、Jimmy Ba 和 Mohammad Norouzi 合作完成。此外,我们还要感谢在整个项目期间,对我们的论文草稿发表意见并随时提供反馈的 Google Brain 团队全体成员。
如果您想详细了解 本文讨论 的相关内容,请参阅以下文档。这些文档深入探讨了这篇文章中提及的许多主题:
源代码(阅读原文)
https://github.com/google-research/dreamerDreamer
https://arxiv.org/pdf/1912.01603.pdfDQN
https://arxiv.org/pdf/1312.5602v1.pdfAlphaStar
https://deepmind.com/blog/article/alphastar-mastering-real-time-strategy-game-starcraft-ii真实场景
https://ai.googleblog.com/2019/01/soft-actor-critic-deep-reinforcement.html深度规划网络
https://ai.googleblog.com/2019/02/introducing-planet-deep-planning.htmlDeepMind
https://deepmind.com/PlaNet
https://ai.googleblog.com/2019/02/introducing-planet-deep-planning.htmlDeepMind Control Suite
https://github.com/deepmind/dm_control
DeepMind Lab
https://github.com/deepmind/labPlaNet
https://arxiv.org/pdf/1811.04551.pdfA3C
https://arxiv.org/pdf/1602.01783.pdfD4PG
https://arxiv.org/pdf/1804.08617.pdf
更多 AI 相关阅读:
用机器学习改善网络通话质量
推出 2020 年图像匹配基准和挑战赛
预测未来八小时降水情况的神经网络天气模型
提升机器学习训练数据多样性,增加医学应用可训练数据量
基于 MediaPipe 的移动端实时 3D 对象检测
发布 Open Images V6:新增局部叙事标注

最后
以上就是友好冬日最近收集整理的关于推出 Dreamer:使用世界模型的可扩展强化学习的全部内容,更多相关推出内容请搜索靠谱客的其他文章。








发表评论 取消回复