目的:将Caltech行人数据集转换为Pascal VOC格式
- 参考来源https://www.cnblogs.com/arkenstone/p/7337077.html 但是这里面的代码有一些问题,我在其中修改了一些
- 操作步骤如下:
- 将下载好的caltech pedestrian dataset解压,数据集下载地址,并按如下格式存放:(最好是按照下图的格式存放,不然容易报错)
-
运行程序如下:
import os, glob, argparse
import cv2
from scipy.io import loadmat
from collections import defaultdict
import numpy as np
from lxml import etree, objectify
"""
将caltech数据集格式转换成VOC格式,即.seq转换成.jpg; .vbb转换成xml
"""
def vbb_anno2dict(vbb_file, cam_id, person_types=None):
"""
Parse caltech vbb annotation file to dict
Args:
vbb_file: input vbb file path
cam_id: camera id
person_types: list of person type that will be used (total 4 types: person, person-fa, person?, people).
If None, all will be used:
Return:
Annotation info dict with filename as key and anno info as value
"""
filename = os.path.splitext(os.path.basename(vbb_file))[0]
annos = defaultdict(dict)
vbb = loadmat(vbb_file)
# object info in each frame: id, pos, occlusion, lock, posv
objLists = vbb['A'][0][0][1][0]
objLbl = [str(v[0]) for v in vbb['A'][0][0][4][0]]
# person index
if not person_types:
person_types = ["person", "person-fa", "person?", "people"]
person_index_list = [x for x in range(len(objLbl)) if objLbl[x] in person_types]
for frame_id, obj in enumerate(objLists):
if len(obj) > 0:
frame_name = str(cam_id) + "_" + str(filename) + "_" + str(frame_id+1) + ".jpg"
annos[frame_name] = defaultdict(list)
annos[frame_name]["id"] = frame_name
for fid, pos, occl in zip(obj['id'][0], obj['pos'][0], obj['occl'][0]):
fid = int(fid[0][0]) - 1 # for matlab start from 1 not 0
if not fid in person_index_list: # only use bbox whose label is given person type
continue
annos[frame_name]["label"] = objLbl[fid]
pos = pos[0].tolist()
occl = int(occl[0][0])
annos[frame_name]["occlusion"].append(occl)
annos[frame_name]["bbox"].append(pos)
if not annos[frame_name]["bbox"]:
del annos[frame_name]
return annos
def seq2img(annos, seq_file, outdir, cam_id):
"""
Extract frames in seq files to given output directories
Args:
annos: annos dict returned from parsed vbb file
seq_file: seq file path
outdir: frame save dir
cam_id: camera id
Returns:
camera captured image size
"""
cap = cv2.VideoCapture(seq_file)
index = 1
# captured frame list
v_id = os.path.splitext(os.path.basename(seq_file))[0]
cap_frames_index = np.sort([int(os.path.splitext(id)[0].split("_")[2]) for id in annos.keys()])
while True:
ret, frame = cap.read()
if ret:
if not index in cap_frames_index:
index += 1
continue
if not os.path.exists(outdir):
os.makedirs(outdir)
outname = os.path.join(outdir, str(cam_id)+"_"+v_id+"_"+str(index)+".jpg")
print("Current frame: ", v_id, str(index))
cv2.imwrite(outname, frame)
height, width, _ = frame.shape
else:
break
index += 1
img_size = (width, height)
return img_size
def instance2xml_base(anno, img_size, bbox_type='xyxy'):
"""
Parse annotation data to VOC XML format
Args:
anno: annotation info returned by vbb_anno2dict function
img_size: camera captured image size
bbox_type: bbox coordinate record format: xyxy (xmin, ymin, xmax, ymax); xywh (xmin, ymin, width, height)
Returns:
Annotation xml info tree
"""
assert bbox_type in ['xyxy', 'xywh']
E = objectify.ElementMaker(annotate=False)
anno_tree = E.annotation(
E.folder('VOC2014_instance/person'),
E.filename(anno['id']),
E.source(
E.database('Caltech pedestrian'),
E.annotation('Caltech pedestrian'),
E.image('Caltech pedestrian'),
E.url('None')
),
E.size(
E.width(img_size[0]),
E.height(img_size[1]),
E.depth(3)
),
E.segmented(0),
)
for index, bbox in enumerate(anno['bbox']):
bbox = [float(x) for x in bbox]
if bbox_type == 'xyxy':
xmin, ymin, w, h = bbox
xmax = xmin+w
ymax = ymin+h
else:
xmin, ymin, xmax, ymax = bbox
xmin = int(xmin)
ymin = int(ymin)
xmax = int(xmax)
ymax = int(ymax)
if xmin < 0:
xmin = 0
if xmax > img_size[0] - 1:
xmax = img_size[0] - 1
if ymin < 0:
ymin = 0
if ymax > img_size[1] - 1:
ymax = img_size[1] - 1
if ymax <= ymin or xmax <= xmin:
continue
E = objectify.ElementMaker(annotate=False)
anno_tree.append(
E.object(
E.name(anno['label']),
E.bndbox(
E.xmin(xmin),
E.ymin(ymin),
E.xmax(xmax),
E.ymax(ymax)
),
E.difficult(0),
E.occlusion(anno["occlusion"][index])
)
)
return anno_tree
def parse_anno_file(vbb_inputdir, seq_inputdir, vbb_outputdir, seq_outputdir, person_types=None):
"""
Parse Caltech data stored in seq and vbb files to VOC xml format
Args:
vbb_inputdir: vbb file saved pth
seq_inputdir: seq file saved path
vbb_outputdir: vbb data converted xml file saved path
seq_outputdir: seq data converted frame image file saved path
person_types: list of person type that will be used (total 4 types: person, person-fa, person?, people).
If None, all will be used:
"""
# annotation sub-directories in hda annotation input directory
assert os.path.exists(vbb_inputdir)
sub_dirs = os.listdir(vbb_inputdir)
for sub_dir in sub_dirs:
print("Parsing annotations of camera: ", sub_dir)
cam_id = sub_dir
vbb_files = glob.glob(os.path.join(vbb_inputdir, sub_dir, "*.vbb"))
for vbb_file in vbb_files:
annos = vbb_anno2dict(vbb_file, cam_id, person_types=person_types)
if annos:
vbb_outdir = os.path.join(vbb_outputdir, "annotations", sub_dir, "bbox")
# extract frames from seq
seq_file = os.path.join(seq_inputdir, sub_dir, os.path.splitext(os.path.basename(vbb_file))[0]+".seq")
seq_outdir = os.path.join(seq_outputdir, sub_dir, "frame")
if not os.path.exists(vbb_outdir):
os.makedirs(vbb_outdir)
if not os.path.exists(seq_outdir):
os.makedirs(seq_outdir)
img_size = seq2img(annos, seq_file, seq_outdir, cam_id)
for filename, anno in sorted(annos.items(), key=lambda x: x[0]):
if "bbox" in anno:
anno_tree = instance2xml_base(anno, img_size)
outfile = os.path.join(vbb_outdir, os.path.splitext(filename)[0]+".xml")
print("Generating annotation xml file of picture: ", filename)
etree.ElementTree(anno_tree).write(outfile, pretty_print=True)
def visualize_bbox(xml_file, img_file):
import cv2
tree = etree.parse(xml_file)
# load image
image = cv2.imread(img_file)
# get bbox
for bbox in tree.xpath('//bndbox'):
coord = []
for corner in bbox.getchildren():
coord.append(int(float(corner.text)))
# draw rectangle
# coord = [int(x) for x in coord]
image = cv2.rectangle(image, (coord[0], coord[1]), (coord[2], coord[3]), (0, 0, 255), 2)
# visualize image
cv2.imshow("test", image)
cv2.waitKey(0)
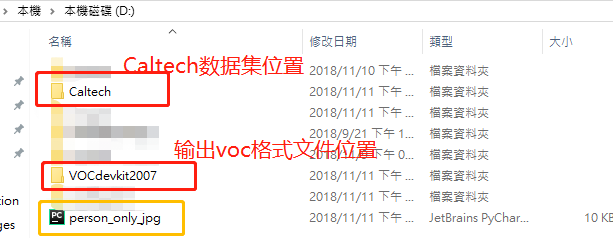
#注意!以下输入输出目录地址请参照上文示意图,确保seq文件被正确读入,不然可能会产生空文件夹或报错
def main():
# parser = argparse.ArgumentParser()
# parser.add_argument("seq_dir", default="C:\workspace\data\images", help="Caltech dataset seq data root directory")
# parser.add_argument("vbb_dir", default="C:\workspace\data\annotations", help="Caltech dataset vbb data root directory")
# parser.add_argument("output_dir",default="C:\workspace\data\VOCdevkit2007\Caltech", help="Root saving path for frame and annotation files")
# # parser.add_argument("person_type", default="person", type=str, help="Person type extracted within 4 options: "
# # "'person', 'person-fa', 'person?', 'people'. If multiple type used,"
# # "separated with comma",
# # choices=["person", "person-fa", "person?", "people"])
# parser.add_argument("person_type", default="person", type=str)
# args = parser.parse_args()
outdir = "/VOCdevkit2007"
#outdir = args.output_dir
frame_out = os.path.join(outdir, "frame")
anno_out = os.path.join(outdir, "annotation")
# person_type = args.person_type.split(",")
person_type = "person"
seq_dir = "/Caltech"
vbb_dir = "/Caltech/annotations"
parse_anno_file(vbb_dir, seq_dir, anno_out, frame_out, person_type)
print("Generating done!")
#
# def test():
# seq_inputdir = "/startdt_data/caltech_pedestrian_dataset"
# vbb_inputdir = "/startdt_data/caltech_pedestrian_dataset/annotations"
# seq_outputdir = "/startdt_data/caltech_pedestrian_dataset/test"
# vbb_outputdir = "/startdt_data/caltech_pedestrian_dataset/test"
# person_types = ["person"]
# parse_anno_file(vbb_inputdir, seq_inputdir, vbb_outputdir, seq_outputdir, person_types=person_types)
#
# # xml_file = "/startdt_data/caltech_pedestrian_dataset/annotations/set00/bbox/set00_V013_1511.xml"
# # img_file = "/startdt_data/caltech_pedestrian_dataset/set00/frame/set00_V013_1511.jpg"
# # visualize_bbox(xml_file, img_file)
if __name__ == "__main__":
main()
出现的一个错误:UnboundLocalError: local variable 'width' referenced before assignment
原因:.seq文件没有读到导致的,要检查一下输入目录https://github.com/CasiaFan/Dataset_to_VOC_converter/issues/1
有一个问题值得注意:caltech中与行人有关的类有四种:person_types = ["person", "person-fa", "person?", "people"]
如果不特别设置,直接用一些现成的代码去转换.seq文件为.jpg是把所有frame都截取出来,而一些代码中转换vbb文件为xml文件时却只把person类的标注出来,就会导致images和annotation最后的总数不一致,如:https://blog.csdn.net/qq_33297776/article/details/79869813
我参考的代码设置了.seq和.vbb均只截取person类,所以数量一致
最后
以上就是丰富草莓最近收集整理的关于将caltech数据集转换成VOC格式目的:将Caltech行人数据集转换为Pascal VOC格式的全部内容,更多相关将caltech数据集转换成VOC格式目的:将Caltech行人数据集转换为Pascal内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复