在《微服务治理1 - Eureka服务治理架构及客户端装配和启动流程分析》中介绍了Eureka Client端主要提供以下功能:
- 服务注册:服务在启动时通过发送REST请求将自己注册到Eureka注册中心
- 服务续约(Renew):周期性的向Eureka注册中心发送心跳信息,以防止Eureka注册中心将服务剔除
- 服务下线:关闭服务时,向Eureka注册中心发送REST请求,告诉Eureka注册中心服务下线
- 获取服务列表:向Eureka注册中心发送REST请求以获取Eureka注册中心上的注册的服务清单
接下来将逐条分析上述功能的源码。
1. 服务注册
在文章《微服务治理1 - Eureka服务治理架构及客户端装配和启动流程分析》中的步骤(14)~(15)中说明了服务注册是在DiscoverClient的initScheduledTasks()函数中完成的,接下来看看initScheduledTasks()函数的源码:
private void initScheduledTasks() {
......
(1)if (clientConfig.shouldRegisterWithEureka()) {
int renewalIntervalInSecs = instanceInfo.getLeaseInfo().getRenewalIntervalInSecs();
int expBackOffBound = clientConfig.getHeartbeatExecutorExponentialBackOffBound();
logger.info("Starting heartbeat executor: " + "renew interval is: {}", renewalIntervalInSecs);
// Heartbeat timer
(2)scheduler.schedule(
new TimedSupervisorTask(
"heartbeat",
scheduler,
heartbeatExecutor,
renewalIntervalInSecs,
TimeUnit.SECONDS,
expBackOffBound,
new HeartbeatThread()
),
renewalIntervalInSecs, TimeUnit.SECONDS);
// InstanceInfo replicator
(3)instanceInfoReplicator = new InstanceInfoReplicator(
this,
instanceInfo,
clientConfig.getInstanceInfoReplicationIntervalSeconds(),
2); // burstSize
statusChangeListener = new ApplicationInfoManager.StatusChangeListener() {
@Override
public String getId() {
return "statusChangeListener";
}
@Override
public void notify(StatusChangeEvent statusChangeEvent) {
if (InstanceStatus.DOWN == statusChangeEvent.getStatus() ||
InstanceStatus.DOWN == statusChangeEvent.getPreviousStatus()) {
// log at warn level if DOWN was involved
logger.warn("Saw local status change event {}", statusChangeEvent);
} else {
logger.info("Saw local status change event {}", statusChangeEvent);
}
instanceInfoReplicator.onDemandUpdate();
}
};
if (clientConfig.shouldOnDemandUpdateStatusChange()) {
applicationInfoManager.registerStatusChangeListener(statusChangeListener);
}
(4)instanceInfoReplicator.start(clientConfig.getInitialInstanceInfoReplicationIntervalSeconds());
} else {
logger.info("Not registering with Eureka server per configuration");
}
}(1) 是否向Eureka Server注册服务信息,默认为true,可以通过eureka.client.register-with-eureka配置属性控制
(2) 服务续约,在后续的章节详细介绍
(3) 实例化InstanceInfoReplicator对象,该类的注释如下:
/**
* A task for updating and replicating the local instanceinfo to the remote server. Properties of this task are:
* - configured with a single update thread to guarantee sequential update to the remote server
* - update tasks can be scheduled on-demand via onDemandUpdate()
* - task processing is rate limited by burstSize
* - a new update task is always scheduled automatically after an earlier update task. However if an on-demand task
* is started, the scheduled automatic update task is discarded (and a new one will be scheduled after the new
* on-demand update).
*/从注释中可以看出其是任务类,负责将服务实例信息周期性的上报到Eureka server,其特性如下:
- 两个触发场景:单线程周期性自动更新实例信息、通过调用
onDemandUpdate()函数按需更新实例信息 - 任务处理通过burstSize参数来控制频率
- 先创建的任务总是先执行,但是
onDemandUpdate()方法中创建的任务会将周期性任务给丢弃掉
在实例化InstanceInfoReplicator对象时,传入了4个参数,其中:
instanceInfo代表服务实例信息,该实例信息的初始化在请参考附录代码一clientConfig.getInstanceInfoReplicationIntervalSeconds(),该方法返回的是服务实例信息向Eureka Server同步的周期(默认30s),可以通过eureka.client.instance-info-replication-interval-seconds属性进行配置- 2为burstSize的值,控制任务处理的频率
(4) 通过调用instanceInfoReplicator.start()启动周期性任务,传入的参数为clientConfig.getInitialInstanceInfoReplicationIntervalSeconds(),该参数代表产自注册服务实例信息的延迟时间(默认40s),可以通过属性eureka.client.initial-instance-info-replication-interval-seconds配置,这也是为什么首次注册服务实例信息比较慢的原因
接下来进入InstanceInfoReplicator类中,分析其注册服务信息的过程,其构造函数为:
InstanceInfoReplicator(DiscoveryClient discoveryClient, InstanceInfo instanceInfo, int replicationIntervalSeconds, int burstSize) {
this.discoveryClient = discoveryClient;
this.instanceInfo = instanceInfo;
(5)this.scheduler = Executors.newScheduledThreadPool(1,
new ThreadFactoryBuilder()
.setNameFormat("DiscoveryClient-InstanceInfoReplicator-%d")
.setDaemon(true)
.build());
this.scheduledPeriodicRef = new AtomicReference<Future>();
this.started = new AtomicBoolean(false);
(6)this.rateLimiter = new RateLimiter(TimeUnit.MINUTES);
this.replicationIntervalSeconds = replicationIntervalSeconds;
this.burstSize = burstSize;
(7)this.allowedRatePerMinute = 60 * this.burstSize / this.replicationIntervalSeconds;
logger.info("InstanceInfoReplicator onDemand update allowed rate per min is {}", allowedRatePerMinute);
}(5) core size为1的线程池
(6) 工具类,用于限制单位时间内的任务次数
(7) 通过周期间隔,和burstSize参数,计算每分钟允许的任务数
步骤(4)中通过调用InstanceInfoReplicator类中的start方法启动任务,代码如下:
public void start(int initialDelayMs) {
(8)if (started.compareAndSet(false, true)) {
instanceInfo.setIsDirty(); // for initial register
(9)Future next = scheduler.schedule(this, initialDelayMs, TimeUnit.SECONDS);
(10)scheduledPeriodicRef.set(next);
}
}(8) CAS操作,保证start方法的逻辑只执行一次
(9) 提交一个延时执行任务,由于第一个参数是this,因此延时结束时会调用InstanceInfoReplicator中的run方法
(10) 将任务的Feature对象放在成员变量scheduledPeriodicRef中,方便后续在调用onDemandUpdate函数时取消任务
当延迟结束时,会调用InstanceInfoReplicator中的run方法,代码如下:
public void run() {
try {
(11)discoveryClient.refreshInstanceInfo();
Long dirtyTimestamp = instanceInfo.isDirtyWithTime();
(12)if (dirtyTimestamp != null) {
(13)discoveryClient.register();
instanceInfo.unsetIsDirty(dirtyTimestamp);
}
} catch (Throwable t) {
logger.warn("There was a problem with the instance info replicator", t);
} finally {
Future next = scheduler.schedule(this, replicationIntervalSeconds, TimeUnit.SECONDS);
scheduledPeriodicRef.set(next);
}
}(11) 更新服务实例信息
(12) 只有服务实例信息改变后才会真正执行服务注册操作,从而能够减少网络通信量
(13) 向Eureka Server注册服务
可以看到最终双调到了DiscoveryClient类的register()方法,代码如下:
/**
* Register with the eureka service by making the appropriate REST call.
*/
boolean register() throws Throwable {
logger.info(PREFIX + "{}: registering service...", appPathIdentifier);
EurekaHttpResponse<Void> httpResponse;
try {
(14)httpResponse = eurekaTransport.registrationClient.register(instanceInfo);
} catch (Exception e) {
logger.warn(PREFIX + "{} - registration failed {}", appPathIdentifier, e.getMessage(), e);
throw e;
}
if (logger.isInfoEnabled()) {
logger.info(PREFIX + "{} - registration status: {}", appPathIdentifier, httpResponse.getStatusCode());
}
return httpResponse.getStatusCode() == Status.NO_CONTENT.getStatusCode();
}(14) 可以看到最终是通过发送REST请求来注册服务实例信息
2. 服务注册的REST请求分析
上节讲到了最终调用DiscoveryClient的register()函数来注册服务,本节看一下register()是如何同Eureka Server进行通信的。
Eureka Client同Eureka Server通信的所有API都封装在接口EurekaHttpClient接口中,其中包含的API如下:
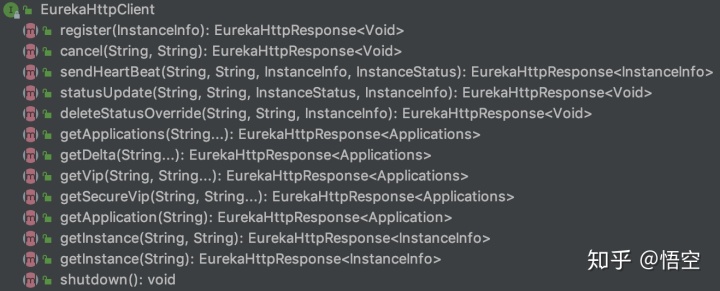
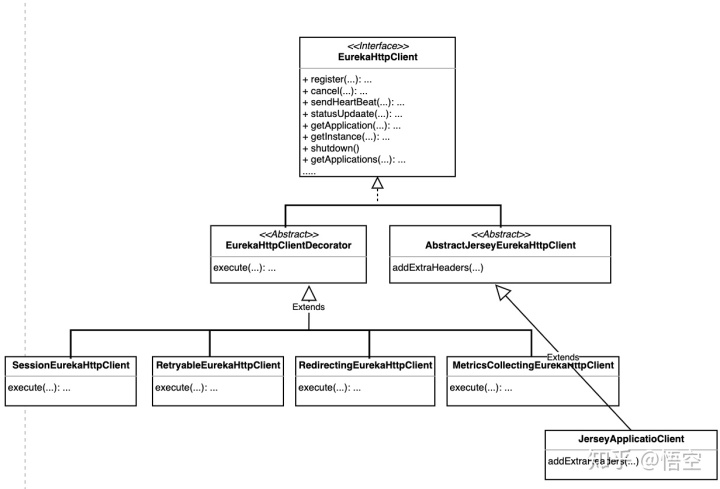
该接口的继承关系如下(请读者可自行分析):
register()调用时序图如下(请读者自行分析):
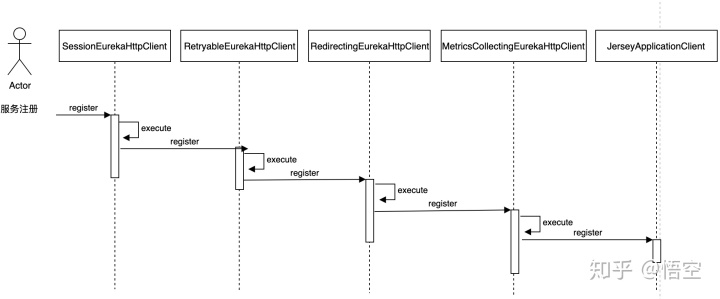
结合上面两幅图可知:
EurekaHttpClientDecorator采用的是装饰器模式设计注册的业务逻辑- 每个
EurekaHttpClientDecorator的实现类在execute函数中封装其特有的业务逻辑 - 最终调
JerseyApplicationClient实现真正的同Eureka Server通信
每个类的具体作用如下:
SessionEurekaHttpClient:维持与Eureka Server的会话,同时为了防止长时间占用一个Eureka Server和实现Eureka Server的负载均衡,会定期重连Eureka ServerRetryableEurekaHttpClient:当与某一个Eureka Server通信失败时,尝试与集群中的其他Eureka Server通信,默认尝试次数为3,不可在属性中配置。RetryableEurekaHttpClient会将失败的Eureka Server放入其quarantineSet集合中(该集合的大小超过阈值后会被清空)RedirectingEurekaHttpClient:处理Eureka Server重定向的业务逻辑MetricsCollectingEurekaClient:分类统计与Eureka Server通信的异常信息JerseyApplicationClient:完成与Eureka Server的通信
3. Eureka Client的Regin和Zone
在文章《微服务治理1 - Eureka服务治理架构及客户端装配和启动流程分析》中,我们看到Eureka Server服务治理架构中有区域亲和特性,即Eureka Client可以优先访问与其处于同一个区域的Eureka Server。通过这种特性,配合实际部署的物理结构,就可以设计出对区域性故障的容错集群。在Eureka Client中通过Regin和Zone两个概念来实现区域亲和特性。
使用Region和Zone的一般配置方式如下:
eureka:
client:
service-url:
test1: http://peer3.9003/erureka
test2: http://peer3.9003/erureka
region: test
availability-zones:
test: test1, test2eureka.client.service-url是Map类行,其中key为Zone,value为Eureka Server的地址,多个地址可以用逗号分割;eureka.client.region是String类型,代表当前Eureka Client的Region,eureka.client.availability-zones也是Map类型,其中key为Region,value为Zone,多个Zone用逗号分割。可以看到Region和Zone的关系是一对多。
上一节介绍了当与某一个Eureka Server通信失败时,RetryableEurekaHttpClient会尝试与集群中的其他Eureka Server通信,其中的关键代码为:
@Override
protected <R> EurekaHttpResponse<R> execute(RequestExecutor<R> requestExecutor) {
List<EurekaEndpoint> candidateHosts = null;
int endpointIdx = 0;
for (int retry = 0; retry < numberOfRetries; retry++) {
EurekaHttpClient currentHttpClient = delegate.get();
EurekaEndpoint currentEndpoint = null;
if (currentHttpClient == null) {
if (candidateHosts == null) {
(15)candidateHosts = getHostCandidates();
(16)currentEndpoint = candidateHosts.get(endpointIdx++);
currentHttpClient = clientFactory.newClient(currentEndpoint);
}
try {
EurekaHttpResponse<R> response = requestExecutor.execute(currentHttpClient);
} catch (Exception e) {
}
}
}(15) 获得当前所有可用的Eureka Server
(16) 获得下一个将要通信的Eureka Server
这里的关键是步骤(15)中通过getHostCandidates()获得所有Eureka Server,其通过调用AsyncResolver类中的getClusterEndpoints()获得配置的所有Eureka Server信息,而AsyncResolver类的初始化则在EurekaHttpClients类中完成,代码如下:
static ClosableResolver<AwsEndpoint> defaultBootstrapResolver(final EurekaClientConfig clientConfig, final InstanceInfo myInstanceInfo, final EndpointRandomizer randomizer) {
(17)String[] availZones = clientConfig.getAvailabilityZones(clientConfig.getRegion());
(18)String myZone = InstanceInfo.getZone(availZones, myInstanceInfo);
(19)ClusterResolver<AwsEndpoint> delegateResolver = new ZoneAffinityClusterResolver(
new ConfigClusterResolver(clientConfig, myInstanceInfo),
myZone,
true,
randomizer
);
(20)List<AwsEndpoint> initialValue = delegateResolver.getClusterEndpoints();
if (initialValue.isEmpty()) {
String msg = "Initial resolution of Eureka server endpoints failed. Check ConfigClusterResolver logs for more info";
logger.error(msg);
failFastOnInitCheck(clientConfig, msg);
}
(21)return new AsyncResolver<>(
EurekaClientNames.BOOTSTRAP,
delegateResolver,
initialValue,
1,
clientConfig.getEurekaServiceUrlPollIntervalSeconds() * 1000
);
}(17) 根据Region获得配置的可用Zone,代码如下:
@Override
public String[] getAvailabilityZones(String region) {
String value = this.availabilityZones.get(region);
if (value == null) {
//默认Zone为defaultZone,即通过eureka.client.service-url.defaultZone配置的值
value = DEFAULT_ZONE;
}
return value.split(",");
}如果使用本节开始介绍的一般配置,该步骤将获得test1, test2
(18) 获取服务实例所在的Zone,默认返回步骤(17)中获得的第一个Zone
(19) 初始化ZoneAffinityClusterResolver类
(20) 获得配置的Eureka Server集群节点,这个方法是最关键的方法,其代码如下:
@Override
public List<AwsEndpoint> getClusterEndpoints() {
//获得配置的Eureka Server集群节点
List<AwsEndpoint>[] parts = ResolverUtils.splitByZone(delegate.getClusterEndpoints(), myZone);
List<AwsEndpoint> myZoneEndpoints = parts[0];
List<AwsEndpoint> remainingEndpoints = parts[1];
List<AwsEndpoint> randomizedList = randomizeAndMerge(myZoneEndpoints, remainingEndpoints);
if (!zoneAffinity) {
Collections.reverse(randomizedList);
}
logger.debug("Local zone={}; resolved to: {}", myZone, randomizedList);
//返回随机化后的Eureka Server集群节点信息
return randomizedList;
}其中delegate.getClusterEndpoints()函数最调用的是ConfigClusterResolver类中的getClusterEndpointsFromConfig()函数,后者又调用EndpointUtils类中的getServiceUrlsMapFromConfig函数以获得配置的Eureka Server集群节点信息。
(21) 初始化AsyncResolver类
以上就是Region和Zone配置信息初始化及生效的代码分析过程。
附录
代码一
该附录分析一下本文步骤(3)中的instanceInfo实例的初始化过程。instanceInfo是类InstanceInfo类的实例,InstanceInfo即代表向Eureka Server注册的服务实例信息,同时也是服务消费者从Eureka Server获取的服务实例信息,比如应用名、ip地址、端口、homePageUrl、healthCheckUrl、statusPageUrl、securePort等。在DiscoveryClient实例中instanceInfo通过ApplicationInfoManager实例初始化,而后者的实例为EurekaClientAutoConfiguration类中向Spring容器注入的bean(可以看下CloudEurekaClient的初始化过程),代码如下:
@Bean
@ConditionalOnMissingBean(value = ApplicationInfoManager.class,
search = SearchStrategy.CURRENT)
public ApplicationInfoManager eurekaApplicationInfoManager(
EurekaInstanceConfig config) {
(1)InstanceInfo instanceInfo = new InstanceInfoFactory().create(config);
return new ApplicationInfoManager(config, instanceInfo);
}(1) 通过工厂方法创建InstanceInfo实例,需要用到注入的EurekaInstanceConfig实例,其同样是在EurekaClientAutoConfiguration类中初始化的,代码如下:
@Bean
@ConditionalOnMissingBean(value = EurekaInstanceConfig.class,
search = SearchStrategy.CURRENT)
public EurekaInstanceConfigBean eurekaInstanceConfigBean(InetUtils inetUtils,
ManagementMetadataProvider managementMetadataProvider) {
String hostname = getProperty("eureka.instance.hostname");
boolean preferIpAddress = Boolean
.parseBoolean(getProperty("eureka.instance.prefer-ip-address"));
String ipAddress = getProperty("eureka.instance.ip-address");
boolean isSecurePortEnabled = Boolean
.parseBoolean(getProperty("eureka.instance.secure-port-enabled"));
String serverContextPath = env.getProperty("server.servlet.context-path", "/");
int serverPort = Integer.parseInt(
env.getProperty("server.port", env.getProperty("port", "8080")));
Integer managementPort = env.getProperty("management.server.port", Integer.class);
String managementContextPath = env
.getProperty("management.server.servlet.context-path");
Integer jmxPort = env.getProperty("com.sun.management.jmxremote.port",
Integer.class);
EurekaInstanceConfigBean instance = new EurekaInstanceConfigBean(inetUtils);
instance.setNonSecurePort(serverPort);
instance.setInstanceId(getDefaultInstanceId(env));
instance.setPreferIpAddress(preferIpAddress);
instance.setSecurePortEnabled(isSecurePortEnabled);
if (StringUtils.hasText(ipAddress)) {
instance.setIpAddress(ipAddress);
}
if (isSecurePortEnabled) {
instance.setSecurePort(serverPort);
}
if (StringUtils.hasText(hostname)) {
instance.setHostname(hostname);
}
String statusPageUrlPath = getProperty("eureka.instance.status-page-url-path");
String healthCheckUrlPath = getProperty("eureka.instance.health-check-url-path");
if (StringUtils.hasText(statusPageUrlPath)) {
instance.setStatusPageUrlPath(statusPageUrlPath);
}
if (StringUtils.hasText(healthCheckUrlPath)) {
instance.setHealthCheckUrlPath(healthCheckUrlPath);
}
ManagementMetadata metadata = managementMetadataProvider.get(instance, serverPort,
serverContextPath, managementContextPath, managementPort);
if (metadata != null) {
instance.setStatusPageUrl(metadata.getStatusPageUrl());
instance.setHealthCheckUrl(metadata.getHealthCheckUrl());
if (instance.isSecurePortEnabled()) {
instance.setSecureHealthCheckUrl(metadata.getSecureHealthCheckUrl());
}
Map<String, String> metadataMap = instance.getMetadataMap();
metadataMap.computeIfAbsent("management.port",
k -> String.valueOf(metadata.getManagementPort()));
}
else {
// without the metadata the status and health check URLs will not be set
// and the status page and health check url paths will not include the
// context path so set them here
if (StringUtils.hasText(managementContextPath)) {
instance.setHealthCheckUrlPath(
managementContextPath + instance.getHealthCheckUrlPath());
instance.setStatusPageUrlPath(
managementContextPath + instance.getStatusPageUrlPath());
}
}
setupJmxPort(instance, jmxPort);
return instance;
}可以看到我们在配置文件中设置的很多属性最终都会在这里生效。
Github博客地址
CSDN
最后
以上就是伶俐墨镜最近收集整理的关于ajax请求是宏任务还是微任务_微服务治理2 - Eureka服务注册的全部内容,更多相关ajax请求是宏任务还是微任务_微服务治理2内容请搜索靠谱客的其他文章。








发表评论 取消回复