目录
snapshot(快照)基础原理
snapshot能实现什么功能?
hbase snapshot用法大全
hbase snapshot分布式架构-两阶段提交
snapshot核心实现
clone_snapshot如何实现呢?
其他需要注意的
参考文献
更多信息可参考《Hbase原理与实战》第十一章 备份与恢复
snapshot(快照)基础原理
snapshot是很多存储系统和数据库系统都支持的功能。一个snapshot是一个全部文件系统、或者某个目录在某一时刻的镜像。实现数据文件镜像最简单粗暴的方式是加锁拷贝(之所以需要加锁,是因为镜像得到的数据必须是某一时刻完全一致的数据),拷贝的这段时间不允许对原数据进行任何形式的更新删除,仅提供只读操作,拷贝完成之后再释放锁。这种方式涉及数据的实际拷贝,数据量大的情况下必然会花费大量时间,长时间的加锁拷贝必然导致客户端长时间不能更新删除,这是生产线上不能容忍的。
snapshot机制并不会拷贝数据,可以理解为它是原数据的一份指针。在HBase这种LSM类型系统结构下是比较容易理解的,我们知道HBase数据文件一旦落到磁盘之后就不再允许更新删除等原地修改操作,如果想更新删除的话可以追加写入新文件(HBase中根本没有更新接口,删除命令也是追加写入)。这种机制下实现某个表的snapshot只需要给当前表的所有文件分别新建一个引用(指针),其他新写入的数据重新创建一个新文件写入即可。如下图所示:
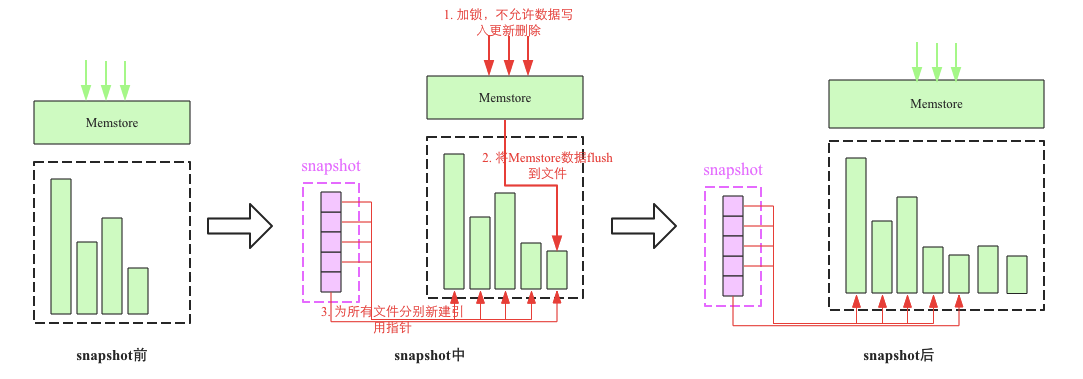
snapshot流程主要涉及3个步骤:
1. 加一把全局锁,此时不允许任何的数据写入更新以及删除
2. 将Memstore中的缓存数据flush到文件中(可选)
3. 为所有HFile文件分别新建引用指针,这些指针元数据就是snapshot
扩展思考:LSM类系统确实比较容易理解,那其他非LSM系统原地更新的存储系统如何实现snapshot呢?
snapshot能实现什么功能?
snapshot是HBase非常核心的一个功能,使用snapshot的不同用法可以实现很多功能,比如:
- 全量/增量备份:任何数据库都需要有备份的功能来实现数据的高可靠性,snapshot可以非常方便的实现表的在线备份功能,并且对在线业务请求影响非常小。使用备份数据,用户可以在异常发生的情况下快速回滚到指定快照点。增量备份会在全量备份的基础上使用binlog进行周期性的增量备份。
- 使用场景一:通常情况下,对重要的业务数据,建议至少每天执行一次snapshot来保存数据的快照记录,并且定期清理过期快照,这样如果业务发生重要错误需要回滚的话是可以回滚到之前的一个快照点的。
- 使用场景二:如果要对集群做重大的升级的话,建议升级前对重要的表执行一次snapshot,一旦升级有任何异常可以快速回滚到升级前。
2. 数据迁移:可以使用ExportSnapshot功能将快照导出到另一个集群,实现数据的迁移
- 使用场景一:机房在线迁移,通常情况是数据在A机房,因为A机房机位不够或者机架不够需要将整个集群迁移到另一个容量更大的B集群,而且在迁移过程中不能停服。基本迁移思路是先使用snapshot在B集群恢复出一个全量数据,再使用replication技术增量复制A集群的更新数据,等待两个集群数据一致之后将客户端请求重定向到B机房。具体步骤可以参考:https://www.cloudera.com/documentation/enterprise/5-5-x/topics/cdh_bdr_hbase_replication.html#topic_20_11_7
- 使用场景二:使用snapshot将表数据导出到HDFS,再使用HiveSpark等进行离线OLAP分析,比如审计报表、月度报表等
hbase snapshot用法大全
snapshot最常用的命令有snapshot、restore_snapshot、clone_snapshot以及ExportSnapshot这个工具,具体使用方法如下:
- 为表’sourceTable’打一个快照’snapshotName’,快照并不涉及数据移动,可以在线完成。
hbase> snapshot 'sourceTable', ‘snapshotName'- 恢复指定快照,恢复过程会替代原有数据,将表还原到快照点,快照点之后的所有更新将会丢失。需要注意的是原表需要先disable掉,才能执行restore_snapshot操作。
hbase> restore_snapshot ‘snapshotName'- 根据快照恢复出一个新表,恢复过程不涉及数据移动,可以在秒级完成。很好奇是怎么做的吧,且听下文分解。
hbase> clone_snapshot 'snapshotName', ‘tableName'- 使用ExportSnapshot命令可以将A集群的快照数据迁移到B集群,ExportSnapshot是HDFS层面的操作,会使用MR进行数据的并行迁移,因此需要在开启MR的机器上进行迁移。HMaster和HRegionServer并不参与这个过程,因此不会带来额外的内存开销以及GC开销。唯一的影响是DN在拷贝数据的时候需要额外的带宽以及IO负载,ExportSnapshot也针对这个问题设置了参数-bandwidth来限制带宽的使用。
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot
-snapshot MySnapshot -copy-from hdfs://srv2:8082/hbase
-copy-to hdfs://srv1:50070/hbase -mappers 16 -bandwidth 1024
hbase snapshot分布式架构-两阶段提交
hbase为指定表执行snapshot操作,实际上真正执行snapshot的是对应表的所有region。这些region因为分布在多个RegionServer上,所以需要一种机制来保证所有参与执行snapshot的region要么全部完成,要么都没有开始做,不能出现中间状态,比如某些region完成了,某些region未完成。
HBase使用两阶段提交协议(2PC)来保证snapshot的分布式原子性。2PC一般由一个协调者和多个参与者组成,整个事务提交分为两个阶段:prepare阶段和commit阶段。其中prepare阶段协调者会向所有参与者发送prepare命令,所有参与者开始获取相应资源(比如锁资源)并执行prepare操作确认可以执行成功,通常核心工作都是在prepare操作中完成的。并返回给协调者prepared应答。协调者接收到所有参与者返回的prepared应答之后(表明所有参与者都已经准备好提交),在本地持久化commit状态,进入commit阶段,协调者会向所有参与者发送commit命令,参与者接收到commit命令之后会执行commit操作并释放资源,通常commit操作都非常简单。
接下来就看看hbase是如何使用2PC协议来构建snapshot架构的,基本步骤如下:
1. prepare阶段:HMaster在zookeeper创建一个’/acquired-snapshotname’节点,并在此节点上写入snapshot相关信息(snapshot表信息)。所有regionserver监测到这个节点之后,根据/acquired-snapshotname节点携带的snapshot表信息查看当前regionserver上是否存在目标表,如果不存在,就忽略该命令。如果存在,遍历目标表中的所有region,分别针对每个region执行snapshot操作,注意此处snapshot操作的结果并没有写入最终文件夹,而是写入临时文件夹。regionserver执行完成之后会在/acquired-snapshotname节点下新建一个子节点/acquired-snapshotname/nodex,表示nodex节点完成了该regionserver上所有相关region的snapshot准备工作。
2. commit阶段:一旦所有regionserver都完成了snapshot的prepared工作,即都在/acquired-snapshotname节点下新建了对应子节点,hmaster就认为snapshot的准备工作完全完成。master会新建一个新的节点/reached-snapshotname,表示发送一个commit命令给参与的regionserver。所有regionserver监测到/reached-snapshotname节点之后,执行snapshot commit操作,commit操作非常简单,只需要将prepare阶段生成的结果从临时文件夹移动到最终文件夹即可。执行完成之后在/reached-snapshotname节点下新建子节点/reached-snapshotname/nodex,表示节点nodex完成snapshot工作。
3. abort阶段:如果在一定时间内/acquired-snapshotname节点个数没有满足条件(还有regionserver的准备工作没有完成),hmaster认为snapshot的准备工作超时。hmaster会新建另一种新的节点/abort-snapshotname,所有regionserver监听到这个命令之后会清理snapshot在临时文件夹中生成的结果。
可以看到,在这个系统中HMaster充当了协调者的角色,RegionServer充当了参与者的角色。HMaster和RegionServer之间的通信通过Zookeeper来完成,同时,事务状态也是记录在Zookeeper上的节点上。HMaster高可用情况下主HMaster宕机了,从HMaster切成主后根据Zookeeper上的状态可以决定事务十分继续提交或者abort。
snapshot核心实现
上节从架构层面介绍了snapshot如何在分布式体系中完成原子性操作。那每个region是如何真正实现snapshot呢?hmaster又是如何汇总所有region snapshot结果?
region如何实现snapshot?
在基本原理一节我们提到过snapshot不会真正拷贝数据,而是使用指针引用的方式创建一系列元数据。那元数据具体是什么样的元数据呢?实际上snapshot的整个流程基本如下:
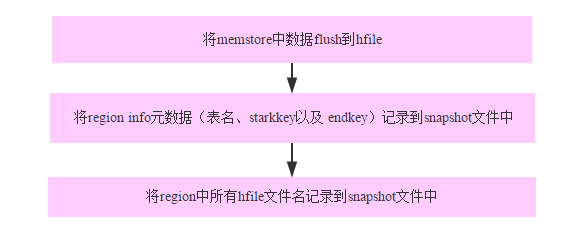
分别对应debug日志中如下片段:
snapshot.FlushSnapshotSubprocedure: Flush Snapshotting region yixin:yunxin,user1359,1502949275629.77f4ac61c4db0be9075669726f3b72e6. started...
snapshot.SnapshotManifest: Storing 'yixin:yunxin,user1359,1502949275629.77f4ac61c4db0be9075669726f3b72e6.' region-info for snapshot.
snapshot.SnapshotManifest: Creating references for hfiles
snapshot.SnapshotManifest: Adding snapshot references for [] hfiles注意:region生成的snapshot文件是临时文件,生成目录在/hbase/.hbase-snapshot/.tmp下,一般因为snapshot过程特别快,所以很难看到单个region生成的snapshot文件。
hmaster如何汇总所有region snapshot的结果?
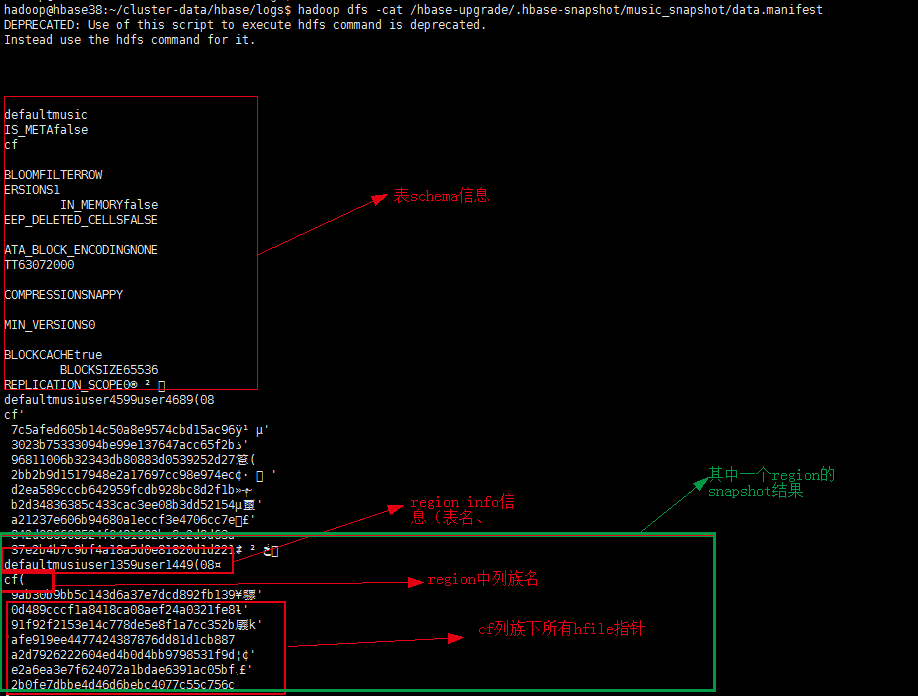
hmaster会在所有region完成snapshot之后执行一个汇总操作(consolidate),将所有region snapshot manifest汇总成一个单独manifest,汇总后的snapshot文件是可以在HDFS目录下看到的,路径为:/hbase/.hbase-snapshot/snapshotname/data.manifest。注意,snapshot目录下有3个文件,如下图所示:

其中.snapshotinfo为snapshot基本信息,包含待snapshot的表名称以及snapshot名;data.manifest为snapshot执行后生成的元数据信息,即snapshot结果信息。可以使用hadoop dfs -cat /hbase/.hbase-snapshot/snapshotname/data.manifest 查看:
clone_snapshot如何实现呢?
前文提到snapshot可以用来搞很多大事情,比如restore_snapshot、clone_snapshot以及export snapshot等等,这节就来看看clone_snapshot这个功能具体是如何实现的。直接进入正题,整个步骤可以概括为如下:
- 预检查:确认目标表没有进行snapshot操作以及restore操作,否则直接返回错误
- 在tmp文件夹下新建表目录并在表目录下新建.tabledesc文件,在该文件中写入表schema信息
- 新建region目录:这个步骤是clone_snapshot和create table最大的不同,新建的region目录是依据snapshot manifest中信息确定的,region中有哪些列族?列族中有哪些HFile文件?都来源于此。
此处有一个很有意思的事情是clone_snapshot克隆表的过程中并不涉及数据的移动,那不禁要问克隆出的表中文件是什么文件?与原表中数据文件之间的对应关系如何建立?这个问题的解决和split过程中reference文件的解决思路基本一致,不过在clone_snapshot中并不称作reference文件,而叫做linkfile,和reference文件不一样的是linkfile文件没有任何内容,只是在文件名上做了文章,比如原文件名是abc,生成的linkfile就为:table=region-abc,通过这种方式就可以很容易定位到原表中原始文件的具体路径:xxx/table/region/hfile,因此就可以不需要移动数据了。

上图中LinkFile文件名为music=5e54d8620eae123761e5290e618d556b-f928e045bb1e41ecbef6fc28ec2d5712,根据定义我们知道music为原始文件的表名,5e54d8620eae123761e5290e618d556b为引用文件所在的region,f928e045bb1e41ecbef6fc28ec2d5712为引用文件,如下图所示:

我们可以依据规则可以直接根据LinkFile的文件名定位到引用文件所在位置:***/music/5e54d8620eae123761e5290e618d556b/cf/f928e045bb1e41ecbef6fc28ec2d5712,如下图所示:

4. 将表目录从tmp文件夹下移动到hbase root location
5. 修改meta表,将克隆表的region信息添加到meta表中,注意克隆表的region名称和原数据表的region名称并不相同(region名称与table名称相关,table名不同,region名称就肯定不会相同)
6. 将这些region通过round-robin方式立刻均匀分配到整个集群中,并在zk上将克隆表的状态设置为enabled,正式对外提供服务
其他需要注意的
不知道大家有没有关注另一个问题,按照上文的说法我们知道snapshot实际上是一系列原始表的元数据,主要包括表schema信息、原始表所有region的region info信息,region包含的列族信息以及region下所有的hfile文件名以及文件大小等。那如果原始表发生了compaction导致hfile文件名发生了变化或者region发生了分裂,甚至删除了原始表,之前所做的snapshot是否就失效了?
从功能实现的角度来讲肯定不会让用户任何时间点所作的snapshot失效,那如何避免上述所列的各种情况下snapshot失效呢?HBase的实现也比较简单,在原始表发生compact的操作前会将原始表复制到archive目录下再执行compact(对于表删除操作,正常情况也会将删除表数据移动到archive目录下),这样snapshot对应的元数据就不会失去意义,只不过原始数据不再存在于数据目录下,而是移动到了archive目录下。
大家可以做一下这样一个实验看看:
1. 使用snapshot给一张表做快照,比如snapshot ’test’,’test_snapshot’
2. 查看archive目录,确认不存在目录:/hbase-root-dir/archive/data/default/test
3. 对表test执行major_compact操作:major_compact ’test’
4. 再次查看archive目录,就会发现test原始表移动到了该目录,/hbase-root-dir/archive/data/default/test就会存在同理,如果对原始表执行delete操作,比如delete ’test’,也会在archive目录下找到该目录。和普通表删除的情况不同的是,普通表一旦删除,刚开始是可以在archive中看到删除表的数据文件,但是等待一段时间后archive中的数据就会被彻底删除,再也无法找回。这是因为master上会启动一个定期清理archive中垃圾文件的线程(HFileCleaner),定期会对这些被删除的垃圾文件进行清理。但是snapshot原始表被删除之后进入archive,并不可以被定期清理掉,上文说过clone出来的新表并没有clone真正的文件,而是生成的指向原始文件的连接,这类文件称之为LinkFile,很显然,只要LinkFile还指向这些原始文件,它们就不可以被删除。好了,这里有两个问题:
1. 什么时候LinkFile会变成真实的数据文件?
如果看过笔者上篇文章《HBase原理 – 所有Region切分的细节都在这里了》的同学,肯定看着这个问题有种似曾相识的赶脚。不错,HBase中一个region分裂成两个子region后,子region的文件也是引用文件,这些引用文件是在执行compact的时候才真正将父region中的文件迁移到自己的文件目录下。LinkFile也一样,在clone出的新表执行compact的时候才将合并后的文件写到新目录并将相关的LinkFile删除,理论上也是借着compact顺便做了这件事。
2. 系统在删除archive中原始表文件的时候怎么知道这些文件还被一些LinkFile引用着?
HBase Split后系统要删除父region的数据文件,是首先要确认两个子region已经没有引用文件指向它了,系统怎么确认这点的呢?上节我们分析过,meta表中会存储父region对应的两个子region,再扫描两个子region的所有文件确认是否还有引用文件,如果已经没有引用文件了,就可以放心地将父region的数据文件删掉了,当然,如果还有引用文件存在就只能作罢。
那删除clone后的原始表文件,是不是也是一样的套路?答案并不是,HBase用了另一种方式来根据原始表文件找到引用文件,这就是back-reference机制。HBase系统在archive目录下新建了一种新的back-reference文件,来帮助原始表文件找到引用文件。来看看back-reference文件是一种什么样的文件,它是如何根据原始文件定位到LinkFile的:
(1)原始文件:/hbase/data/table-x/region-x/cf/file-x
(2)clone生成的LinkFile:/hbase/data/table-cloned/region-y/cf/{table-x}-{region-x}-{file-x},因此可以很容易根据LinkFile定位到原始文件
(3)back-reference文件:/hbase/.archive/data/table-x/region-x/cf/.links-file-x/{region-y}.{table-cloned},可以看到,back-reference文件路径中包含所有原始文件和LinkFile的信息,因此可以有效的根据原始文件/table-x/region-x/cf/file-x定位到LinkFile:/table-cloned/region-y/cf/{table-x}-{region-x}-{file-x}
到这里,有兴趣的童鞋可以将这块知识点串起来做个简单的小实验:
(1)使用snapshot给一张表做快照,比如snapshot ’table-x’,’table-x-snapshot’
(2)使用clone_snapshot克隆出一张新表,比如clone_snapshot ’table-x-snapshot’,’table-x-cloned’。并查看新表test_clone的HDFS文件目录,确认会存在LinkFile

(3)删除原表table-x(删表之前先确认archive下没有原表文件),查看确认原表文件进入archive,并在archive中存在back-reference文件。注意瞅瞅back-reference文件格式哈。


(4)对表’table-x-clone’执行major_compact,命令为major_compact ’test_clone’。执行命令前确认table-x-clone文件目录下LinkFile存在。
(5)major_compact执行完成之后查看table-x-clone的HDFS文件目录,确认所有LinkFile已经不再存在,全部变成了真实数据文件。

参考文献
Introduction to Apache HBase Snapshots:http://blog.cloudera.com/blog/2013/03/introduction-to-apache-hbase-snapshots/
Introduction to Apache HBase Snapshots, Part 2: Deeper Dive:http://blog.cloudera.com/blog/2013/06/introduction-to-apache-hbase-snapshots-part-2-deeper-dive/
最后
以上就是认真冬天最近收集整理的关于HBase原理 – snapshot 快照的全部内容,更多相关HBase原理内容请搜索靠谱客的其他文章。








发表评论 取消回复