高性能高可用MySQL(主从同步,读写分离,分库分表,去中心化,虚拟IP,心跳机制)
视频地址:https://www.bilibili.com/video/BV1ry4y1v7Tr?p=8&spm_id_from=pageDriver
1、面试题
为什么要分库分表(设计高并发系统的时候,数据库层面该如何设计)?用过哪些分库分表中间件?不同的分库分表中间件都有什么优点和缺点?你们具体是如何对数据库如何进行垂直拆分或水平拆分的?
其实这块肯定是扯到高并发了,因为分库分表一定是为了支撑高并发、数据量大两个问题的。而且现在说实话,尤其是互联网类的公司面试,基本上都会来这么一下,分库分表如此普遍的技术问题,不问实在是不行,而如果你不知道那也实在是说不过去!
(1)为什么要分库分表?(设计高并发系统的时候,数据库层面该如何设计?)
说白了,分库分表是两回事儿,大家可别搞混了,可能是光分库不分表,也可能是光分表不分库,都有可能。我先给大家抛出来一个场景。
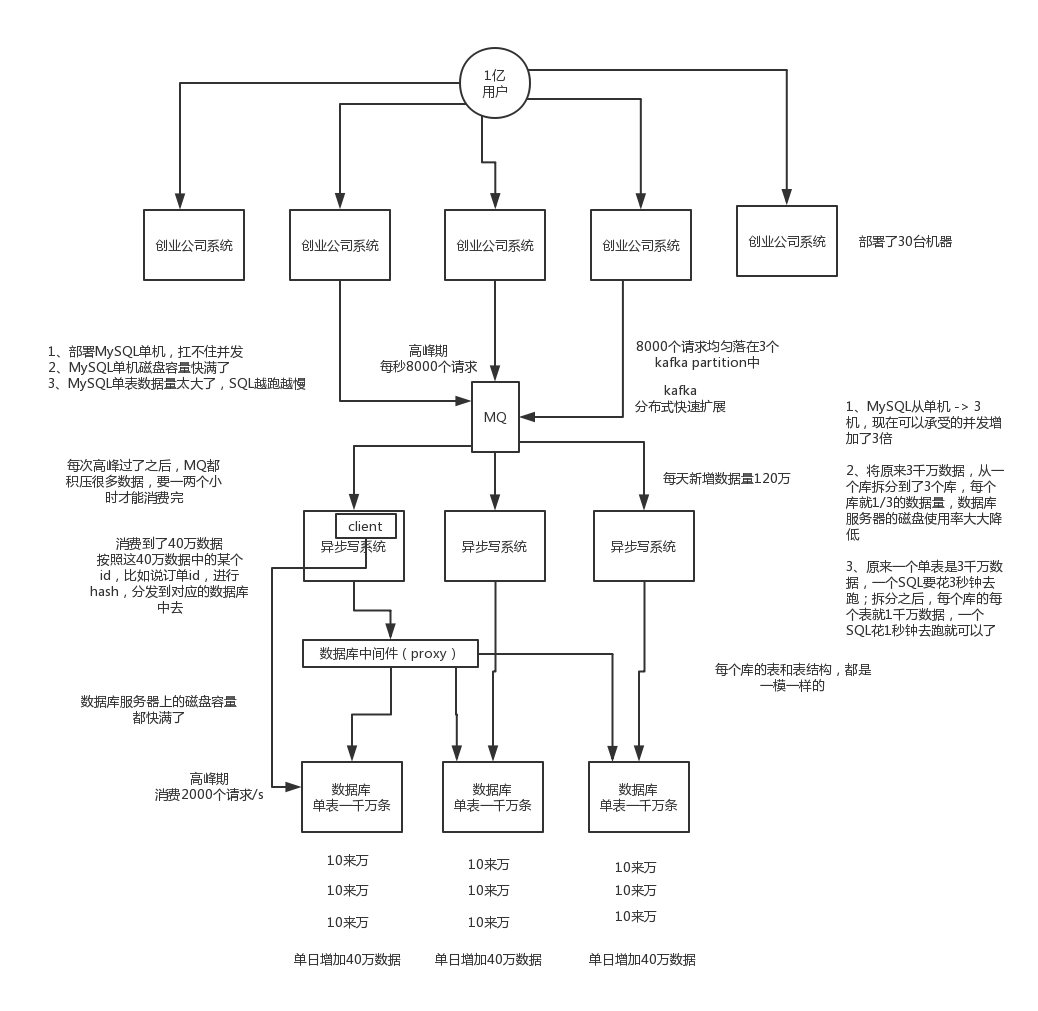
假如我们现在是一个小创业公司(或者是一个BAT公司刚兴起的一个新部门),现在注册用户就20万,每天活跃用户就1万,每天单表数据量就1000,然后高峰期每秒钟并发请求最多就10。。。天,就这种系统,随便找一个有几年工作经验的,然后带几个刚培训出来的,随便干干都可以。
结果没想到我们运气居然这么好,碰上个CEO带着我们走上了康庄大道,业务发展迅猛,过了几个月,注册用户数达到了2000万!每天活跃用户数100万!每天单表数据量10万条!高峰期每秒最大请求达到1000!同时公司还顺带着融资了两轮,紧张了几个亿人民币啊!公司估值达到了惊人的几亿美金!这是小独角兽的节奏!
好吧,没事,现在大家感觉压力已经有点大了,为啥呢?因为每天多10万条数据,一个月就多300万条数据,现在咱们单表已经几百万数据了,马上就破千万了。但是勉强还能撑着。高峰期请求现在是1000,咱们线上部署了几台机器,负载均衡搞了一下,数据库撑1000 QPS也还凑合。但是大家现在开始感觉有点担心了,接下来咋整呢。。。。。。
再接下来几个月,我的天,CEO太牛逼了,公司用户数已经达到1亿,公司继续融资几十亿人民币啊!公司估值达到了惊人的几十亿美金,成为了国内今年最牛逼的明星创业公司!天,我们太幸运了。
但是我们同时也是不幸的,因为此时每天活跃用户数上千万,每天单表新增数据多达50万,目前一个表总数据量都已经达到了两三千万了!扛不住啊!数据库磁盘容量不断消耗掉!高峰期并发达到惊人的5000~8000!别开玩笑了,哥。我跟你保证,你的系统支撑不到现在,已经挂掉了!
好吧,所以看到你这里你差不多就理解分库分表是怎么回事儿了,实际上这是跟着你的公司业务发展走的,你公司业务发展越好,用户就越多,数据量越大,请求量越大,那你单个数据库一定扛不住。
比如你单表都几千万数据了,你确定你能抗住么?绝对不行,单表数据量太大,会极大影响你的sql执行的性能,到了后面你的sql可能就跑的很慢了。一般来说,就以我的经验来看,单表到几百万的时候,性能就会相对差一些了,你就得分表了。
分表是啥意思?就是把一个表的数据放到多个表中,然后查询的时候你就查一个表。比如按照用户id来分表,将一个用户的数据就放在一个表中。然后操作的时候你对一个用户就操作那个表就好了。这样可以控制每个表的数据量在可控的范围内,比如每个表就固定在200万以内。
分库是啥意思?就是你一个库一般我们经验而言,最多支撑到并发2000,一定要扩容了,而且一个健康的单库并发值你最好保持在每秒1000左右,不要太大。那么你可以将一个库的数据拆分到多个库中,访问的时候就访问一个库好了。
这就是所谓的分库分表,为啥要分库分表?你明白了吧
(2)用过哪些分库分表中间件?不同的分库分表中间件都有什么优点和缺点?
比较常见的包括:cobar、TDDL、atlas、sharding-jdbc、mycat
cobar:阿里b2b团队开发和开源的,属于proxy层方案。早些年还可以用,但是最近几年都没更新了,基本没啥人用,差不多算是被抛弃的状态吧。而且不支持读写分离、存储过程、跨库join和分页等操作。
TDDL:淘宝团队开发的,属于client层方案。不支持join、多表查询等语法,就是基本的crud语法是ok,但是支持读写分离。目前使用的也不多,因为还依赖淘宝的diamond配置管理系统。
atlas:360开源的,属于proxy层方案,以前是有一些公司在用的,但是确实有一个很大的问题就是社区最新的维护都在5年前了。所以,现在用的公司基本也很少了。
sharding-jdbc:当当开源的,属于client层方案。确实之前用的还比较多一些,因为SQL语法支持也比较多,没有太多限制,而且目前推出到了2.0版本,支持分库分表、读写分离、分布式id生成、柔性事务(最大努力送达型事务、TCC事务)。而且确实之前使用的公司会比较多一些(这个在官网有登记使用的公司,可以看到从2017年一直到现在,是不少公司在用的),目前社区也还一直在开发和维护,还算是比较活跃,个人认为算是一个现在也可以选择的方案。
mycat:基于cobar改造的,属于proxy层方案,支持的功能非常完善,而且目前应该是非常火的而且不断流行的数据库中间件,社区很活跃,也有一些公司开始在用了。但是确实相比于sharding jdbc来说,年轻一些,经历的锤炼少一些。
所以综上所述,现在其实建议考量的,就是sharding-jdbc和mycat,这两个都可以去考虑使用。
sharding-jdbc这种client层方案的优点在于不用部署,运维成本低,不需要代理层的二次转发请求,性能很高,但是如果遇到升级啥的需要各个系统都重新升级版本再发布,各个系统都需要耦合sharding-jdbc的依赖;
mycat这种proxy层方案的缺点在于需要部署,自己及运维一套中间件,运维成本高,但是好处在于对于各个项目是透明的,如果遇到升级之类的都是自己中间件那里搞就行了。
通常来说,这两个方案其实都可以选用,但是我个人建议中小型公司选用sharding-jdbc,client层方案轻便,而且维护成本低,不需要额外增派人手,而且中小型公司系统复杂度会低一些,项目也没那么多;
但是中大型公司最好还是选用mycat这类proxy层方案,因为可能大公司系统和项目非常多,团队很大,人员充足,那么最好是专门弄个人来研究和维护mycat,然后大量项目直接透明使用即可。
我们,数据库中间件都是自研的,也用过proxy层,后来也用过client层
(3)你们具体是如何对数据库如何进行垂直拆分或水平拆分的?
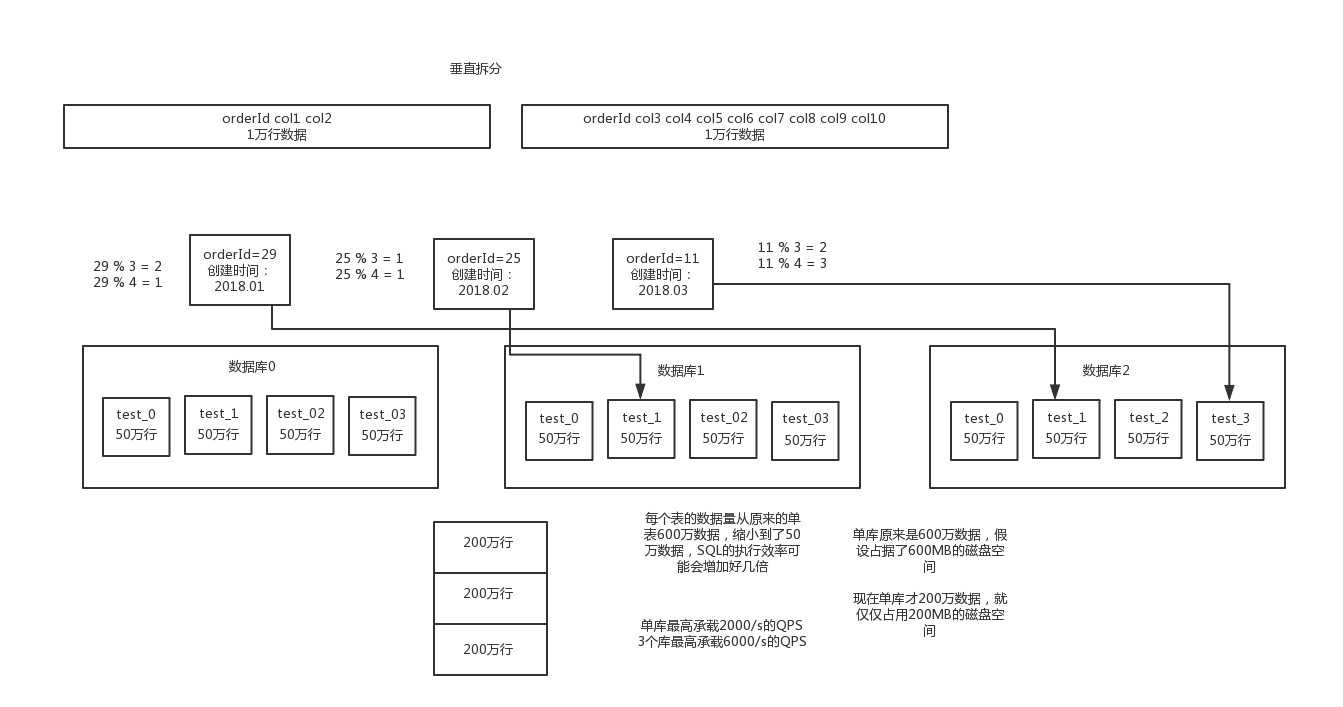
水平拆分的意思,就是把一个表的数据给弄到多个库的多个表里去,但是每个库的表结构都一样,只不过每个库表放的数据是不同的,所有库表的数据加起来就是全部数据。水平拆分的意义,就是将数据均匀放更多的库里,然后用多个库来抗更高的并发,还有就是用多个库的存储容量来进行扩容。
垂直拆分的意思,就是把一个有很多字段的表给拆分成多个表,或者是多个库上去。每个库表的结构都不一样,每个库表都包含部分字段。一般来说,会将较少的访问频率很高的字段放到一个表里去,然后将较多的访问频率很低的字段放到另外一个表里去。因为数据库是有缓存的,你访问频率高的行字段越少,就可以在缓存里缓存更多的行,性能就越好。这个一般在表层面做的较多一些。
这个其实挺常见的,不一定我说,大家很多同学可能自己都做过,把一个大表拆开,订单表、订单支付表、订单商品表。
还有表层面的拆分,就是分表,将一个表变成N个表,就是让每个表的数据量控制在一定范围内,保证SQL的性能。否则单表数据量越大,SQL性能就越差。一般是200万行左右,不要太多,但是也得看具体你怎么操作,也可能是500万,或者是100万。你的SQL越复杂,就最好让单表行数越少。
好了,无论是分库了还是分表了,上面说的那些数据库中间件都是可以支持的。就是基本上那些中间件可以做到你分库分表之后,中间件可以根据你指定的某个字段值,比如说userid,自动路由到对应的库上去,然后再自动路由到对应的表里去。
你就得考虑一下,你的项目里该如何分库分表?一般来说,垂直拆分,你可以在表层面来做,对一些字段特别多的表做一下拆分;水平拆分,你可以说是并发承载不了,或者是数据量太大,容量承载不了,你给拆了,按什么字段来拆,你自己想好;分表,你考虑一下,你如果哪怕是拆到每个库里去,并发和容量都ok了,但是每个库的表还是太大了,那么你就分表,将这个表分开,保证每个表的数据量并不是很大。
2、mysql分区的数据类型
而且这儿还有两种分库分表的方式,一种是按照range来分,就是每个库一段连续的数据,这个一般是按比如时间范围来的,但是这种一般较少用,因为很容易产生热点问题,大量的流量都打在最新的数据上了;或者是按照某个字段hash一下均匀分散,这个较为常用。
range来分,好处在于说,后面扩容的时候,就很容易,因为你只要预备好,给每个月都准备一个库就可以了,到了一个新的月份的时候,自然而然,就会写新的库了;缺点,但是大部分的请求,都是访问最新的数据。实际生产用range,要看场景,你的用户不是仅仅访问最新的数据,而是均匀的访问现在的数据以及历史的数据
hash分法,好处在于说,可以平均分配没给库的数据量和请求压力;坏处在于说扩容起来比较麻烦,会有一个数据迁移的这么一个过程
mysql数据库 数据分区的类型:
RANGE分区:基于属于一个给定连续区间的列值,把多行分配给分区。
(mysql5.5之前的版本只接收int类型的参数)
举例如下:
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
)
PARTITION BY RANGE (store_id) (
PARTITION p0 VALUES LESS THAN (6),
PARTITION p1 VALUES LESS THAN (11),
PARTITION p2 VALUES LESS THAN (16),
PARTITION p3 VALUES LESS THAN (21)
);
LIST分区:类似于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择。
(mysql5.5之前的版本只接收int类型的参数)
举例如下:
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
)
PARTITION BY LIST(store_id)
PARTITION pNorth VALUES IN (3,5,6,9,17),
PARTITION pEast VALUES IN (1,2,10,11,19,20),
PARTITION pWest VALUES IN (4,12,13,14,18),
PARTITION pCentral VALUES IN (7,8,15,16)
);
HASH分区:基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。这个函数可以包含MySQL 中有效的、产生非负整数值的任何表达式。
(mysql5.5之前的版本只接收int类型的参数)
举例如下:
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
)
PARTITION BY HASH(YEAR(hired))
PARTITIONS 4;
KEY 分区:类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL 服务器提供其自身的哈希函数。必须有一列或多列包含整数值。
举例如下:
CREATE TABLE tk (
col1 INT NOT NULL,
col2 CHAR(5),
col3 DATE
)
PARTITION BY LINEAR KEY (col1)
PARTITIONS 3;
mysql处理海量数据
主从同步:会带来数据冗余
1.“从”节点可以作为 备份节点
2. 主从同步 可以实现读写分离(mycat中间件)
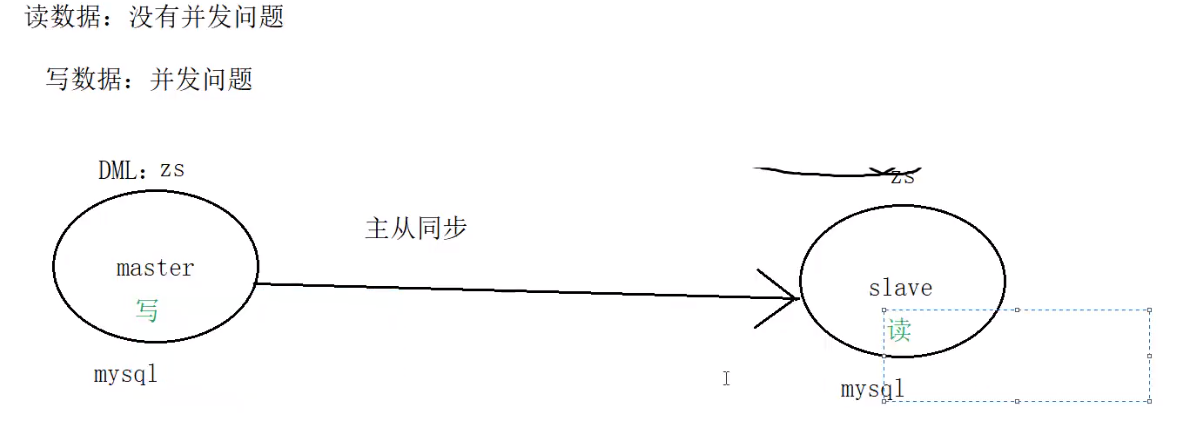
mysql中解决并发问题:读写分离
1.一般项目中, 读>>写
100002=10000读+2次
实现读写分离?中间件 mycat
mycat
1: 读写分离
2:分表分库(大量数据分成小的)
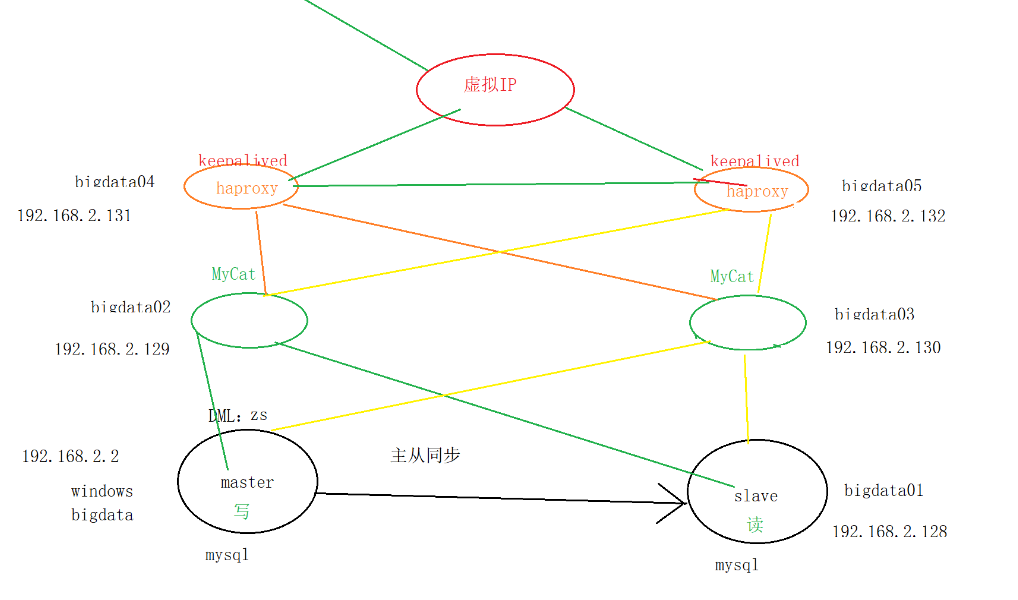
haproxy:搭建多个mycat集群
集群:防止单点故障
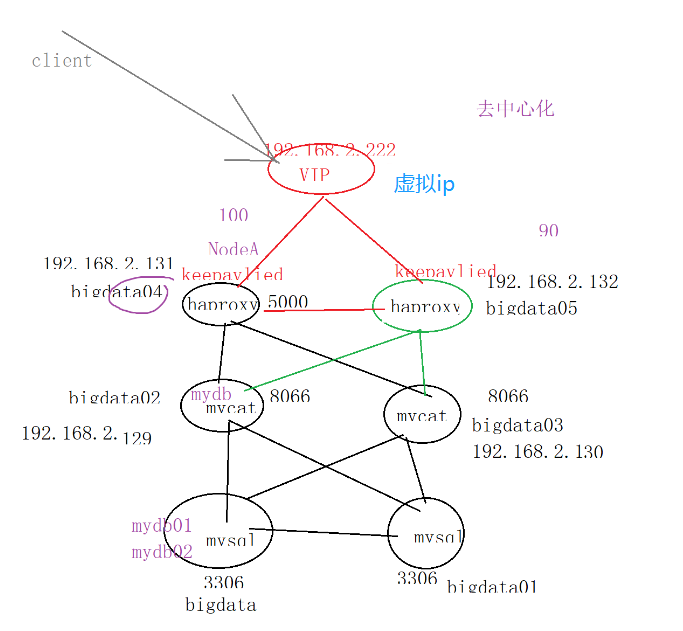
去中心化:
1.多个节点之间彼此发送 心跳 (感知对方是否还存活)
2.维护一个 VIP(虚拟ip)
6台=1windows +5台centos7
准备5centos:
(为了学习方便,先全部使用超级管理员root)
配置一个,克隆出其他的
克隆完毕后 需要处理:
1.内存
2.ip
vi /etc/sysconfig/network-scripts/ifcfg-ens33
删除网卡中的唯一标志符
3.hostname
hostnamectl set-hostname bigdata05
4.bigdata01/02/03/04修改映射
centos: vi /etc/hosts
windows: C:WindowsSystem32driversetc
增加6个计算机全部的映射
5.刷新网络
systemctl restart network
6.ssh
生成秘钥 ssh-keygen -t rsa
私钥发给自己 ssh-copy-id localhost
公钥发给别人 ssh-copy-id 别人的ip
一、主从同步(详细看上一篇博客)
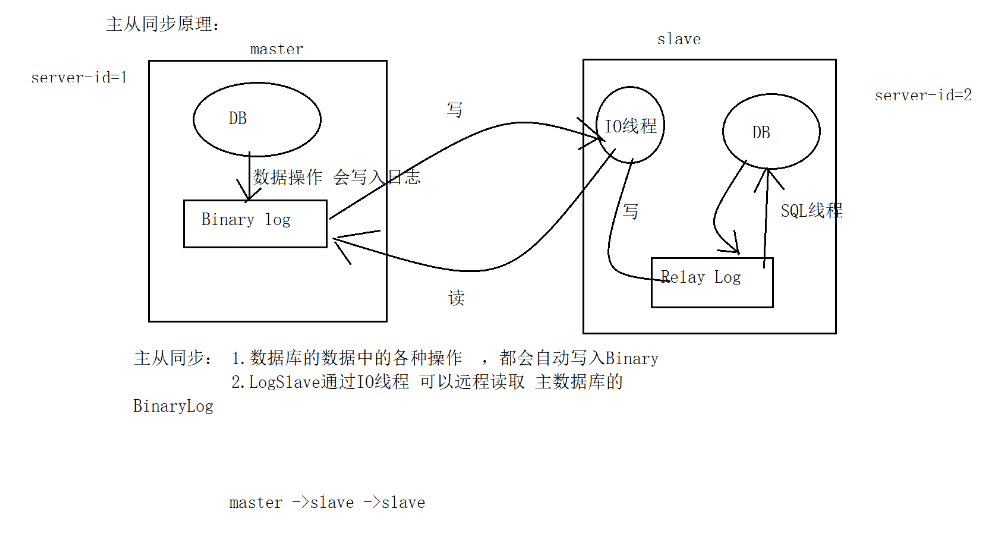
windows - bigdata01
windows主
bigdata01:从
centos7关闭防火墙:
systemctl stop firewalld
systemctl disable firewalld
为了学习方便,在学习时,临时把防火墙关闭 (开放端口)
处理mysql权限:开放(windows/centos)远程访问MySql的权限:
登录Mysql管理员账户:
grant all privileges on *.* to 'root'@'192.168.2.%' identified by 'root' with grant option ;
flush privileges;本地的mysql可以被: 192.168.2.% ,root/root 访问
1.配置master(windows)
my.ini
[mysqld]
#master的id
server-id=1
#binary log
log-bin="C:/Program Files/MySQL/data/mysql-bin"
#异常信息的日志
log-error="C:/Program Files/MySQL/data/mysql-error"
# The TCP/IP Port the MySQL Server will listen on
port=3306
#Path to installation directory. All paths are usually resolved relative to this.
#MySQL根路径
basedir="C:/Program Files/MySQL/MySQL Server 5.5/"
#指定需要同步哪些数据库(默认全部数据库)
#binlog-do-bo=mydb01
#指定需要 不同步哪些数据库(排除)
binlog-ignore-db=mysql
#Path to the database root
datadir="C:/ProgramData/MySQL/MySQL Server 5.5/Data/"
2.配置slave(centos)
/etc/my.cnf
[mysqld]
server-id=2
log-bin=mysql-bin
replicate-do-db=mydb01
replicate-do-db=mydb02
windwos/centos需要在配置完毕后 重启服务
3.设置主从关系 :
slave ->master
显示master的位置
通过以下命令查看master的信息:
(windows)show master status;
File: mysql-bin.000001
Position:107
salve:指定master (slave指定master作为自己的老大)
(bigdata01,mysql命令)
在mysql中写:
change master to
master_host='192.168.2.2',
master_user='root',
master_password='root',
master_port=3306,
master_log_file='mysql-bin.000001',
master_log_pos=107;
验证主从同步:
准备数据:
create database mydb02;
create database mydb01;
开启slave (bigdata01,mysql命令):
start slave ;
验证主从是否成功执行:
show slave status G,必须保证以下两个为yes:
Slave_IO_Running:
Slave_SQL_Running:
如果有问题,查看日志:Last_IO_Errno/Last_SQL_Errno
本次提示:master和slave有相同的server-id
当前主 windows: 5.5.62
centos7: 5.5.58
通过命令行 指定:
server-id=2 (永久设置)
临时设置: bigdata01(slave) : set global server_id=2;
再次尝试:
stop slave ;
start slave;
尝试在master中mydb01/mydb02中创建表、插入数据,然后测试slave中是否有相应的表和数据。
如果遇到以下错误:出错的原因:之前已经搭建/启动主从
1.ERROR 1201 :could not initlze master info structure ...
数据库之前已经设置过了主从同步
解决:关闭并重置slave(在slave中sql命令中)
slave stop
reset slave ;
change master to ....(检查最新的 File、Position)
2.ERROR 1198 :..... RUN STOP SLAVE ..
数据库之前已经设置过了主从同步,并且也已经开启了主从同步
stop slave ;
change master to ....(检查最新的 File、Position)
启动Mysql:
/etc/init.d/mysql start
chkconfig mysql on
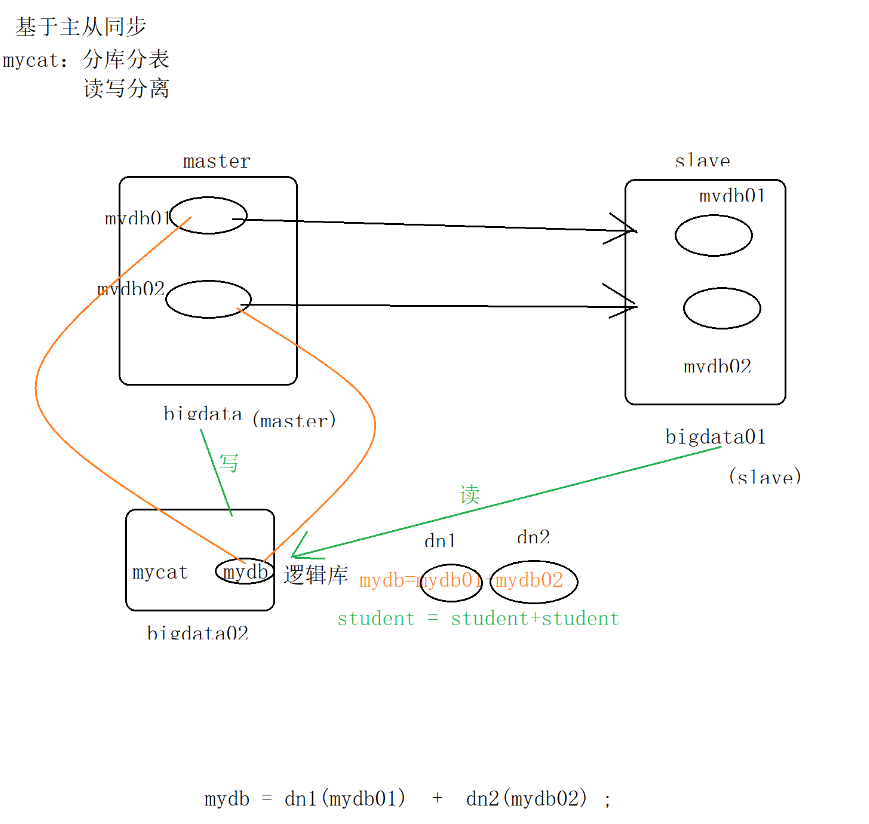
二.mycat:
1.分库分表:
mycat研究对象:水平拆分:订单数据( 订单数据1 订单数据2 订单数据3)
了解:(微服务)垂直拆分:系统 (订单数据库、 用户数据库)
2.读写分离:读-》服务器节点(数据库)
写-》服务器节点(数据库)
安装mycat: 中国人开发的
上传、解压缩
配置(/usr/local/mycat/conf)
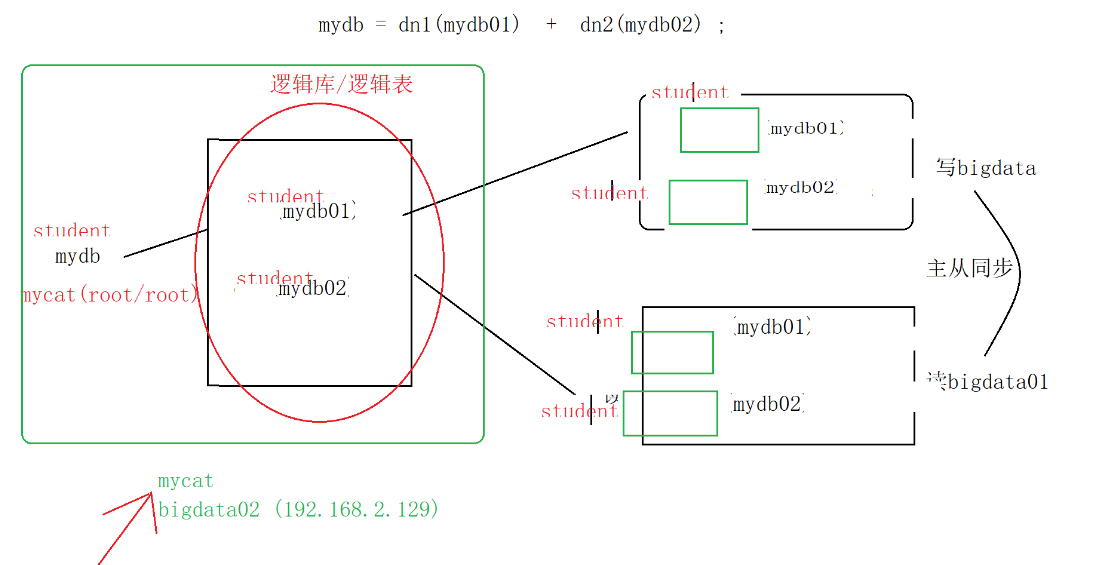
1.server.xml(配置访问Mycat的用户,schemas代表逻辑库)
<user name="root" defaultAccount="true">
<property name="password">root</property>
<!-- 逻辑库-->
<property name="schemas">mydb</property>
</user>
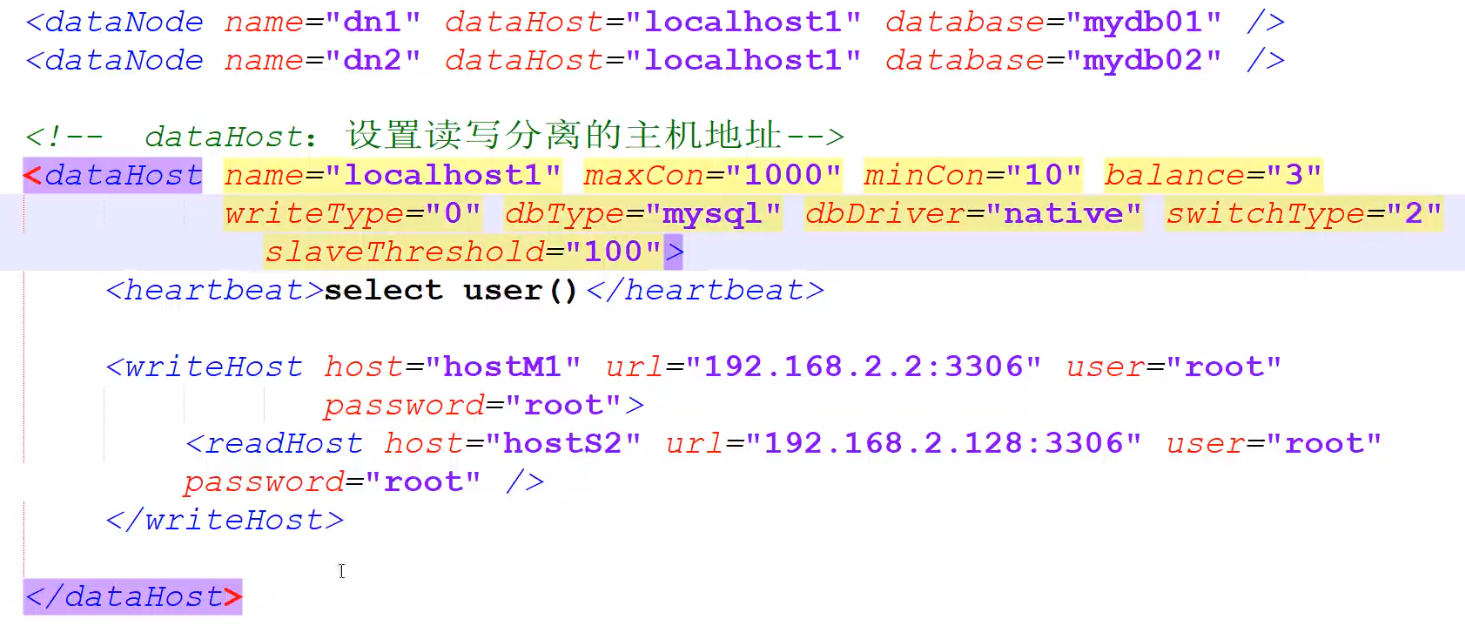
2.schema.xml(读写分离、分库分表)

读写分离的写:主从同步的Master
读写分离的读:主从同步的Slave
配置文件中的dataHost :
balance:读请求的负载均衡
0 :不开启读写分离,所有的读操作 都发送到writehost中
1:全部的readhost和stand by writehost(多个写节点待命的那些)都参与 读操作的负责均衡
2:读请求 随机发送给readhost、writehost
3:读请求随机发送给writehost中的readhost (writehost不参与读请求) --推荐(一般用的是1和3)
writeType:写请求的负载均衡
0:写请求先发送给schema.xml中的第一个writehost。当第一个writehost挂掉,再自动切换到下一个writehost中 。切换的记录 会被记录在 conf/dnindex.properties --推荐
1:写请求随机发送到所有的wirtehost中
switchType: 是否允许 “读操作”在readhost和writehost上自动切换(解决延迟问题:当从readhost中读取数据中 出现网络延迟等问题时,自动从writehost中读数据)
-1:不许
1:默认,允许
2:根据“主从同步的状态” 自动选择是否 切换。
主从之间 会持续发送心跳。 当心跳检测机制发现了IO延迟,则readhost自动切换到writehost; 否则不切换。 必须将心跳设置 show slave status --推荐

3.rule.xml:分库分表的拆分规则(平均拆分)
mydb->mydb01+mydb02
把第2步中的rule改成mod-long



准备数据:
确保bigdata、bigdata01中都存在mydb01和mydb02
表:student
create table student(id int(4) ,name varchar(10) ) ;验证读写分离:
写:bigdata(master)
验证逻辑:
向mycat中插入数据 -> 是否会 自动写入 writehost(bigdata)
具体步骤:
开启mycat
bin/mycat start
查看状态
bin/mycat status
登录mycat
提示:
不能直接在mycat所在节点 登录:mysql -uroot -proot -P8066 (这里虽然是mysql命令,但是还是mycat)
需要借助一个 已经安装了mysql软件的 计算机上 远程操作mysql:
在windows上远程连接 bigdata02上的 Mycat :mysql -uroot -proot -h192.168.2.129 -P8066
show database;查看一下mydb在不在来验证是否登陆成功
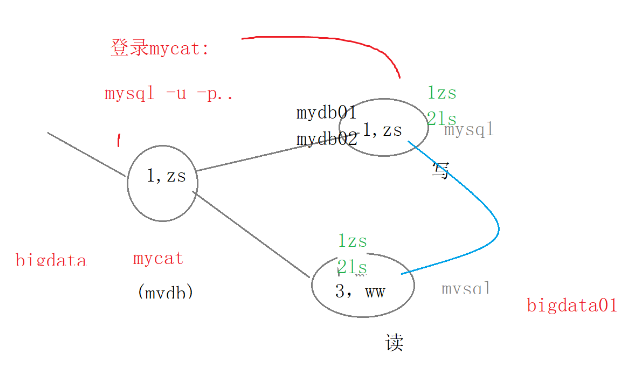
向mycat中插入数据
insert into student(id,name) values(1,'zs');//sql92语法,严格验证:从bigdata(master)中查看数据是否写入
读:bigdata01(slave)
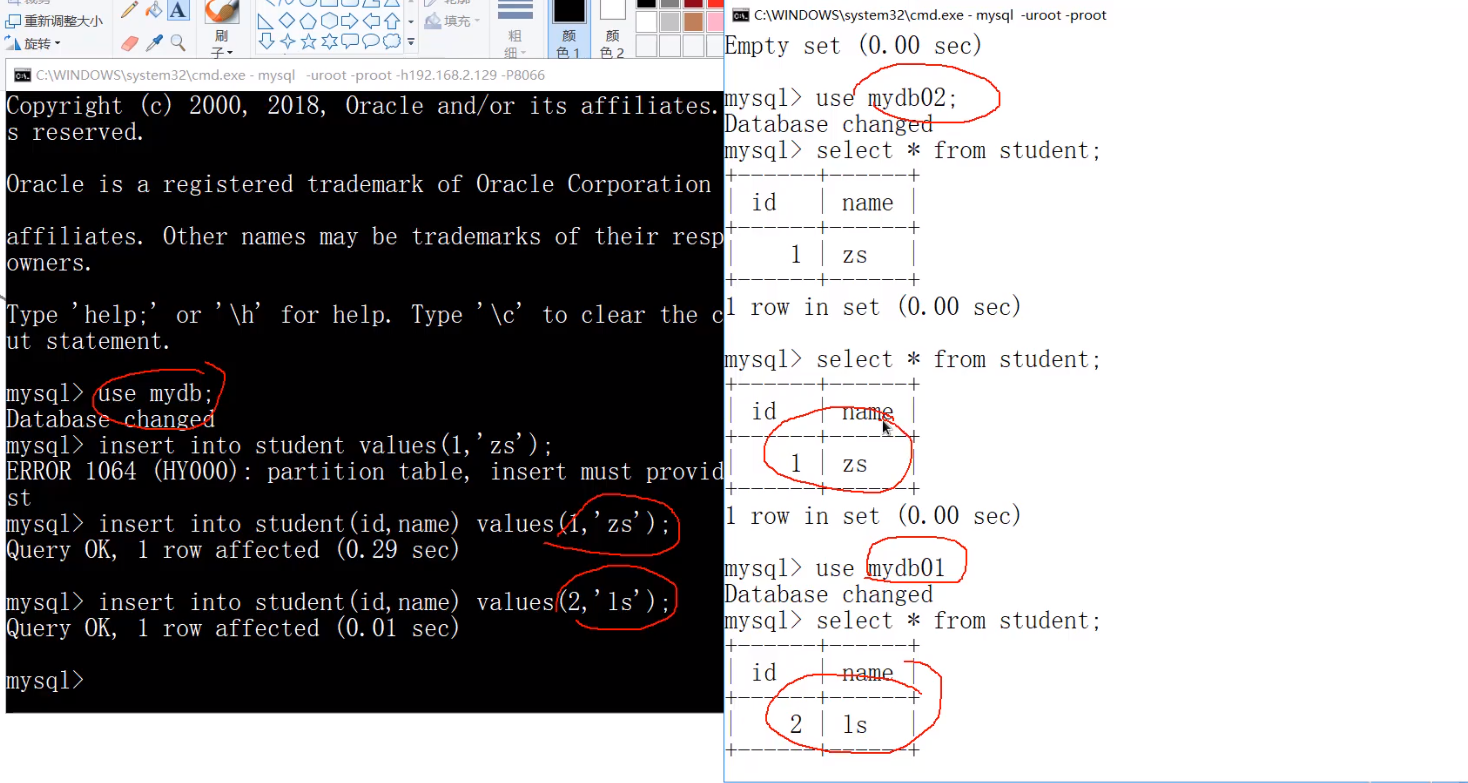
上图左边是mycat逻辑库逻辑表,右图是主节点(master),可以看到,已经分库分表成功。
验证:bigdata01(slave)中查看是否 读:
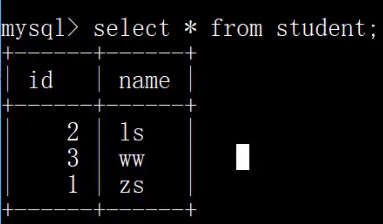
在bigdata01中插入数据
use mydb01;
insert into student values(3,'ww');在mycat中读:
常见bug:
如果无法正常实现mycat功能,调试:
日志:
mycat/logs :
mycat.log:执行出错
wrapper.log:启动错误
Invalid DataSource:0 ,常见解决方案:防火墙、IP、端口,权限问题:临时开放全部的权限
操作Mycat: 和sql 92基本一致 ; 操作端口8066 ;使用mycat的方法 和mysql基本一致
管理端口9066
SQL92:语法严格的SQL
insert into student(id,name) values(1,zs) ;
SQL99:语法较为宽松
insert into student values(1,zs) ;
开放mysql的一切权限(root)
mycat-> a ,b ,在a,b计算机中的Mysql中通过以下执行 开放权限(root)
mycat-> bigdata/bigdata01
use mysql ;
update user set
`Select_priv` = 'Y', `Insert_priv` = 'Y',`Update_priv` = 'Y',`Delete_priv` = 'Y',
`Create_priv` = 'Y',`Drop_priv` = 'Y',`Reload_priv` = 'Y',`Shutdown_priv` = 'Y',
`Process_priv` = 'Y',`File_priv` = 'Y',`Grant_priv` = 'Y',`References_priv` = 'Y',
`Index_priv` = 'Y',`Alter_priv` = 'Y',`Show_db_priv` = 'Y',`Super_priv` = 'Y',
`Create_tmp_table_priv` = 'Y',`Lock_tables_priv` = 'Y',`Execute_priv` = 'Y',
`Repl_slave_priv` = 'Y',`Repl_client_priv` = 'Y',`Create_view_priv` = 'Y',
`Show_view_priv` = 'Y',`Create_routine_priv` = 'Y',`Alter_routine_priv` = 'Y',
`Create_user_priv` = 'Y',`Event_priv` = 'Y',`Trigger_priv` = 'Y',`Create_tablespace_priv` = 'Y'
where user="root" ;flush privileges;
三、搭mycat集群,保证高可用
---
在bigta03上再次搭建mycat,和bigdat02组成mycat集群
启动bigdata02/03上的mycat
--
通过haproxy 整合多个mycat:
在bigdata04搭建haproxy,用于整合2个mycat
在线安装haproxy:
查看可用的haproxy版本:yum list | grep haproxy
haproxy.x86_64
在线安装:
yum -y install haproxy.x86_64
设置: 用户名是haproxy
chown -R haproxy:haproxy /etc/haproxy/
配置文件(1.日志)
vi /etc/rsyslog.conf
将以下2个指令的注释释放:
$ModLoad imudp
$UDPServerRun 514
设置日志文件的路径:
local2.* 日志的保存文件
重启日志服务:
systemctl restart rsyslog.service
配置文件(2.haproxy)
yum安装后的配置文件默认etc
vi /etc/haproxy/haproxy.cfg (里面的日志文件名 和刚才配置的保持一致)
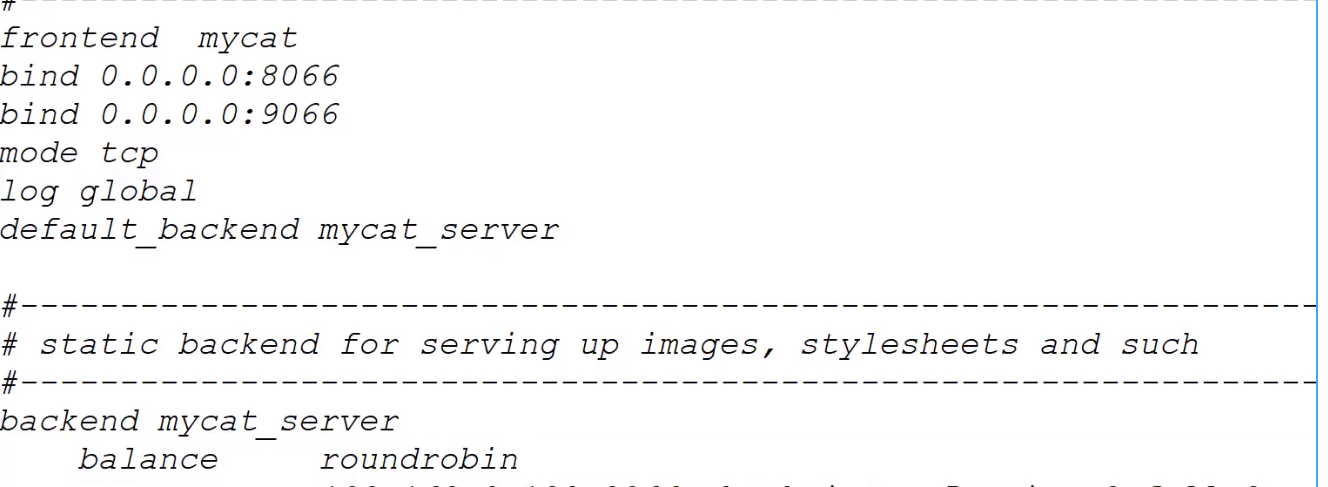
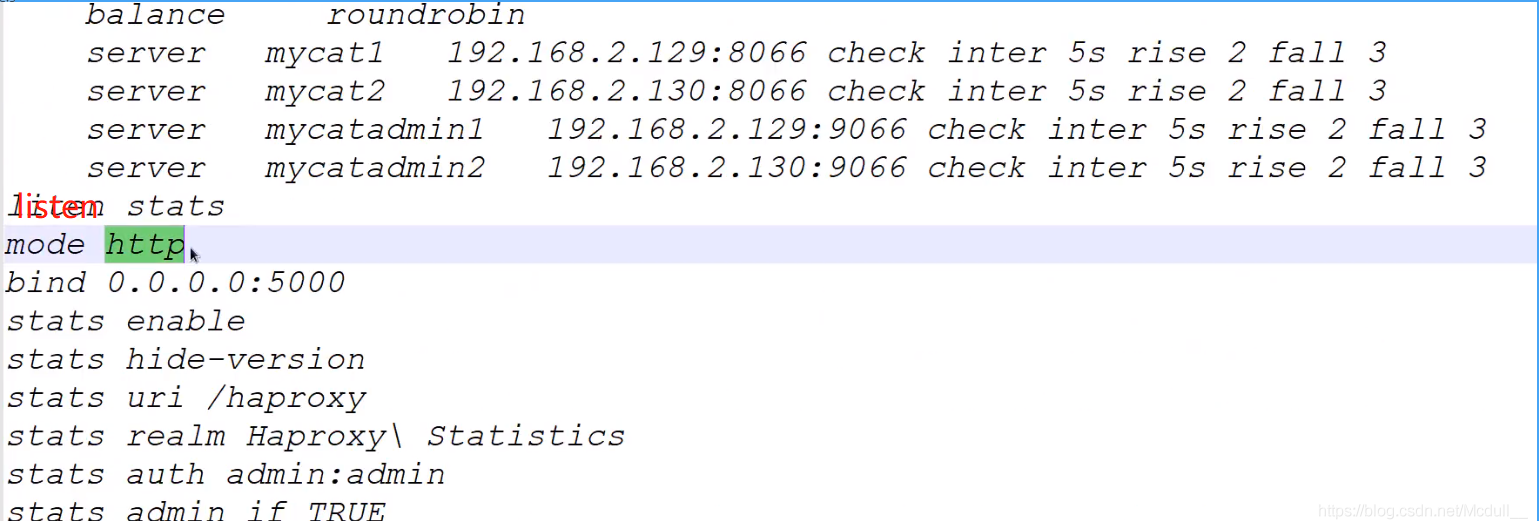
启动并使用haproxy:
启动
systemctl start haproxy.service
systemctl stop haproxy.service
systemctl status haproxy.service
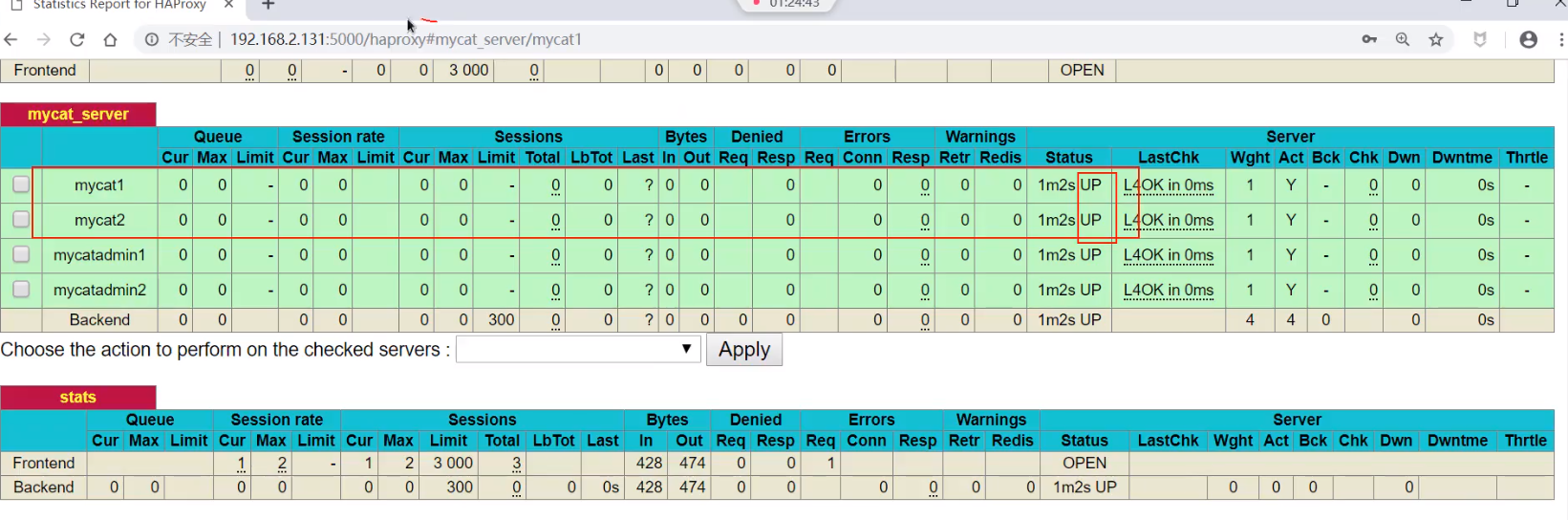
访问web界面的地址: /haproxy admin/admin
bug: cannot bind socket :网络
权限设置 setenforce 0 关闭
时间同步指令:
yum -y install npt ntpdate
ntpdate cn.pool.ntp.org
hwclock --systoch
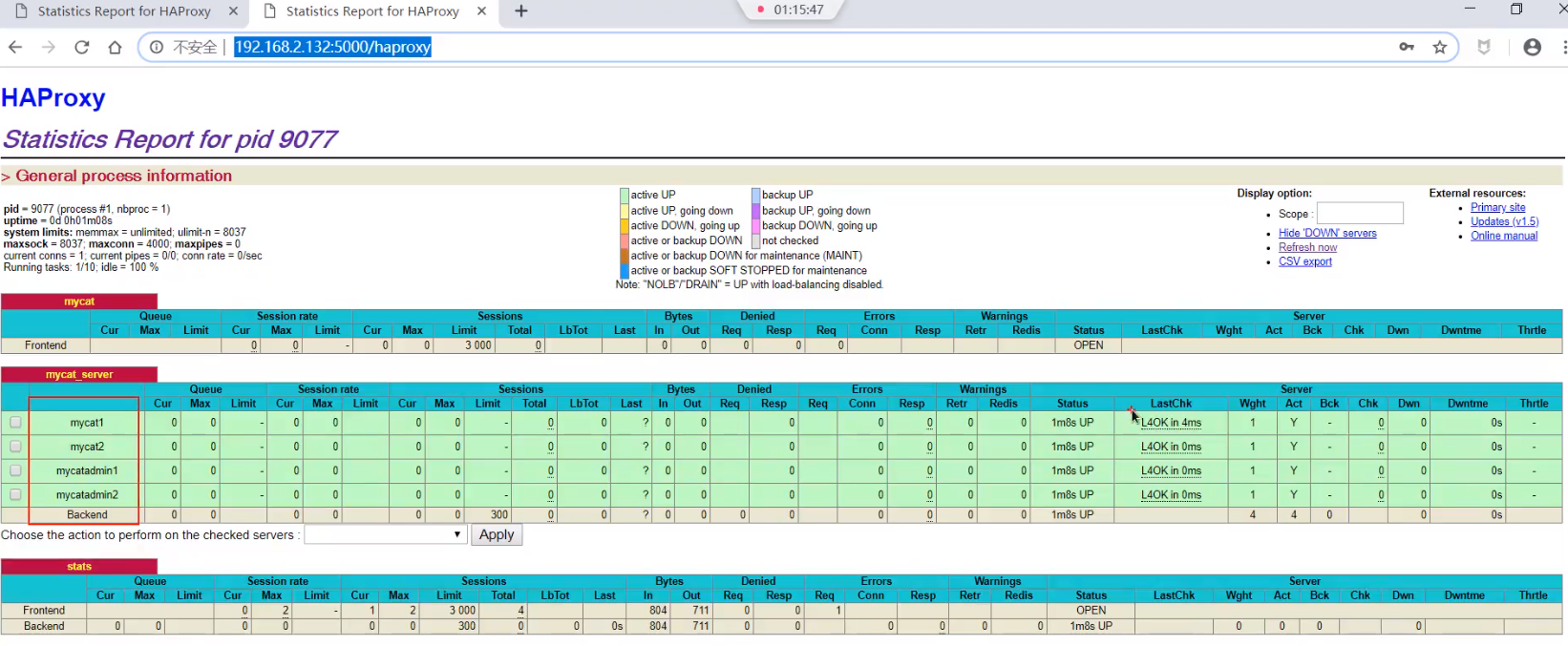
以上配置完毕,再用同样的方法 增加另一个haproxy (bigdata05 )(为了防止单点故障)
四、keepalived心跳机制(实现去中心化)
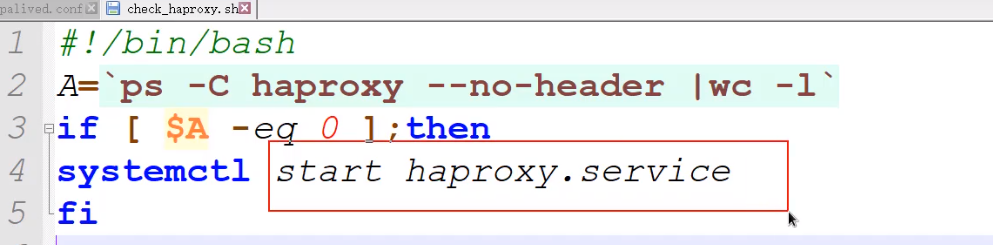
在线安装
yum list | grep keepalived
yum -y install keepalived.x86_64
配置
文件/etc/keepalived/keepalived.conf
/etc/check_haproxy.sh


脚本:
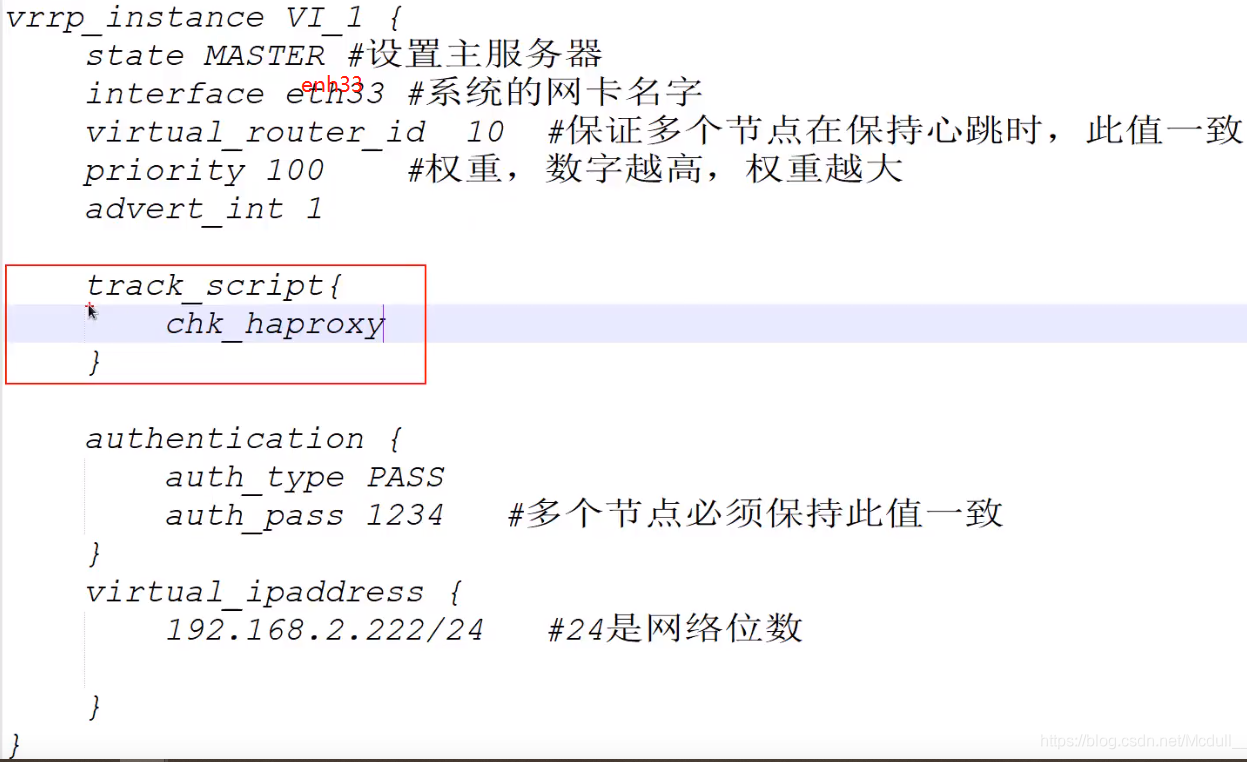
搭建keepalived集群:
用同样的办法,在bigdata05上配置第二个keepalived。 在bigdata05修改以下:
router_id :NodeB
priority :90 # 权重
使用keepalived:
启动
systemctl start keepalived.service
systemctl restart keepalived.service
systemctl enable keepalived.service
systemctl stop keepalived.service
systemctl status keepalived.service
分别在配置了keepalived的计算机上(bigdata04和bigdata05) 通过ip a 查看ip情况
bigdata04:权重是100 所以抢到了

bigdata05:权重是90 所以没抢到
当左边挂掉时,右边抢到了 (实现高可用)
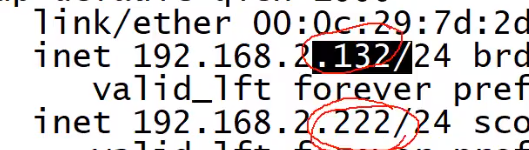
当左边又复活了,左边又抢回来了
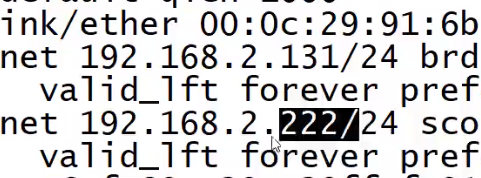
五、整个过程试验:
过程:192.168.2.222 ->VIP (keepalived) -> haproxy ->MyCat1/MyCat2 ->MySQL主从..
保证以上都开着
访问mycat:
windows:
mysql -uroot -proot -h192.168.2.222 -P8066

演示 将bigdata04这台机子挂掉 :

最后
以上就是直率铃铛最近收集整理的关于高性能高可用MySQL(主从同步,读写分离,分库分表,去中心化,虚拟IP,心跳机制)高性能高可用MySQL(主从同步,读写分离,分库分表,去中心化,虚拟IP,心跳机制)1、面试题2、mysql分区的数据类型一、主从同步(详细看上一篇博客) 二.mycat:的全部内容,更多相关高性能高可用MySQL(主从同步,读写分离,分库分表,去中心化,虚拟IP,心跳机制)高性能高可用MySQL(主从同步,读写分离,分库分表,去中心化,虚拟IP,心跳机制)1、面试题2、mysql分区的数据类型一、主从同步(详细看上一篇博客)内容请搜索靠谱客的其他文章。








发表评论 取消回复