决策树主要有ID3、C4.5、CART分类回归树。决策树的“规则”大体上来说类似于一个"if...then..."的过程。
ID3
ID3只能用于分类的问题。ID3不能使用连续特征,只能使用离散特征。ID3可以是多叉树。通过信息增益来达到分裂节点的目的,信息增益越大的特征,越可能成为被先选择分裂的节点。而信息增益,指的是在增加了该特征后,标签的不确定性减少的程度(熵减少的程度)。一般地,熵H(Y)与条件熵H(Y|X)之差称为互信息。信息增益等价于集合中类与特征的互信息。
信息增益(互信息)的公式为
![]()
其中H(D)为经验熵,H(D|A)为条件经验熵。
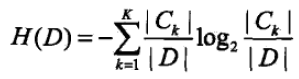
其中|Ck|为属于类Ck的样本个数。
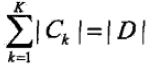
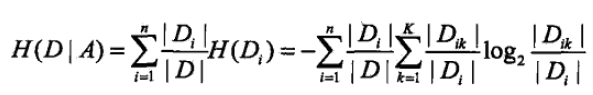
根据特征A的取值将D划分为n个子集D1,D2...Dn, D_ik为D_i与C_k的交集。(为了容易理解,这里可以先考虑二分类问题,即K=2)
根据上式,可以发现信息增益倾向于选择取值数量多的特征(比如特征1有a,b,c三种取值,特征2有d,e两种取值,那么特征1比特征2更可能被选择)。说明取值数量多的特征的条件经验熵更低。
从公式出发,信息增益是整个数据集的经验熵与特征A对整个数据集的条件经验熵的差值,信息增益越大即条件经验熵越小,那什么情况下的属性会有极小的的经验条件熵呢?举个极端的例子,如果将身份证号作为一个属性,那么,其实每个人的身份证号都是不相同的,也就是说,有多少个人,就有多少种取值,如果用身份证号这个属性去划分原数据集,那么,原数据集中有多少个样本,就会被划分为多少个子集,这样的话,会导致信息增益公式的第二项整体为0,虽然这种划分毫无意义(无法泛化),但是从信息增益准则来讲,这就是最好的划分属性。其实从概念来讲,就一句话,信息增益表示由于特征A而使得数据集的分类不确定性减少的程度,信息增益大的特征具有更强的分类能力。
再细说第二项整体为0,打个比方是二分类,由于身份证号的唯一性,导致每个Di子集的大小为1,也就是这里|Di| = 1, |D_ik|就为1或者0了。
当然,由上面那个例子也可以看出,信息增益会有缺点,属性取值多的特征并不一定是最优。
于是提出了C4.5,C4.5利用信息增益比来分裂节点。
ID3的大概生成步骤:
- 输入训练集D,信息增益阈值
- 首先选择信息增益最大的特征Ag。
- 如果特征的信息增益小于阈值,则返回单节点树,标记类别为样本中输出类别D实例数最多的类别。
- 否则,按特征Ag的不同取值Agi将对应的样本输出D分成不同的类别Di,每个类别产生一个子节点(这就导致了多叉树的产生)。对应特征值为Agi,返回增加了节点的树T。
- 对各个子节点,分别令D = Di,A = A - {Ag}递归调用上述步骤,得到子树Ti并返回。
小结:
ID3倾向于选择特征取值较多的特征,因为信息增益反映的是给定条件以后不确定性减少的程度,特征取值越多就意味着确定性更高,也就是条件熵越小,信息增益越大。比较极限的情况就是之前提到的身份证号。但是这样模型的泛化能力时候很弱的。所以引入了信息增益比对取值比较多的特征进行惩罚。
C4.5
C4.5对信息增益添加了罚项,改为了信息增益比。并且能够处理连续特征了。以及相比于ID3,能够处理缺失值了。但是C4.5仍然只能用于分类。C4.5也可以是多叉树。
信息增益比的公式为
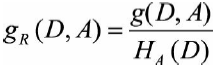
其中g(D,A)为信息增益,H_A(D)为数据集D关于特征A的取值熵。
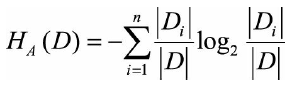
其中n是特征A取值的个数。
通过上述公式,可以发现当A取值越多时,不纯度越大,熵越大,导致信息增益比越小。达到了惩罚的目的。
而针对连续特征,C4.5先将连续特征排序,以连续两个值的中间值作为分裂点,将小于这个点的值为类别1,大于这个点的值为类别2(连续变量离散化,所以本质上还是用的离散特征),计算信息增益,并尝试每一种分裂点(比如属性A有v个连续值,那么就有v-1个划分点需要进行计算),找到最大的信息增益的分裂点作为该特征的分裂点。比如下面HUMIDITY找到了70这个分裂点。
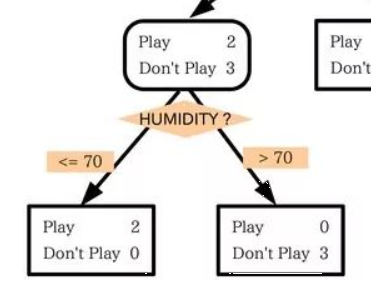
计算最佳分裂点的信息增益比作为特征的信息增益比(不然没办法和离散特征进行比较)。注意,此处需对最佳分裂点的信息增益进行修正:减去log2(N-1)/|D|(N是连续特征的取值个数,D是训练数据数目,此修正的原因在于:当离散属性和连续属性并存时,C4.5算法倾向于选择连续特征做最佳树分裂节点。因为当分裂后,连续属性变为两类,此时其他属性取值才更多,因此反而需要弥补该连续属性的信息增益。)
对于处理缺失值,对于某一个有缺失特征值的特征A,C4.5将数据分成两部分,一部分是有特征值的D1,一部分是没有特征值的D2。对每个样本设置一个权重(初始可以都是1),然后对于没有缺失特征A的数据集D1来和对应的A特征的各个特征值一起计算加权重后的信息增益比,最后乘上一个系数,这个系数是无特征A缺失的样本加权后所占加权总样本的比例。
对于选定了特征后,该特征上缺失特征的样本的处理。可以将缺失特征的样本同时划分入所有的子节点,不过将该样本的权重按各个子节点样本的数量比例来分配。比如缺失特征A的样本a之前权重为1,特征A有3个特征值A1,A2,A3。 3个特征值对应的无缺失A特征的样本个数为2,3,4.则a同时划分入A1,A2,A3。对应权重调节为2/9,3/9, 4/9。
除此之外,C4.5引入了正则化系数进行初步的剪枝,来防止过拟合,这也是ID3所不具备的。
C4.5的生成方式和之前ID3的类似,将信息增益改为信息增益比。
C4.5的不足与可改进的地方:
由于决策树算法非常容易过拟合,所以对于生成的决策树必须进行剪枝。思路主要有两种,预剪枝:在生成的时候就决定是否剪枝;后剪枝:在生成后通过交叉验证来剪枝。
C4.5生成多叉树,在很多时候,计算机中二叉树模型会比多叉树运算效率高。如果采用二叉树,可以提高效率。
C4.5使用熵模型,里面有大量耗时的对数运算,若是连续特征还有大量的排序运算。
上述提到的几个问题在CART里面得到了优化,不考虑集成学习的话,在普通的决策树算法里,CART是比较优的算法了。scikit-learn的决策树也是使用的CART算法。
CART (classification and regression tree)
CART相对于ID3和C4.5,已经可以用于回归问题了。但是不同的是,就像刚刚提到的那样,在很多时候,计算机中二叉树模型会比多叉树运算效率高,CART只能是二叉树,也就是说,无论是连续还是离散特征,无论属性取值有两个还是多个,在节点内部都只能根据属性值二分,节点内部特征的取值为“是”和“否”。同时,为了降低计算复杂度,放弃了熵模型,采用了基尼系数(简化模型的同时也不至于完全丢失熵模型的优点)。基尼系数代表了模型的不纯度,基尼系数越小,则不纯度越低,特征越好(和信息增益比是相反的)。
假设有K个类,样本点属于第K类的概率为Pk,则概率分布的基尼指数定义:
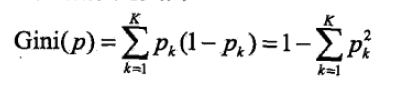 ——》
——》 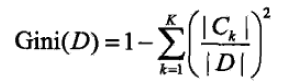
二分类:
![]()
对于特征A,如果根据特征A的某个值a,把D分成D1和D2两部分(一般是大于和小于),则在特征A的条件下,D的基尼指数表达式为:
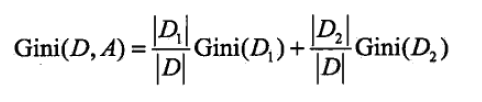
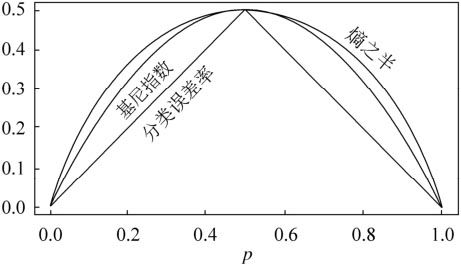
可以看出,基尼系数和熵之半的曲线非常接近,基尼系数可以作为熵模型的一个近似代替。CART分类树就是采用了基尼系数代替了信息增益比。
分类树:相比于C4.5采用了基尼指数,且只能二叉
对于连续特征:和C4.5类似,将连续的特征离散化,区别就是采用了基尼系数。对连续特征的m个取值,先从大到小排列,可取m-1个划分点(就是每两个点的中点),分别计算每个划分点时二分类的基尼系数。选择基尼系数最小的点作为二元离散分类点。比如取到的划分点为at,则大于at的为类别1,小于at的为类别2。同时,该特征在本次子节点生成过后,还可以参与后续的子节点的产生。
对于离散特征:采用的思路是不停地二分离散特征,同时该特征还会参与子节点的产生选择过程(相比于ID3和C4.5的离散特征只参与一次便退出)。相比于ID3和C4.5,如果遇到了A有A1,A2,A3三个类别,会在决策树建立一个三叉的节点。这样导致多叉树的产生。而CART是不停地二分,会考虑把A分成{A1}和{A2,A3}, {A2}和{A1,A3}, {A3}和{A1,A2}三种情况,然后找到基尼系数最小的组合,建立二叉树节点,比如{A2}和{A1,A3},一个节点是A2对应的样本,另一个节点是{A1,A3}对应的节点。由于没有完全将A划分开,后面还可以继续在子节点选择特征A来划分A1和A3。
CART分类树大概生成步骤:
输入训练集D,基尼系数的阈值,样本个数阈值。
0、如果基尼系数小于阈值,则返回决策树子树,当前节点停止递归。如果当前节点的样本数小于阈值或者没有特征,返回决策子树,停止递归。
1、计算当前节点的现有的各个特征的各个特征值对数据集D的基尼系数。离散特征和连续特征分别见上述。选择基尼系数最小的特征A和对应的特征值a。将数据集划分为两部分D1和D2。
2、对左右的子节点递归调用上述步骤。
对于生成的决策树预测时,加入测试集的样本X落到了某个叶子节点,而节点里有多个训练样本。则对于A的类别预测采用这个叶子节点里概率最大的类别。(所以也可以输出概率)
回归树:也称为最小回归树
首先区分回归树与分类树的不同,如果输出的是离散值,就是分类树,连续值,就是回归树。使用平方误差最小化准则来选择特征并进行划分,并采用样本的最小方差作为节点分裂的依据。
对于连续特征:不采用基尼系数。而是常见的最小二乘法则。扫描特征j的所有划分点,对每个划分点s将数据划分为D1和D2,求出使D1和D2各自集合的均方差最小,同时D1和D2的均方差之和最小所对应的特征和特征值划分。找到这样的特征和特征值,就是最优特征和以及它的最优划分点。
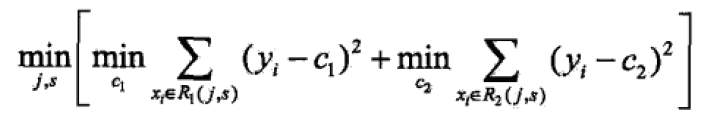
这个式子相当于是将两部分的标签的方差相加。

c1为D1数据集的样本输出均值,c2为D2数据集的样本输出均值。
对于离散特征:和分类树类似。
同时与分类树不同的是,采用的是最终叶子的均值或者中位数来预测输出结果。
CART的大概生成步骤对比:
分类树: 回归树:
1、计算各个特征的基尼系数 1、对属性内部的分裂规则和分类树一样,但是计算的是最小方差和。
2、选择基尼系数最小的特征和对应特征值 2、选择最小方差和的对应特征和相应的分裂点
3、递归生成决策树 3、递归生成决策树
CART决策树的缺点:
- 和ID3,C4.5一样,做特征选择的时候都是选择一个最优特征来做分类决策,但是大多数分类决策不应该是由某一个特征决定的,而是应该由一组特征决定的。这样决策得到的决策树更加准确,这个决策树叫做多变量决策树。选择最优的一个线性组合来做决策,这个算法的代表是OC1。
- 如果样本发生一点改动,就会导致树结构的剧烈改变,可以通过集成学习里的随机森林之类的方法解决。
CART的剪枝
由于决策时很容易过拟合,导致泛化能力差,为了解决这个问题,我们需要对CART树进行剪枝。
预剪枝
预剪枝的思想是在树中节点进行扩展前,先计算当前划分能否带来模型泛化能力的提升。如果不能,则不再继续生长子树。此时可能存在不同类别的样本同时存在于节点中,按照多数投票的原则判断该节点所属类别。
- 当树到达一定深度时停止生长
- 当到达当前节点的数量小于某个阈值的时候,停止生长
- 计算每次分裂对测试集的准确度提升,当小于某个阈值的时候,不再继续扩展
预剪枝简单、效率高,适合解决大规模问题。但如何准确估计何时停止树的生长,针对不同问题有很大差别,需要做经验判断。且预剪枝有欠拟合的风险,虽然当前的划分会导致测试集准确率降低,但在之后的划分中准确率可能上升。
后剪枝
后剪枝是在决策树生长完全后,从最底层向上进行剪枝。剪枝过程将子树删除,用一个叶子节点代替,该节点的类别同样用多数投票的原则进行判断。后剪枝通过测试集上准确率进行判断,如果剪枝过后准确率有所提升,则进行剪枝。
CART选择后剪枝,即先生成决策树,然后产生所有可能的剪枝后的CART树,然后使用交叉验证来检验各种剪枝的效果,选择泛化能力最好的剪枝策略。
剪枝的损失函数:
![]()
alpha是正则化参数,和线性回归的正则化一样。C(T)为训练数据的预测误差,分类树是用基尼系数度量,回归树是用均方差。|T|是子树T的叶子节点的数量。当alpha为0,没有正则化,不剪枝,生成的决策树就是最优的;当alpha为无穷,正则化强度最大,此时由原始的根节点组成的单节点树为最优子树。一般来说,正则化系数alpha越大,剪枝越厉害。
对于某一固定的alpha,一定存在使损失函数C_a(T)最小的唯一子树。
剪枝策略:
对任意一棵子树,如果损失是![]()
当仅仅保留根节点时,损失是![]()
当alpha很小或为0时,![]() 一般是小于
一般是小于![]() 的,因为前者更细致,损失更小。
的,因为前者更细致,损失更小。
当alpha达到某种程度,![]() 等于
等于![]() 。
。
此时误差增加率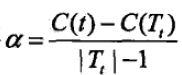 ,也就是Tt和t有了相同的损失,但是t的节点更少,因此可以对Tt进行剪枝,变成单节点t。
,也就是Tt和t有了相同的损失,但是t的节点更少,因此可以对Tt进行剪枝,变成单节点t。
因此,对每个节点,都计算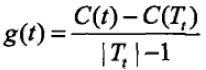 。
。
可以计算出每个子树的剪枝的阈值alpha,针对不同的alpha所对应的剪枝后的最优子树做交叉验证。这样就有一个最好的alpha,也有了对应的最优子树。在alpha偏大的时候,最优子树偏小;在alpha偏小的时候,最优子树偏大。
剪枝大致步骤:
1、设alpha为正无穷。子树集合目前为空。
2、自下而上地对各内部节点计算alpha,若alpha比之前小,则更新alpha。一直找到最小的alpha。在这个阶段记录下所有更新过的alpha,弄做一个集合。
3、自上而下地访问内部节点,如果有g(t)<=alpha集合中的最大值,进行剪枝,得到对应的树T(如果是分类树,叶节点是概率最高的类别,如果是回归树,则是所有样本的均值)。在子树集合中,将刚刚得到的最优子树并入。alpha集合去掉刚刚使用的alpha。
4、如果alpha集合还不为空,则回到步骤3.
5、在得到的最优子树集合中,对每个子树进行交叉验证,得到最优子树。
剪枝小结:
剪枝过程占有极其重要的地位,很多研究表明,剪枝比树的生成过程更为关键。对于不同划分标准生成的过拟合决策树,经过剪枝后都能保留最重要的属性划分。因此最终性能差距不大。
小结
决策树的优点:
1、简单直观,可解释性强
2、不需预处理,不需归一化,处理缺失值。
3、代价是O(log2 m),m为样本数。
4、既可以处理离散值又可以处理连续值。
5、相比神经网络的黑盒分类,决策树在逻辑上可以得到很好解释。
6、可以交叉验证剪枝,提高泛化能力。
7、对异常点容错性好。
8、有特征选择作用
9、可扩展性强,容易并行
缺点:
1、容易过拟合。可以通过设置最少样本数量和限制深度来改进。
2、因为样本的一点变动导致树结构的剧烈改变,可以通过集成学习之类的方法解决。
3、类似于异或这样的复杂关系,没有办法,可以换神经网络来解决。
4、某些特征的样本比例过大,决策树容易偏向这些特征。通过调节样本权重来改善。
5、缺乏平滑性(回归预测只能输出有限的若干种数值)
6、不适合处理高维稀疏数据
最后
以上就是呆萌路灯最近收集整理的关于个人总结:决策树的全部内容,更多相关个人总结内容请搜索靠谱客的其他文章。








发表评论 取消回复