Eureka生产优化
Eureka生产优化核心就是优化服务注册、上下线的速度,减少服务上下线的延时
eureka的优化之前需要了解原理,通过debug发现待优化的点
原理概述
-
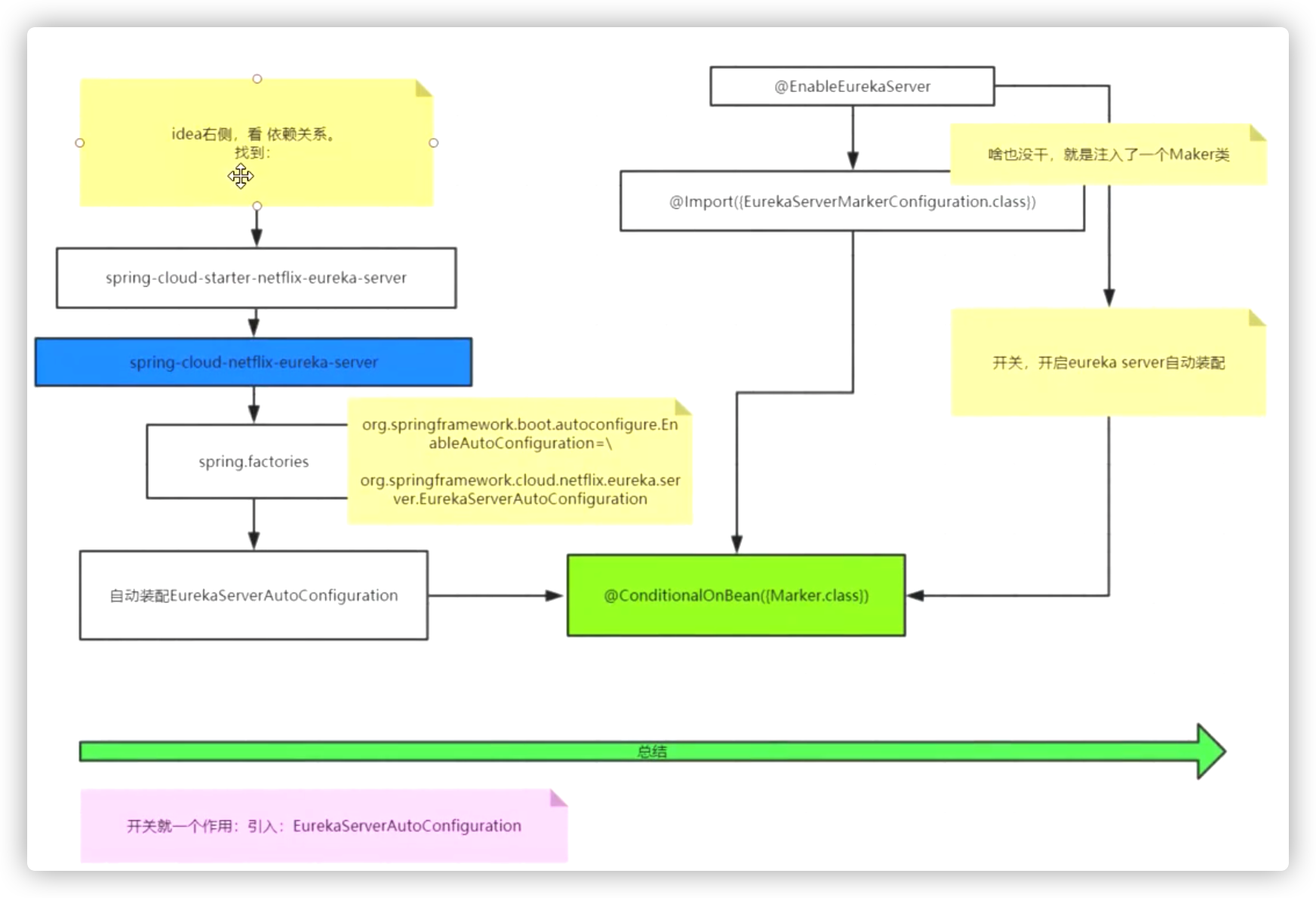
进入EurekaServer的依赖中发现通过配置文件spring.factories将EurekaServerAutoConfiguration注入进来

-
我们的启动类上又有个@EnableEurekaServer
-
进入这个注解中发现又导入了EurekaServerMarkerConfiguration
-
在EurekaServerMarkerConfiguration类中注入了一个Marker空类
@Configuration(proxyBeanMethods = false) public class EurekaServerMarkerConfiguration { @Bean public Marker eurekaServerMarkerBean() { return new Marker(); // 注入了一个空类 } class Marker { } } -
通过
@ConditionalOnBean(EurekaServerMarkerConfiguration.Marker.class)发现,容器中有了这个Marker类才能将EurekaServerAutoConfiguration类注入到容器中,这个Marker类(空类)就是起到一个开关的作用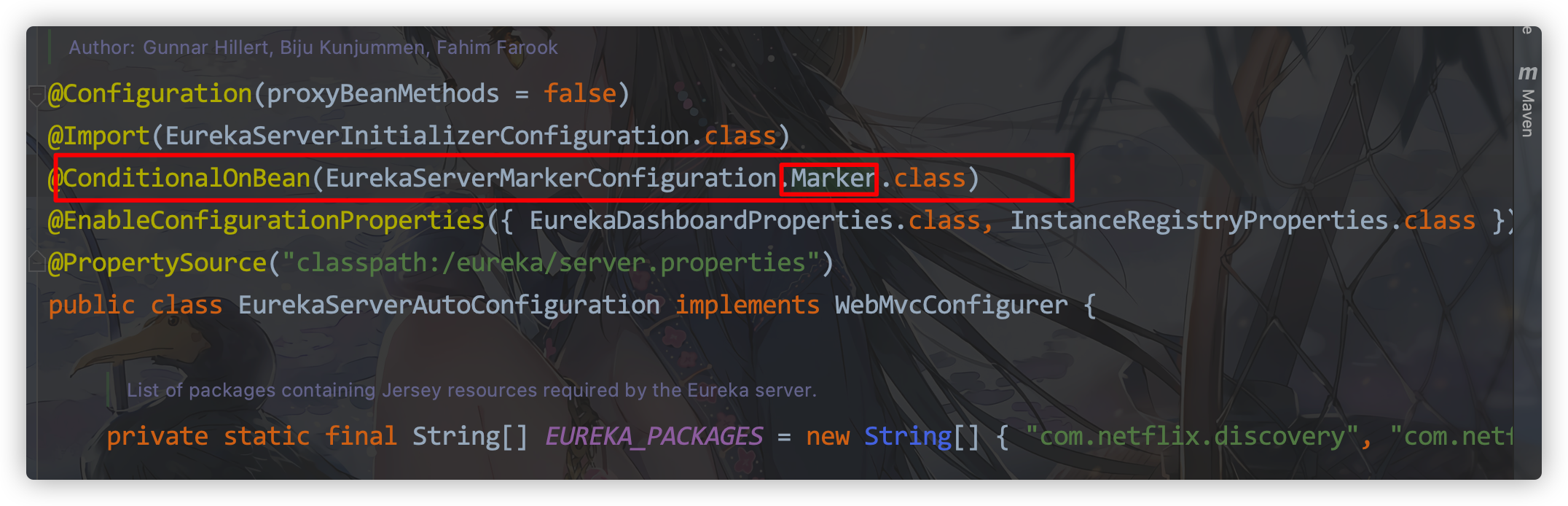
结构图:
Eureka的自我保护
假设如果总共有1000个服务 ,此时有3个服务因为网络抖动导致Eureka-Server收不到心跳,这会是非常正常的现象,但是我们的Eureka不能因为网络抖动把这三个收不到心跳的服务踢掉 。
但是如果不开启自我保护机制这三个就会踢掉了。
什么时候开自我保护什么时候不开呢?
服务多的时候开启自我保护,服务少的不开启。
因为服务多的时候,超过15%没收到心跳,网络问题可能性更大。但是服务少超过15%没心跳,服务挂的可能性更大,如果把挂掉的服务保护起来,就会给客户端返回错
一些配置信息
**客户端心跳发送时间间隔(eureka.instance.lease-renewal-interval-in-seconds):**默认30s
客户端服务续约时间(eureka.instance.lease-expiration-duration-in-seconds): 默认90s。当客户端最后一次发送心跳后,在该服务续约时间内如果没有再向服务端发送心跳链接,则服务器端可以对该服务进行剔除操作。 (客户端配置)
**服务端的服务剔除时间间隔(eureka.server.eviction-interval-timer-in-ms):**默认60 * 1000(60s )。在server服务端会定期的将没有心跳的服务剔除。 (服务端配置)
阈值更新时间间隔(renewalPercentThreshold) : eureka-server此次单位时间内收到的心跳总数 / 上次单位时间内收到的心跳总数(系统默认配置的因子值为0.85)的间隔时间,默认为15分钟。
获取注册信息的时间间隔(eureka.client.registry-fetchI-interval-seconds ): 从eureka服务器注册表中获取注册信息的时间间隔(s),默认为30秒
什么时候开启自我保护机制:Eureka Server有个阈值,当此次单位时间内收到的心跳总数 / 上次单位时间内收到的心跳总数小于阈值,就会触发自我保护机制,Eureka就认为本台EurekaServer节点可能网络出现故障,当做自身问题处理,不会去剔除客户端服务信息。(当然也存在可能真的是Eureka客户端服务节点真的都挂了,调用将会出现失败情况)
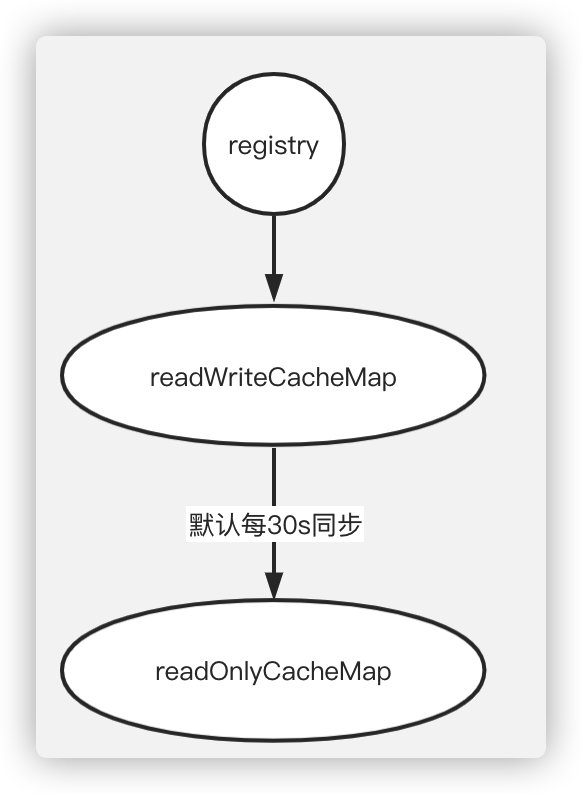
三级缓存
Eureka Server 存在三个变量:registry、readWriteCacheMap、readOnlyCacheMap 保存服务注册信息。
public abstract class AbstractInstanceRegistry implements InstanceRegistry {
// 一级缓存registry注册表
private final ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>> registry
= new ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>>();
}
public class ResponseCacheImpl implements ResponseCache {
// 三级缓存readOnlyCacheMap
private final ConcurrentMap<Key, Value> readOnlyCacheMap = new ConcurrentHashMap<Key, Value>();
// 二级缓存readWriteCacheMap
private final LoadingCache<Key, Value> readWriteCacheMap;
}
三级缓存工作流程
默认情况下定时任务每 30s 将 readWriteCacheMap 同步至 readOnlyCacheMap,每 60s 清理超过 90s 未续约的节点,Eureka Client 每 30s 从 readOnlyCacheMap 拉取服务注册信息,而服务的注册则在 registry 更新信息。
源码如下(ResponseCacheImpl类)
// 这是个定时任务
private TimerTask getCacheUpdateTask() {
return new TimerTask() {
@Override
public void run() {
logger.debug("Updating the client cache from response cache");
for (Key key : readOnlyCacheMap.keySet()) {
if (logger.isDebugEnabled()) {
logger.debug("Updating the client cache from response cache for key : {} {} {} {}",
key.getEntityType(), key.getName(), key.getVersion(), key.getType());
}
try {
CurrentRequestVersion.set(key.getVersion());
Value cacheValue = readWriteCacheMap.get(key); // 从二级缓存里拉取信息
Value currentCacheValue = readOnlyCacheMap.get(key); // 从三级缓存里拉取信息
if (cacheValue != currentCacheValue) { // 如果信息不同将信息同步一下
readOnlyCacheMap.put(key, cacheValue);
}
} catch (Throwable th) {
logger.error("Error while updating the client cache from response cache for key {}", key.toStringCompact(), th);
} finally {
CurrentRequestVersion.remove();
}
}
}
};
}
// 这段代码是每隔一段时间调用上面那个二三级缓存同步的定时任务
if (shouldUseReadOnlyResponseCache) {
timer.schedule(getCacheUpdateTask(),
new Date(((System.currentTimeMillis() / responseCacheUpdateIntervalMs) * responseCacheUpdateIntervalMs)
+ responseCacheUpdateIntervalMs),
responseCacheUpdateIntervalMs);
}
三级缓存的优点
保证了对EurekaServer的大量请求,都是快速从内存中取,提高性能的同时保证了注册表中的数据不会出现读写冲突。
eureka.server.use-read-only-response-cache # 是否使用多级缓存
Eureka的CAP
Eureka同步注册表的流程
每 30s 从二级缓存向三级缓存同步数据
- 二级缓存有效
- 从二级缓存向三级缓存同步数据
- 二级缓存失效
- 触发二级缓存的同步(从registry注册表中拉取数据)
在哪些地方没实现一致性?也就是CAP中的C。
-
ReadOnlyCacheMap和ReadWriteCacheMap之间的数据同步
由于我们取获取服务时,默认从readOnlyCacheMap中读取,由于readWriteCacheMap每隔30s才同步到readOnlyCacheMap,数据不是强一致性的,所以这是Eureka只实现了AP,没有实现C的原因。
-
从其他节点获取注册表,所以不保证节点间的状态一定是强一致,只能保证最终一致
-
集群同步,集群并没有扩大Eureka并没有扩大它的承受能力,只是实现了可用性。
在什么情况下会同步数据?我们从以下几个节点分析。- 注册:第一个节点注册进来,只同步下一个节点。
- 续约:有新服务续约,自动同步到其他Eureka-Server。
- 下线:一直同步所有集群。
- 剔除:不同步,每个Server都有自己的剔除机制。
服务测算
怎样测算出Eureka的并发量
比如有100个服务,每个服务部署20个实例。就是2000个实例。
每台机器上的服务实例内部都有一个Eureka Client组件,它会每隔30秒请求一次Eureka Server,拉取变化的注册表。
那么这个Eureka Server作为一个微服务注册中心,每秒钟要被请求多少次?一天要被请求多少次?
此外,每个服务实例上的Eureka Client都会每隔30秒发送一次心跳请求给Eureka Server。
一个实例默认30秒发一次心跳,30秒拉取一次注册表。那Service每分钟接收到的请求量就是。2000 * 2 * 2 = 8000次。那一天能承受的量就是 8000 * 60 * 24 = 1152w次请求,每天1000多万的访问量。
换算到每秒,则是8000 / 60 = 133次左右,大概估算为Eureka Server每秒会被请求150次
所以通过设置一个适当的拉取注册表以及发送心跳的频率,可以保证大规模系统里对Eureka Server的请求压力不会太大。
定时器Timer的优化
Eureka源码用了大量的Timer定时任务,由于Timer定时器存在以下缺陷:
Timer的缺陷:
Timer在执行所有定时任务时只会创建一个线程,当存在多个任务时,其任务是串行执行的。由于Timer只会创建一个线程,那么在TimerTask抛出了一个未检出的异常,那么Timer线程就会被终止掉,导致其它任务都停止。Timer执行周期任务时依赖系统时间,如果当前系统时间发生变化会出现一些执行上的变化。
建议使用ScheduledExecutorService
但是它是基于源码层面的,我们无法进行修改
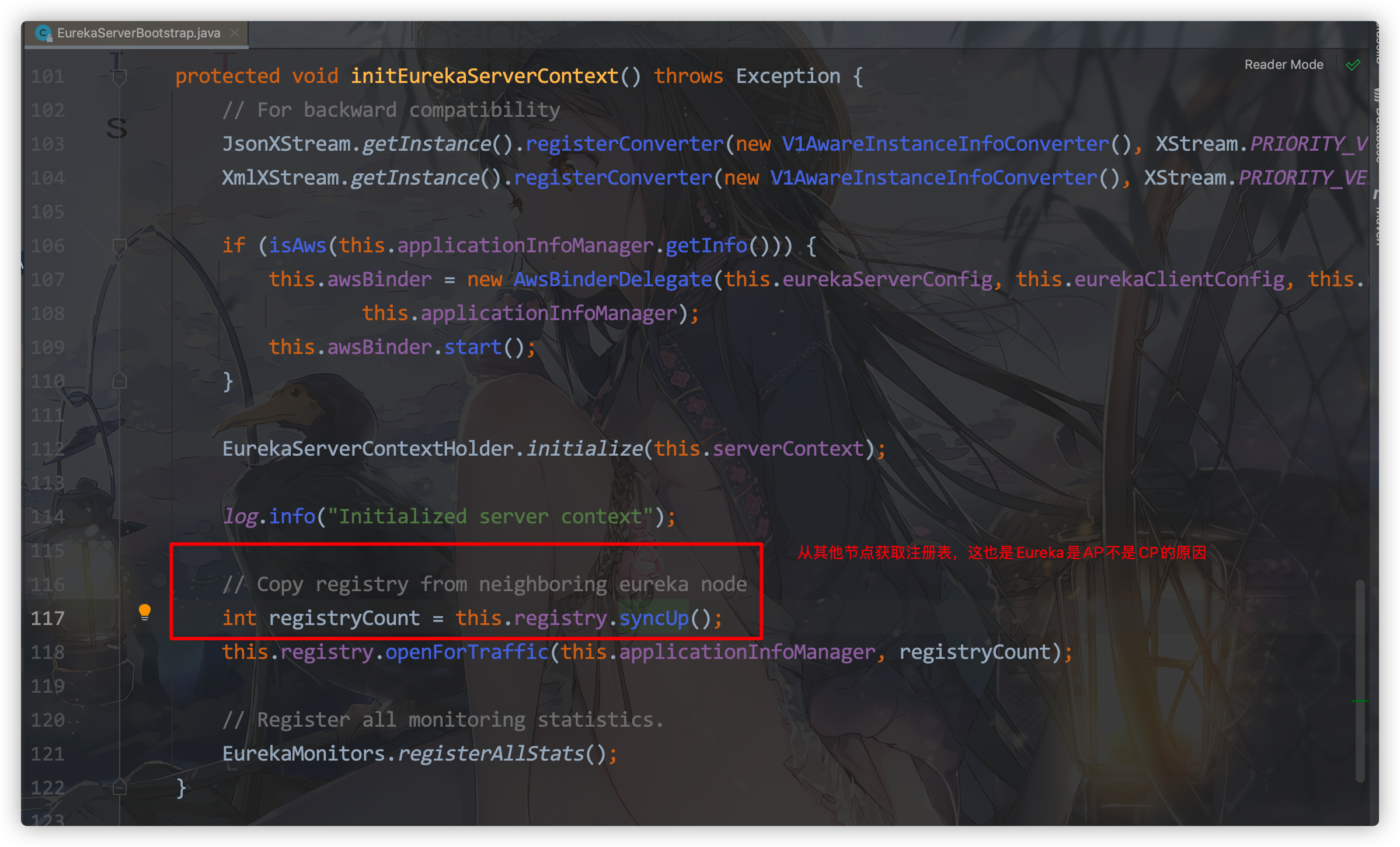
Eureka注册的原理
- 发起注册,先注册到registry中
- 找readOnlyCacheMap —没有—> readWriteCacheMap —没有—> registry
- 拉取注册表到服务中
- 新部署了一个服务,注册到了registry中
- registry发生变化,过期readWriteCacheMap
- 自动同步两个readWriteCacheMap到readOnlyCacheMap
Eureka服务优化点
1、Eureka服务的快速下线
Eureka Server在启动时会创建一个定时任务,每隔一段时间(默认60秒),从当前服务清单中把超时没有续约(默认90秒)的服务剔除。我们可以把服务剔除这个定时任务间隔的时间设置得短一点,做到快速下线。防止拉取到不可用的服务。
eureka:
server:
eviction-interval-timer-in-ms: 1000 //比如1s
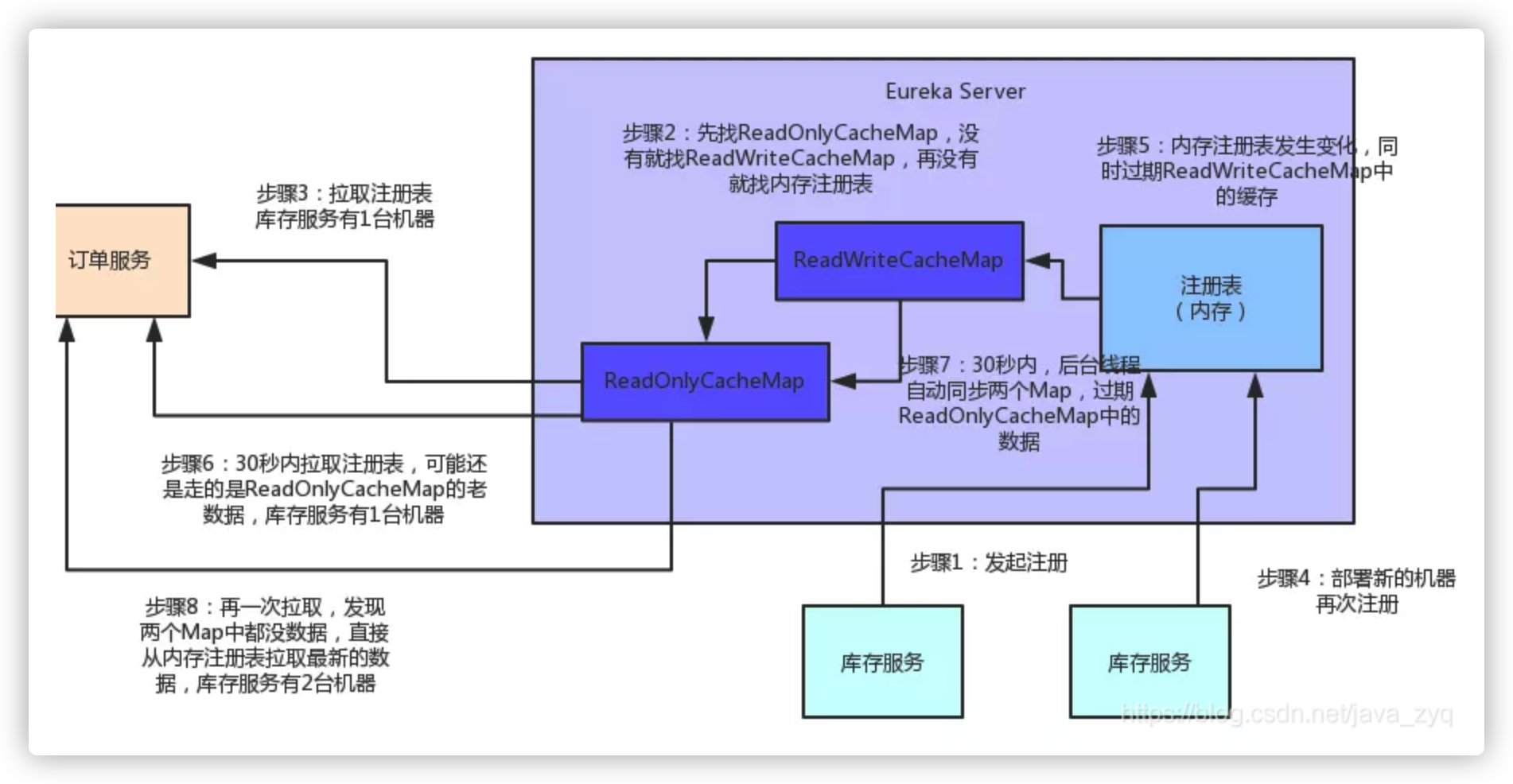
2、缓存优化
Eureka Server为了避免同时读写内存数据结构造成的并发冲突问题,采用了3级缓存机制来进一步提升服务请求的响应速度。
拉取注册表的步骤是:
-
首先从ReadOnlyCacheMap里查缓存的注册表。
-
若没有,就找ReadWriteCacheMap里缓存的注册表。
-
如果还没有,就从内存中registry中获取实际的注册表数据。
当新的服务注册,先更新注册表registry中的数据和ReadWriteCacheMap里缓存的数据,默认30s后把ReadWriteCacheMap里面的数据更新到ReadOnlyCacheMap。
为了提高服务被发现的速度。我们可以做一些设置。
拉取服务的时候,不从ReadOnlyCacheMap里查,直接从ReadWriteCacheMap取。
eureka:
server:
use-read-only-response-cache: false # 关闭从ReadOnlyCacheMap拉取数据。
- 缩短ReadWriteCacheMap向ReadOnlyCacheMap同步的时间间隔,默认30秒,我们可以优化到1秒,这个根据自己的情况而定。
eureka:
server:
response-cache-update-interval-ms: 1000 # 减少readWrite 和 readOnly 同步时间间隔。
3、客户端拉取注册表更及时
客户端会定时到eureka-server拉取注册表。默认情况下每30秒拉取一次。可以根据实际情况设置拉取时间间隔。
eureka:
client:
fetch-registry: true
registry-fetch-interval-seconds: 3 # 拉取注册表信息间隔时间
4、url顺序的打乱
我们在生产中配置eureka.client.service-url.defaultZone的时候,各个client端的配置尽量要随机一下,即打乱一下defaultZone中url的顺序。
原因:
-
在拉取注册表的时候,默认从第一个url开始拉取,拉取不到才从下一个拉取,并且最多只能拉取3个
-
在注册的时候,只会注册到第一个url,然后同步到后面的url,所以我们打乱了顺序以后,就减少了对某一个server的依赖,也降低了对某一个server的请求次数。
5、client心跳频率
默认情况下,client每隔30秒就会向服务端发送一次心跳。这个时间也可以适当调小一点。
eureka:
instance:
lease-renewal-interval-in-seconds: 30 # 每间隔30s,向服务端发送一次心跳。
6、服务端剔除客户端的时间间隔
默认情况下,server在90s之内没有收到client心跳,将服务踢出掉。为了让服务快速响应,可以适当地把这个时间改的小一点。
eureka:
instance:
lease-expiration-duration-in-seconds: 90
https://blog.csdn.net/weixin_39665762/article/details/112183496
Eureka的优雅下线和重启服务
方式1:直接关闭服务
简单粗暴,如果直接kill -9 Springcloud服务端口号,服务不会立即剔除,还会在注册表中,等待server在默认90s之内没有收到client心跳进行剔除,那么就会期间导致服务还能调用,但是会报错。
解决办法:
- 调用方要有重试策略:比如使用Feign作为客户端调用接口 可以配置ribbon的重试策略
- 被调用方要有幂等策略:防止重试调用时出现重复数据的问题。
方式2:调用eurekaClient.shutdown()
调用此方法删除registry中的注册表,但是服务拉取的时候默认走的第三级缓存(ReadOnlyCacheMap),在定时任务同步registry之前这段时间服务依然会正常调用
此方法只能将服务下线,无法将服务上线
方式3:使用actuator
/actuator/service-registry 可以以Get请求的方式获取当前服务的状态,以Post请求的方式修改当前服务状态,如将服务设置为Down状态,这样其他微服务接收到此状态后将不调用此服务。
将服务状态设置为DOWN:
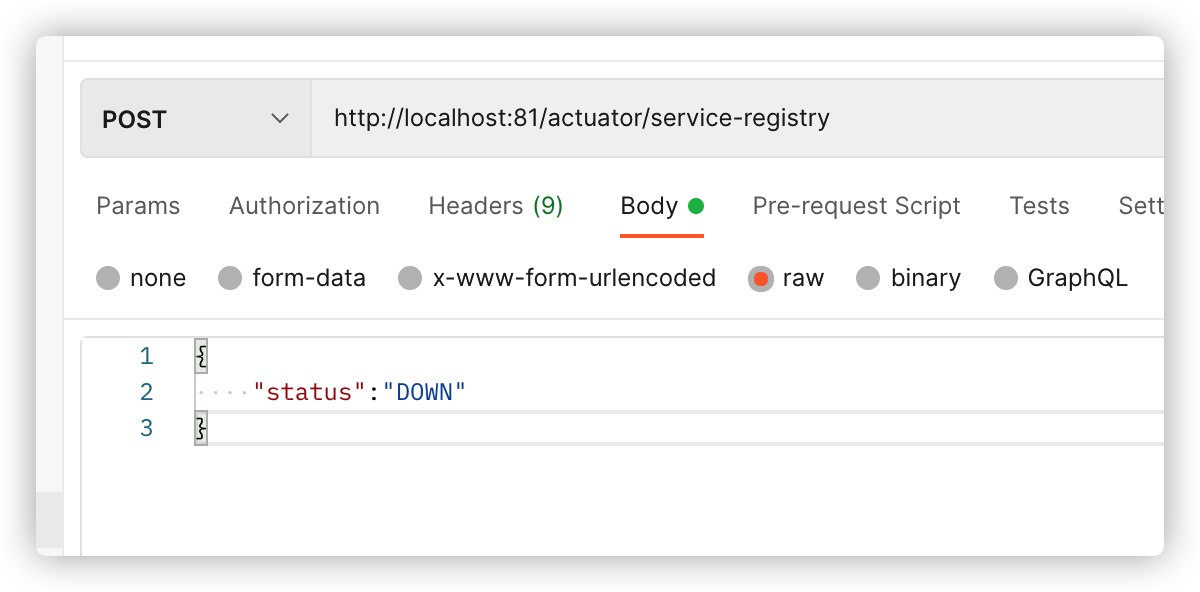
将服务状态设置为UP
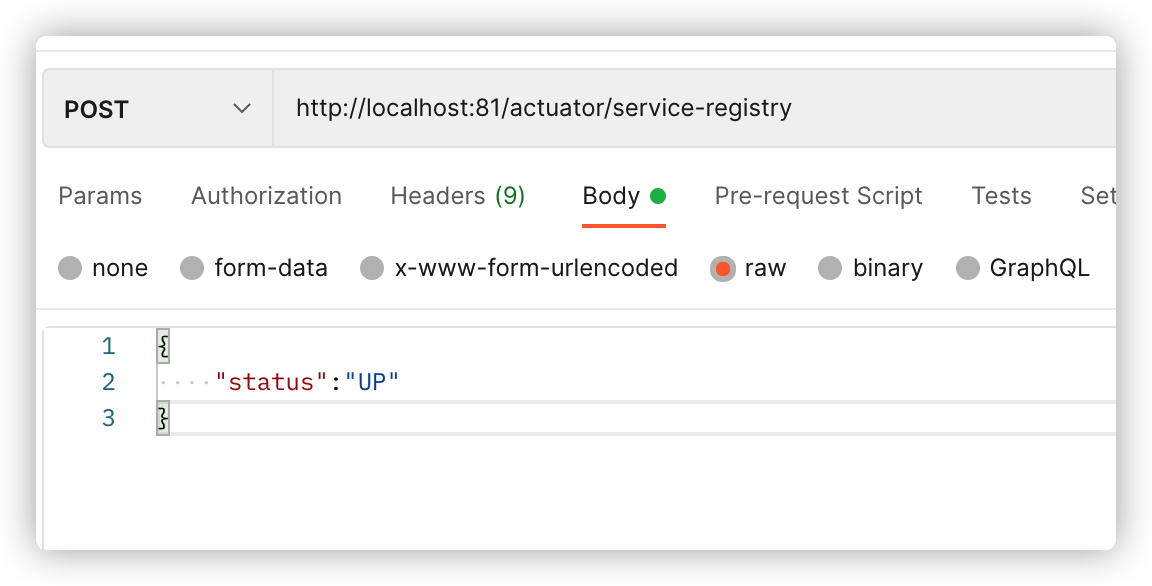
这样一个服务的上线和下线就优雅的完成了
总结
以上三种方式都可以实现微服的下线,第三种方式最为优雅,可以主动下线和上线
最后
以上就是整齐秋天最近收集整理的关于Eureka的三级缓存以及生产优化Eureka生产优化的全部内容,更多相关Eureka内容请搜索靠谱客的其他文章。








发表评论 取消回复