FaceBoxes: A CPU Real-time Face Detector with High Accuracy笔记
1. Introduction
略。
2. Related work
略。
3. FaceBoxes
本节介绍了能使 F a c e B o x e s mathrm{FaceBoxes} FaceBoxes在 C P U mathrm{CPU} CPU设备上准确而高效地运行的三点贡献:快速分解卷积层( R D C L mathrm{RDCL} RDCL),多尺度卷积层( M S C L mathrm{MSCL} MSCL)及锚框稠化策略。最后,我们介绍了相关的训练方法。
3.1. Rapidly Digested Convolutional Layers
大多数基于 C N N mathrm{CNN} CNN的人脸检测方法都会受到时间开销的限制,尤其是在 C P U mathrm{CPU} CPU设备上。更准确地说,当输入、内核和输出大小较大时, C P U mathrm{CPU} CPU卷积运算非常耗时。我们提出的 R D C L mathrm{RDCL} RDCL通过采用适当的内核大小并减少输出通道数的方式快速收缩输入空间大小,这使得 F a c e B o x e s mathrm{FaceBoxes} FaceBoxes能在 C P U mathrm{CPU} CPU设备上达到实时的速度:
收缩输入空间大小:为了快速收缩输入空间大小,我们在 R D C L mathrm{RDCL} RDCL的卷积层和池化层中采用了大步长。如下图所示, C o n v 1 mathrm{Conv1} Conv1、 P o o l 1 mathrm{Pool1} Pool1、 C o n v 2 mathrm{Conv2} Conv2和 P o o l 2 mathrm{Pool2} Pool2的步长分别为 4 4 4、 2 2 2、 2 2 2和 2 2 2。 R D C L mathrm{RDCL} RDCL的总步长为 32 32 32,这意味着输入空间可以快速地收缩 32 32 32倍。
选择适当的内核大小:在一个网络中,前几层的内核大小应该较小,这样可以降低网络推理延迟,但从减轻由空间大小减小造成的信息损失的角度来看,内核大小应该较大。如下图所示,为了保证网络的高效与有效性,我们将 C o n v 1 mathrm{Conv1} Conv1、 C o n v 2 mathrm{Conv2} Conv2及所有池化层的内核大小分别设置为 7 × 7 7times 7 7×7, 5 × 5 5times 5 5×5及 3 × 3 3times 3 3×3。
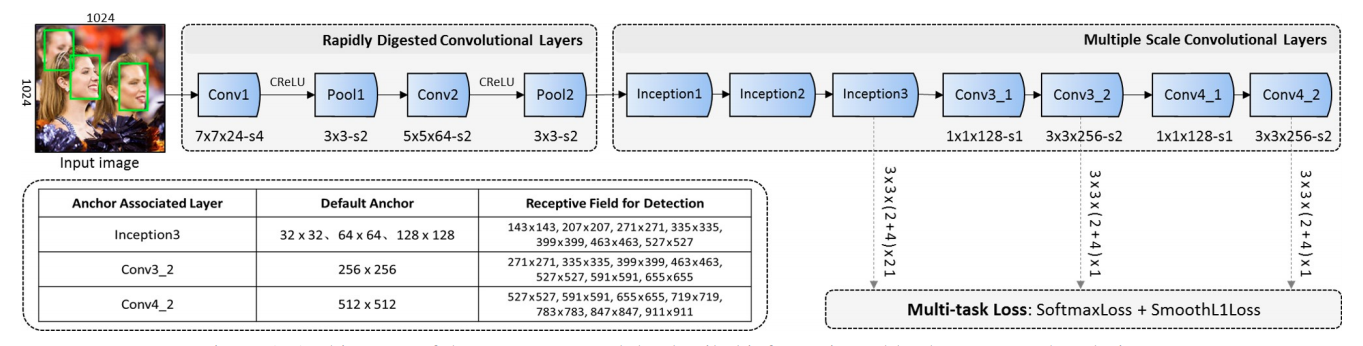
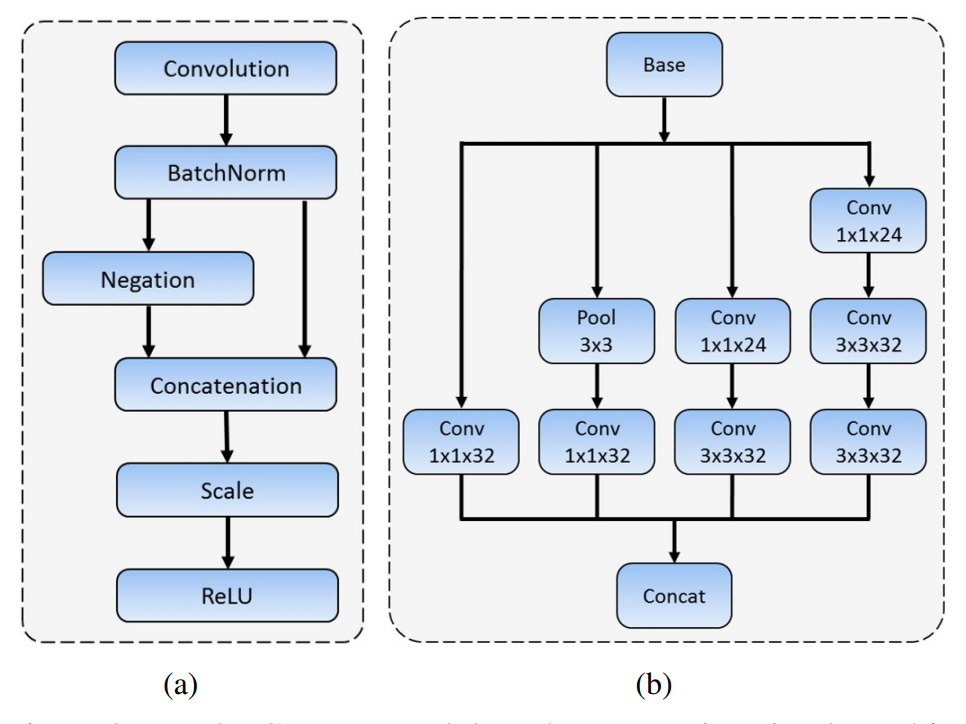
减少输出通道数:我们利用 C . R e L U mathrm{C.ReLU} C.ReLU激活函数(如下图 ( a ) (a) (a)所示)来减少输出通道数。有研究表明,在 C N N mathrm{CNN} CNN的较低层中滤波器成对(即相位相反的滤波器)出现。 C . R e L U mathrm{C.ReLU} C.ReLU函数将原始输出与取反输出相串联,并使用 R e L U mathrm{ReLU} ReLU函数对串联张量进行激活,最终输出通道数会增加一倍。 C . R e L U mathrm{C.ReLU} C.ReLU函数可以显著提高速度,同时其导致的精确度下降可以忽略不计。
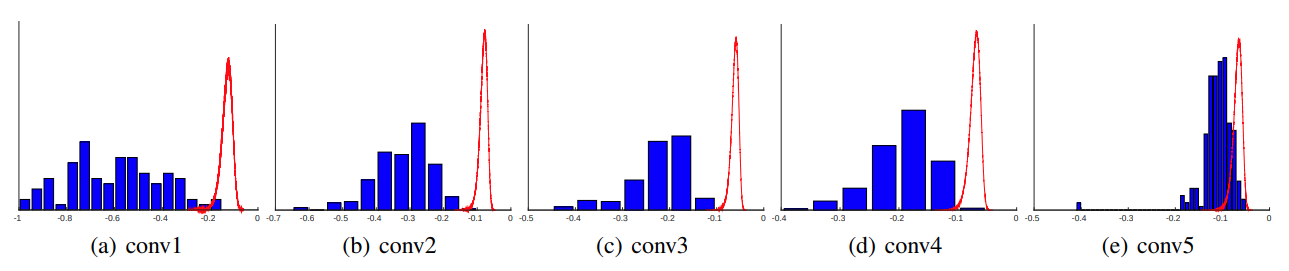
C . R e L U mathrm{C.ReLU} C.ReLU:是文献《 U n d e r s t a n d i n g Understanding Understanding a n d and and I m p r o v i n g Improving Improving C o n v o l u t i o n a l Convolutional Convolutional N e u r a l Neural Neural N e t w o r k s Networks Networks v i a via via C o n c a t e n a t e d Concatenated Concatenated R e c t i f i e d Rectified Rectified L i n e a r Linear Linear U n i t s Units Units》提出的激活函数。作者在研究 C N N mathrm{CNN} CNN模型时发现,使用 R e L U mathrm{ReLU} ReLU作为激活函数时,模型最初几层学习到的滤波器存在负相似性,这说明这些滤波器存在冗余。作者在 A l e x N e t mathrm{AlexNet} AlexNet模型上进行实验,模型前 5 5 5层卷积层的滤波器余弦相似度统计如下图所示,其中蓝色表示模型滤波器相似度直方图统计,红色表示随机滤波器相似度统计。一开始,模型滤波器相似度中心位于负轴,随着层数的加深,中心逐渐向零靠拢。作者猜想由于 R e L U mathrm{ReLU} ReLU函数会消除负值,所以模型前几层会通过学习负相似的滤波器来抵消这种影响。如果显示地利用上述先验知识,设计一种允许正负值同时通过的激活函数,那么就可以降低滤波器冗余。
3.2. Multiple Scale Convolutional Layers
本文提出的方法基于 R P N mathrm{RPN} RPN改进, R P N mathrm{RPN} RPN是一种在多类别目标检测场景中发展起来的与类别无关的候选器。对于单类别检测任务(如人脸检测), R P N mathrm{RPN} RPN则可以看作一种与类别相关的检测器。然而,作为一种独立的人脸检测算法, R P N mathrm{RPN} RPN并不具有竞争力。我们认为这主要由两个方面造成。首先, R P N mathrm{RPN} RPN锚框特征来自于最后一个卷积层,其特异性和分辨率不足以处理各种不同尺度的人脸。其次,锚框所关联的卷积层感受野单一,无法匹配不同尺度的人脸。为了解决上述两个问题,我们提出的 M S C L mathrm{MSCL} MSCL从以下两个维度进行设计:
网络深度维度的多尺度设计. 如 3.1 3.1 3.1节图 1 1 1所示,我们设计的 M S C L mathrm{MSCL} MSCL由多个层结构组成。这些层的尺寸逐渐减小,并且其中一部分层输出会组合形成多尺度特征图。与 S S D mathrm{SSD} SSD相似,我们的默认锚框与不同尺度的特征图(即 I n c e p t i o n 3 mathrm{Inception3} Inception3、 C o n v 3 _ 2 mathrm{Conv3_2} Conv3_2及 C o n v 4 _ 2 mathrm{Conv4_2} Conv4_2)相关联。这些层是一种沿着网络深度维度的多尺度设计,将锚框离散到不同分辨率的多个层上,可以处理不同大小的人脸。
网络宽度维度的多尺度设计. 为了学习不同尺度的人脸视觉模式,锚框相关层的输出应该对应不同大小的感受野,这可以通过 I n c e p t i o n mathrm{Inception} Inception模块轻松实现。 I n c e p t i o n mathrm{Inception} Inception模块由不同核的多个卷积分支组成。这些分支是一种沿着网络宽度维度的多尺度设计,能够丰富感受野。如 3.1 3.1 3.1节图 1 1 1所示, M S C L mathrm{MSCL} MSCL的前三层基于 I n c e p t i o n mathrm{Inception} Inception模块设计。我们的 I n c e p t i o n mathrm{Inception} Inception模块实现如 3.1 3.1 3.1节图 2 ( b ) 2(b) 2(b)所示,这是一种性价比很高的模块,可以捕捉不同尺度的人脸。
3.3. Anchor densification strategy
如 3.1 3.1 3.1节图 1 1 1所示,我们对于默认锚框采用 1 : 1 1:1 1:1的纵横比(即正方形锚框),这是因为人脸框接近于正方形。对于 I n c e p t i o n 3 mathrm{Inception3} Inception3层而言,其锚框尺度为 32 32 32、 64 64 64及 128 128 128像素,对于 C o n v 3 _ 2 mathrm{Conv3_2} Conv3_2及 C o n v 4 _ 2 mathrm{Conv4_2} Conv4_2层而言,其锚框分别为 256 256 256及 512 512 512像素。
在原始输入图像上,其锚框间隔等于锚框相关联层的总体步长。举个例子,
C
o
n
v
3
_
2
mathrm{Conv3_2}
Conv3_2的总体步长为
64
64
64像素,其锚框尺寸为
256
×
256
256times256
256×256,这意味着在输入图像上,每
64
64
64像素就会有一个
256
×
256
256times256
256×256的锚框。我们用下式定义锚框密度:
A
d
e
n
s
i
t
y
=
A
s
c
a
l
e
/
A
i
n
t
e
r
v
a
l
A_{density}=A_{scale}/A_{interval}
Adensity=Ascale/Ainterval
其中,
A
s
c
a
l
e
A_{scale}
Ascale表示锚框尺寸,
A
i
n
t
e
r
v
a
l
A_{interval}
Ainterval表示锚框间隔。我们的默认锚框间隔分别为
32
32
32,
32
32
32,
32
32
32,
64
64
64及
128
128
128。根据上式,其对应的锚框密度为
1
1
1,
2
2
2,
4
4
4,
4
4
4及
4
4
4,很显然,对于不同尺度的锚框存在密度不平衡的问题。与大锚框(即
128
×
128
128times128
128×128、
256
×
256
256times256
256×256及
512
×
512
512times512
512×512)相比,小锚框(即
32
×
32
32times32
32×32及
64
×
64
64times64
64×64)过于稀疏,这会导致小尺度人脸的召回率的降低。
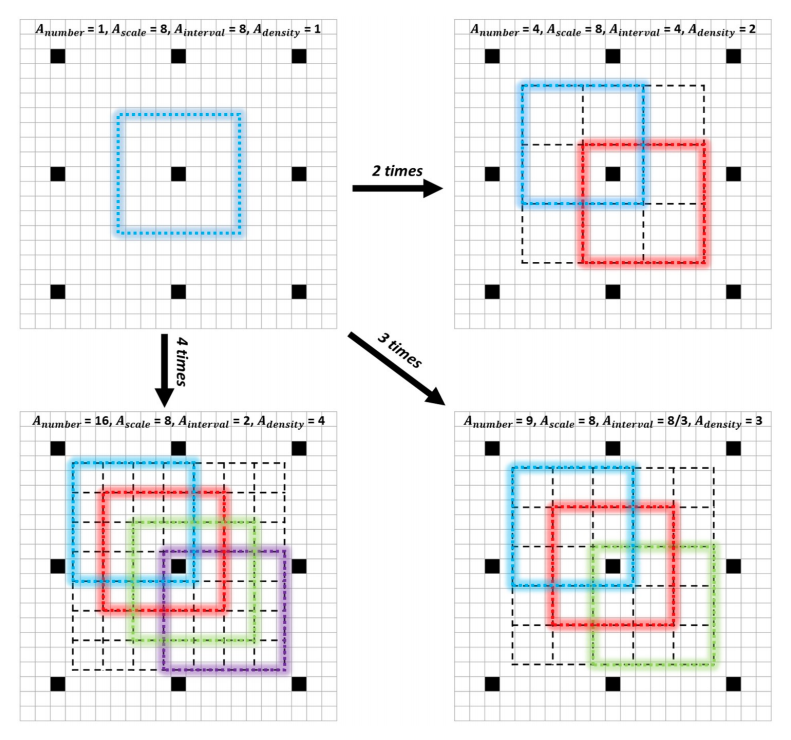
为了消除这种不平衡,我们提出了一种锚框稠化策略。具体来说,为了稠化某一种类型的锚框,我们会在感受野中心均匀的平铺 A n u m b e r = n 2 A_{number}=n^2 Anumber=n2个而非 1 1 1个锚框,如下图所示。在本文中,我们将 32 × 32 32times32 32×32的锚框稠化了 4 4 4倍, 64 × 64 64times64 64×64的锚框稠化了 2 2 2倍,这保证了不同尺度的锚框在输入图像上都具有相同的密度(即 4 4 4),因此不同尺度的人脸可以匹配几乎相同数量的锚框。
3.4. Training
本节我们将介绍训练数据集、数据增强、匹配策略、损失函数、难负例挖掘及其他实现细节。
训练数据集. 我们的模型在 W I D E R F A C E mathrm{WIDER} mathrm{FACE} WIDER FACE的 12880 12880 12880张图片的训练集上进行训练。
数据增强. 每张训练图片都通过以下数据增强策略进行顺序处理。
-
颜色变换:我们对原始图像应用了一些与文献《 S o m e Some Some i m p r o v e m e n t s improvements improvements o n on on d e e p deep deep c o n v o l u t i o n a l convolutional convolutional n e u r a l neural neural n e t w o r k network network b a s e d based based i m a g e image image c l a s s i f i c a t i o n classification classification》相似的像素变换。
-
随机裁剪:我们会从原始图像中随机裁剪五个正方形补丁:其中一个正方形补丁按最大尺寸进行裁剪,其余正方形补丁按原始图像短边尺寸的 [ 0.3 , 1 ] [0.3,1] [0.3,1]进行裁剪。之后,我们随机挑选一个补丁进行后续操作。
-
尺寸变换:随机裁剪之后,我们将挑选的正方形补丁调整至 1024 × 1024 1024times1024 1024×1024。
-
水平翻转:调整后的图像按概率 0.5 0.5 0.5进行水平翻转。
-
人脸框过滤:如果人脸框中心位于上述处理过的图像中,我们会保留其重叠部分,如果保留的人脸框宽度或高度小于 20 20 20个像素,我们会将其过滤掉。
匹配策略. 在训练期间,我们需要决定哪些锚框与人脸框相关。首先我们会将人脸框按最佳** j a c c a r d mathrm{jaccard} jaccard重叠**匹配到相应的锚框上,其次我们也会把锚框与任意人脸框jaccard重叠超过某一阈值(如 0.35 0.35 0.35)的框相匹配。
颜色变换:
j a c c a r d mathrm{jaccard} jaccard重叠:
损失函数. 我们的损失函数与 F s t e r R − C N N mathrm{Fster R-CNN} Fster R−CNN中 R P N mathrm{RPN} RPN的损失函数相同。对于分类部分我们使用 2 2 2分类 s o f t m a x mathrm{softmax} softmax损失,对于回归部分我们使用 s m o o t h L 1 mathrm{smooth L1} smooth L1损失。
难负例挖掘. 锚框匹配完成后,我们发现绝大部分锚框都为负例,这导致正负例严重不平衡。为了更快且更稳定地训练模型,我们会将锚框按损失值排序并选取最高的几个进行训练,同时我们在选取过程中也会保证正负例比率最多不超过 1 : 3 1:3 1:3。
其他实现细节. 所有的模型参数都采用了 x a v i e r mathrm{xavier} xavier方法随机初始化。模型使用 S G D mathrm{SGD} SGD方法进行优化,动量系数为 0.9 0.9 0.9,权重衰减系数为 0.0005 0.0005 0.0005,批大小为 32 32 32。模型训练最大迭代次数为 120 k 120k 120k,在前 80 k 80k 80k迭代中使用 1 0 − 3 10^{-3} 10−3大小的学习速率,在后续两个 20 k 20k 20k迭代中分别使用 1 0 − 4 10^{-4} 10−4及 1 0 − 5 10^{-5} 10−5大小的学习速率。整体训练使用 C a f f e mathrm{Caffe} Caffe库实现。
4. Experiments
在本节中,我们首先介绍了 F a c e B o x e s mathrm{FaceBoxes} FaceBoxes的运行效率,然后对模型进行了详细的分析,最后在常用的人脸检测基准上对其进行了评估。
4.1. Runtime efficiency
基于 C N N mathrm{CNN} CNN的算法一直被诟病其运行效率不高。尽管现有的 C N N mathrm{CNN} CNN人脸检测器可以通过高端 G P U s mathrm{GPUs} GPUs进行加速,但在大多数实际的应用尤其是基于 C P U mathrm{CPU} CPU的应用中,其运行速度还不够快。如下所述, F a c e B o x e s mathrm{FaceBoxes} FaceBoxes具有满足实际需求的足够效率。
在推断过程中, F a c e B o x e s mathrm{FaceBoxes} FaceBoxes会输出大量的边界框(例如,对于 V G A mathrm{VGA} VGA分辨率的图像会输出 8525 8525 8525个边界框)。首先模型会根据 0.05 0.05 0.05的置信阈值过滤掉大多数边界框并保留前 400 400 400个边界框,然后根据 0.3 0.3 0.3的 j a c c a r d mathrm{jaccard} jaccard重叠阈值应用 N M S mathrm{NMS} NMS并保留前 200 200 200个边界框。我们使用 T i t a n X ( P a s c a l ) mathrm{Titan X(Pascal)} Titan X(Pascal)显卡及 c u D N N v 5.1 mathrm{cuDNN v5.1} cuDNN v5.1加速库在 I n t e l X e o n E 5 − 2660 v 3 @ 2.60 G H z mathrm{Intel Xeon E5-2660v3@2.60GHz} Intel Xeon E5−2660v3@2.60GHz中央处理器上进行速度测量。如下表所示,与近来基于 C N N mathrm{CNN} CNN的算法相比, F a c e B o x e s mathrm{FaceBoxes} FaceBoxes可以在 C P U mathrm{CPU} CPU上以 20 F P S 20 mathrm{FPS} 20 FPS的速度运行,并且拥有最高水准的准确率。此外,模型也可以在单 G P U mathrm{GPU} GPU上以 125 F P S 125 mathrm{FPS} 125 FPS的速度运行,并且只有 4.1 M B 4.1mathrm{MB} 4.1MB大小。
| Approach | CPU-model | mAP(%) | FPS |
|---|---|---|---|
| ACF | i7-3770@3.40 | 85.2 | 20 |
| CasCNN | E5-2620@2.00 | 85.7 | 14 |
| FaceCraft | N/A | 90.8 | 10 |
| STN | i7-4770@3.50 | 91.5 | 10 |
| MTCNN | N/A@2.60 | 94.4 | 16 |
| Ours | E5-2660v3@2.60 | 96.0 | 20 |
4.2. Model analysis
我们在 F D D B mathrm{FDDB} FDDB数据集上进行消融实验分析模型。相较于 A F W mathrm{AFW} AFW与 P A S C A L mathrm{PASCAL} PASCAL人脸数据集, F D D B mathrm{FDDB} FDDB数据集更具有挑战性,因此在 F D D B mathrm{FDDB} FDDB数据集上分析模型是有说服力的。对于所有的实验,除了对组件进行指定的更改外,我们都使用了相同的设置。
消融设置. 为了更好地理解 F a c e B o x e s mathrm{FaceBoxes} FaceBoxes,我们依次剔除模型组件以实验各组件对最终性能的影响。1)首先,我们剔除了锚框稠化策略。2)然后,我们将 M S C L mathrm{MSCL} MSCL替换为三个卷积层,每层核大小为 3 × 3 3times3 3×3且其输出通道数与 M S C L mathrm{MSCL} MSCL前三个 I n c e p t i o n mathrm{Inception} Inception模块相同。同时,我们也仅将锚框与最后一层卷积层相关联。3)最后,我们将 R D C L mathrm{RDCL} RDCL中的 R e L U mathrm{ReLU} ReLU替换为 C . R e L U mathrm{C.ReLU} C.ReLU。消融实验结果如下表所示,相关实验结论也如下描述:
| Contribution | FaceBoxes | |||
|---|---|---|---|---|
| RDCL | x | |||
| MSCL | x | x | ||
| Strategy | x | x | x | |
| Accuracy(mAP) | 96.0 | 94.9 | 93.9 | 94.0 |
| Speed(ms) | 50.98 | 48.27 | 48.23 | 67.48 |
锚框稠化策略至关重要. 锚框稠化策略通过增加小锚框的密度(如 32 × 32 32times32 32×32及 64 × 64 64times64 64×64)来提高模型对小尺度人脸的召回率。从上表的结果中可以看出,剔除锚框稠化策略后,模型在 F D D B mathrm{FDDB} FDDB数据集上的 m A P mathrm{mAP} mAP由 96.0 % 96.0% 96.0%下降至 94.9 % 94.9% 94.9%。 m A P mathrm{mAP} mAP性能的骤降(即 1.1 % 1.1% 1.1%)证明了锚框稠化策略的有效性。
M S C L mathrm{MSCL} MSCL更优. 上表第二、三列的比较表明 M S C L mathrm{MSCL} MSCL可以将模型 m A P mathrm{mAP} mAP有效地提高 1.0 % 1.0% 1.0%,这归功于 M S C L mathrm{MSCL} MSCL中多种感受野及多尺度锚框的机制。
R D C L mathrm{RDCL} RDCL是一种能保持模型精度的高效组件. R D C L mathrm{RDCL} RDCL的设计使得 F a c e B o x e s mathrm{FaceBoxes} FaceBoxes能在 C P U mathrm{CPU} CPU上实现实时速度。如上表所示, R D C L mathrm{RDCL} RDCL所导致的精度下降可以忽略不计,但对于模型运行速度有显著的提高。具体来说,在 F D D B mathrm{FDDB} FDDB数据集上,模型 m A P mathrm{mAP} mAP降低了 0.1 % 0.1% 0.1%,但换取了大约 19.3 m s 19.3mathrm{ms} 19.3ms的速度提升。
4.3. Evaluation on benchmark
我们在常见的人脸检测基准数据集上评估了 F a c e B o x e s mathrm{FaceBoxes} FaceBoxes,包括 A F W mathrm{AFW} AFW, P A S C A L mathrm{PASCAL} PASCAL人脸及 F D D B mathrm{FDDB} FDDB数据集。
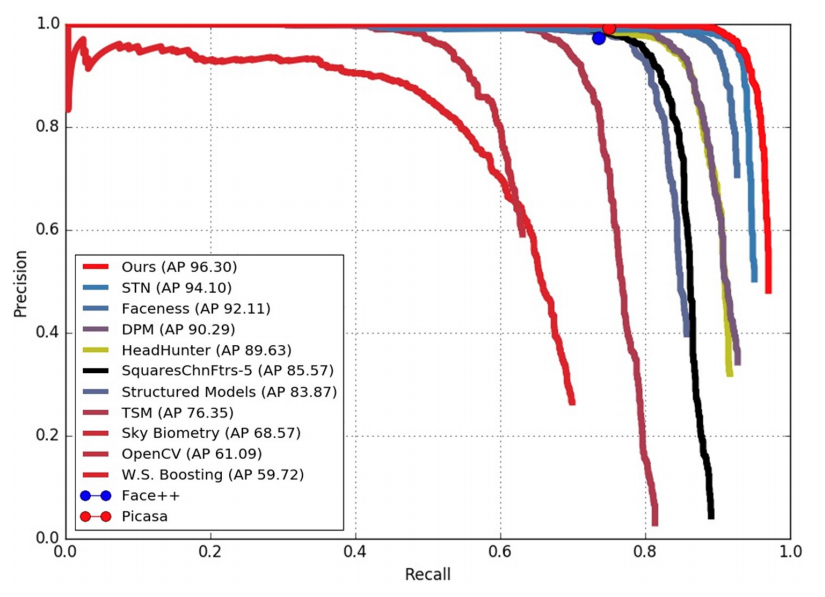
A F W mathrm{AFW} AFW数据集. 该数据集包含 205 205 205张图片, 473 473 473个人脸。我们将 F a c e B o x e s mathrm{FaceBoxes} FaceBoxes模型与其他前沿模型及商业人脸检测模型(如 F a c e . c o m mathrm{Face.com} Face.com, F a c e + + mathrm{Face++} Face++及 P i c a s a mathrm{Picasa} Picasa)进行对比评估。结果如下图所示, F a c e B o x e s mathrm{FaceBoxes} FaceBoxes模型相较于其他模型有很明显的优势。
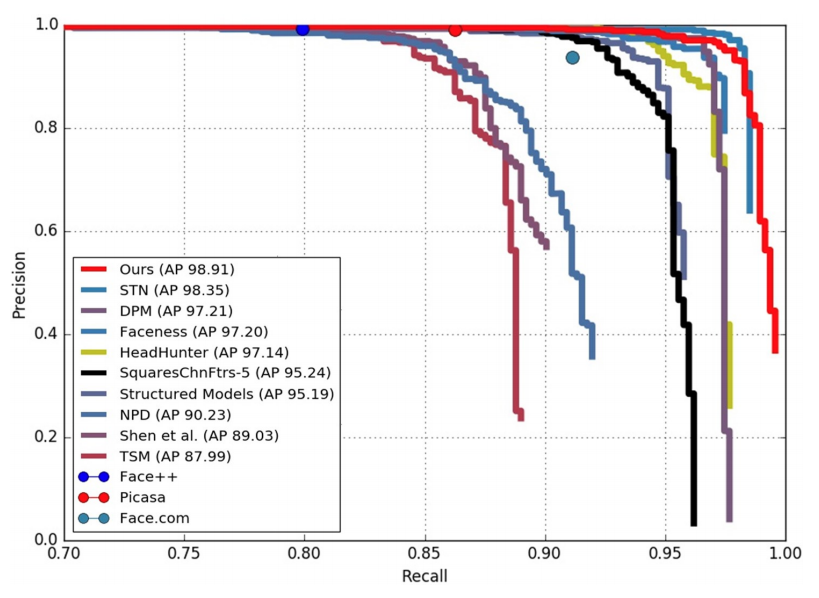
P A S C A L mathrm{PASCAL} PASCAL人脸数据集. 该数据集收集至 P A S C A L mathrm{PASCAL} PASCAL人体部位测试集,包含 851 851 851张图片, 1335 1335 1335个大尺度及不同姿态的人脸。其 P R mathrm{PR} PR曲线如下图所示。 F a c e B o x e s mathrm{FaceBoxes} FaceBoxes模型明显优于所有的其他模型及商业人脸检测模型(如 S k y B i o m e t r y mathrm{SkyBiometry} SkyBiometry, F a c e + + mathrm{Face++} Face++及 P i c a s a mathrm{Picasa} Picasa)。
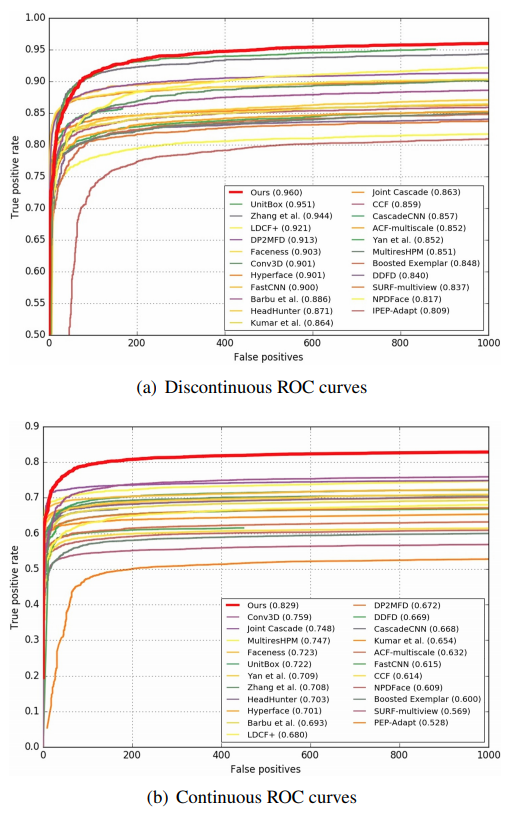
F D D B mathrm{FDDB} FDDB数据集. 该数据集包含 2845 2845 2845张来自 Y a h o o mathrm{Yahoo} Yahoo网站的新闻图片, 5171 5171 5171个人脸。 F D D B mathrm{FDDB} FDDB数据集采用椭圆边界框对人脸进行标注,而 F a c e B o x e s mathrm{FaceBoxes} FaceBoxes的输出为矩形边界框。这种不一致对于模型连续性评分有很大的影响。为了更公平的评估模型连续性评分,我们训练了一个椭圆回归器用以将模型预测的矩形边界框转换为椭圆边界框。 F a c e B o x e s mathrm{FaceBoxes} FaceBoxes与其他模型的对比评估如下图所示。 F a c e B o x e s mathrm{FaceBoxes} FaceBoxes是目前为止性能最好模型,并且其不连续与连续 R O C mathrm{ROC} ROC曲线相较于其他模型有很明显的优势。这些结果表明 F a c e B o x e s mathrm{FaceBoxes} FaceBoxes能够鲁棒地检测出无约束的人脸。
5. Conclusion
略。
最后
以上就是欣喜乌龟最近收集整理的关于《FaceBoxes: A CPU Real-time Face Detector with High Accuracy》论文笔记FaceBoxes: A CPU Real-time Face Detector with High Accuracy笔记的全部内容,更多相关《FaceBoxes:内容请搜索靠谱客的其他文章。








发表评论 取消回复