【人脸检测】FaceBoxes论文阅读与效果展示
- Introduction
- 网络结构
- 1.Rapidly Digested Convolutional Layers
- 2.Mutiple Scale Convolutional Layers
- 3.Anchor densification strategy
- 训练
- 运行结果
Introduction
文章针对2个问题:
1)在杂乱背景下、人脸视角很大变化时,需要人脸检测器精准的解决复杂人脸和非人脸的分类问题。
2)图片上较大的搜索空间和人脸尺寸的增大,增加了时间效率的需要。
传统方法效率高(?)但人脸存在大的视角变化下精度不够,基于CNN的方法精度高但速度很慢。
受到Faster R-CNN的RPN以及SSD中多尺度机制的启发,便有了这篇可以在CPU上实时跑的FaceBoxes。
网络结构
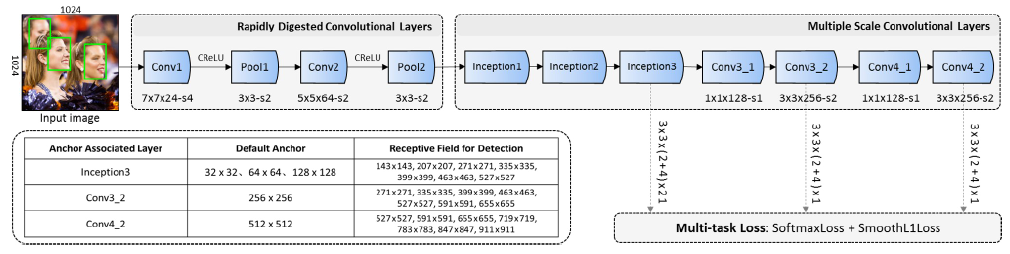
可以看到,整个网络主要分为两大块,一边是Rapidly Digested Convolutional Layers(用来加速),一边是Multiple Scale Convolutional Layers(用来检测多尺度目标),就是这两个模块实现了FaceBoxes的“快”和“准”。
1.Rapidly Digested Convolutional Layers
1、采用合适的卷积与池化尺寸:Conv1 7x7,Conv2 5x5,Pool1 3x3 Pool2 3x3
2、采用大的滑动步长来加速降维,卷积1卷积2池化1的步长分别是1024x1024只需要两次卷积一次池化就到
1024
/
(
4
∗
2
∗
2
∗
2
)
=
32
1024/(4*2*2*2)=32
1024/(4∗2∗2∗2)=32了,缩小了32倍
3、减少卷积核深度,利用C.ReLU,使计算量减少的前提下,又能保证特征图维度不会太少
下面是C.ReLU的结构:
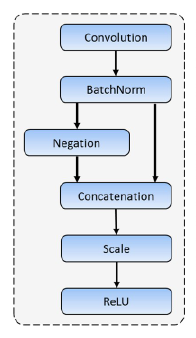
可以看到,在进行一次卷积与BN操作之后,C.ReLU把特征图的值都取反了一下,然后concat到一起再进行ReLU操作,这样的好处显而易见:减少了卷积操作但是又double了out channels,提高了训练与使用的速度
2.Mutiple Scale Convolutional Layers
1、深度维度的不同尺度下预测的网络构造:其实就是不同层的结果拿出来预测不同尺度的目标,主要是考虑了小物体在最后几层就没有响应了。对应图中的inception3,conv3_2,conv4_2
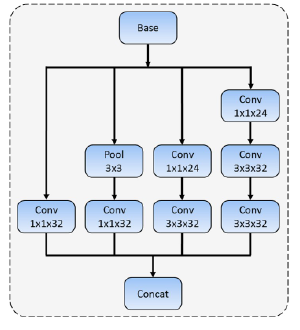
2、宽度维度的不同尺度下预测的网络构造:没看懂这里有什么创新,我感觉就是inception模块啊说是能增加感受野,下图
3.Anchor densification strategy
这里有点难以理解了,主要是作者觉得,大尺度的东西容易检测到,小尺度的东西占的anchor太少了,导致小物体检测的召回率降低。所以作者给小物体的anchor进行中心偏移“稠化”。随着层数的加深,特征图中的每个像素,在原图中代表的像素都会增加。比如inception3那层一个像素对应原图中是32x32,。也就是说越往后的层的特征越难以检测小物体,而且小物体的loss占的比重本来就是相对少,所以要针对小物体稠化候选框。作者给出的稠化策略是32x32的框变为四倍,64x64的框变为两倍,其他不变。方法如下图: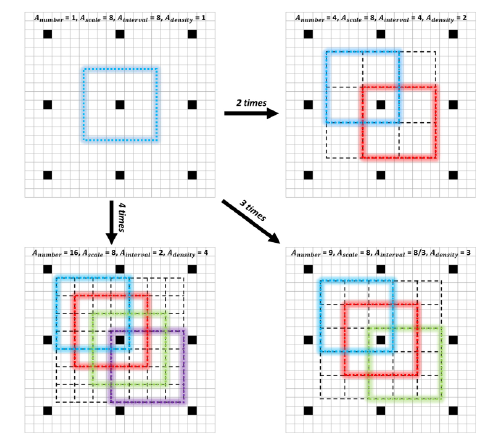
简单粗暴增加了候选框个数,而且全都是正方形的框(因为人脸框大多数情况下近似正方形)。这样的话,一个inception3后的每一个anchor里面就会有4x4(32的)+2x2(64的)+1x1(128的)=21个框。
训练
数据集:WIDER FACE
数据增广:1.色彩扭曲 2.随机裁剪 3.尺度缩放 4.随机翻转 5.人脸框过滤(小于20像素的)
代价函数:RPN还是用的Faster R-CNN的,分类用softmax,回归用smooth L1 loss
处理正负样本不均:按分数排序,保证正负比为1:3
运行结果
待更新
最后
以上就是失眠白猫最近收集整理的关于【人脸检测】FaceBoxes论文阅读与效果的全部内容,更多相关【人脸检测】FaceBoxes论文阅读与效果内容请搜索靠谱客的其他文章。








发表评论 取消回复