麦克风阵列,是一组位于空间不同位置的全向麦克风按一定的形状规则布置形成的阵列,是对空间传播声音信号进行空间采样的一种装置,采集到的信号包含了其空间位置信息。根据声源和麦克风阵列之间距离的远近,可将阵列分为近场模型和远场模型。根据麦克风阵列的拓扑结构,则可分为线性阵列、平面阵列、体阵列等。
麦克风不同的排列对应不同的算法,那么最简单的排列就是线性排列了,也就是麦克风排列成一排。在远场(指说话人距离麦克风很远)的情况下,我们一般认为人说话的波形是平面波,如下:
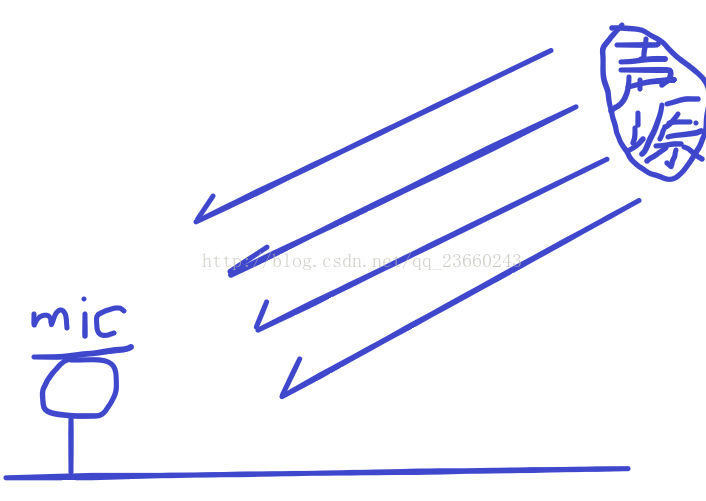
那么每个麦克风接收到的信号在同一时刻都不会相同,因为有时延,你可能会问什么是时延,那么下面给出具体的统一线性麦克风阵列模型图:
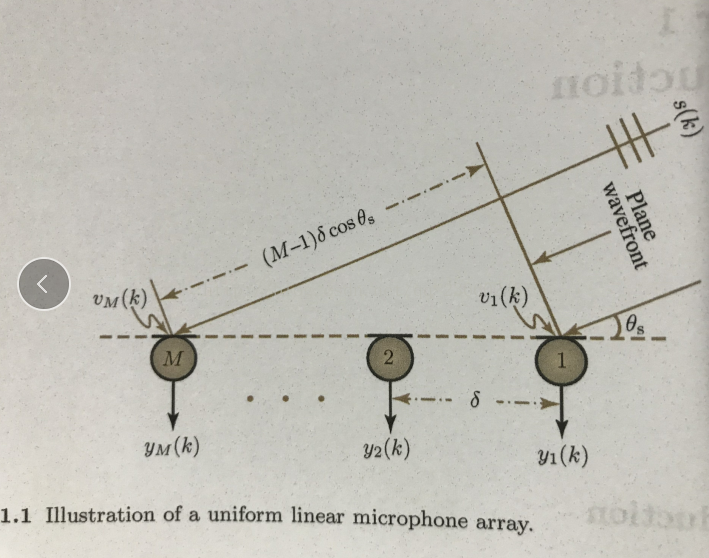
这个模型具体参数此处不做讲解,很简单直白。那么从这里我们可以看出来,每个麦克风接收到的数据ym(k)与之前的麦克风接收到的数据之前存在延迟。其公式如下:
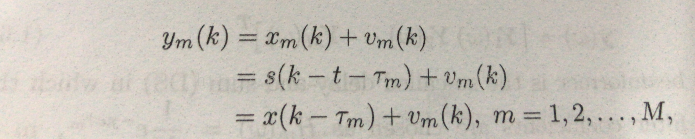
时间延迟如下(c是声速340m/s):
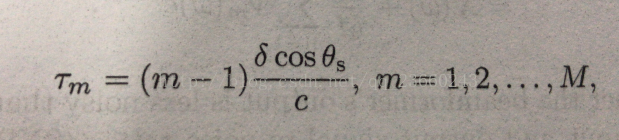
一般我们都是转化到频域去处理,所以将上述傅里叶变换后得到(别问我傅里叶变换是什么):
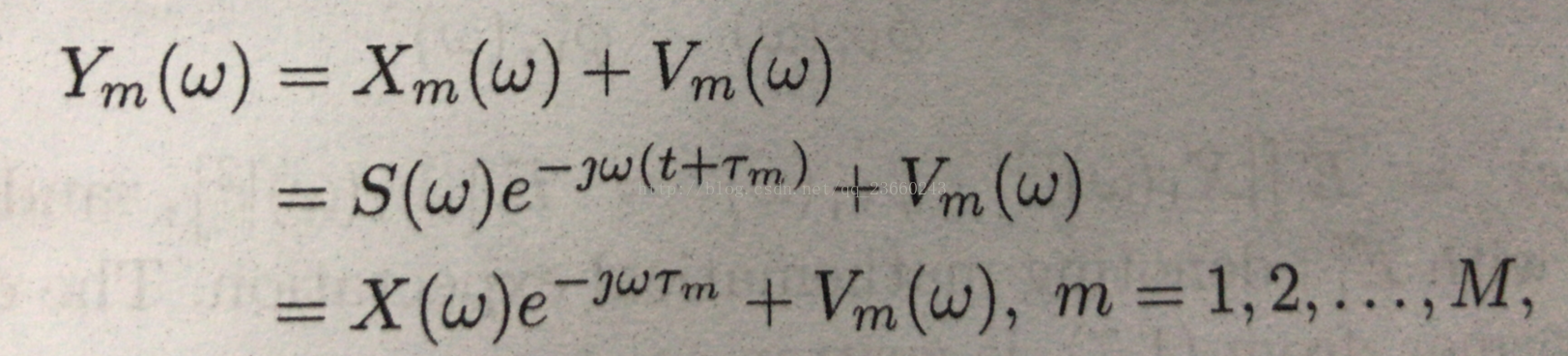
切记,这里都是原式子的傅里叶变换后的形式。
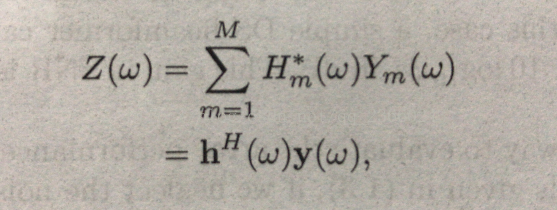
好了,理论模型推理到这里,那么开始看我们手头有什么数据,说白了,方程中有哪些参数我们是已知的,ym(k)是已知的,这就是我们的麦克风接收到的数据呀,术语观测数据。这时候不要脑袋一热就开始根据模型往回带数据,模型仅仅是为我们提供参考思路(即使想带回去也不行,vm根本就未知)。
得知观测数据的我们,需要从观测数据中抽离我们想要的内容,那么很自然的想到滤波器。我们称这种滤波器叫做:波束形成滤波器(因为它增强了我们想要的内容,削弱了我们不想要的内容,跟前面的指向性麦克风联系起来,是不是感觉世界很奇妙):
其中:
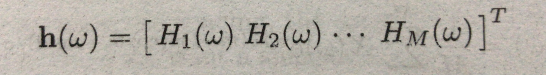
而这个得到的Z,就是我们所要求的。
问题到了这里变得很清晰,如何估计这个滤波器。波束增强有很多种算法,有很多种估计滤波器的方式,从简单到复杂,从效果差到效果好,各有不同。那么我们这里说一下基于我们上面模型的最简单的delay-and-sum(DS)滤波器,他的效果用一句话概括就是:我们仅仅把各个麦克风接收到的信号补偿他们的时延,然后求一个均值,没有考虑混响等实际场景可能发生的情况。那么,我们的Z如下:
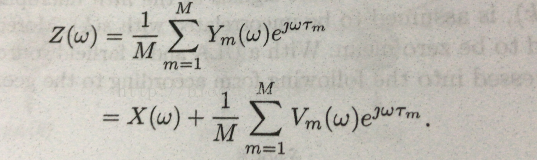
从而我们用最简单的办法得到了我们所要的信号,其性能评估等后续说明。
最后
以上就是大力鼠标最近收集整理的关于【Audio音频兴趣拓展】麦克风阵列_线性排列的全部内容,更多相关【Audio音频兴趣拓展】麦克风阵列_线性排列内容请搜索靠谱客的其他文章。








发表评论 取消回复