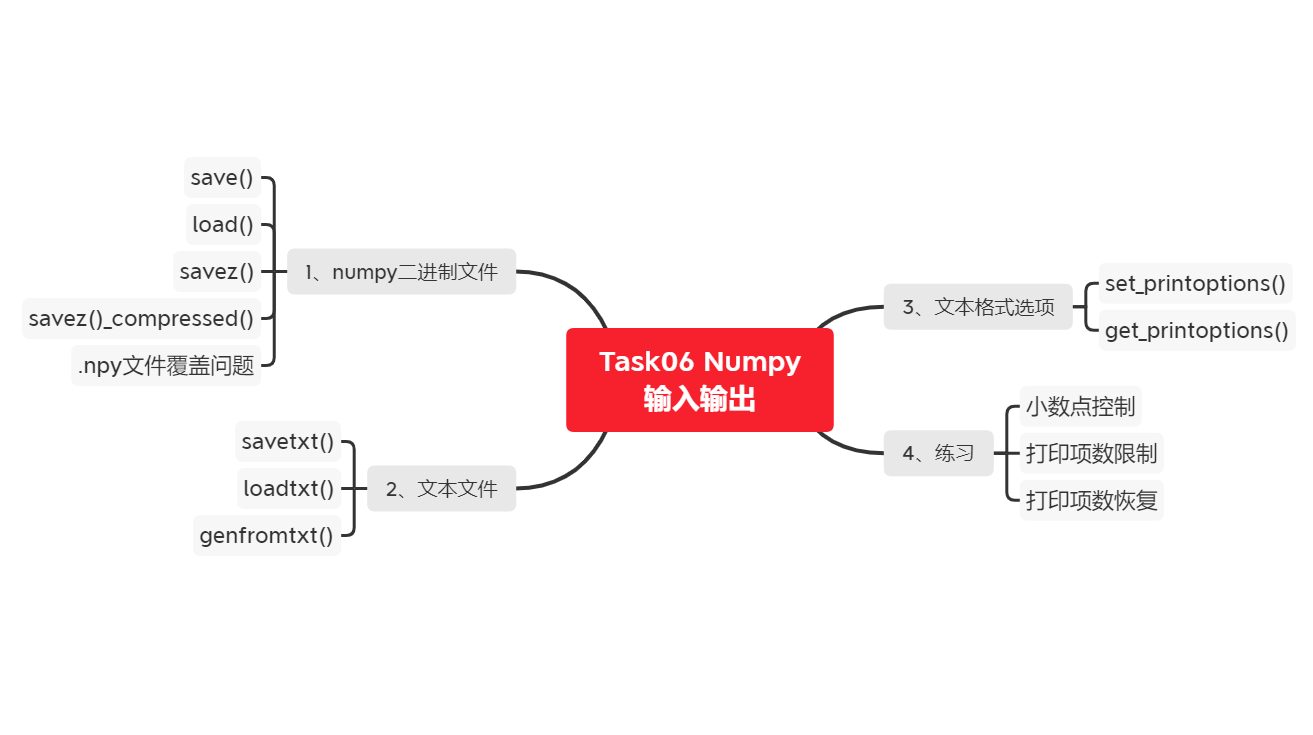
Task06学习思维导图
注:为了节约行数,默认import numpy as np已经写在每段代码前,不再重复写入,如果有新的包引入,会在代码头部import。
前言
Numpy 可以读写磁盘上的文本数据或二进制数据。
NumPy 为 ndarray 对象引入了一个简单的文件格式:npy。
npy 文件用于存储重建 ndarray 所需的数据、图形、dtype 和其他信息。
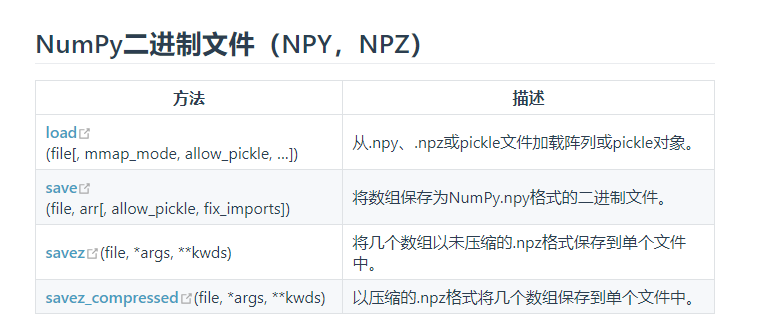
常用的 IO 函数有:
load() 和 save() 函数是读写文件数组数据的两个主要函数,默认情况下,数组是以未压缩的原始二进制格式保存在扩展名为 .npy 的文件中。
savez() 函数用于将多个数组写入文件,默认情况下,数组是以未压缩的原始二进制格式保存在扩展名为 .npz 的文件中。
numpy.savez_compressed()函数用于保存压缩的npz文件。
loadtxt() 、savetxt()和genfromtxt()函数处理正常的文本文件(.txt、.csv等)
一、numpy二进制文件
numpy二进制文件方法有如下几种:
1、save()方法

参数解释:
- file:文件对象、字符串或者路径,如果当前文件名不存在,会自动在文件后添加“.npy”
- arr:将要添加的Array
- allow_pickie:允许添加pickles数据类型,默认为True
- fix_import2:允许从python2读入pickie data stream,默认为True
2、load()方法
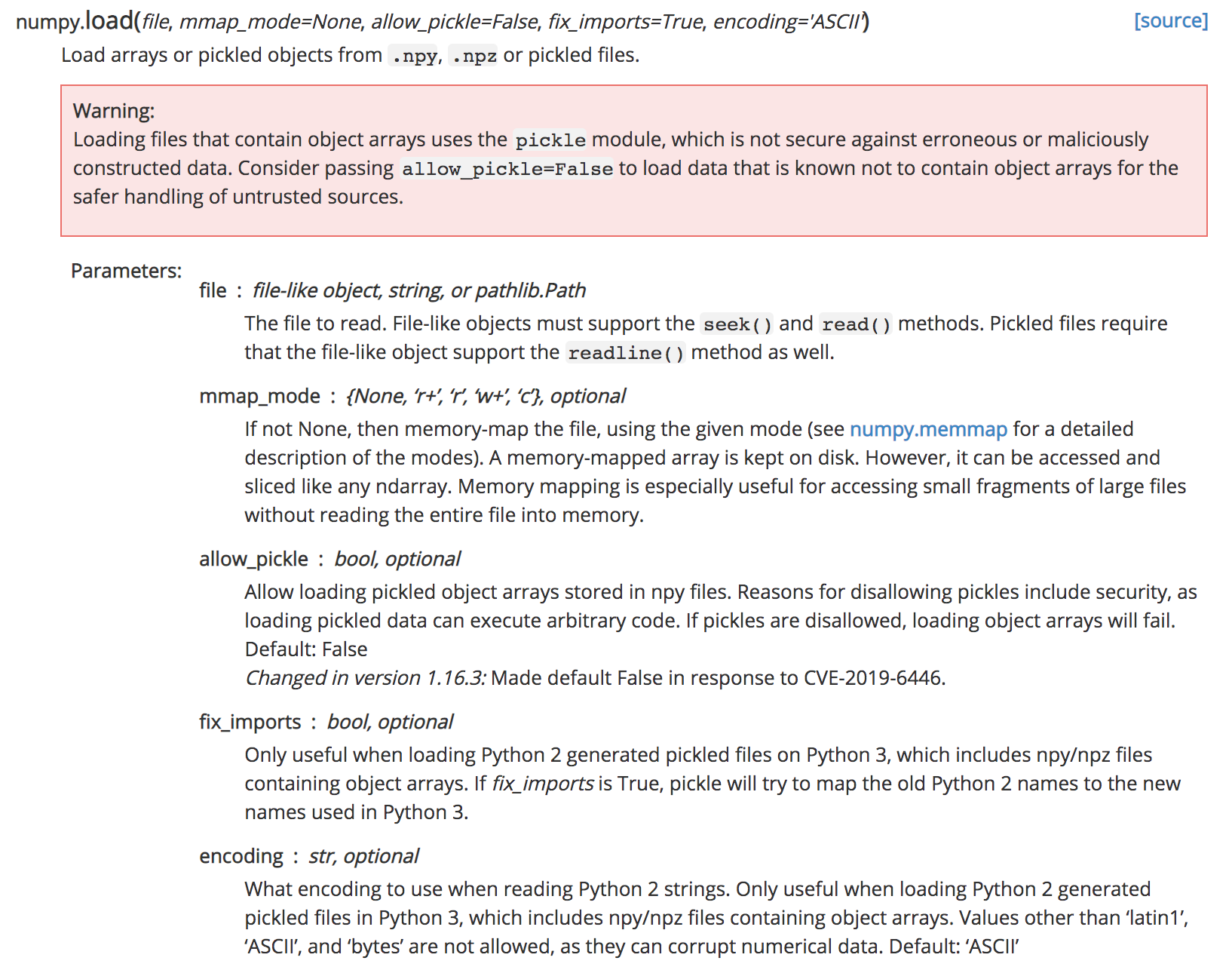
参数解释:
- file:文件对象、字符串或者路径,如果当前文件名不存在,会自动在文件后添加“.npy”
- mmap_mode: load模式
- allow_pickie:允许添加pickles数据类型,默认为True
- fix_import2:允许从python2读入pickie data stream,默认为True
- encoding:制定编码格式,默认为“ASCII”
3、save()和load()方法举例
>>> outfile = r'.test.npy'
>>> np.random.seed(20201123)
>>> x = np.random.randint(0,100,[5,5])
#参数1表示文件名 参数2表示要输入的数据
>>> np.save(outfile,x)
>>> y = np.load(outfile)
>>> print(y)
[[31 30 53 94 66]
[47 99 0 85 45]
[57 43 28 89 4]
[57 67 91 87 99]
[33 73 35 37 33]]
这里注意,使用save()时,第一个参数可以不加.npy后缀。
4、savez()方法

参数解释:
- file:文件对象、字符串,如果当前文件名不存在,会自动在文件后添加“.npz”
- args:想要添加的数组,默认name为“arr_0”、“arr_1”等等
- kwds:要保存的数组使用关键字名称
5、savez()方法举例
>>> outfile = r'.test.npz'
>>> x = np.linspace(0,np.pi,5)
>>> y = np.sin(x)
>>> z = np.cos(x)
>>> a = np.arange(5)
>>> np.savez(outfile,x,y,xiao=z,hys=a)
>>> data = np.load(outfile)
>>> print(data.files)
['xiao', 'hys', 'arr_0', 'arr_1']
>>> for x in data.files:
>>> print(data[x])
[ 1.00000000e+00 7.07106781e-01 6.12323400e-17 -7.07106781e-01
-1.00000000e+00]
[0 1 2 3 4]
[0. 0.78539816 1.57079633 2.35619449 3.14159265]
[0.00000000e+00 7.07106781e-01 1.00000000e+00 7.07106781e-01
1.22464680e-16]
我们可以看到,在自定义数组的关键字名称后,它们是依次向后插入的,有一种数据结构中队列的思想,先进的放在前面,先被访问。
当然,我们也可以用data['arr_0']来直接访问npz文件。
6、savez_compressed()方法
savez_compressed()方法用于保存压缩的npz文件:

参数解释与savez()方法一致,不加赘述。
7、savez_compressed()方法举例
outfile1 = r'.npz1.npz'
outfile2 = r'.npz2.npz'
x = np.linspace(0,np.pi,5)
y = np.sin(x)
z = np.cos(x)
np.savez(outfile1,x,y,z_d=z)
np.savez_compressed(outfile2,x,y,z_d=z)
data = np.load(outfile2)
for x in data.files:
print(data[x])
[ 1.00000000e+00 7.07106781e-01 6.12323400e-17 -7.07106781e-01
-1.00000000e+00]
[0. 0.78539816 1.57079633 2.35619449 3.14159265]
[0.00000000e+00 7.07106781e-01 1.00000000e+00 7.07106781e-01
1.22464680e-16]
我们可以看到在使用上,它与savez()方法没有任何区别,然后我们再看生成的文件:
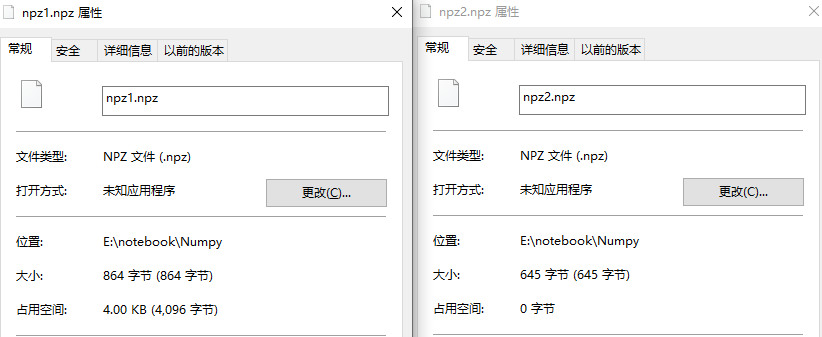
我们可以得知savez_compressed()方法相比于savez()方法确实压缩了npz文件。
8、探究修改npy文件会出现覆盖的问题及如何避免
#探究填数据问题
def printRow(filename):
with open(filename,'rb') as f:
while(True):
try:
a = np.load(f)
print(a)
except:
print('----end----')
return
>>> outfile = r'.test.npy'
>>> f1 = open(outfile,'wb')
>>> np.save(f1, np.array([1, 2]))
>>> np.save(f1, np.array([3, 4]))
>>> printRow(outfile)
[1 2]
[3 4]
----end----
#情况一
>>> np.save(f1, np.array([5, 6]))
>>> printRow(outfile)
[1 2]
[3 4]
[5 6]
----end----
#情况二
>>> f1.close()
>>> with open(outfile,'wb') as f:
>>> np.save(f, np.array([7, 8]))
>>> printRow(outfile)
[7 8]
----end----
这里printRow()函数是用来打印文件中所有数据的自定义函数,功能不是重点。
在情况一中,我们没有关闭文件指针,所以save()方法会继续在文件末尾保存,在情况二中,我们关闭了之前的文件对象,利用with语句重新打开该npy文件,此时由于文件指针在文件最开始,所以save()会覆盖之前所有的数据。
二、文本文件
文本文件的相关方法如下:
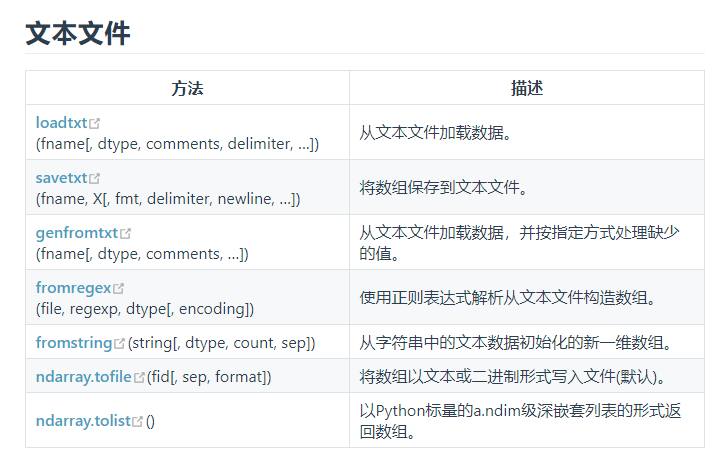
1、savetxt()方法

参数解释:
- fname:文件路径
- X:存入文件的数组
- fmt:写入文件中每个元素的字符串格式,默认’%.18e’(保留18位小数的浮点数形式)
- delimiter:分割字符串,默认以空格分隔
- newline:分隔列的字符串或字符
- header:将在文件开头写入的字符串
- footer:将写在文件末尾的字符串
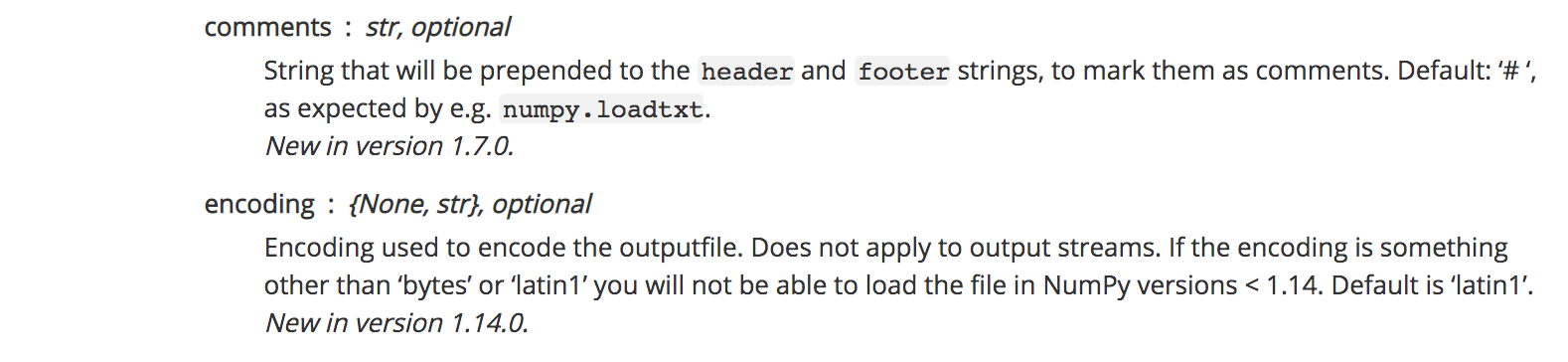
- comments:将附加到header和footer字符串的字符串,以将其标记为注释
- encoding:输出文件的编码
2、loadtxt()方法


参数解释:
- fname:文件路径
- dtype:指定读取后数据的数据类型
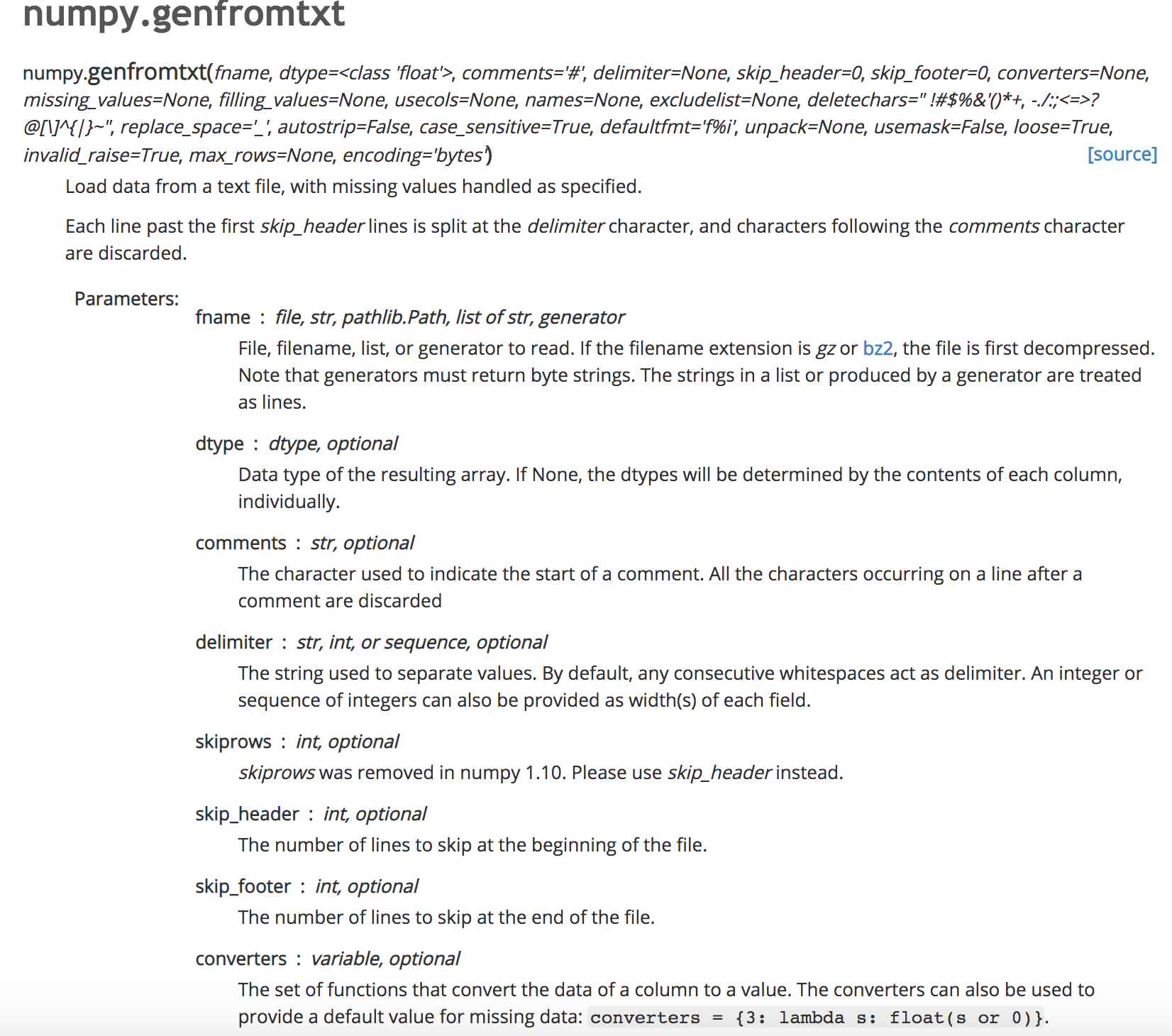
- comments:跳过文件中指定参数开头的行(即不读取)
- delimiter:分割字符串,默认以空格分隔
- converters:对读取的数据进行预处理
- skiprows:选择跳过的行数
- usecols:指定需要读取的列
- unpack:选择是否将数据进行向量输出
- ndmin:限制输出array的最小维度
- encoding:对读取的文件进行预编码
- max_rows:在skiprows之后最多可以读取的行数
3、savetxt()和loadtxt()方法举例
#保存和读取txt文件
>>> outfile = r'.test.txt'
>>> x = np.arange(0, 10).reshape(5, -1)
>>> np.savetxt(outfile, x)
>>> y = np.loadtxt(outfile)
>>> print(y)
[[0. 1.]
[2. 3.]
[4. 5.]
[6. 7.]
[8. 9.]]
>>> a=np.arange(0,10,0.5).reshape(4,-1)
>>> np.savetxt("out.csv",a,fmt="%f",delimiter=",")
>>> b = np.loadtxt("out.csv",delimiter=",")
>>> print(b)
[[0. 0.5 1. 1.5 2. ]
[2.5 3. 3.5 4. 4.5]
[5. 5.5 6. 6.5 7. ]
[7.5 8. 8.5 9. 9.5]]
直接打开csv文件:
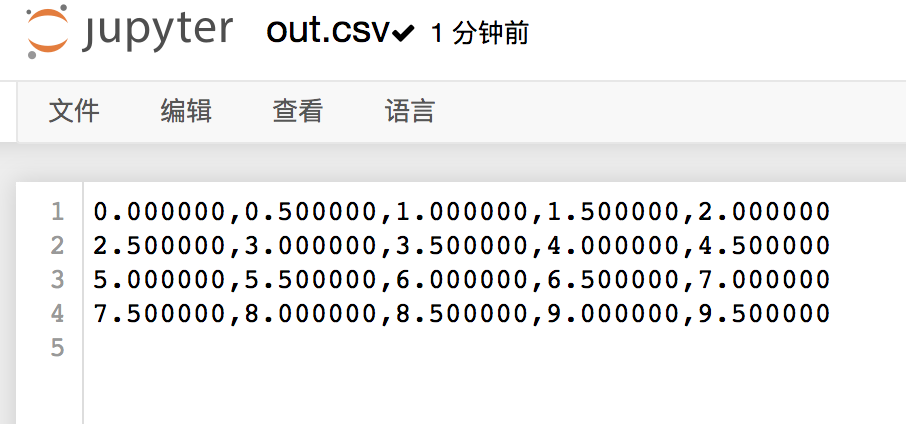
我们可以发现直接打开csv文件和用loadtxt()方法相比还是有一点差距的,至于如何改变print的输出格式我会在下一章说明。
4、genfromtxt()方法


参数解释:
- fname:文件路径
- dtype:指定读取后数据的数据类型
- comments:跳过文件中指定参数开头的行(即不读取)
- delimiter:分割字符串,默认以空格分隔
- skiprows:选择跳过的行数
- skip_header:选择跳过的开头行数
- skip_footer:选择跳过的尾部行数
- converters:对读取的数据进行预处理
- missing/missing_values:与缺失数据相对应的字符串集
- filling_values:指定填充的字符
- usecols:指定需要读取的列
- names:是否读取属性名
#确保字段名称不包含任何空格或无效字符的三个属性:
-
1)excludelist:提供要排除的名称列表,排除的名称会在后面加一个下划线
-
2)deletechars:提供一个字符串,组合必须从名称中删除的所有字符。默认情况下,无效字符为~!@#$%^& *() - = +〜 |]} [{’;: /?.& &lt。
-
3)case_sensitive:field names是否大小写敏感,若设置则在打印x.dtype时会产生改变
-
defaultfmt:定义初始化field names的格式
-
autostrip:是否保留数据中前导或尾随的空格
-
replace_space:对于field names中的空格提供替换的字符
-
unpack:选择是否将数据进行向量输出
-
usemask:是否使用mask,功能为使用‘–’代替传统的nan
-
loose:是否针对invalid values报错
-
invalid_raise:监测到不合法行的时候是否报错
-
max_rows:在skiprows之后最多可以读取的行数
-
encoding:对读取的文件进行预编码
这里由于invalid_raise参数的使用比较难理解,所以举例说明:
目标文件:
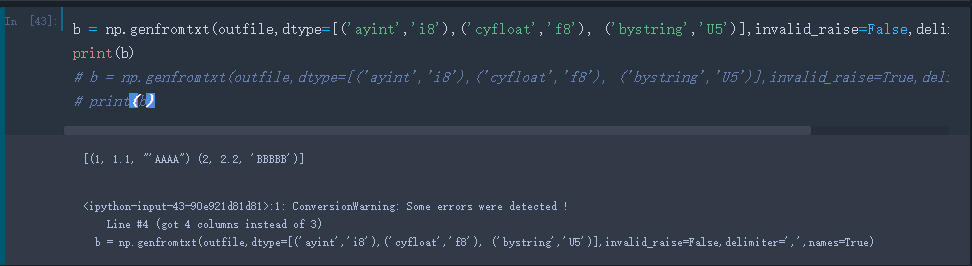
使用代码,此处只是warning级别,后续代码仍可以执行:
若将此参数设为True,则:
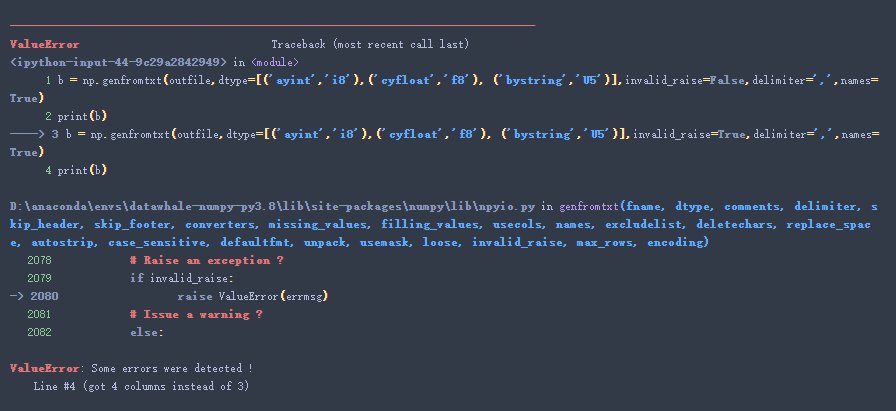
后续代码不可以执行。
5、genfromtxt()方法举例
>>> outfile = r'data.csv'
>>> x = np.genfromtxt(outfile, delimiter=',', names=True)
>>> print(x)
[(1., 123., 1.4, 23.) (2., 110., nan, 18.) (3., nan, 2.1, 19.)]
>>> print(type(x))
<class 'numpy.ndarray'>
>>> print(x.dtype)
[('id', '<f8'), ('value1', '<f8'), ('value2', '<f8'), ('value3', '<f8')]
>>> print(x['id'])
[1. 2. 3.]
>>> print(x['value1'])
[123. 110. nan]
>>> print(x['value2'])
[1.4 nan 2.1]
>>> print(x['value3'])
[23. 18. 19.]
我们可以看到genfromtxt()方法可以将空白补为nan
三、文本格式选项
1、set_printoptions()方法


参数解释:
- precision:设置浮点精度,控制输出的小数点个数,默认是8
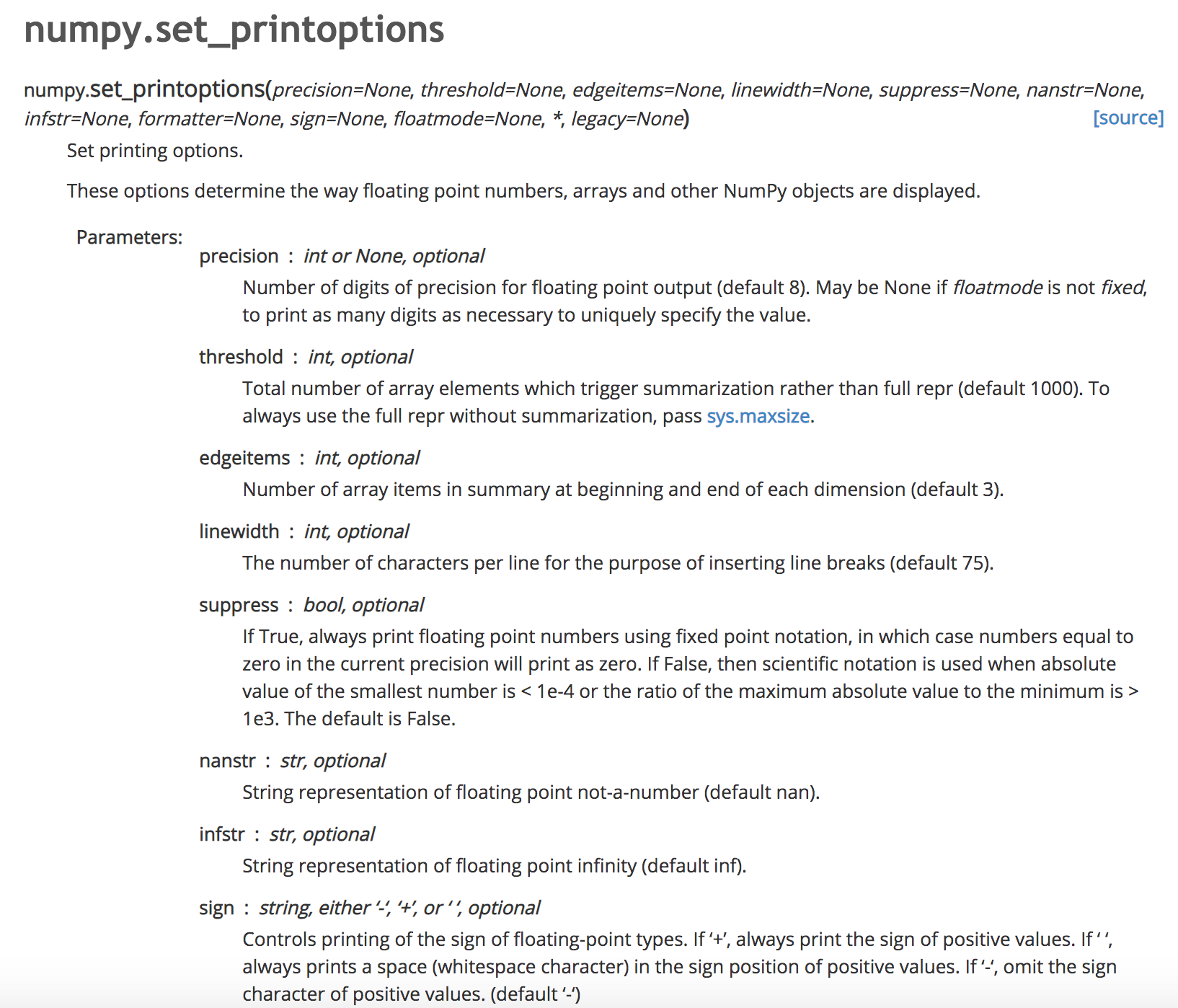
- threshold:概略显示,数据长度超过该值则以“…”的形式来表示,默认是1000:
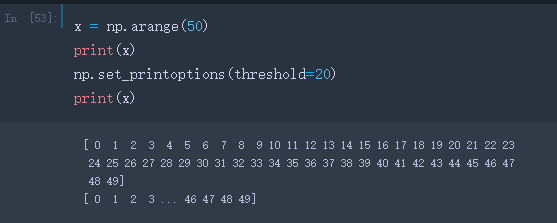
- edgeitems:在开头和结尾的摘要中的数组项数 每个维度 简单理解就是改变上面参数前后的显示数量,默认是3:
- linewidth:用于确定每行多少字符数后插入换行符,默认为75
- suppress:当suppress=True,表示小数不需要以科学计数法的形式输出,默认是False
- nanstr:浮点非数字的字符串表示形式,默认nan
- infstr:浮点无穷大的字符串表示形式,默认inf
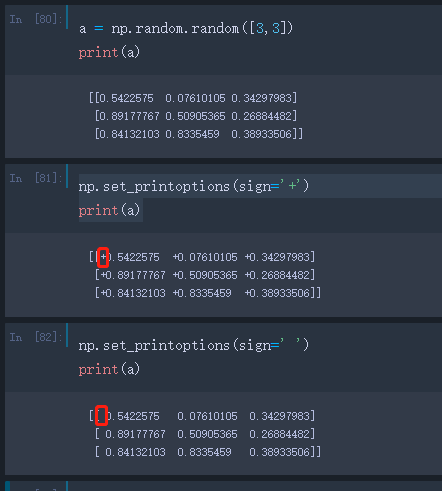
- sign:控制浮点类型符号的打印,‘+’打印正值,‘-’不打印,‘ ’表示打印空格:
- formatter:可调用字典,格式化功能
- floatmode:控制precision选项
- legacy:设置传统打印模式,False则禁用传统模式
2、get_printoptions()方法
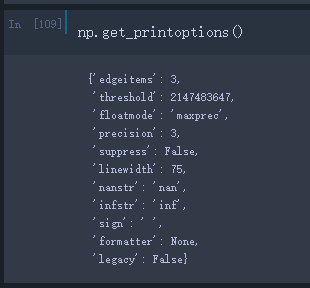
get_printoptions()方法的内容解释都可以在上一节找到,所以不加赘述。
四、练习
1、只打印或显示numpy数组rand_arr的小数点后3位。
rand_arr = np.random.random([5, 3])
【知识点:输入和输出】
如何在numpy数组中只打印小数点后三位?
>>> rand_arr = np.random.random([5, 3])
>>> print(rand_arr)
[[ 0.2702845 0.81236709 0.26412603]
[ 0.7338969 0.72472315 0.18310301]
[ 0.77319474 0.23241475 0.4175588 ]
[ 0.48420047 0.24837131 0.4236997 ]
[ 0.94304758 0.28155661 0.80372373]]
>>> np.set_printoptions(precision=3)
>>> print(rand_arr)
[[ 0.27 0.812 0.264]
[ 0.734 0.725 0.183]
[ 0.773 0.232 0.418]
[ 0.484 0.248 0.424]
[ 0.943 0.282 0.804]]
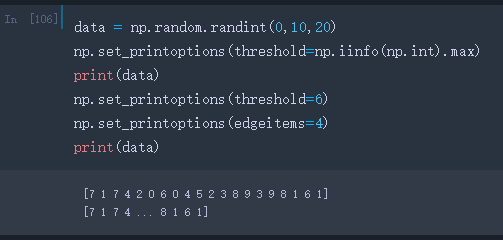
2、将numpy数组a中打印的项数限制为最多6个元素。
【知识点:输入和输出】
如何限制numpy数组输出中打印的项目数?
>>> data = np.random.randint(0,10,20)
>>> np.set_printoptions(threshold=np.iinfo(np.int).max)
>>> print(data)
[1 1 4 3 1 7 6 4 5 8 7 0 5 0 1 7 4 9 0 0]
>>> np.set_printoptions(threshold=6)
>>> np.set_printoptions(edgeitems=3)
>>> print(data)
[1 1 4 ... 9 0 0]
注意除了改变threshold属性以外还要改变edgeitems属性,大小时前者的一般,否则会出现这种情况:
3、打印完整的numpy数组a而不中断。
【知识点:输入和输出】
如何打印完整的numpy数组而不中断?
>>> np.set_printoptions(threshold=np.iinfo(np.int).max)
>>> print(data)
[1 1 4 3 1 7 6 4 5 8 7 0 5 0 1 7 4 9 0 0]
参考文献
#菜鸟教程-numpy部分
1.https://www.runoob.com/numpy/numpy-io.html
#np.set_printoptions
2.https://blog.csdn.net/weixin_41043240/article/details/79721114
#numpy官方网站
3.https://numpy.org/doc/stable/reference/generated/numpy.save.html
#三种numpy保存数据的方法
4.https://www.jb51.net/article/143411.htm
#numpy教程:基本输入输出和文件输入输出Input and output
5.https://blog.csdn.net/pipisorry/article/details/39088003
#genfromtxt函数详解
6.https://www.cnblogs.com/zhangyafei/p/10567891.html
#numpy 中关于genfromtxt的几个示例
7.https://blog.csdn.net/tumin999/article/details/19413703
#set_printoptions设置输出样式
8.https://www.it610.com/article/1280647054577647616.htm
最后
以上就是长情悟空最近收集整理的关于【Task06】Numpy学习打卡Task06学习思维导图前言一、numpy二进制文件二、文本文件三、文本格式选项四、练习参考文献的全部内容,更多相关【Task06】Numpy学习打卡Task06学习思维导图前言一、numpy二进制文件二、文本文件三、文本格式选项四、练习参考文献内容请搜索靠谱客的其他文章。








发表评论 取消回复