前面的文章中,已经简单介绍了Spring Cloud Eureka的用法,下面再说明下详细的功能和源码。
Spring Cloud Eureka分为Server端和Client端,Server端作为应用的注册中心,Client端会向Server端注册自己的服务。
Eureka Server和Eureka Client都是采用Java编写的,所以,Eureka主要适用于通过Java实现的分布式系统,但是Eureka Server的服务治理机制提供了完备的RESTful API,所以它也支持将非Java语言构建的微服务应用纳入Eureka的服务治理体系中来。只不过其他语言在接入Eureka的时候,需要自己来实现Eureka Client,调用Eureka Server提供的API来进行服务注册、服务续约、服务下线等操作。目前也已经有了一些针对非Java语言实现的Eureka Client框架,比如.Net平台的Steeltoe、Node.js的Eureka-js-client等。
Eureka的一些概念:
在Eureka的服务治理中,会涉及到下面一些概念:
服务注册:Eureka Client会通过发送REST请求的方式向Eureka Server注册自己的服务,提供自身的元数据,比如ip地址、端口、运行状况指标的url、主页地址等信息。Eureka Server接收到注册请求后,就会把这些元数据信息存储在一个双层的Map中。
服务续约:在服务注册后,Eureka Client会维护一个心跳来持续通知Eureka Server,说明服务一直处于可用状态,防止被剔除。Eureka Client在默认的情况下会每隔30秒发送一次心跳来进行服务续约。
服务同步:Eureka Server之间会互相进行注册,构建Eureka Server集群,不同Eureka Server之间会进行服务同步,用来保证服务信息的一致性。
获取服务:服务消费者(Eureka Client)在启动的时候,会发送一个REST请求给Eureka Server,获取上面注册的服务清单,并且缓存在Eureka Client本地,默认缓存30秒。同时,为了性能考虑,Eureka Server也会维护一份只读的服务清单缓存,该缓存每隔30秒更新一次。
服务调用:服务消费者在获取到服务清单后,就可以根据清单中的服务列表信息,查找到其他服务的地址,从而进行远程调用。Eureka有Region和Zone的概念,一个Region可以包含多个Zone,在进行服务调用时,优先访问处于同一个Zone中的服务提供者。
服务下线:当Eureka Client需要关闭或重启时,就不希望在这个时间段内再有请求进来,所以,就需要提前先发送REST请求给Eureka Server,告诉Eureka Server自己要下线了,Eureka Server在收到请求后,就会把该服务状态置为下线(DOWN),并把该下线事件传播出去。
服务剔除:有时候,服务实例可能会因为网络故障等原因导致不能提供服务,而此时该实例也没有发送请求给Eureka Server来进行服务下线,所以,还需要有服务剔除的机制。Eureka Server在启动的时候会创建一个定时任务,每隔一段时间(默认60秒),从当前服务清单中把超时没有续约(默认90秒)的服务剔除。
自我保护:既然Eureka Server会定时剔除超时没有续约的服务,那就有可能出现一种场景,网络一段时间内发生了异常,所有的服务都没能够进行续约,Eureka Server就把所有的服务都剔除了,这样显然不太合理。所以,就有了自我保护机制,当短时间内,统计续约失败的比例,如果达到一定阈值,则会触发自我保护的机制,在该机制下,Eureka Server不会剔除任何的微服务,等到正常后,再退出自我保护机制。
从这些概念中,就可以知道大体的流程,Eureka Client向Eureka Server注册,并且维护心跳来进行续约,如果长时间不续约,就会被剔除。Eureka Server之间进行数据同步来形成集群,Eureka Client从Eureka Server获取服务列表,用来进行服务调用,Eureka Client服务重启前调用Eureka Server的接口进行下线操作。
源码分析:
Eureka Client源码:
先从服务注册开始梳理,Eureka Client启动的时候就去Eureka Server注册服务。通过在启动类上添加@EnableDiscoveryClient这个注解,来声明这是一个Eureka Client。所以,先看下这个注解:
/**
* Annotation to enable a DiscoveryClient implementation.
* @author Spencer Gibb
*/
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@Import(EnableDiscoveryClientImportSelector.class)
public @interface EnableDiscoveryClient {
}这个注解上方有注释,说这个注解是为了开启一个DiscoveryClient的实例。
接下来就可以搜索DiscoveryClient,可以发现有一个类,还有一个接口,查看这个类的关系图:
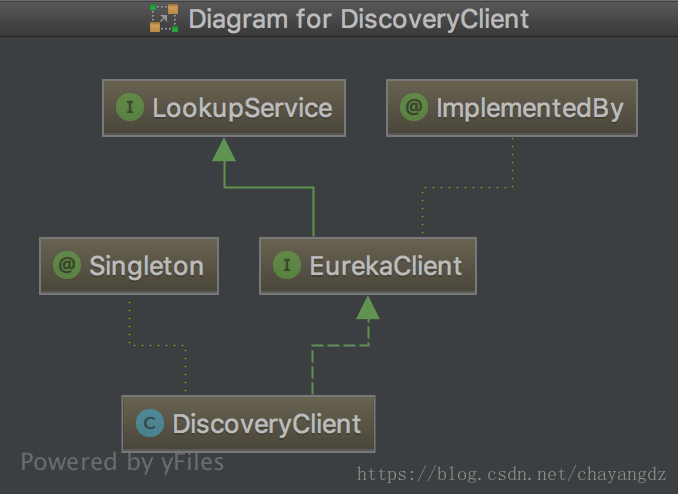
这个类实现了EurekaClient接口,而EurekaClient又继承了LookupService接口。这两个接口都是Netflix开源包中的内容,主要定义了针对Eureka发现服务的抽象方法。所以,DiscoveryClient类主要就是发现服务的。
接下来,就详细看下DiscoveryClient类,类上面的注释,说明了这个类是用来帮助和Eureka Server互相协作的,可以进行服务注册,服务续约,服务下线,获取服务列表。需要配置一个Eureka Server的Url列表。
上面提到的这个列表,就是我们在配置文件中配置的eureka.client.service-url.defaultZone这一选项,这个地址就是Eureka Server的地址,服务注册、服务续约以及其他的操作,都是向这个地址发送请求的。
在DiscoveryClient类中可以看到有很多方法,包括register()、renew()、shutdown()、unregister()等。
既然Eureka Client需要一开始先初始化DiscoveryClient实例,那就看下DiscoveryClient的构造方法。
DiscoveryClient的构造方法还是挺长的,里面初始化了一大堆的对象,不过可以观察到在new了这么一大堆对象之后,调用了initScheduledTasks();这个方法,所以,点进initScheduledTasks()方法里面看下。
/**
* Initializes all scheduled tasks.
*/
private void initScheduledTasks() {
if (clientConfig.shouldFetchRegistry()) {
// registry cache refresh timer
int registryFetchIntervalSeconds = clientConfig.getRegistryFetchIntervalSeconds();
int expBackOffBound = clientConfig.getCacheRefreshExecutorExponentialBackOffBound();
scheduler.schedule(
new TimedSupervisorTask(
"cacheRefresh",
scheduler,
cacheRefreshExecutor,
registryFetchIntervalSeconds,
TimeUnit.SECONDS,
expBackOffBound,
new CacheRefreshThread()
),
registryFetchIntervalSeconds, TimeUnit.SECONDS);
}
if (clientConfig.shouldRegisterWithEureka()) {
int renewalIntervalInSecs = instanceInfo.getLeaseInfo().getRenewalIntervalInSecs();
int expBackOffBound = clientConfig.getHeartbeatExecutorExponentialBackOffBound();
logger.info("Starting heartbeat executor: " + "renew interval is: " + renewalIntervalInSecs);
// Heartbeat timer
scheduler.schedule(
new TimedSupervisorTask(
"heartbeat",
scheduler,
heartbeatExecutor,
renewalIntervalInSecs,
TimeUnit.SECONDS,
expBackOffBound,
new HeartbeatThread()
),
renewalIntervalInSecs, TimeUnit.SECONDS);
// InstanceInfo replicator
instanceInfoReplicator = new InstanceInfoReplicator(
this,
instanceInfo,
clientConfig.getInstanceInfoReplicationIntervalSeconds(),
2); // burstSize
statusChangeListener = new ApplicationInfoManager.StatusChangeListener() {
@Override
public String getId() {
return "statusChangeListener";
}
@Override
public void notify(StatusChangeEvent statusChangeEvent) {
if (InstanceStatus.DOWN == statusChangeEvent.getStatus() ||
InstanceStatus.DOWN == statusChangeEvent.getPreviousStatus()) {
// log at warn level if DOWN was involved
logger.warn("Saw local status change event {}", statusChangeEvent);
} else {
logger.info("Saw local status change event {}", statusChangeEvent);
}
instanceInfoReplicator.onDemandUpdate();
}
};
if (clientConfig.shouldOnDemandUpdateStatusChange()) {
applicationInfoManager.registerStatusChangeListener(statusChangeListener);
}
instanceInfoReplicator.start(clientConfig.getInitialInstanceInfoReplicationIntervalSeconds());
} else {
logger.info("Not registering with Eureka server per configuration");
}
}在initScheduledTasks方法中,初始化了几个任务。
一开始有个if判断,判断是否需要从Eureka Server获取数据,如果为真,则初始化一个服务获取的定时任务。
还有有个if (clientConfig.shouldRegisterWithEureka())的判断,所以,当Eureka Client配置这个为true时,就会执行这个if语句里面的逻辑。if语句中,会初始化一个Heartbeat timer和InstanceInfoReplicator。Heartbeat timer就是不断的发送请求来维持心跳的,也就是服务续约的任务。而InstanceInfoReplicator类实现了Runnable接口,所以需要看下InstanceInfoReplicator类中的run方法。
public void run() {
try {
discoveryClient.refreshInstanceInfo();
Long dirtyTimestamp = instanceInfo.isDirtyWithTime();
if (dirtyTimestamp != null) {
discoveryClient.register();
instanceInfo.unsetIsDirty(dirtyTimestamp);
}
} catch (Throwable t) {
logger.warn("There was a problem with the instance info replicator", t);
} finally {
Future next = scheduler.schedule(this, replicationIntervalSeconds, TimeUnit.SECONDS);
scheduledPeriodicRef.set(next);
}
}在run方法中,会调用我们之前看到的discoveryClient.register()方法进行服务注册。
/**
* Register with the eureka service by making the appropriate REST call.
*/
boolean register() throws Throwable {
logger.info(PREFIX + appPathIdentifier + ": registering service...");
EurekaHttpResponse<Void> httpResponse;
try {
httpResponse = eurekaTransport.registrationClient.register(instanceInfo);
} catch (Exception e) {
logger.warn("{} - registration failed {}", PREFIX + appPathIdentifier, e.getMessage(), e);
throw e;
}
if (logger.isInfoEnabled()) {
logger.info("{} - registration status: {}", PREFIX + appPathIdentifier, httpResponse.getStatusCode());
}
return httpResponse.getStatusCode() == 204;
}register()方法,就会把instanceInfo信息,通过REST请求发送给Eureka Server。instanceInfo就是客服端服务的元数据。
所以,在initScheduledTasks方法中,做了三个操作,向Eureka Server注册服务,并且在条件满足的情况下,创建服务获取和服务续约两个定时任务。
我们在Eureka Client的配置文件中还配置了eureka.client.service-url.defaultZone这个地址,所以,在DiscoveryClient类中找一下serviceUrl这个关键字,可以看到有相应的方法:
/**
* @deprecated use {@link #getServiceUrlsFromConfig(String, boolean)} instead.
*/
@Deprecated
public static List<String> getEurekaServiceUrlsFromConfig(String instanceZone, boolean preferSameZone) {
return EndpointUtils.getServiceUrlsFromConfig(staticClientConfig, instanceZone, preferSameZone);
}方法最终调用了EndpointUtils.getServiceUrlsFromConfig,点进这个方法看下:
/**
* Get the list of all eureka service urls from properties file for the eureka client to talk to.
*
* @param clientConfig the clientConfig to use
* @param instanceZone The zone in which the client resides
* @param preferSameZone true if we have to prefer the same zone as the client, false otherwise
* @return The list of all eureka service urls for the eureka client to talk to
*/
public static List<String> getServiceUrlsFromConfig(EurekaClientConfig clientConfig, String instanceZone, boolean preferSameZone) {
List<String> orderedUrls = new ArrayList<String>();
String region = getRegion(clientConfig);
String[] availZones = clientConfig.getAvailabilityZones(clientConfig.getRegion());
if (availZones == null || availZones.length == 0) {
availZones = new String[1];
availZones[0] = DEFAULT_ZONE;
}
logger.debug("The availability zone for the given region {} are {}", region, Arrays.toString(availZones));
int myZoneOffset = getZoneOffset(instanceZone, preferSameZone, availZones);
List<String> serviceUrls = clientConfig.getEurekaServerServiceUrls(availZones[myZoneOffset]);
if (serviceUrls != null) {
orderedUrls.addAll(serviceUrls);
}
int currentOffset = myZoneOffset == (availZones.length - 1) ? 0 : (myZoneOffset + 1);
while (currentOffset != myZoneOffset) {
serviceUrls = clientConfig.getEurekaServerServiceUrls(availZones[currentOffset]);
if (serviceUrls != null) {
orderedUrls.addAll(serviceUrls);
}
if (currentOffset == (availZones.length - 1)) {
currentOffset = 0;
} else {
currentOffset++;
}
}
if (orderedUrls.size() < 1) {
throw new IllegalArgumentException("DiscoveryClient: invalid serviceUrl specified!");
}
return orderedUrls;
}在方法中,先获取了该项目配置的Region,又根据region获取了可用的zone列表。这里可以看到,项目的region只能属于一个,一个region下可以配置多个zone。
再通过getZoneOffset方法,从多个zone中选择对应的一个下标,根据这个zone来加载这个zone下的serviceUrls。
Eureka Server源码:
下面再看下Eureka Server方面的源码,主要代码都在com.netflix.eureka:eureka-core-1.4.6.jar包下。
先看下这个包下的EurekaBootStrap类,这个类实现了ServletContextListener接口,在 Servlet API 中有一个 ServletContextListener 接口,它能够监听 ServletContext 对象的生命周期,当Servlet 容器启动或终止Web 应用时,会触发ServletContextEvent 事件,该事件由ServletContextListener 来处理。在 ServletContextListener 接口中定义了处理ServletContextEvent 事件的两个方法:contextInitialized和contextDestroyed。
EurekaBootStrap类中实现了这两个方法,在容器初始化的时候,就会执行这个类中的方法。
@Override
public void contextInitialized(ServletContextEvent event) {
try {
initEurekaEnvironment();
initEurekaServerContext();
ServletContext sc = event.getServletContext();
sc.setAttribute(EurekaServerContext.class.getName(), serverContext);
} catch (Throwable e) {
logger.error("Cannot bootstrap eureka server :", e);
throw new RuntimeException("Cannot bootstrap eureka server :", e);
}
}在contextInitialized中,会初始化EurekaEnvironment和EurekaServerContext,进入EurekaServerContext方法,可以看到,在方法中,新建了几个类,PeerAwareInstanceRegistryImpl和PeerEurekaNodes等。
Eureka Server会接收Eureka Client发送的REST请求,进行服务的注册,续约,下线等操作,这部分代码在com.netflix.eureka:eureka-core-1.4.6.jar包的resources目录下。
在resources目录下有个ApplicationResource类,类中有个方法,addInstance,这个方法就是接收注册服务请求的,下面看下这个方法:
/**
* Registers information about a particular instance for an
* {@link com.netflix.discovery.shared.Application}.
*
* @param info
* {@link InstanceInfo} information of the instance.
* @param isReplication
* a header parameter containing information whether this is
* replicated from other nodes.
*/
@POST
@Consumes({"application/json", "application/xml"})
public Response addInstance(InstanceInfo info,
@HeaderParam(PeerEurekaNode.HEADER_REPLICATION) String isReplication) {
logger.debug("Registering instance {} (replication={})", info.getId(), isReplication);
// validate that the instanceinfo contains all the necessary required fields
if (isBlank(info.getId())) {
return Response.status(400).entity("Missing instanceId").build();
} else if (isBlank(info.getHostName())) {
return Response.status(400).entity("Missing hostname").build();
} else if (isBlank(info.getAppName())) {
return Response.status(400).entity("Missing appName").build();
} else if (!appName.equals(info.getAppName())) {
return Response.status(400).entity("Mismatched appName, expecting " + appName + " but was " + info.getAppName()).build();
}
// handle cases where clients may be registering with bad DataCenterInfo with missing data
DataCenterInfo dataCenterInfo = info.getDataCenterInfo();
if (dataCenterInfo instanceof UniqueIdentifier) {
String dataCenterInfoId = ((UniqueIdentifier) dataCenterInfo).getId();
if (isBlank(dataCenterInfoId)) {
boolean experimental = "true".equalsIgnoreCase(serverConfig.getExperimental("registration.validation.dataCenterInfoId"));
if (experimental) {
String entity = "DataCenterInfo of type " + dataCenterInfo.getClass() + " must contain a valid id";
return Response.status(400).entity(entity).build();
} else if (dataCenterInfo instanceof AmazonInfo) {
AmazonInfo amazonInfo = (AmazonInfo) dataCenterInfo;
String effectiveId = amazonInfo.get(AmazonInfo.MetaDataKey.instanceId);
if (effectiveId == null) {
amazonInfo.getMetadata().put(AmazonInfo.MetaDataKey.instanceId.getName(), info.getId());
}
} else {
logger.warn("Registering DataCenterInfo of type {} without an appropriate id", dataCenterInfo.getClass());
}
}
}
registry.register(info, "true".equals(isReplication));
return Response.status(204).build(); // 204 to be backwards compatible
}这个方法接收一个InstanceInfo info参数,这个参数就是要注册的Eureka Client节点的信息,在对这个InstanceInfo信息进行了一连串的校验之后,会调用registry.register(info, “true”.equals(isReplication))这个方法,进行服务注册,再进入这个方法看下:
@Override
public void register(final InstanceInfo info, final boolean isReplication) {
int leaseDuration = Lease.DEFAULT_DURATION_IN_SECS;
if (info.getLeaseInfo() != null && info.getLeaseInfo().getDurationInSecs() > 0) {
leaseDuration = info.getLeaseInfo().getDurationInSecs();
}
super.register(info, leaseDuration, isReplication);
replicateToPeers(Action.Register, info.getAppName(), info.getId(), info, null, isReplication);
}这个方法就是在EurekaBootStrap中初始化的PeerAwareInstanceRegistryImpl类中的方法,在方法中,会获取InstanceInfo的续约时间信息,默认是90秒。然后调用父类的register方法注册,注册完后,会调用replicateToPeers方法,把这个节点的注册信息告诉其它Eureka Server节点。
先看下父类的register方法:
/**
* Registers a new instance with a given duration.
*
* @see com.netflix.eureka.lease.LeaseManager#register(java.lang.Object, int, boolean)
*/
public void register(InstanceInfo r, int leaseDuration, boolean isReplication) {
try {
read.lock();
Map<String, Lease<InstanceInfo>> gMap = registry.get(r.getAppName());
REGISTER.increment(isReplication);
if (gMap == null) {
final ConcurrentHashMap<String, Lease<InstanceInfo>> gNewMap =
new ConcurrentHashMap<String, Lease<InstanceInfo>>();
gMap = registry.putIfAbsent(r.getAppName(), gNewMap);
if (gMap == null) {
gMap = gNewMap;
}
}
Lease<InstanceInfo> existingLease = gMap.get(r.getId());
// Retain the last dirty timestamp without overwriting it, if there is already a lease
if (existingLease != null && (existingLease.getHolder() != null)) {
Long existingLastDirtyTimestamp = existingLease.getHolder().getLastDirtyTimestamp();
Long registrationLastDirtyTimestamp = r.getLastDirtyTimestamp();
logger.debug("Existing lease found (existing={}, provided={}", existingLastDirtyTimestamp, registrationLastDirtyTimestamp);
if (existingLastDirtyTimestamp > registrationLastDirtyTimestamp) {
logger.warn("There is an existing lease and the existing lease's dirty timestamp {} is " +
"greater than the one that is being registered {}",
existingLastDirtyTimestamp,
registrationLastDirtyTimestamp);
r.setLastDirtyTimestamp(existingLastDirtyTimestamp);
}
} else {
// The lease does not exist and hence it is a new registration
synchronized (lock) {
if (this.expectedNumberOfRenewsPerMin > 0) {
// Since the client wants to cancel it, reduce the threshold
// (1
// for 30 seconds, 2 for a minute)
this.expectedNumberOfRenewsPerMin = this.expectedNumberOfRenewsPerMin + 2;
this.numberOfRenewsPerMinThreshold =
(int) (this.expectedNumberOfRenewsPerMin * serverConfig.getRenewalPercentThreshold());
}
}
logger.debug("No previous lease information found; it is new registration");
}
Lease<InstanceInfo> lease = new Lease<InstanceInfo>(r, leaseDuration);
if (existingLease != null) {
lease.setServiceUpTimestamp(existingLease.getServiceUpTimestamp());
}
gMap.put(r.getId(), lease);
synchronized (recentRegisteredQueue) {
recentRegisteredQueue.add(new Pair<Long, String>(
System.currentTimeMillis(),
r.getAppName() + "(" + r.getId() + ")"));
}
// This is where the initial state transfer of overridden status happens
if (!InstanceStatus.UNKNOWN.equals(r.getOverriddenStatus())) {
logger.debug("Found overridden status {} for instance {}. Checking to see if needs to be add to the "
+ "overrides", r.getOverriddenStatus(), r.getId());
if (!overriddenInstanceStatusMap.containsKey(r.getId())) {
logger.info("Not found overridden id {} and hence adding it", r.getId());
overriddenInstanceStatusMap.put(r.getId(), r.getOverriddenStatus());
}
}
InstanceStatus overriddenStatusFromMap = overriddenInstanceStatusMap.get(r.getId());
if (overriddenStatusFromMap != null) {
logger.info("Storing overridden status {} from map", overriddenStatusFromMap);
r.setOverriddenStatus(overriddenStatusFromMap);
}
// Set the status based on the overridden status rules
InstanceStatus overriddenInstanceStatus = getOverriddenInstanceStatus(r, existingLease, isReplication);
r.setStatusWithoutDirty(overriddenInstanceStatus);
// If the lease is registered with UP status, set lease service up timestamp
if (InstanceStatus.UP.equals(r.getStatus())) {
lease.serviceUp();
}
r.setActionType(ActionType.ADDED);
recentlyChangedQueue.add(new RecentlyChangedItem(lease));
r.setLastUpdatedTimestamp();
invalidateCache(r.getAppName(), r.getVIPAddress(), r.getSecureVipAddress());
logger.info("Registered instance {}/{} with status {} (replication={})",
r.getAppName(), r.getId(), r.getStatus(), isReplication);
} finally {
read.unlock();
}
}这个方法挺长的,有兴趣的可以仔细看下,方法功能大体还是注册信息了,注册的信息会存放在map中,而且还是个两层的ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>>,外层map的key是appName,也就是服务名,内层map的key是instanceId,也就是实例名。更新完map信息后,还会更新缓存信息。
注册完信息后,调用了replicateToPeers方法,向其他Eureka Server转发该注册信息,以便实现信息的同步。进到这个方法里面看下:
/**
* Replicates all eureka actions to peer eureka nodes except for replication
* traffic to this node.
*
*/
private void replicateToPeers(Action action, String appName, String id,
InstanceInfo info /* optional */,
InstanceStatus newStatus /* optional */, boolean isReplication) {
Stopwatch tracer = action.getTimer().start();
try {
if (isReplication) {
numberOfReplicationsLastMin.increment();
}
// If it is a replication already, do not replicate again as this will create a poison replication
if (peerEurekaNodes == Collections.EMPTY_LIST || isReplication) {
return;
}
for (final PeerEurekaNode node : peerEurekaNodes.getPeerEurekaNodes()) {
// If the url represents this host, do not replicate to yourself.
if (peerEurekaNodes.isThisMe(node.getServiceUrl())) {
continue;
}
replicateInstanceActionsToPeers(action, appName, id, info, newStatus, node);
}
} finally {
tracer.stop();
}
}方法中会通过for循环遍历所有的PeerEurekaNode,调用replicateInstanceActionsToPeers方法,把信息复制给其他的Eureka Server节点,下面是replicateInstanceActionsToPeers方法:
/**
* Replicates all instance changes to peer eureka nodes except for
* replication traffic to this node.
*
*/
private void replicateInstanceActionsToPeers(Action action, String appName,
String id, InstanceInfo info, InstanceStatus newStatus,
PeerEurekaNode node) {
try {
InstanceInfo infoFromRegistry = null;
CurrentRequestVersion.set(Version.V2);
switch (action) {
case Cancel:
node.cancel(appName, id);
break;
case Heartbeat:
InstanceStatus overriddenStatus = overriddenInstanceStatusMap.get(id);
infoFromRegistry = getInstanceByAppAndId(appName, id, false);
node.heartbeat(appName, id, infoFromRegistry, overriddenStatus, false);
break;
case Register:
node.register(info);
break;
case StatusUpdate:
infoFromRegistry = getInstanceByAppAndId(appName, id, false);
node.statusUpdate(appName, id, newStatus, infoFromRegistry);
break;
case DeleteStatusOverride:
infoFromRegistry = getInstanceByAppAndId(appName, id, false);
node.deleteStatusOverride(appName, id, infoFromRegistry);
break;
}
} catch (Throwable t) {
logger.error("Cannot replicate information to {} for action {}", node.getServiceUrl(), action.name(), t);
}
}方法中,会判断action具体的动作,如果是Register,就会调用node.register(info);
/**
* Sends the registration information of {@link InstanceInfo} receiving by
* this node to the peer node represented by this class.
*
* @param info
* the instance information {@link InstanceInfo} of any instance
* that is send to this instance.
* @throws Exception
*/
public void register(final InstanceInfo info) throws Exception {
long expiryTime = System.currentTimeMillis() + getLeaseRenewalOf(info);
batchingDispatcher.process(
taskId("register", info),
new InstanceReplicationTask(targetHost, Action.Register, info, null, true) {
public EurekaHttpResponse<Void> execute() {
return replicationClient.register(info);
}
},
expiryTime
);
}在该方法中,是通过启动了一个任务,来向其它节点同步信息的,不是实时同步的。
看到这里,注册的流程就算是看完了,其它像续约、下线的流程也类似,在此不再一一列举,有兴趣的同学可以顺着代码仔细看下。
参考资料:
1.《Spring Cloud与Docker微服务架构实战》 周立 著
2.《Spring Cloud微服务实战》 翟永超 著
3.《深入理解Spring Cloud与微服务构建》 方志朋 著
最后
以上就是开朗果汁最近收集整理的关于Spring Cloud Eureka源码分析的全部内容,更多相关Spring内容请搜索靠谱客的其他文章。








发表评论 取消回复