redis的数据结构以及使用场景分析
1. string
a. 底层结构
string的数据结构存储的是key-value类型, value不仅可以是string,也可以是数字。
redis中的String是可以修改的,称为动态字符串(SDS),其实就是维护了一个预分配的字节数组,如下
struct SDS{
T capacity; //数组容量
T len; //实际长度
byte flages; //标志位,低三位表示类型
byte[] content; //数组内容
}
b. 常用命令
set [key] [value] 给指定key设置值(set 可覆盖老的值)
get [key] 获取指定key 的值
del [key] 删除指定key
exists [key] 判断是否存在指定key
mset [key1] [value1] [key2] [value2] ...... 批量存键值对
mget [key1] [key2] ...... 批量取key
expire [key] [time] 给指定key 设置过期时间 单位秒
setex [key] [time] [value] 等价于 set + expire 命令组合
setnx [key] [value] 如果key不存在则set 创建,否则返回0
incr [key] 如果value为整数 可用 incr命令每次自增1
incrby [key] [number] 使用incrby命令对整数值 进行增加 number
c. 使用场景举例
缓存
简单key-value存储
分布式锁
setnx key value,当key不存在时,将 key 的值设为 value ,返回1
若给定的 key 已经存在,则setnx不做任何动作,返回0。
当setnx返回1时,表示获取锁,做完操作以后del key,表示释放锁,如果setnx返回0表示获取锁失败,整体思路大概就是这样
计数器
如知乎每个问题的被浏览器次数
全局标志位
例如售罄标志,防止超卖
2. hash
a. 底层结构
Redis中的Hash和 Java的HashMap更加相似,都是数组+链表的结构,当发生 hash 碰撞时将会把元素追加到链表上,下面是hash存储的一个KV结构
key=JavaUser293847
value={
“id”: 1,
“name”: “SnailClimb”,
“age”: 22,
“location”: “Wuhan, Hubei”
}
(可以看作是 map< key, map<key, value> >)
b. 常用指令
hset [key] [field] [value] 新建字段信息
hget [key] [field] 获取字段信息
hdel [key] [field] 删除字段
hlen [key] 保存的字段个数
hgetall [key] 获取指定key 字典里的所有字段和值 (字段信息过多,会导致慢查询 慎用:亲身经历 曾经用过这个这个指令导致线上服务故障)
hmset [key] [field1] [value1] [field2] [value2] ...... 批量创建
hincr [key] [field] 对字段值自增
hincrby [key] [field] [number] 对字段值增加number
c. 应用场景
可以存储对象( (对象名,成员变量名,值) )
3. list
a. 底层结构
Redis中的list和Java中的LinkedList很像,底层都是一种链表结构,list的插入和删除操作非常快,时间复杂度为 0(1),不像数组结构插入、删除操作需要移动数据。
像归像,但是redis中的list底层可不是一个双向链表那么简单。
在redis3.2版本之前,对list的实现是:
- 当数据量较少的时候它的底层存储结构为一块连续内存,称之为ziplist(压缩列表),它将所有的元素紧挨着一起存储,分配的是一块连续的内存;(保存的是entry数组)
struct ziplist<T>{
int32 zlbytes; //压缩列表占用字节数
int32 zltail_offset; //最后一个元素距离起始位置的偏移量,用于快速定位到最后一个节点
int16 zllength; //元素个数
T[] entries; //元素内容
int8 zlend; //结束位 0xFF
}
- 当数据量较多的时候,它的底层结构是使用linkedlist来做的,是离散的。
typedef struct listNode{
struct listNode *prev;
struct listNode *next;
void *value;
}listNode;
typedef struct list{
listNode *head;
listNode *tail;
unsigned long len; // 链表长度
......
......
}list;
重新引入了一个 quicklist 的数据结构,列表的底层都由quicklist实现。
quicklist其实就是又对linkedlist和ziplist进行了一层抽象,变为quicklistnode, 它可以指向压缩后的list,也可以指向未压缩的list, 如下图
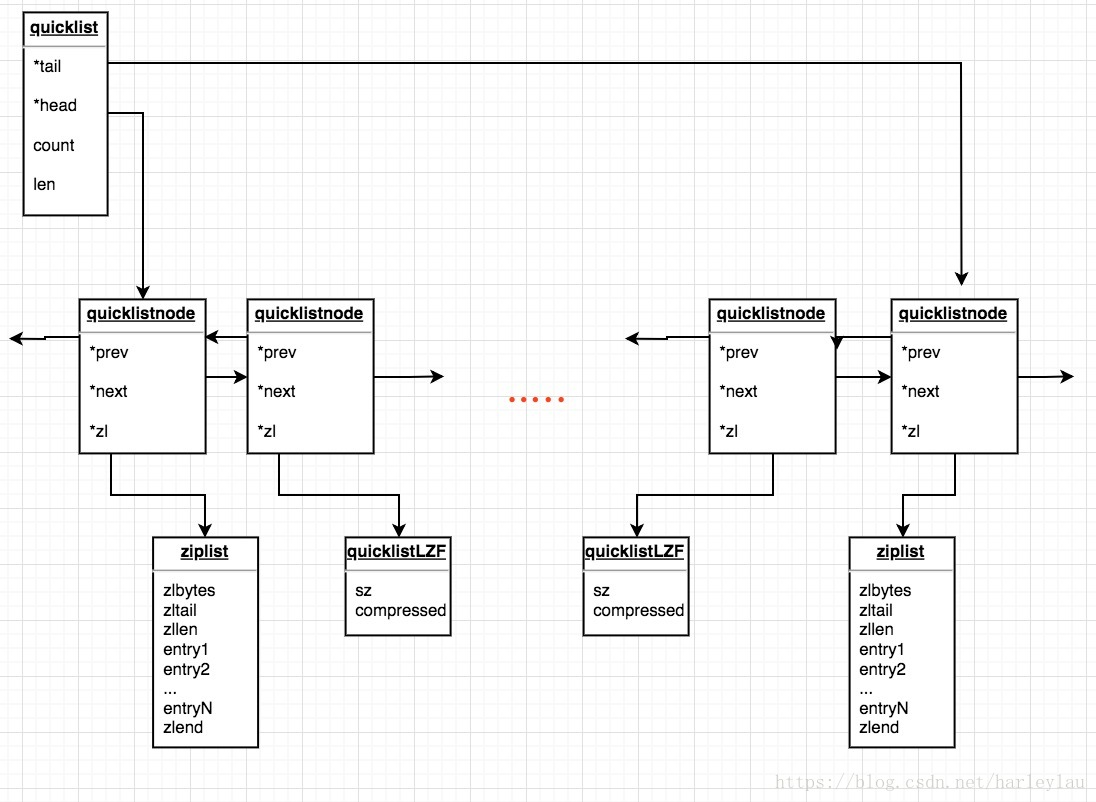
typedef struct quicklist {
quicklistNode *head; // 指向quicklist的头部
quicklistNode *tail; // 指向quicklist的尾部
unsigned long count; // 列表中所有数据项的个数总和
unsigned int len; // quicklist节点的个数,即ziplist的个数
int fill : 16; // ziplist大小限定,由list-max-ziplist-size给定
unsigned int compress : 16; // 节点压缩深度设置,由list-compress-depth给定
} quicklist;
typedef struct quicklistNode {
struct quicklistNode *prev; // 指向上一个ziplist节点
struct quicklistNode *next; // 指向下一个ziplist节点
unsigned char *zl; // 数据指针,如果没有被压缩,就指向ziplist结构,反之指向quicklistLZF结构
unsigned int sz; // 表示指向ziplist结构的总长度(内存占用长度)
unsigned int count : 16; // 表示ziplist中的数据项个数
unsigned int encoding : 2; // 编码方式,1--ziplist,2--quicklistLZF
unsigned int container : 2; // 预留字段,存放数据的方式,1--NONE,2--ziplist
unsigned int recompress : 1; // 解压标记,当查看一个被压缩的数据时,需要暂时解压,标记此参数为1,之后再重新进行压缩
unsigned int attempted_compress : 1; // 测试相关
unsigned int extra : 10; // 扩展字段,暂时没用
} quicklistNode;
b. 常用指令
rpush [key] [value1] [value2] ...... 链表右侧插入
rpop [key] 移除右侧列表头元素,并返回该元素
lpop [key] 移除左侧列表头元素,并返回该元素
llen [key] 返回该列表的元素个数
lrem [key] [count] [value] 删除列表中与value相等的元素,count是删除的个数。 count>0 表示从左侧开始查找,删除count个元素,count<0 表示从右侧开始查找,删除count个相同元素,count=0 表示删除全部相同的元素
(PS: index 代表元素下标,index 可以为负数, index= 表示倒数第一个元素,同理 index=-2 表示倒数第二 个元素。)
lindex [key] [index] 获取list指定下标的元素 (需要遍历,时间复杂度为O(n))
lrange [key] [start_index] [end_index] 获取list 区间内的所有元素 (时间复杂度为 O(n))
ltrim [key] [start_index] [end_index] 保留区间内的元素,其他元素删除(时间复杂度为 O(n))
c. 应用场景
由于list它是一个按照插入顺序排序的列表,所以应用场景相对还较多的,例如:
消息队列
lpop和rpush(或者反过来,lpush和rpop)能实现队列的功能
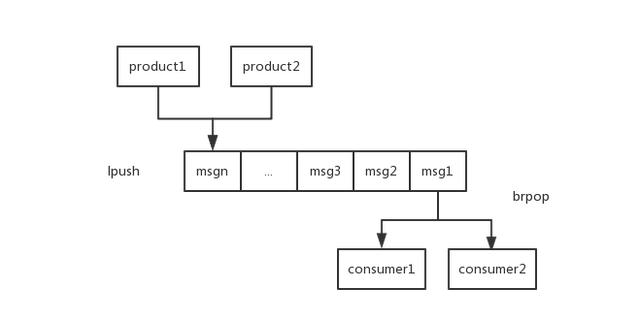
朋友圈用户消息列表
例如想拿最近发得10条动态,就可以使用 lrange 来拿
4. set
a. 底层结构
Redis中的set和Java中的HashSet有些类似,它内部的键值对是无序的、唯一 的。它的内部实现相当于一个特殊的字典,字典中所有的value都是一个值 NULL。当集合中最后一个元素被移除之后,数据结构被自动删除,内存被回收。
b. 常用指令
sadd [key] [value] 向指定key的set中添加元素
smembers [key] 获取指定key 集合中的所有元素
sismember [key] [value] 判断集合中是否存在某个value
scard [key] 获取集合的长度
spop [key] 弹出一个元素
srem [key] [value] 删除指定元素
sinterstore key1 key2 key3 将交集存在key1内
d. 高频指令
求交集:sinterstore key1 key2 key3 将交集存在key1内
c. 应用场景
在微博应用中,可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。Redis 可以非常方便的实现如共同关注、共同粉丝、共同喜好、共同好友等功能。这个过程也就是求交集的过程。
(关键字:共同)
5. zset ( sorted set )
和 set 相比,sorted set 增加了一个权重参数 score,使得集合中的元素能够按 score 进行有序排列。
a. 底层结构
zset是基于skiplist(跳表)实现的。
b. 常用指令
zadd [key] [score] [value] 向指定key的集合中增加元素
zrange [key] [start_index] [end_index] 获取下标范围内的元素列表,按score 排序输出
zrevrange [key] [start_index] [end_index] 获取范围内的元素列表 ,按score排序 逆序输出
zcard [key] 获取集合列表的元素个数
zrank [key] [value] 获取元素再集合中的排名
zrangebyscore [key] [score1] [score2] 输出score范围内的元素列表
zrem [key] [value] 删除元素
zscore [key] [value] 获取元素的score
c. 应用场景
zset可以用做排行榜,但是和list不同的是zset它能够实现动态的排序,例如: 可以用来存储粉丝列表,value 值是粉丝的用户 ID,score 是关注时间,我们可以对粉丝列表按关注时间进行排序。
zset还可以用来存储学生的成绩,value值是学生的 ID,score是他的考试成绩。 我们对成绩按分数进行排序就可以得到他的名次。
(关键字:排行榜)
d. 高频指令
- 求名次为[a,b]的分数的玩家 :
zrevrange [key] [start_index] [end_index]ps: zrange是升序,zrevrange是降序 - 求某一个玩家的排名 :
zrank - 求分数为[a,b]的玩家 :
zrangebyscore [key] [score1] [score2] - 求某一个玩家的分数 :
zscore [key] [value]( zscore player_set czf )
最后
以上就是眼睛大大白最近收集整理的关于redis的数据结构以及使用场景分析redis的数据结构以及使用场景分析的全部内容,更多相关redis内容请搜索靠谱客的其他文章。








发表评论 取消回复