如何实现负载均衡
为了系统负载的均衡,主要通过如下三种手段:
(1)当一个进程要加入runqueue时,选择负载最轻的cpu上的runqueue
(2)当前CPU的runqueue为空时,主动拉取其他runqueue上的进程来运行
(3)周期计算各个CPU上的负载情况,在必要的时候迁移进程
具体的场景,CFS调度器负载均衡发生在如下的一些路径上:
1.当前进程离开runqueue,进入睡眠,而对应的runqueue中已无进程可运行时,触发负载均衡,试图从别的run_queue中pull一个进程过来运行。
static struct task_struct *
pick_next_task_fair(struct rq *rq, struct task_struct *prev)
{
......
if (!cfs_rq->nr_running)
goto idle;
......
idle:
new_tasks = idle_balance(rq);
/*
* Because idle_balance() releases (and re-acquires) rq->lock, it is
* possible for any higher priority task to appear. In that case we
* must re-start the pick_next_entity() loop.
*/
if (new_tasks < 0)
return RETRY_TASK;
if (new_tasks > 0)
goto again;
return NULL;
}
}
这条内核路径上的负载均衡主入口为idle_balance函数,我们在后面进行讲解。
2.周期调度器scheduler_tick在执行时会判断负载情况,如有必要会执行负载均衡操作。
void scheduler_tick(void)
{
int cpu = smp_processor_id();
struct rq *rq = cpu_rq(cpu);
struct task_struct *curr = rq->curr;
sched_clock_tick();
raw_spin_lock(&rq->lock);
update_rq_clock(rq);
curr->sched_class->task_tick(rq, curr, 0);
update_cpu_load_active(rq);
raw_spin_unlock(&rq->lock);
perf_event_task_tick();
#ifdef CONFIG_SMP
rq->idle_balance = idle_cpu(cpu);
trigger_load_balance(rq);
#endif
rq_last_tick_reset(rq);
}
这条内核路径上的负载均衡主入口为trigger_load_balance函数,我们同样在后面进行讲解。
3.fork创建进程时/exec运行进程时
do_fork–>wake_up_new_task->select_task_rq:
void wake_up_new_task(struct task_struct *p)
{
unsigned long flags;
struct rq *rq;
raw_spin_lock_irqsave(&p->pi_lock, flags);
#ifdef CONFIG_SMP
/*
* Fork balancing, do it here and not earlier because:
* - cpus_allowed can change in the fork path
* - any previously selected cpu might disappear through hotplug
*/
set_task_cpu(p, select_task_rq(p, task_cpu(p), SD_BALANCE_FORK, 0)); //子进程重新选择runqueue和cpu,相当于进行了一次负载均衡处理
#endif
/* Initialize new task's runnable average */
init_task_runnable_average(p); //依据权重初始化子进程的时间片和负载贡献
rq = __task_rq_lock(p);
activate_task(rq, p, 0); //把子进程加入到runqueue,这是该函数的关键核心
p->on_rq = TASK_ON_RQ_QUEUED;
trace_sched_wakeup_new(p, true);
check_preempt_curr(rq, p, WF_FORK);
#ifdef CONFIG_SMP
if (p->sched_class->task_woken)
p->sched_class->task_woken(rq, p);
#endif
task_rq_unlock(rq, p, &flags);
}
select_task_rq这条语句就是重新根据负载选择runqueue和CPU的。
4.try_to_wake_up唤醒进程时
static int
try_to_wake_up(struct task_struct *p, unsigned int state, int wake_flags)
{
......
p->sched_contributes_to_load = !!task_contributes_to_load(p);
p->state = TASK_WAKING;
if (p->sched_class->task_waking)
p->sched_class->task_waking(p);
cpu = select_task_rq(p, p->wake_cpu, SD_BALANCE_WAKE, wake_flags);
if (task_cpu(p) != cpu) {
wake_flags |= WF_MIGRATED;
set_task_cpu(p, cpu);
}
......
}
唤醒一个进程时根据select_task_rq来进行选择一个负载最轻的CPU去运行,这也就是进行了负载均衡的处理
调度域
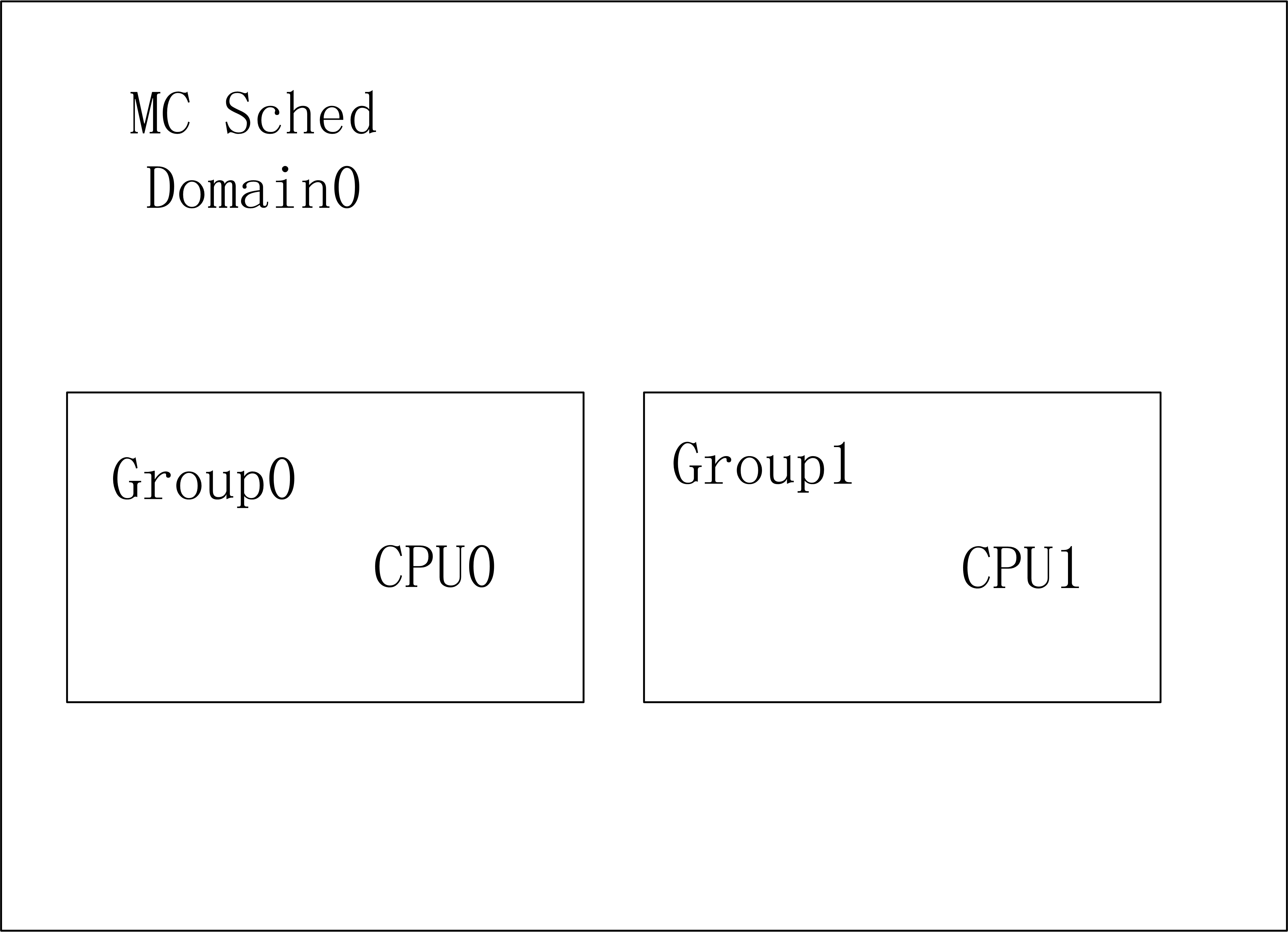
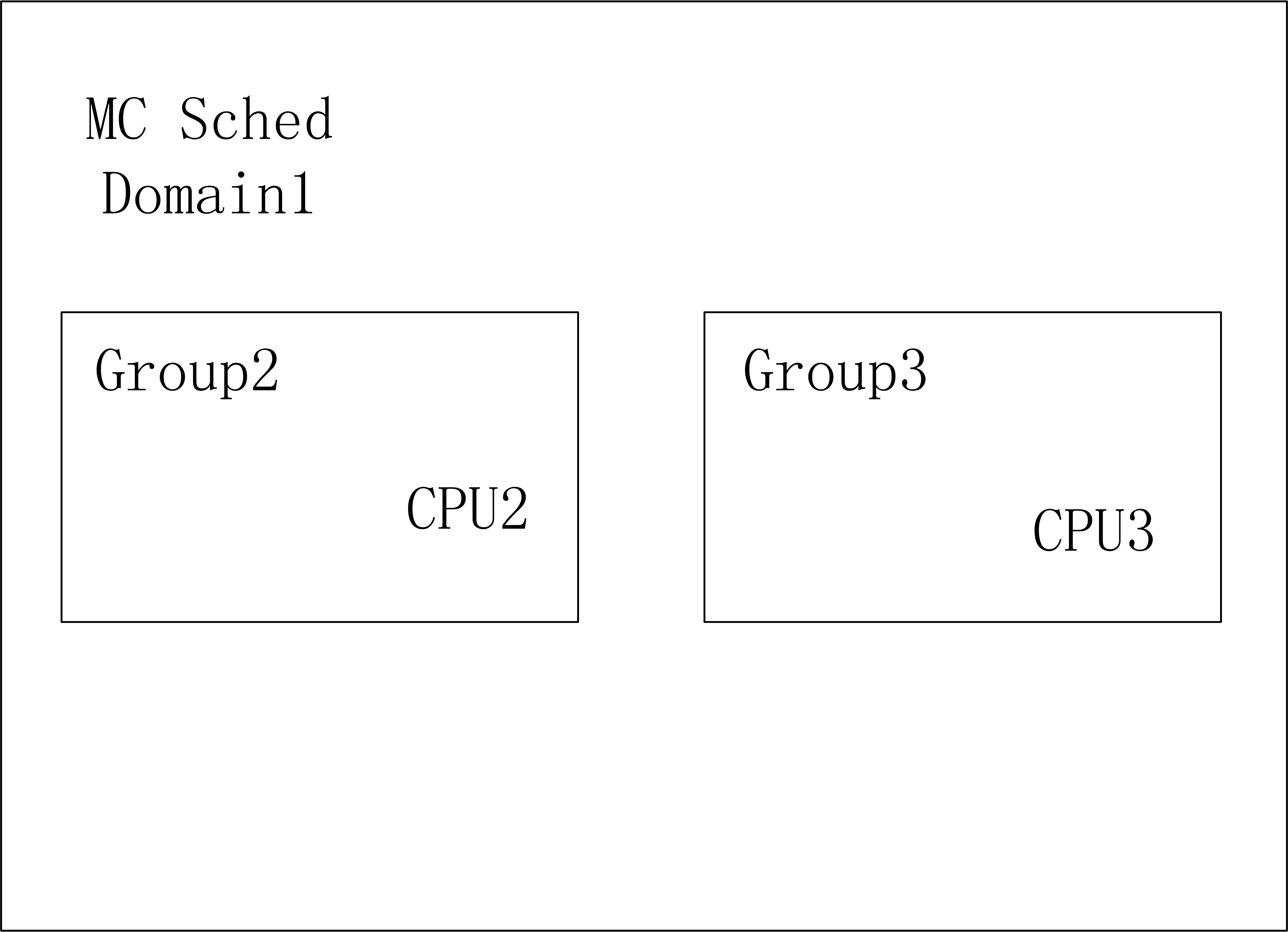
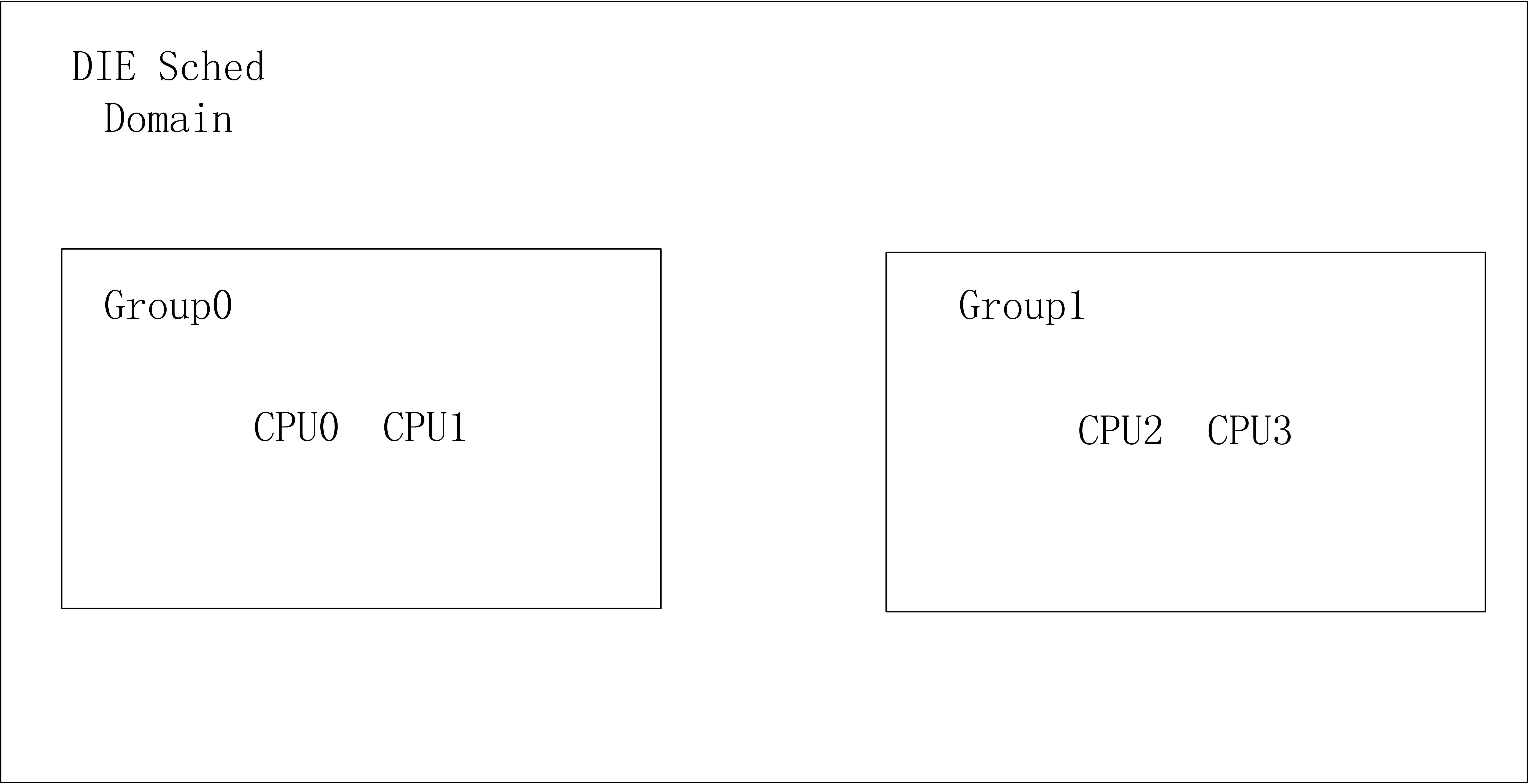
对于现代的多核心CPU,如何发挥系统多核心的优势,又能够节省功耗,是一个很关键的问题,为了做到多核心之间的负载均衡而引入调度域的概念。我们知道一个多核心的soc片上系统,内部结构是很复杂的,内核采用CPU拓扑结构来描述一个SOC的架构。内核使用调度域来描述CPU之间的层次关系,对于低级别的调度域来说,CPU之间的负载均衡处理开销比较小,而对于越高级别的调度域,其负载均衡的开销就越大。比如一个4核心的SOC,两个核心是一个cluster,共享L2 cache,那么每个cluster可以认为是一个MC调度域,每个MC调度域中有两个调度组,每个调度组中只有一个CPU。而整个SOC可以认为是高一级别的DIE调度域,其中有两个调度组,cluster0属于一个调度组,cluster1属于另一个调度组。跨cluster的负载均衡是需要清除L2 cache的,开销是很大的,因此SOC级别的DIE调度域
进行负载均衡的开销会更大一些。
- 低层MC调度域
- 高层DIE调度域
负载均衡算法分析
一个调度域中的负载是否均衡是通过比较各个调度组之间的平均负载来衡量的。调度组平均负载的计算方法:内核中定义单个CPU的最大capacity为1024,针对不同的调度组,可能包含有不同数量和能力的CPU,因此组内的capacity也是不同的。内核计算平均负载公式:
avg_load = (group_load * SCHED_CAPACITY_SCALE) / group_capacity;
SCHED_CAPACITY_SCALE大小为1024。group_load是调度组内各个CPU的cpu_load之和,cpu_load的计算是基于PELT章节介绍的runqueue中的runnable_load负载来完成的。内核引入了一个加权系数delta。为了防止单个CPU负载曲线的波动过大,内核引用该公式计算CPU负载,加入历史负载来计算,delta值越大,历史负载对当前cpu_load的影响越大,也就越不容易产生波动。计算公式如下:
cpu_load=(previous_runnable_load * (delta-1) + curr_runnable_load) / delta
各个调度组的平均负载计算和PELT中介绍的负载计算比较,可以看出是多了一个参量的,就是CPU的capacity能力值,PELT仅仅是以调度实体或者进程为考量的,而不会考虑当前CPU的能力。系统在周期调度时更新上面对应的负载值,进而进行负载均衡的处理。
迁移一个进程的代价是对cache的刷新代价,当进程在cache能够共享的CPU之间进行迁移时,那么付出的代价就会低一些,如果进程在cache独立的CPU之间进行迁移,那么付出的代价就大一些,通过调节上述delta值可以来表示这种迁移的阻力。
代码详解
- select_task_rq
这个函数是选择一个目标rq的过程,其实就是为了负载均衡处理。
static inline
int select_task_rq(struct task_struct *p, int cpu, int sd_flags, int wake_flags)
{
if (p->nr_cpus_allowed > 1)
cpu = p->sched_class->select_task_rq(p, cpu, sd_flags, wake_flags); //如果当前进程允许被在多个CPU上运行,那么就执行对应调度类的select_task_rq回调
/*
* In order not to call set_task_cpu() on a blocking task we need
* to rely on ttwu() to place the task on a valid ->cpus_allowed
* cpu.
*
* Since this is common to all placement strategies, this lives here.
*
* [ this allows ->select_task() to simply return task_cpu(p) and
* not worry about this generic constraint ]
*/
if (unlikely(!cpumask_test_cpu(cpu, tsk_cpus_allowed(p)) ||
!cpu_online(cpu)))
cpu = select_fallback_rq(task_cpu(p), p);
return cpu;
}
//CFS调度器对应的select_task_rq回调函数
static int
select_task_rq_fair(struct task_struct *p, int prev_cpu, int sd_flag, int wake_flags) //prev_cpu指上次该进程执行的CPU
{
struct sched_domain *tmp, *affine_sd = NULL, *sd = NULL;
int cpu = smp_processor_id(); //当前执行唤醒的CPU
int new_cpu = cpu;
int want_affine = 0;
int sync = wake_flags & WF_SYNC;
if (sd_flag & SD_BALANCE_WAKE)
want_affine = cpumask_test_cpu(cpu, tsk_cpus_allowed(p)); //判断wakeup CPU是否允许执行该进程
rcu_read_lock();
for_each_domain(cpu, tmp) { //自下至上遍历调度域
if (!(tmp->flags & SD_LOAD_BALANCE))
continue;
/*
* If both cpu and prev_cpu are part of this domain,
* cpu is a valid SD_WAKE_AFFINE target.
*/
if (want_affine && (tmp->flags & SD_WAKE_AFFINE) &&
cpumask_test_cpu(prev_cpu, sched_domain_span(tmp))) { //如果当前执行唤醒的CPU和进程上次运行的CPU在同一个调度域,找到该调度域
affine_sd = tmp;
break;
}
if (tmp->flags & sd_flag)
sd = tmp;
}
if (affine_sd && cpu != prev_cpu && wake_affine(affine_sd, p, sync)) //会计算负载,并判断wakeup CPU加上进程负载后与prev CPU的大小
prev_cpu = cpu; //如果wakeup CPU + 进程load < prev CPU,优先使用wakeup CPU
if (sd_flag & SD_BALANCE_WAKE) {
new_cpu = select_idle_sibling(p, prev_cpu); //自上而下遍历调度域,优先使用找到的idle CPU
goto unlock;
}
while (sd) { //处理没有设置SD_BALANCE_WAKE的情况,查找相同sd_flag的最空闲CPU来运行
struct sched_group *group;
int weight;
if (!(sd->flags & sd_flag)) {
sd = sd->child;
continue;
}
group = find_idlest_group(sd, p, cpu, sd_flag);
if (!group) {
sd = sd->child;
continue;
}
new_cpu = find_idlest_cpu(group, p, cpu);
if (new_cpu == -1 || new_cpu == cpu) {
/* Now try balancing at a lower domain level of cpu */
sd = sd->child;
continue;
}
/* Now try balancing at a lower domain level of new_cpu */ //在更低一层调度域执行均衡
cpu = new_cpu;
weight = sd->span_weight;
sd = NULL;
for_each_domain(cpu, tmp) {
if (weight <= tmp->span_weight)
break;
if (tmp->flags & sd_flag)
sd = tmp;
}
/* while loop will break here if sd == NULL */
}
unlock:
rcu_read_unlock();
return new_cpu;
}
首先判断唤醒CPU是否允许执行该进程,然后判断唤醒CPU和上次执行CPU是否有在同一个调度域,如果有在同一个调度域,那就找到对应的调度域,在该调度域中更新两个CPU的负载情况,如果唤醒CPU加上进程负载后小于prev CPU,那么优先使用唤醒CPU运行进程。
-
idle_balance->load_balance
当前CPU没有进程要运行时,进行负载均衡处理。load_balance函数我们在下面讲解。 -
scheduler_tick->trigger_load_balance
void trigger_load_balance(struct rq *rq)
{
/* Don't need to rebalance while attached to NULL domain */
if (unlikely(on_null_domain(rq)))
return;
if (time_after_eq(jiffies, rq->next_balance))
raise_softirq(SCHED_SOFTIRQ);
#ifdef CONFIG_NO_HZ_COMMON
if (nohz_kick_needed(rq))
nohz_balancer_kick();
#endif
}
在时钟中断处理中,当检测到了下一次负载平衡的时间点时,就触发一个软中断,这个软中断是在CFS调度器初始化时就已经注册好了的:
__init void init_sched_fair_class(void)
{
#ifdef CONFIG_SMP
open_softirq(SCHED_SOFTIRQ, run_rebalance_domains);
#ifdef CONFIG_NO_HZ_COMMON
nohz.next_balance = jiffies;
zalloc_cpumask_var(&nohz.idle_cpus_mask, GFP_NOWAIT);
cpu_notifier(sched_ilb_notifier, 0);
#endif
#endif /* SMP */
}
下面看下实际运行的函数处理run_rebalance_domains->rebalance_domains:
static void rebalance_domains(struct rq *rq, enum cpu_idle_type idle)
{
int continue_balancing = 1;
int cpu = rq->cpu;
unsigned long interval;
struct sched_domain *sd;
/* Earliest time when we have to do rebalance again */
unsigned long next_balance = jiffies + 60*HZ;
int update_next_balance = 0;
int need_serialize, need_decay = 0;
u64 max_cost = 0;
update_blocked_averages(cpu);
rcu_read_lock();
for_each_domain(cpu, sd) { //循环遍历调度域,从低级别的MC调度域到高级别的DIE调度域,进行不同调度域中的负载均衡
/*
* Decay the newidle max times here because this is a regular
* visit to all the domains. Decay ~1% per second.
*/
if (time_after(jiffies, sd->next_decay_max_lb_cost)) {
sd->max_newidle_lb_cost =
(sd->max_newidle_lb_cost * 253) / 256;
sd->next_decay_max_lb_cost = jiffies + HZ;
need_decay = 1;
}
max_cost += sd->max_newidle_lb_cost;
if (!(sd->flags & SD_LOAD_BALANCE))
continue;
/*
* Stop the load balance at this level. There is another
* CPU in our sched group which is doing load balancing more
* actively.
*/
if (!continue_balancing) {
if (need_decay)
continue;
break;
}
interval = get_sd_balance_interval(sd, idle != CPU_IDLE); //获取调度域负载均衡的间隔
need_serialize = sd->flags & SD_SERIALIZE;
if (need_serialize) {
if (!spin_trylock(&balancing))
goto out;
}
if (time_after_eq(jiffies, sd->last_balance + interval)) { //检测是否到达调度域负载均衡的时间点
if (load_balance(cpu, rq, sd, idle, &continue_balancing)) { //进行调度域中的负载均衡处理
/*
* The LBF_DST_PINNED logic could have changed
* env->dst_cpu, so we can't know our idle
* state even if we migrated tasks. Update it.
*/
idle = idle_cpu(cpu) ? CPU_IDLE : CPU_NOT_IDLE;
}
sd->last_balance = jiffies; //处理完成后更新上次负载均衡的时间
interval = get_sd_balance_interval(sd, idle != CPU_IDLE); //获取下次执行负载均衡的间隔
}
if (need_serialize)
spin_unlock(&balancing);
out:
if (time_after(next_balance, sd->last_balance + interval)) { //最少要间隔1分钟时间才能执行下次负载均衡
next_balance = sd->last_balance + interval;
update_next_balance = 1;
}
}
if (need_decay) {
/*
* Ensure the rq-wide value also decays but keep it at a
* reasonable floor to avoid funnies with rq->avg_idle.
*/
rq->max_idle_balance_cost =
max((u64)sysctl_sched_migration_cost, max_cost);
}
rcu_read_unlock();
/*
* next_balance will be updated only when there is a need.
* When the cpu is attached to null domain for ex, it will not be
* updated.
*/
if (likely(update_next_balance))
rq->next_balance = next_balance; //更新下次负载均衡的时间点
}
这个函数主要执行如下的步骤:
1.按照当前CPU所在的调度域,从低级别到高级别依次进行遍历,优先进行低级别的负载均衡,因为这种级别的cache代价小。
2.load_balance依次检查当前CPU在调度域内是否已经负载均衡,如果负载不均衡,要执行均衡操作
3.每个调度域负载均衡结束后,要进行下次负载均衡时间的更新
load_balance是处理负载均衡的核心函数,它的处理单元是一个调度域,也就是sched domain。其中会包含对调度组的处理,这里不再细节讲述代码,而只文字介绍处理流程:
1.should_we_balance判断是否要在本CPU上执行负载均衡操作,这里会挑选一个idle CPU或者处于第一个调度组的第一个CPU(调度域中的第一个CPU)来执行负载均衡操作。如果不是对应的CPU,则直接跳出负载均衡的处理。
2.find_busiest_group找出对应调度域中的最繁忙的调度组,该函数中会调用update_sd_lb_stats更新当前调度域相关的调度状态数据,最繁忙调度组必须是除了本CPU所属的调度组之外的调度组,如果本调度组就是最繁忙的调度组,那么退出负载均衡的处理。
判断是否要进行负载均衡的评估方法如下:
(1)当前CPU处于idle,判断最繁忙组中的idle CPU数量多于当前组,说明当前组负载更重,不用做均衡。
(2)当前CPU不是idle,判断最繁忙组和当前组的avg_load,如果当前组的avg_load * 125% 大于最繁忙组,说明负载差距不大,不用做均衡。
(3)其余情况都需要做负载均衡处理。
(4)calculate_imbalance计算要迁移的负载。
3.find_busiest_queue找出最繁忙调度组中的最繁忙运行队列,也就是对应的CPU。这个最繁忙运行队列一定不能是本队列。
4.从最繁忙运行队列,迁移对应的imbalance_load到当前CPU运行队列上,完成负载均衡操作。
最后分享一下计算imbalance负载的方法,这里的imbalance负载实际上就是对应的group_load,按照前面介绍的公式:
delta_avg_load = (group_load * SCHED_CAPACITY_SCALE) / group_capacity;
我们可以通过delta_avg_load反推出来group_load的,真正迁移也就是通过根据进程的load最大迁移group_load大小的负载量。这里的delta_avg_load会计算最繁忙调度组和调度域的平均负载的差值,也会计算当前调度组和调度域平均负载的差值,两者取小来确定的。
最后
以上就是迷路悟空最近收集整理的关于CPU负载均衡的全部内容,更多相关CPU负载均衡内容请搜索靠谱客的其他文章。
![kernel 中断分析之四——中断申请 [下]前言__setup_irq——线程化处理__setup_irq——创建irq handler thread__setup_irq——添加new irqaction_setup_irq——收尾工作nested irq](https://www.shuijiaxian.com/files_image/reation/bcimg9.png)







发表评论 取消回复