关键词
Memory, reasoning
来源
arXiv 2016.10.20
问题
在此之前,所有 multi-turn 模型都为多跳推断预先设定了固定的跳数。但是并不是所有的 document-query 对都需要同样的推理步数,有的只需要词或者句子级别的匹配,有的需要复杂的语义理解和深度推理。基于此,本文提出了动态调整跳数的模型。
文章思路
Memory Initialization
首先通过 Bi-LSTM 对 document、query 中每个词分别编码,将前向后向隐层状态拼接分别组成 document、query 词的 memory 初始值。如下:
Hypothesis Testing
query 和 document 的 memory 都要经过假设检验循环这样一个迭代过程来处理。每次循环中,query meomory 都要利用 document memory 的内容来更新来形成新的 query (也就是 hypothesis formulation)。新的 query 利用 document 事实来检验并且用来做答案预测 (也就是 hypothesis testing)
这一部分由 Neural Semantic Encoder (NSE) 控制,分为三个模块:read、compose、write。
Read 模块
这一模块把前一时刻 document 和 query 的状态作为输入,初始状态为 Bi-LSTM 的最终状态。作如下计算
Compose 模块
将当前的 document、query 和 read 模块当前隐层状态组合起来
这一模块可以看做从当前的 document、query 对抽取特征的过程;通过接受 rt,也就把 read 的当前决策告诉了 write 模块。
Write 模块
这一模块接收 read 模块,并更新 query memory
其中 1 表示全 1 矩阵。同时 write 模块也负责检验新的假设。文中提出了两种策略:query gating、adaptive computation。下图给出两种策略的图像化描述
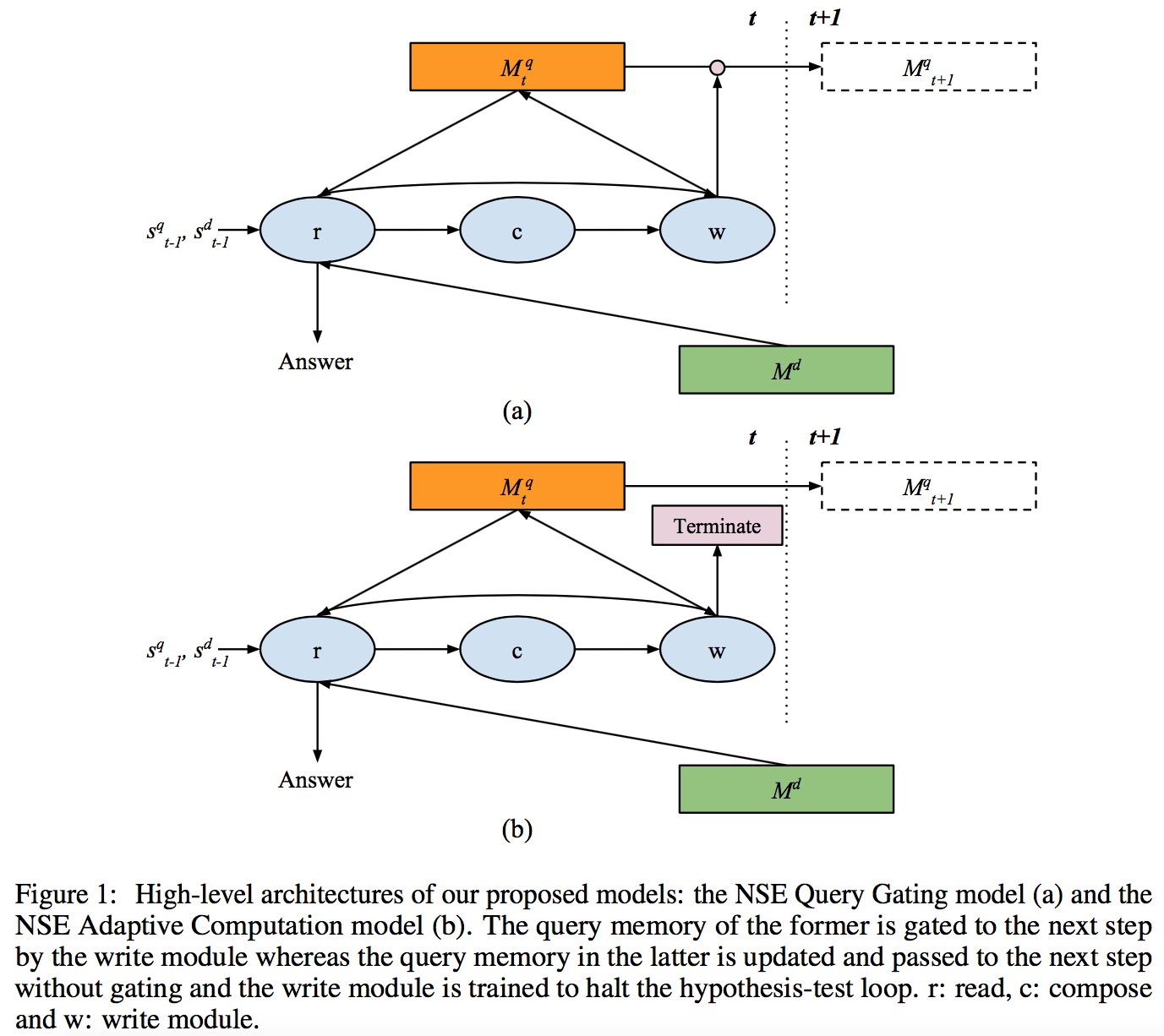
Query Gating
这种策略并不对是否终止循环做出硬性决策,而是在词的级别上做 query memory gating
在这种策略下,期望 write 模块能够在假设正确时锁住 query 状态。假设检验的步数 T 是模型中的一个超参。
Adaptive Computation
这种策略拥有终止机制,每步上,write 模块都会输出一个终止得分 et,计算方式如下
其中 o 是一个可训练的量。然后 t 步后的终止概率按如下公式计算:
这里也用 T 表示最大允许步数。如果 T 步后,模型仍然没有终止,就强迫模型输出结果。在这种情况下,终止阅读的概率如下
Answer Prediction
在 t 步,采用 query-to-document 对齐打分 ldt
来计算概率
对于 query gating 模型,使用最后一步的概率 PT(a|Q,D) 选择结果;
对于 adaptive computation 模型,使用如下公式计算正确答案
注:在实验中,read 和 write 模块都采用了单层 LSTM 网络,compose 模块采用了单层 MLP。
资源
论文地址:https://arxiv.org/abs/1610.06454
代码地址:近期会放出
相关工作
EpiReader 这一模型做两个阶段的计算。首先利用 Attention Sum Reader 选出最可能的 K 个答案填到原始问题 placeholder 中形成新的问题。然后利用 EpiReader 在 document 和新的 query 之间做一个 entailment estimation 来预测答案。但是 entailment estimation 为它的应用带来了限制。
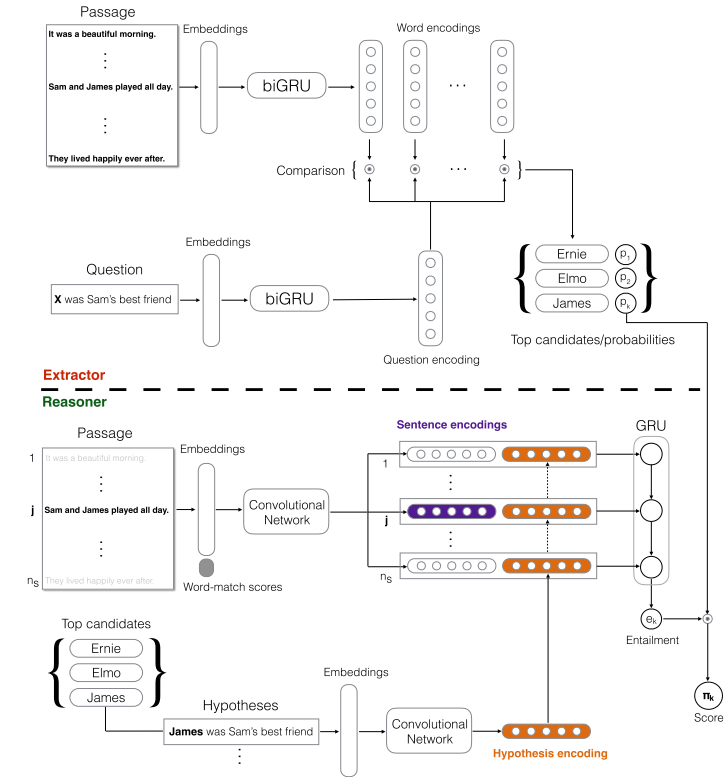
简评
最终实验证明在 T = 12 时,adaptive computation 方法在 CBT 和 WDW 两个数据集上都取得了最佳效果。本文受人脑中的假设检验过程启发,从而提出这样一个模型,解决了推理网络的跳数自适应问题。
最后
以上就是开心金毛最近收集整理的关于论文分享 - Reasoning with Memory Augmented Neural Networks for Language Comprehension关键词来源问题文章思路资源相关工作简评的全部内容,更多相关论文分享内容请搜索靠谱客的其他文章。

![[论文阅读系列---Few Shot 6]Memory-Augmented Neural Networks](https://www.shuijiaxian.com/files_image/reation/bcimg23.png)






发表评论 取消回复