Flink
- Flink概述
- 数据流与流计算
- Flink简介
- 应用场景
- Flink架构
- 安装配置
- 示例演示
- 单词统计示例
- 创建Flink工程
- 示例代码
- 基本概念
- DataStream和DataSet
- 数据类型
- 元组
- POJOs
- 基础数据类型
- 常规类
- 值
- Hadoop Writables
- 数据的操作
- 窗口的含义
- 有状态的流式处理
- DataStream编程
- 执行环境
- 输入流
- 数据流转换
- 输出流
- DataSet编程
- DataSet示例
- 输入源
- 转换操作
- 输出源
- 调试程序
- 本地执行环境
- 收集数据源和接收器
- Table API和SQL编程
- Table API和SQL的程序示例
- TableEnvironment
- 在表空间中注册表
- 注册表
- 注册TableSource
- 注册TableSink
- Table执行过程分析
- Flink Sql 执行流程
- Flink Table Api 执行流程
- 执行计划
- 流和批与Table集成编程
- 将DataStream或DataSet注册为表
- 将DataStream或DataSet转换为表
- 将表转换为DataStream或DataSet
- 将表转换为DataStream
- 将表转换为DataSet
- Mysql数据源
Flink概述
数据流与流计算
数据流是一串连续不断的数据的集合,就象水管里的水流,在水管的一端一点一点地供水,而在水管的另一端看到的是一股连续不断的水流。类似于人们对河流的理解本质上也就是流的概念,但是这条河没有开始也没有结束,数据流非常适合于离散的、没有开头或结尾的数据。例如,交通信号灯的数据是连续的,没有“开始”或“结束”,是连续的过程而不是分批发送的数据记录。通常情况下,数据流对于在生成连续数据流中以小尺寸(通常以KB字节为单位)发送数据的数据源类型是有用的。这包括各种各样的数据源,例如来自连接设备的遥测,客户访问的Web应用时生成的日志文件、电子商务交易或来自社交网络或地理LBS服务的信息等。
传统上,数据是分批移动的,批处理通常同时处理大量数据,具有较长时间的延迟。例如,该复制过程每24小时运行一次。虽然这可以是处理大量数据的有效方法,但它不适用于流式传输的数据,因为数据在处理时已经是旧的内容。
采用数据流是时间序列和随时间检测模式的最佳选择。例如,跟踪Web会话的时间。大多数物联网产生的数据非常适合数据流处理,包括交通传感器,健康传感器,交易日志和活动日志等都是数据流的理想选择。
流数据通常用于实时聚合和关联、过滤或采样。通过数据流,我们可以实时分析数据,并深入了解各种
行为,例如统计,服务器活动,设备地理位置或网站点击量等。
数据流整合技术的解决方案
- 金融机构跟踪市场变化,并可根据配置约束(例如达到特定股票价格时出售)调整客户组合的配置。
- 电网监控吞吐量并在达到某些阈值时生成警报。
- 新闻资讯APP从各种平台进行流式传输时,产生的点击记录,实时统计信息数据,以便它可以提供与受众人口相关的文章推荐。
- 电子商务站点以数据流传输点击记录,可以检查数据流中的异常行为,并在点击流显示异常行为时发出安全警报。
数据流带来的挑战
数据流是一种功能强大的工具,但在使用流数据源时,有一些常见的挑战。以下的列表显示了要规划数据流的一些事项:
- 可扩展性规划
- 数据持久性规划
- 如何在存储层和处理层中加入容错机制
数据流的管理工具
随着数据流的不断增长,出现了许多合适的大数据流解决方案。总结了一个列表,这些都是用于处理流数据的常用工具:
- Apache Kafka
Apache Kafka是一个分布式发布/订阅消息传递系统,它集成了应用程序和数据流处理。 - Apache Storm
Apache Storm是一个分布式实时计算系统。Storm用于分布式机器学习、实时分析处理,尤其是其具有超高数据处理的能力。 - Apache Flink
Apache Flink是一种数据流引擎,为数据流上的分布式计算提供了诸多便利。
Flink简介
Apache Flink 是一个开源的分布式流式处理框架,是新的流数据计算引擎,用java实现。Flink可以:
- 提供准确的结果,甚至在出现无序或者延迟加载的数据的情况下。
- 它是状态化的容错的,同时在维护一次完整的的应用状态时,能无缝修复错误。
- 大规模运行,在上千个节点运行时有很好的吞吐量和低延迟。
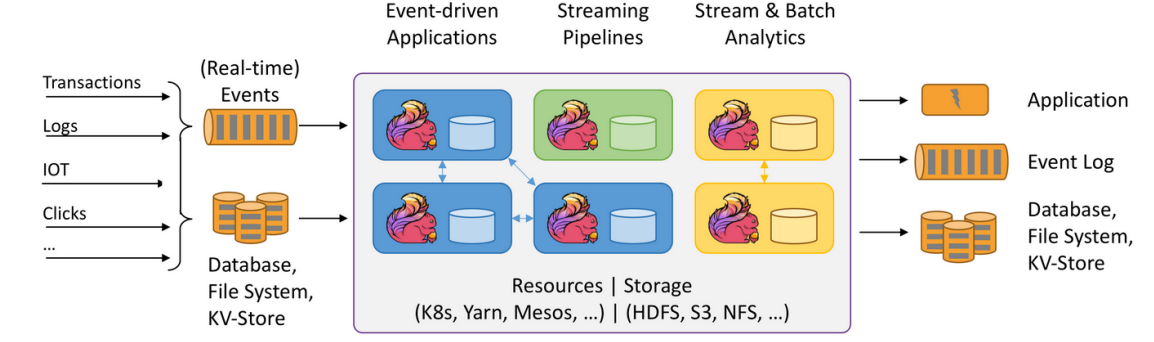
Flink的核心组件:
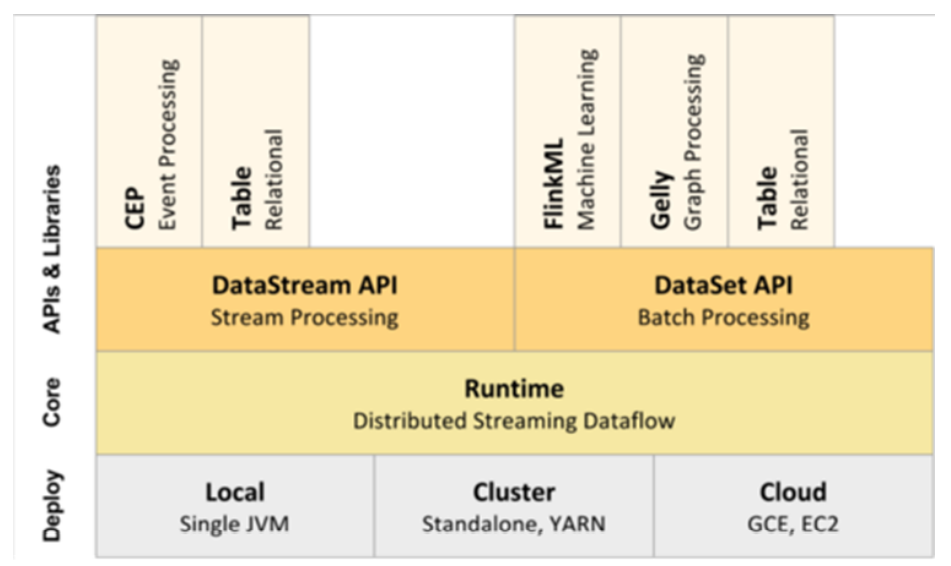
应用场景
Apache Flink 功能强大,支持开发和运行多种不同种类的应用程序。它的主要特性包括:
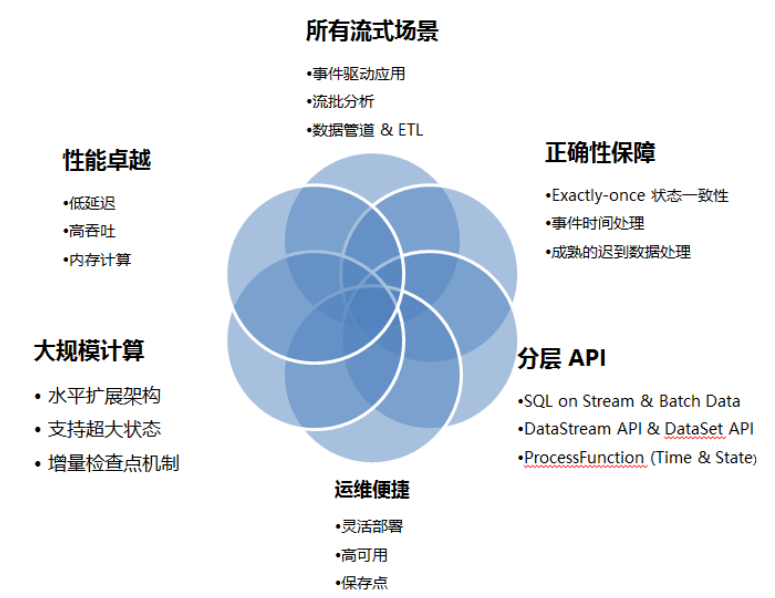
Flink 不仅可以运行在包括 YARN、 Mesos、Kubernetes 在内的多种资源管理框架上,还支持在裸机集群上独立部署。在启用高可用选项的情况下,它不存在单点失效问题。事实证明,Flink 已经可以扩展到数千核心,其状态可以达到 TB 级别,且仍能保持高吞吐、低延迟的特性。世界各地有很多要求严苛的流处理应用都运行在 Flink 之上。
Flink适用的应用场景包括:
- 事件驱动型应用
- 反欺诈
- 异常检测
- 基于规则的报警
- 业务流程监控
- (社交网络)Web 应用
- 数据分析应用
- 电信网络质量监控
- 移动应用中的产品更新及实验评估分析
- 消费者技术中的实时数据即时分析
- 大规模图分析
- 数据管道应用
- 电商中的实时查询索引构建
- 电商中的持续 ETL
Flink架构
Flink在运行中主要有三个组件组成,JobClient,JobManager 和 TaskManager。
工作原理如下图 :
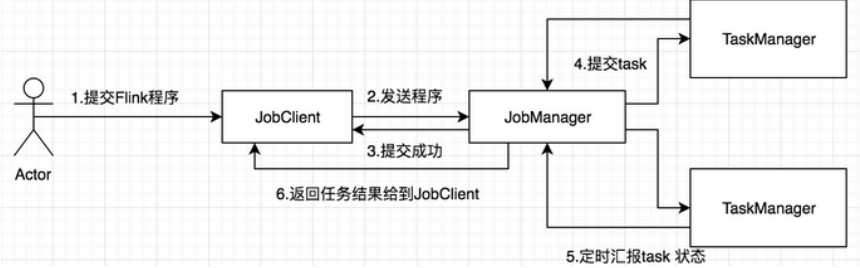
作业提交流程如下图:
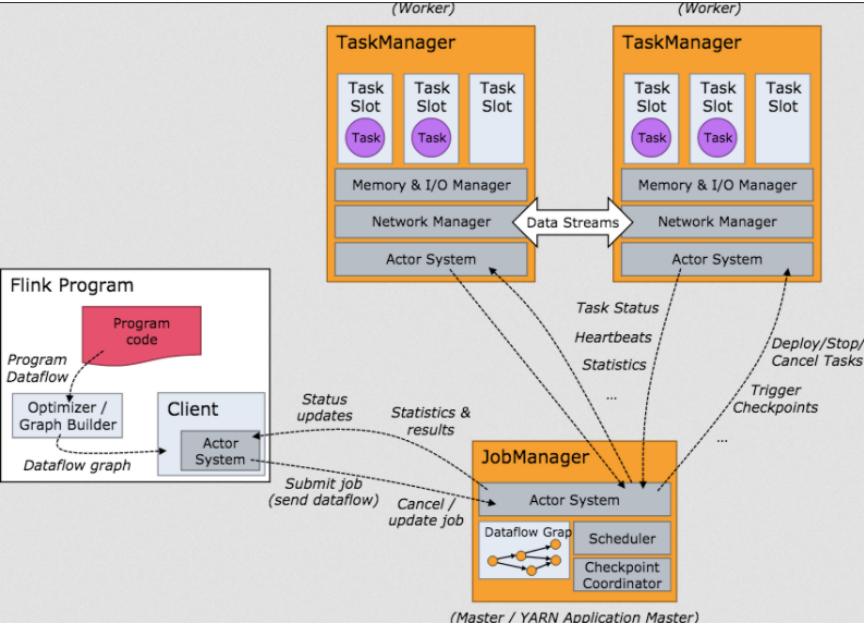
- Program Code:编写的 Flink 应用程序代码。
- Job Client:Job Client 不是 Flink 程序执行的内部部分,但它是任务执行的起点。 Job Client 负责接受用户的程序代码,然后创建数据流,将数据流提交给 Job Manager 以便进一步执行。 执行完成后,Job Client 将结果返回给用户。
- Job Manager:主进程(也称为作业管理器)协调和管理程序的执行。 它的主要职责包括安排任务,管理checkpoint ,故障恢复等。机器集群中至少要有一个 master,master 负责调度 task,协调 checkpoints 和容灾,高可用设置的话可以有多个 master,但要保证一个是 leader, 其他是standby; Job Manager 包含 Actor system、Scheduler、Check pointing 三个重要的组件。
- Task Manager:从 Job Manager 处接收需要部署的 Task。Task Manager 是在 JVM 中的一个或多个线程中执行任务的工作节点。 任务执行的并行性由每个 Task Manager 上可用的任务槽决定。 每个任务代表分配给任务槽的一组资源。 例如,如果 Task Manager 有四个插槽,那么它将为每个插槽分配 25% 的内存。 可以在任务槽中运行一个或多个线程。 同一插槽中的线程共享相同的 JVM。 同一 JVM 中的任务共享 TCP 连接和心跳消息。Task Manager 的一个 Slot 代表一个可用线程,该线程具有固定的内存,注意 Slot 只对内存隔离,没有对 CPU 隔离。默认情况下,Flink允许子任务共享 Slot,即使它们是不同 task 的 subtask,只要它们来自相同的 job。这种共享可以有更好的资源利用率。
安装配置
Flink的运行一般分为三种模式,即local、Standalone、On Yarn。
下载程序:
cd /opt
wget -c http://mirrors.tuna.tsinghua.edu.cn/apache/flink/flink-1.9.1/flink-1.9.1-binscala_2.12.tgz
tar -xzf flink-1.9.1-bin-scala_2.12.tgz
- Local模式
Local模式比较简单,用于本地测试,安装过程也比较简单,只需在主节点上解压安装包就代表成功安装了,在flink安装目录下使用./bin/start-cluster.sh(windows环境下是.bat)命令,就可以通过master:8081监控集群状态,关闭集群命令:./bin/stop-cluster.sh(windows环境下是.bat)。 - Standalone模式
Standalone模式顾名思义是在本地集群上调度执行,不依赖于外部调度机制例如YARN。此时需要对配置文件进行一些简单的修改,我们预计使用当前服务器充当Job manager和Task Manager,一般情况下需要多台机器。
在安装Flink之前,需要对安装环境进行检查,对于Standalone模式,需要提前安装好zookeeper。
- 修改环境变量,vim /etc/profile,添加以下内容
export FLINK_HOME=/opt/flink-1.9.1/
export PATH=$FLINK_HOME/bin:$PATH
- 更改配置文件flink-conf.yaml
cd /opt/flink-1.9.1/conf
vim flink-conf.yaml
# 主要更改的位置有:
jobmanager.rpc.address: 172.17.0.143
taskmanager.numberOfTaskSlots: 2
parallelism.default: 4
#取消下面两行的注释
rest.port: 8081
rest.address: 0.0.0.0
上面只列出了一些常用需要修改的文件内容,下面再简单介绍一些
# jobManager 的IP地址
jobmanager.rpc.address: 172.17.0.143
# JobManager 的端口号
jobmanager.rpc.port: 6123
# JobManager JVM heap 内存大小
jobmanager.heap.size: 1024m
# TaskManager JVM heap 内存大小
taskmanager.heap.size: 1024m
# 每个 TaskManager 提供的任务 slots 数量大小,默认为1
taskmanager.numberOfTaskSlots: 2
# 程序默认并行计算的个数,默认为1
parallelism.default: 4
- 配置masters文件
该文件用于指定主节点及其web访问端口,表示集群的Jobmanager,vim masters => 添加localhost:8081 - 配置slaves文件,该文件用于指定从节点,表示集群的taskManager。添加以下内容
localhost
localhost
localhost
- 启动flink集群 (因为在环境变量中已经指定了flink的bin位置,因此可以直接输入start-cluster.sh)
- 验证flink进程,登录web界面,查看Web界面是否正常。至此,standalone模式已成功安装。
示例演示
Flink安装目录下的example目录里有一些Flink程序示例,可以使用这些示例来看下Flink的功能。
首先看下SocketWindowWordCount这个应用的过程,这个应用的作用是监听某个socket服务器端口,实时计算这个端口数据的单词数量。
1.打开端口
# 在nc命令行中输入文本,必要时需要安装nc命令, yum -y install nc
nc -l 9010
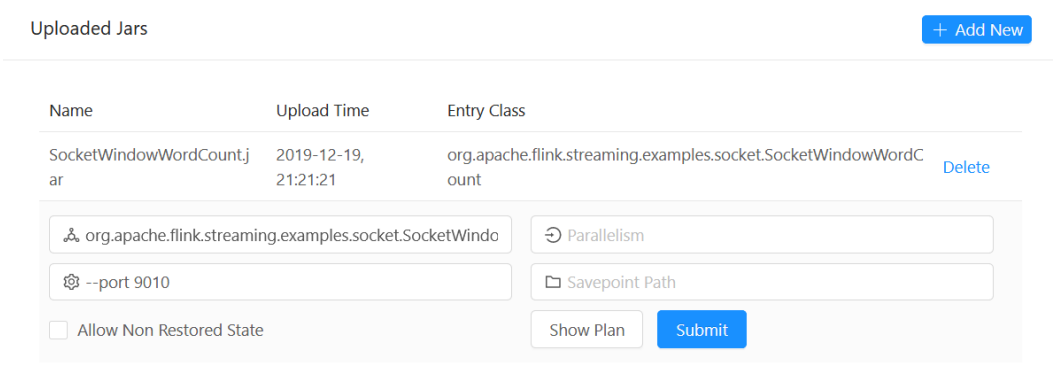
2.提交示例应用
有两种方式提交应用:
- 使用flink命令提交应用
/opt/flink-1.9.1/bin/flink run /opt/flink-1.9.1/examples/streaming/SocketWindowWordCount.jar --port 9010
- 页面上选择应用的jar文件
3.在nc命令行中输入单词
nc -l 9010
4.查看结果
aaa : 2
bbb : 1
ccc : 2
ddd : 2
单词统计示例
创建Flink工程
上面的是flink自带的程序,现在通过cmd命令窗口创建flink应用:
mvn archetype:generate -DarchetypeGroupId=org.apache.flink -DarchetypeArtifactId=flink-quickstart-java -DarchetypeVersion=1.9.1
依次输入: groupid,artifactId,version,package
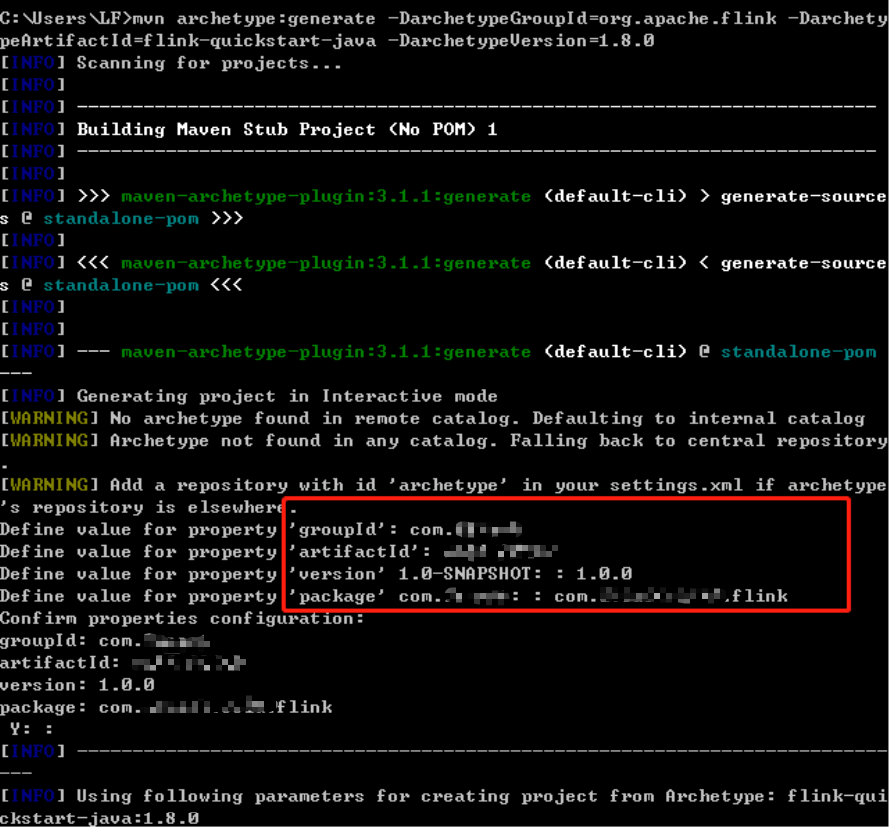
flink工程创建成功,使用idea等工具导入工程,工程目录结构:
flink/
├── pom.xml
└── src
└── main
├── java
│ └── com.xxx.flink
│ └── BatchJob.java
| └── StreamingJob.java
└── resources
└── log4j.properties
Batchjob:批处理程序代码
StreamingJob:流数据程序代码
示例代码
public class WindowWordCount {
public static void main(String[] args) throws Exception {
//设置运行时环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置输入流,并执行数据流的处理和转换
DataStream<Tuple2<String, Integer>> dataStream = env
.socketTextStream("localhost", 1111)
.flatMap(new Splitter())
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1);
//设置输出流
dataStream.print();
//执行程序
env.execute("Window WordCount");
}
public static class Splitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String sentence, Collector<Tuple2<String, Integer>> out) throws Exception {
for (String word: sentence.split(" ")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
}
基本概念
DataStream和DataSet
Flink使用DataStream、DataSet在程序中表示数据,可以将它们视为可以包含重复项的不可变数据集合。
DataSet是有限数据集(比如某个数据文件),而DataStream的数据可以是无限的(比如kafka队列中的消息)。
这些集合在某些关键方面与常规Java集合不同。首先,它们是不可变的,这意味着一旦创建它们就无法添加或删除元素。你也不能简单地检查里面的元素。
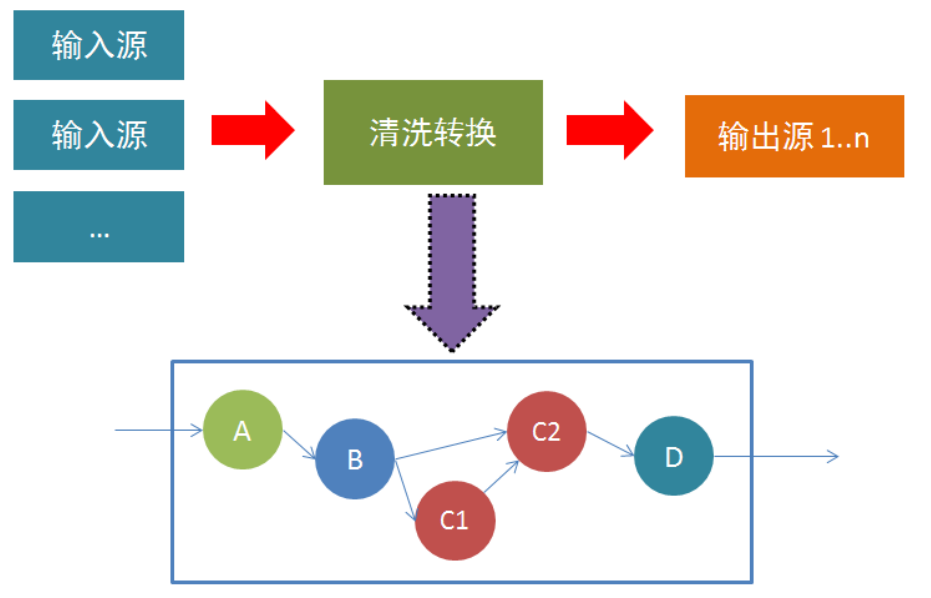
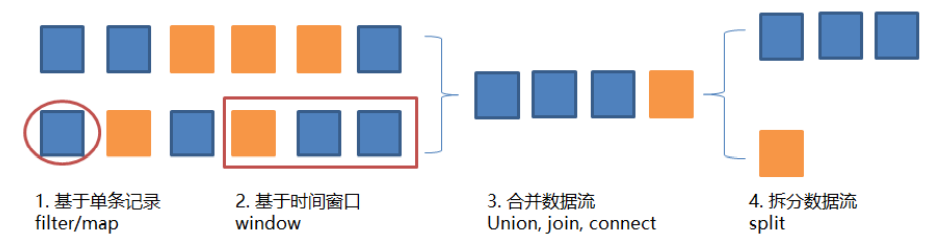
数据流通过filter/map等各种方法,执行过滤、转换、合并、拆分等操作,达到数据计算的目的。
数据类型
Flink对DataSet或DataStream中可以包含的元素类型设置了一些限制,以便于更有效的执行策略。
有六种不同类别的数据类型:
- Java元组和Scala案例类
- Java POJO
- 原始类型
- 常规类
- 值
- Hadoop Writables
元组
元组是包含固定数量的具有各种类型的字段的复合类型。Java API提供了 Tuple1 到 Tuple25 。元组的每个字段都可以是包含更多元组的任意Flink类型,从而产生嵌套元组。可以使用字段名称直接访问元组的字段 tuple.f4,或使用通用getter方法 tuple.getField(int position) 。字段索引从0开始。请注意,这与Scala元组形成对比,但它与Java的一般索引更为一致。
DataStream<Tuple2<String, Integer>> wordCounts = env.fromElements(
new Tuple2<String, Integer>("hello", 1),
new Tuple2<String, Integer>("world", 2));
wordCounts.map(new MapFunction<Tuple2<String, Integer>, Integer>() {
@Override
public Integer map(Tuple2<String, Integer> value) throws Exception {
return value.f1;
}
});
wordCounts.keyBy(0); // also valid.keyBy("f0")
POJOs
如果满足以下要求,则Flink将Java和Scala类视为特殊的POJO数据类型:
- 类必须公开类
- 它必须有一个没有参数的公共构造函数(默认构造函数)。
- 所有字段都是公共的,或者必须通过getter和setter函数访问。对于一个名为 foo 的属性的getter和setter方法的字段必须命名 getFoo() 和 setFoo() 。
- 注册的序列化程序必须支持字段的类型。
序列化:
POJO通常使用PojoTypeInfo和PojoSerializer(使用Kryo作为可配置的回退)序列化。例外情况是POJO实际上是Avro类型(Avro特定记录)或生成为“Avro反射类型”。在这种情况下,POJO使用AvroTypeInfo和AvroSerializer序列化。如果需要,还可以注册自己的自定义序列化程序
public class WordWithCount {
public String word;
public int count;
public WordWithCount() {}
public WordWithCount(String word, int count) {
this.word = word;
this.count = count;
}
}
DataStream<WordWithCount> wordCounts = env.fromElements(
new WordWithCount("hello", 1),
new WordWithCount("world", 2));
wordCounts.keyBy("word"); // key by field expression "word"
基础数据类型
Flink支持所有Java和Scala的原始类型,如 Integer,String 和 Double。
常规类
Flink支持大多数Java和Scala类(API和自定义)。限制适用于包含无法序列化的字段的类,如文件指针,I / O流或其他本机资源。遵循Java Beans约定的类通常可以很好地工作。
所有未标识为POJO类型的类都由Flink作为常规类类型处理。Flink将这些数据类型视为黑盒子,并且无法访问其内容(例如,用于有效排序)。使用序列化框架Kryo对常规类型进行反序列化。
值
值类型手动描述其序列化和反序列化。它们不是通过通用序列化框架,而是通过org.apache.flinktypes.Value 使用方法 read 和实现接口为这些操作提供自定义代码write。当通用序列化效率非常低时,使用值类型是合理的。一个示例是将元素的稀疏向量实现为数组的数据类型。知道数组大部分为零,可以对非零元素使用特殊编码,而通用序列化只需编写所有数组元素。该 org.apache.flinktypes.CopyableValue 接口以类似的方式支持手动内部克隆逻辑。Flink带有与基本数据类型对应的预定义值类型。(ByteValue,ShortValue,IntValue,LongValue,FloatValue,DoubleValue ,StringValue,CharValue,BooleanValue)。这些值类型充当基本数据类型的可变变体:它们的值可以被更改,允许程序员重用对象并从垃圾收集器中消除压力。
Hadoop Writables
使用实现 org.apache.hadoop.Writable 接口的类型。write() 和 readFields() 方法中定义的序列化逻辑将用于序列化。
数据的操作
数据转换,即通过从一个或多个 DataStream 生成新的DataStream 的过程,是主要的数据处理的手段。Flink 提供了多种数据转换操作,基本可以满足所有的日常使用场景。
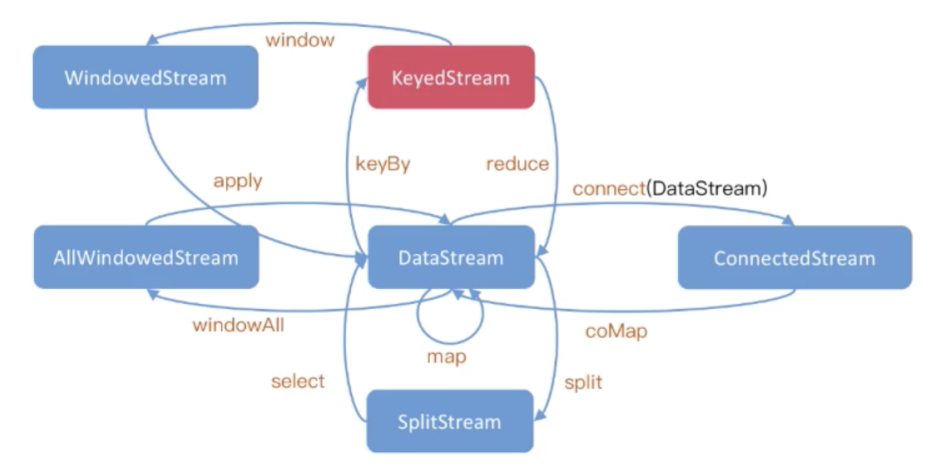
窗口的含义
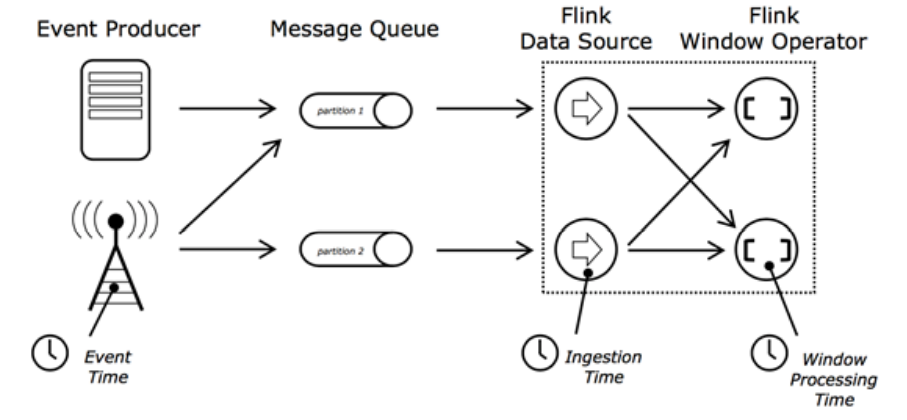
Flink计算引擎中,时间是一个非常重要的概念,Flink的时间分为三种时间:
- EventTime: 事件发生的时间
- IngestionTime:事件进入 Flink 的时间
- ProcessingTime:事件被处理时的时间
窗口是Flink流计算的一个核心概念,Flink窗口主要包括: - 时间窗口
- 翻滚时间窗口
- 滑动时间窗口
- 数量窗口
- 翻滚数量窗口
- 滑动数量窗口
按照形式来划分,窗口又分为:
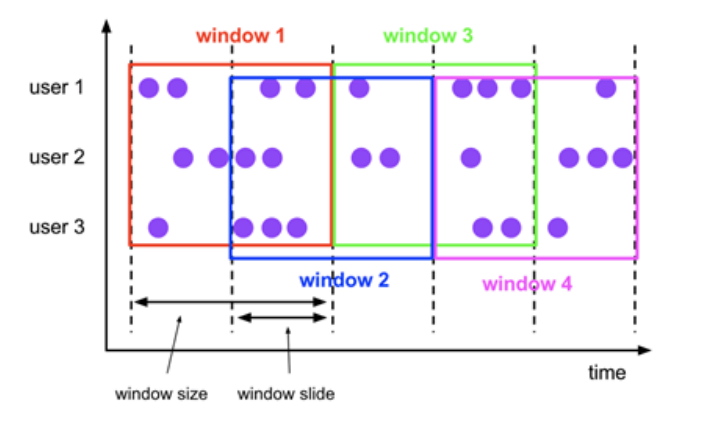
- 翻滚窗口
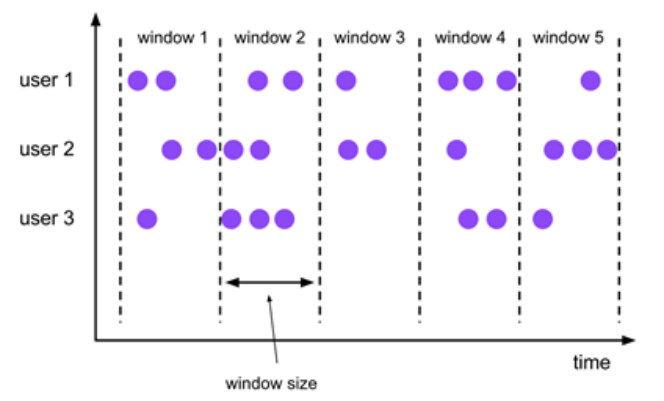
- 滑动窗口
有状态的流式处理
在很多场景下,数据都是以持续不断的流事件创建。例如网站的交互、或手机传输的信息、服务器日志、传感器信息等。有状态的流处理(stateful stream processing)是一种应用设计模式,用于处理无边界的流事件。
对于任何处理流事件的应用来说,并不会仅仅简单的一次处理一个记录就完事了。在对数据进行处理或转换时,操作应该是有状态的。也就是说,需要有能力做到对处理记录过程中生成的中间数据进行存储及访问。当一个应用收到一个 事件,在对其做处理时,它可以从状态信息(state)中读取数据进行协助处理。或是将数据写入state。在这种准则下,状态信息(state)可以被存储(及访问)在很多不同的地方,例如程序变量,本地文件,或是内置的(或外部的)数据库中。
Apache Flink 存储应用状态信息在本地内存或是一个外部数据库中。因为Flink 是一个分布式系统,本地状态信息需要被有效的保护,以防止在应用或是硬件挂掉之后,造成数据丢失。Flink对此采取的机制是:定期为应用状态(application state)生成一个一致(consistent)的checkpoint,并写入到一个远端持久性的存储中。下面是一个有状态的流处理Flink application的示例图:
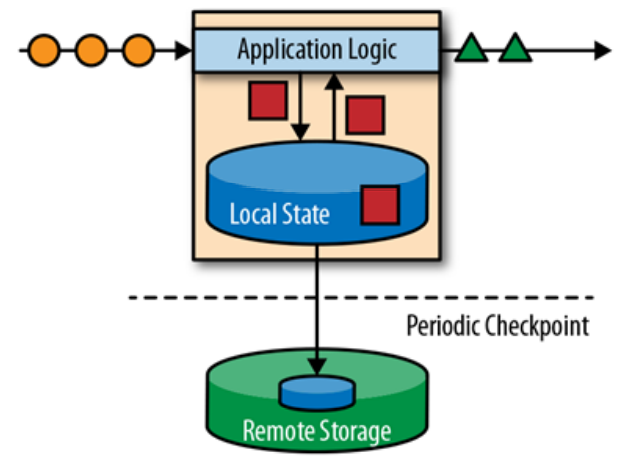
Stateful stream processing 应用的输入一般为:事件日志(event log)的持续事件。Event log 存储并且分发事件流。事件被写入一个持久性的,仅可追加的(append-only)日志中。也就是说,被写入的事件的顺序始终是不变的。所以事件在发布给多个不同用户时,均是以完全一样的顺序发布的。在开源的event log 系统中,最著名的当属 Kafka。
使用flink流处理程序连接event log的理由有多种。在这个架构下,event log 持久化输入的 events,并且可以以既定的顺序重现这些事件。万一应用发生了某个错误,Flink会通过前一个checkpoint 恢复应用的状态,并重置在event log 中的读取位置,并据此对events做重现,直到它抵达stream 的末端。这个技术不仅被用于错误恢复,并且也可以用于更新应用,修复bugs,以及修复之前遗漏结果等场景中。
DataStream编程
执行环境
创建执行环境:
- final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
- final StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment()
- final StreamExecutionEnvironment env = StreamExecutionEnvironment.createRemoteEnvironment(host: String, port: Int, jarFiles: String*)
输入流
源是程序从中读取输入的位置,可以使用以下方法将源附加到您的程序:StreamExecutionEnvironment.addSource(sourceFunction) 。
Flink附带了许多预先实现的源函数,但您可以通过实现 SourceFunction 非并行源,或通过实现ParallelSourceFunction 接口或扩展 RichParallelSourceFunction for parallel源来编写自己的自定义源。
有几个预定义的流源可从以下位置访问 StreamExecutionEnvironment :
基于文件:
- readTextFile(path) - TextInputFormat 逐行读取文本文件,即符合规范的文件,并将它们作为字符串返回。
- readFile(fileInputFormat, path) - 按指定的文件输入格式指定读取(一次)文件。
- readFile(fileInputFormat, path, watchType, interval, pathFilter, typeInfo) - 这是前两个内部调用的方法。它 path 根据给定的内容读取文件 fileInputFormat 。根据提供的内容 watchType ,此源可以定期监视(每 interval ms)新数据(FileProcessingMode. PROCESS_ CONTIN UOUSLY)的路径,或者处理当前在路径中的数据并退出(FileProcessingMode.PROCESS_ONCE )。使用 pathFilter ,用户可以进一步排除正在处理的文件。
实现:
Flink将文件读取过程分为两个子任务,即目录监控和数据读取。这些子任务中的每一个都由单独的实体实现。监视由单个非并行(并行性= 1)任务实现,而读取由并行运行的多个任务执行。后者的并行性等于工作并行性。单个监视任务的作用是扫描目录(定期或仅一次,具体取决于watchType ),找到要处理的文件,将它们分成分割,并将这些拆分分配给下游读者。读者是那些将阅读实际数据的人。每个分割仅由一个读取器读取,而读取器可以逐个读取多个分割。
重要笔记:- 如果 watchType 设置为 FileProcessingMode.PROCESS_CONTINUOUSLY ,则在修改文件时,将完全重新处理其内容。这可以打破“完全一次”的语义,因为在文件末尾附加数据将导致其所有内容被重新处理。
- 如果 watchType 设置为 FileProcessingMode.PROCESS_ONCE ,则源扫描路径一次并退出,而不等待读者完成读取文件内容。当然读者将继续阅读,直到读取所有文件内容。在该点之后关闭源将导致不再有检查点。这可能会导致节点故障后恢复速度变慢,因为作业将从上一个检查点恢复读取。
基于Socket:
- socketTextStream - 从Socket中读取,元素可以用分隔符分隔。
基于集合:
- fromCollection(Collection) - 从Java Java.util.Collection创建数据流。集合中的所有元素必须属于同一类型。
- fromCollection(Iterator, Class) - 从迭代器创建数据流。该类指定迭代器返回的元素的数据类型。
- fromElements(T …) - 从给定的对象序列创建数据流。所有对象必须属于同一类型。
- fromParallelCollection(SplittableIterator, Class) - 并行地从迭代器创建数据流。该类指定迭代器返回的元素的数据类型。
- generateSequence(from, to) - 并行生成给定间隔中的数字序列。
自定义:
- addSource - 附加新的源功能。例如,要从Apache Kafka读取,可以使用 addSource(new FlinkKafkaConsumer08<>(…)) 。
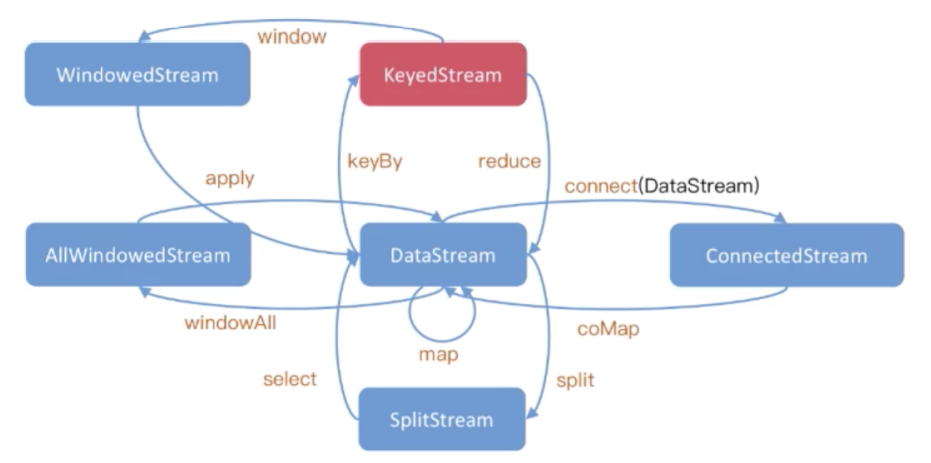
数据流转换
运算符将一个或多个DataStream转换为新的DataStream。程序可以将多个转换组合成复杂的数据流拓扑。
1.Map: DataStream → DataStream
调用用户定义的MapFunction对DataStream[T]数据进行处理,形成新的DataStream[T],其中数据格式可能会发生变化,常用作对数据集内数据的清洗和转换。如以下示例:它将输入流的元素数值增加一倍:
DataStream<Integer> dataStream = //...
dataStream.map(new MapFunction<Integer, Integer>() {
@Override
public Integer map(Integer value) throws Exception {
return 2 * value;
}
});
2.FlatMap:DataStream → DataStream
主要对输入的元素处理之后生成一个或者多个元素,如下示例:将句子拆分成单词:
dataStream.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
for(String word: value.split(" ")){
out.collect(word);
}
}
});
3.Filter: DataStream → DataStream
该算子将按照条件对输入数据集进行筛选操作,将符合条件的数据集输出,将不符合条件的数据过滤掉。如下所示:返回不为0的数据
dataStream.filter(new FilterFunction<Integer>() {
@Override
public boolean filter(Integer value) throws Exception {
return value != 0;
}
});
4.KeyBy: DataStream → KeyedStream
该算子根据指定的key将输入的DataStream[T]数据格式转换为KeyedStream[T],也就是在数据集中执行Partition操作,将相同的key值的数据放置在相同的分区中。简单来说,就是sql里面的group by
dataStream.keyBy("someKey") // Key by field "someKey"
dataStream.keyBy(0) // Key by the first element of a Tuple
注意:如果出现以下情况,则类型不能成为Key:
- 它是POJO类型,但不覆盖hashCode()方法并依赖于Object.hashCode()实现。
- 它是任何类型的数组。
5.Reduce: KeyedStream → DataStream
该算子和MapReduce的Reduce原理基本一致,主要目的是将输入的KeyedStream通过传入的用户自定义的ReduceFunction滚动的进行数据聚合处理,其中定义的ReduceFunction必须满足运算结合律和交换律:
keyedStream.reduce(new ReduceFunction<Integer>() {
@Override
public Integer reduce(Integer value1, Integer value2) throws Exception {
return value1 + value2;
}
});
6.Fold: KeyedStream → DataStream
具有初始值的键控数据流上的“滚动”折叠。将当前元素与最后折叠的值组合并发出新值。折叠函数,当应用于序列(1,2,3,4,5)时,发出序列“start-1”,“start-1-2”,“start-1-2-3”,. …
DataStream<String> result = keyedStream.fold("start", new FoldFunction<Integer, String>() {
@Override
public String fold(String current, Integer value) {
return current + "-" + value;
}
});
7.Aggregations: KeyedStream → DataStream
滚动聚合数据流上的聚合。min和minBy之间的差异是min返回最小值,而minBy返回该字段中具有最小值的元素(max和maxBy相同)。
keyedStream.sum(0);
keyedStream.sum("key");
keyedStream.min(0);
keyedStream.min("key");
keyedStream.max(0);
keyedStream.max("key");
keyedStream.minBy(0);
keyedStream.minBy("key");
keyedStream.maxBy(0);
keyedStream.maxBy("key");
8.Window:KeyedStream → WindowedStream
可以在已经分区的KeyedStream上定义时间窗口。时间窗口根据某些特征(例如,在最后5秒内到达的数据)对每个Key中的数据进行分组。
// 最后5秒的数据
dataStream.keyBy(0).window(TumblingEventTimeWindows.of(Time.seconds(5)));
9.WindowAll:DataStream → AllWindowedStream
Windows可以在常规DataStream上定义。Windows根据某些特征(例如,在最后5秒内到达的数据)对所有流事件进行分组。
注意:在许多情况下,这是非并行转换。所有记录将收集在windowAll运算符的一个任务中。
// 最后5秒的数据
dataStream.windowAll(TumblingEventTimeWindows.of(Time.seconds(5)));
10.Window Apply:WindowedStream → DataStream AllWindowedStream → DataStream
将一般功能应用于整个窗口。下面是一个手动求和窗口元素的函数。注意:如果正在使用windowAll转换,则需要使用AllWindowFunction。
windowedStream.apply (new WindowFunction<Tuple2<String,Integer>, Integer, Tuple, Window>() {
public void apply (Tuple tuple, Window window, Iterable<Tuple2<String, Integer>> values, Collector<Integer> out) throws Exception {
int sum = 0;
for (value t: values) {
sum += t.f1;
}
out.collect (new Integer(sum));
}
});
// applying an AllWindowFunction on non-keyed window stream
allWindowedStream.apply (new AllWindowFunction<Tuple2<String,Integer>, Integer, Window>() {
public void apply (Window window, Iterable<Tuple2<String, Integer>> values, Collector<Integer> out) throws Exception {
int sum = 0;
for (value t: values) {
sum += t.f1;
}
out.collect (new Integer(sum));
}
});
11.Window Reduce:WindowedStream → DataStream
将减少功能应用于窗口并返回减少的值。
windowedStream.reduce (new ReduceFunction<Tuple2<String,Integer>>() {
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {
return new Tuple2<String,Integer>(value1.f0, value1.f1 + value2.f1);
}
});
12.Window Fold:WindowedStream → DataStream
将折叠功能应用于窗口并返回折叠值。示例函数应用于序列(1,2,3,4,5)时,将序列折叠为字符串“start-1-2-3-4-5”:
windowedStream.fold("start", new FoldFunction<Integer, String>() {
public String fold(String current, Integer value) {
return current + "-" + value;
}
});
13.Windows上的聚合:WindowedStream → DataStream
聚合窗口的内容。min和minBy之间的差异是min返回最小值,而minBy返回该字段中具有最小值的元素(max和maxBy相同)。
windowedStream.sum(0);
windowedStream.sum("key");
windowedStream.min(0);
windowedStream.min("key");
windowedStream.max(0);
windowedStream.max("key");
windowedStream.minBy(0);
windowedStream.minBy("key");
windowedStream.maxBy(0);
windowedStream.maxBy("key");
14.Union: DataStream → DataStream
将两个或者多个输入的数据集合并成一个数据集,需要保证两个数据集的格式一致,输出的数据集的格式和输入的数据集格式保持一致
注意:如果将数据流与其自身联合,则会在结果流中获取两次元素。
dataStream.union(otherStream1, otherStream2, ...);
15.Window Join:DataStream,DataStream → DataStream
根据主键和公共时间窗口,连接数据流
dataStream.join(otherStream)
.where(<key selector>).equalTo(<key selector>)
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
.apply (new JoinFunction () {...});
16.Interval Join: KeyedStream,KeyedStream → DataStream
在给定的时间间隔内使用公共Key连接两个键控流的两个元素e1和e2,以便e1.timestamp + lowerBound <= e2.timestamp <= e1.timestamp + upperBound
// this will join the two streams so that
// key1 == key2 && leftTs - 2 < rightTs < leftTs + 2
keyedStream.intervalJoin(otherKeyedStream)
.between(Time.milliseconds(-2), Time.milliseconds(2)) // lower and upper
bound
.upperBoundExclusive(true) // optional
.lowerBoundExclusive(true) // optional
.process(new IntervalJoinFunction() {...});
17.Window CoGroup: DataStream,DataStream → DataStream
在给定Key和公共时间窗口上对两个数据流进行coGroup操作。
dataStream.coGroup(otherStream)
.where(0).equalTo(1)
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
.apply (new CoGroupFunction () {...});
18.Connect: DataStream,DataStream → ConnectedStreams
Connect算子主要是为了合并两种或者多种不同数据类型的数据集,合并后会保留原来的数据集的数据类型。连接操作允许共享状态数据,也就是说在多个数据集之间可以操作和查看对方数据集的状态。
DataStream<Integer> someStream = //...
DataStream<String> otherStream = //...
ConnectedStreams<Integer, String> connectedStreams = someStream.connect(otherStream);
19.CoMap,CoFlatMap: ConnectedStreams → DataStream
类似于连接数据流上的map和flatMap
connectedStreams.map(new CoMapFunction<Integer, String, Boolean>() {
@Override
public Boolean map1(Integer value) {
return true;
}
@Override
public Boolean map2(String value) {
return false;
}
});
connectedStreams.flatMap(new CoFlatMapFunction<Integer, String, String>() {
@Override
public void flatMap1(Integer value, Collector<String> out) {
out.collect(value.toString());
}
@Override
public void flatMap2(String value, Collector<String> out) {
for (String word: value.split(" ")) {
out.collect(word);
}
}
});
20.Split: DataStream → SplitStream
根据某些标准将流拆分为两个或更多个流。
SplitStream<Integer> split = someDataStream.split(new OutputSelector<Integer>() {
@Override
public Iterable<String> select(Integer value) {
List<String> output = new ArrayList<String>();
if (value % 2 == 0) {
output.add("even");
}
else {
output.add("odd");
}
return output;
}
});
21.Select: SplitStream → DataStream
从拆分流中选择一个或多个流。
SplitStream<Integer> split;
DataStream<Integer> even = split.select("even");
DataStream<Integer> odd = split.select("odd");
DataStream<Integer> all = split.select("even","odd");
22.Iterate: DataStream → IterativeStream → DataStream
通过将一个运算符的输出重定向到某个先前的运算符,在流中创建“反馈”循环。这对于定义不断更新模型的算法特别有用。以下代码以流开头并连续应用迭代体。大于0的元素将被发送回反馈通道,其余元素将向下游转发。
IterativeStream<Long> iteration = initialStream.iterate();
DataStream<Long> iterationBody = iteration.map (/*do something*/);
DataStream<Long> feedback = iterationBody.filter(new FilterFunction<Long>(){
@Override
public boolean filter(Long value) throws Exception {
return value > 0;
}
});
iteration.closeWith(feedback);
DataStream<Long> output = iterationBody.filter(new FilterFunction<Long>(){
@Override
public boolean filter(Long value) throws Exception {
return value <= 0;
}
});
23.提取时间戳: DataStream → DataStream
从记录中提取时间戳,以便使用事件时间语义的窗口。
stream.assignTimestamps (new TimeStampExtractor() {...});
24.元组数据流转换Project: DataStream→DataStream
从元组中选择字段的子集
DataStream<Tuple3<Integer, Double, String>> in = // [...]
DataStream<Tuple2<String, Integer>> out = in.project(2,0);
输出流
数据接收器使用DataStream并将它们转发到文件,套接字,外部系统或打印它们。Flink带有各种内置输出格式,这些格式封装在DataStreams上的操作后面:
- writeAsText() / TextOutputFormat - 按字符串顺序写入元素。通过调用每个元素的toString()方法获得字符串。
- writeAsCsv(…) / CsvOutputFormat - 将元组写为逗号分隔值文件。行和字段分隔符是可配置的。每个字段的值来自对象的toString()方法。
- print() / printToErr() - 在标准输出/标准错误流上打印每个元素的toString()值。可选地,可以提供前缀(msg),其前缀为输出。这有助于区分不同的打印调用。如果并行度大于1,则输出也将以生成输出的任务的标识符为前缀。
- writeUsingOutputFormat() / FileOutputFormat - 自定义文件输出的方法和基类。支持自定义对象到字节的转换。
- writeToSocket - 根据a将元素写入套接字 SerializationSchema
- addSink - 调用自定义接收器功能。Flink捆绑了其他系统(如Apache Kafka)的连接器,这些系统实现为接收器功能。
注意:write*() 方法 DataStream 主要用于调试目的。他们没有参与Flink的检查点,这意味着这些函数通常具有至少一次的语义。刷新到目标系统的数据取决于OutputFormat的实现。这意味着并非所有发送到OutputFormat的元素都会立即显示在目标系统中。此外,在失败的情况下,这些记录可能会丢失。为了可靠,准确地将流传送到文件系统,请使用 flink-connector-filesystem 。此外,通过该 .addSink(…) 方法的自定义实现可以参与Flink的精确一次语义检查点。
DataSet编程
Flink中的DataSet程序是实现数据集转换的常规程序(例如,过滤,映射,连接,分组)。数据集最初是从某些来源创建的(例如,通过读取文件或从本地集合创建)。结果通过接收器返回,接收器可以例如将数据写入(分布式)文件或标准输出(例如命令行终端)。Flink程序可以在各种环境中运行,独立运行或嵌入其他程序中。执行可以在本地JVM中执行,也可以在许多计算机的集群上执行。
DataSet示例
通过maven命令创建Flink工程:
mvn archetype:generate -DarchetypeGroupId=org.apache.flink -DarchetypeArtifactId=flink-quickstart-java -DarchetypeVersion=1.9.1
以单词统计程序为例,演示Flink DataSet程序的开发过程:
public class WordCountExample {
public static void main(String[] args) throws Exception {
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<String> text = env.fromElements("Who's there?", "I think I hear them. Stand, ho! Who's there?");
DataSet<Tuple2<String, Integer>> wordCounts = text
.flatMap(new LineSplitter())
.groupBy(0)
.sum(1);
wordCounts.print();
}
public static class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> out) {
for (String word : line.split(" ")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
}
输入源
数据源创建初始数据集,例如来自文件或Java集合。创建数据集的一般机制是在InputFormat后面抽象的 。Flink附带了几种内置格式,可以从通用文件格式创建数据集。其中许多都在ExecutionEnvironment上有快捷方法。
基于文件:
- readTextFile(path)/ TextInputFormat- 按行读取文件并将其作为字符串返回。
- readTextFileWithValue(path)/ TextValueInputFormat- 按行读取文件并将它们作为StringValues返回。StringValues是可变字符串。
- readCsvFile(path)/ CsvInputFormat- 解析逗号(或其他字符)分隔字段的文件。返回元组或POJO的DataSet。支持基本的java类型及其Value对应的字段类型。
- readFileOfPrimitives(path, Class)/ PrimitiveInputFormat- 解析新行(或其他字符序列)分隔的原始数据类型(如String或)的文件Integer。
- readFileOfPrimitives(path, delimiter, Class)/ PrimitiveInputFormat- 解析新行(或其他字符序列)分隔的原始数据类型的文件,例如String或Integer使用给定的分隔符。
基于集合:
- fromCollection(Collection) - 从Java.util.Collection创建数据集。集合中的所有元素必须属于同一类型。
- fromCollection(Iterator, Class) - 从迭代器创建数据集。该类指定迭代器返回的元素的数据类型。
- fromElements(T …) - 根据给定的对象序列创建数据集。所有对象必须属于同一类型。
- fromParallelCollection(SplittableIterator, Class) - 并行地从迭代器创建数据集。该类指定迭代器返回的元素的数据类型。
- generateSequence(from, to) - 并行生成给定间隔中的数字序列。
通用:
- readFile(inputFormat, path) / FileInputFormat - 接受文件输入格式。
- createInput(inputFormat) / InputFormat - 接受通用输入格式。
示例:
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 根据给定的元素创建一个DataSet
DataSet<String> value = env.fromElements("Foo", "bar", "foobar", "fubar");
// 生成一个数字型序列号
DataSet<Long> numbers = env.generateSequence(1, 10000000);
// 从CSV文件中读取三个字段
DataSet<Tuple3<Integer, String, Double>> csvInput = env.readCsvFile("hdfs:///the/CSV/file").types(Integer.class, String.class, Double.class);
// 读取CSV文件中的三个字段,并初始化赋值Person对象
DataSet<Person>> csvInput = env.readCsvFile("hdfs:///the/CSV/file").pojoType(Person.class, "name", "age", "zipcode");
// 从本地系统中读取文本文件
DataSet<String> localLines = env.readTextFile("file:///path/to/my/textfile");
// 从HDFS中读取文件
DataSet<String> hdfsLines = env.readTextFile("hdfs://nnHost:nnPort/path/to/my/textfile");
// 从HDFS的CSV文件中读取5个字段,使用其中的两个
DataSet<Tuple2<String, Double>> csvInput = env.readCsvFile("hdfs:///the/CSV/file")
.includeFields("10010") // 使用第一个和第四个
.types(String.class, Double.class);
// 顺序读取HDFS文件中的字段
DataSet<Tuple2<IntWritable, Text>> tuples = env.createInput(HadoopInputs.readSequenceFile(IntWritable.class, Text.class, "hdfs://nnHost:nnPort/path/to/file"));
// 通过JDBC读取关系型数据库
DataSet<Tuple2<String, Integer> dbData = env.createInput(JDBCInputFormat.buildJDBCInputFormat()
.setDrivername("org.apache.derby.jdbc.EmbeddedDriver")
.setDBUrl("jdbc:derby:memory:persons")
.setQuery("select name, age from persons")
.setRowTypeInfo(new RowTypeInfo(BasicTypeInfo.STRING_TYPE_INFO, BasicTypeInfo.INT_TYPE_INFO))
.finish());
注意:
Flink的程序编译器需要推断由InputFormat返回的数据项的数据类型,如果此信息无法自动推断,则需要手动提供类型信息。
转换操作
数据转换将一个或多个DataSet转换为新的DataSet。程序可以将多个转换组合成复杂的程序集。
1.Map
采用一个元素并生成一个元素。
data.map(new MapFunction<String, Integer>() {
public Integer map(String value) {
return Integer.parseInt(value);
}
});
2.FlatMap
采用一个元素并生成零个,一个或多个元素。
data.flatMap(new FlatMapFunction<String, String>() {
public void flatMap(String value, Collector<String> out) {
for (String s : value.split(" ")) {
out.collect(s);
}
}
});
3.MapPartition
在单个函数调用中转换并行分区。该函数将分区作为 Iterable 流来获取,并且可以生成任意数量的结果值。每个分区中的元素数量取决于并行度和先前的操作。
data.mapPartition(new MapPartitionFunction<String, Long>() {
public void mapPartition(Iterable<String> values, Collector<Long> out) {
long c = 0;
for (String s : values) {
c++;
}
out.collect(c);
}
});
4.Filter
计算每个元素的布尔函数,并保留函数返回true的元素。 重要信息:系统假定该函数不会修改元素,否则可能会导致错误的结果。
data.filter(new FilterFunction<Integer>() {
public boolean filter(Integer value) {
return value > 1000;
}
});
5.Reduce
通过将两个元素重复组合成一个元素,将一组元素组合成一个元素。Reduce可以应用于完整数据集或分组数据集。
data.reduce(new ReduceFunction<Integer> {
public Integer reduce(Integer a, Integer b) {
return a + b;
}
});
如果将reduce应用于分组数据集,则可以通过提供 CombineHintto 来指定运行时执行reduce的组合阶段的方式 setCombineHint 。在大多数情况下,基于散列的策略应该更快,特别是如果不同键的数量与输入元素的数量相比较小(例如1/10)。
6.ReduceGroup
将一组元素组合成一个或多个元素。ReduceGroup可以应用于完整数据集或分组数据集。
data.reduceGroup(new GroupReduceFunction<Integer, Integer> {
public void reduce(Iterable<Integer> values, Collector<Integer> out) {
int prefixSum = 0;
for (Integer i : values) {
prefixSum += i;
out.collect(prefixSum);
}
}
});
7.Aggregate
将一组值聚合为单个值。聚合函数可以被认为是内置的reduce函数。聚合可以应用于完整数据集或分组数据集。
Dataset<Tuple3<Integer, String, Double>> input = // [...]
DataSet<Tuple3<Integer, String, Double>> output = input.aggregate(SUM, 0).and(MIN, 2);
还可以使用简写语法进行最小,最大和总和聚合。
Dataset<Tuple3<Integer, String, Double>> input = // [...]
DataSet<Tuple3<Integer, String, Double>> output = input.sum(0).andMin(2);
8.Distinct
返回数据集的不同元素。它相对于元素的所有字段或字段子集从输入DataSet中删除重复条目。
data.distinct();
9.Join
通过创建在其Key上相等的所有元素对来连接两个数据集。可选地使用JoinFunction将元素对转换为单个元素,或使用FlatJoinFunction将元素对转换为任意多个(包括无)元素。
result = input1.join(input2)
.where(0) // key of the first input (tuple field 0)
.equalTo(1); // key of the second input (tuple field 1)
可以通过 Join Hints 指定运行时执行连接的方式。提示描述了通过分区或广播进行连接,以及它是使用基于排序还是基于散列的算法。如果未指定提示,系统将尝试估算输入大小,并根据这些估计选择最佳策略。
// This executes a join by broadcasting the first data set
// using a hash table for the broadcast data
result = input1.join(input2, JoinHint.BROADCAST_HASH_FIRST).where(0).equalTo(1);
注意:连接转换仅适用于等连接。其他连接类型需要使用OuterJoin或CoGroup表示。
10.OuterJoin
在两个数据集上执行左,右或全外连接。外连接类似于常规(内部)连接,并创建在其键上相等的所有元素对。
input1.leftOuterJoin(input2) // rightOuterJoin or fullOuterJoin for right or full outer joins
.where(0) // key of the first input (tuple field 0)
.equalTo(1) // key of the second input (tuple field 1)
.with(new JoinFunction<String, String, String>() {
public String join(String v1, String v2) {
// NOTE:
// - v2 might be null for leftOuterJoin
// - v1 might be null for rightOuterJoin
// - v1 OR v2 might be null for fullOuterJoin
}
});
11.CoGroup
reduce操作的二维变体。将一个或多个字段上的每个输入分组,然后加入组。每对组调用转换函数。
data1.coGroup(data2)
.where(0)
.equalTo(1)
.with(new CoGroupFunction<String, String, String>() {
public void coGroup(Iterable<String> in1, Iterable<String> in2, Collector<String> out) {
out.collect(...);
}
});
12.Cross
构建两个输入的笛卡尔积(交叉乘积),创建所有元素对。可选择使用CrossFunction将元素对转换为单个元素
DataSet<Integer> data1 = // [...]
DataSet<String> data2 = // [...]
DataSet<Tuple2<Integer, String>> result = data1.cross(data2);
注意:交叉是一个潜在的非常计算密集型操作它甚至可以挑战大的计算集群!建议使用crossWithTiny()和crossWithHuge()来提示系统的DataSet大小。
13.Union
生成两个数据集的并集。
DataSet<String> data1 = // [...]
DataSet<String> data2 = // [...]
DataSet<String> result = data1.union(data2);
14.Rebalance
均匀地重新平衡数据集的并行分区以消除数据偏差。只有类似Map的转换可能会使用重新平衡转换。
DataSet<String> in = // [...]
DataSet<String> result = in.rebalance().map(new Mapper());
15.Hash-Partition
散列分区给定键上的数据集。键可以指定为位置键,表达键和键选择器功能。
DataSet<Tuple2<String,Integer>> in = // [...]
DataSet<Integer> result = in.partitionByHash(0).mapPartition(new PartitionMapper());
16.Range-Partition
范围分区给定键上的数据集。键可以指定为位置键,表达键和键选择器功能。
DataSet<Tuple2<String,Integer>> in = // [...]
DataSet<Integer> result = in.partitionByRange(0).mapPartition(new PartitionMapper());
17.自定义分区
使用自定义分区程序功能基于特定分区的键分配记录。密钥可以指定为位置键,表达式键和键选择器功能。 注意:此方法仅适用于单个字段键。
DataSet<Tuple2<String,Integer>> in = // [...]
DataSet<Integer> result = in.partitionCustom(partitioner, key)
.mapPartition(new PartitionMapper());
18.排序分区
本地按指定顺序对指定字段上的数据集的所有分区进行排序。可以将字段指定为元组位置或字段表达式。通过链接sortPartition()调用来完成对多个字段的排序。
DataSet<Tuple2<String,Integer>> in = // [...]
DataSet<Integer> result = in.sortPartition(1, Order.ASCENDING)
.mapPartition(new PartitionMapper());
输出源
数据接收器(sink)使用DataSet并用于存储或返回它们。使用OutputFormat描述数据接收器操作 。Flink带有各种内置输出格式,这些格式封装在DataSet上的操作后面:
- writeAsText() / TextOutputFormat - 按字符串顺序写入元素。通过调用每个元素的toString()方法获得字符串。
- writeAsFormattedText() / TextOutputFormat - 按字符串顺序编写元素。通过为每个元素调用用户定义的format()方法来获取字符串。
- writeAsCsv(…) / CsvOutputFormat - 将元组写为逗号分隔值文件。行和字段分隔符是可配置的。每个字段的值来自对象的toString()方法。
- print() / printToErr() / print(String msg) / printToErr(String msg) - 在标准输出/标准错误流上打印每个元素的toString()值。可选地,可以提供前缀(msg),其前缀为输出。这有助于区分不同的打印调用。如果并行度大于1,则输出也将以生成输出的任务的标识符为前缀。
- write() / FileOutputFormat - 自定义文件输出的方法和基类。支持自定义对象到字节的转换。
- output() / OutputFormat - 大多数通用输出方法,用于非基于文件的数据接收器(例如将结果存储在数据库中)。
可以将DataSet输入到多个操作。程序可以编写或打印数据集,同时对它们执行其他转换。
示例:
标准数据接收方法:
// 文本类型的数据集
DataSet<String> textData = // [...]
// 将数据集保存到本地文件
textData.writeAsText("file:///my/result/on/localFS");
// 将数据集保存到HDFS系统中
textData.writeAsText("hdfs://nnHost:nnPort/my/result/on/localFS");
// 将数据集保存成文件,如果该文件存在,则覆盖该文件
textData.writeAsText("file:///my/result/on/localFS", WriteMode.OVERWRITE);
// 将数据集保存到本地csv文件,数据集各字段用|分割
DataSet<Tuple3<String, Integer, Double>> values = // [...]
values.writeAsCsv("file:///path/to/the/result/file", "n", "|");
// 按照用户自定义的形式将字符型数据集保存到文本文件
values.writeAsFormattedText("file:///path/to/the/result/file", new TextFormatter<Tuple2<Integer, Integer>>() {
public String format (Tuple2<Integer, Integer> value) {
return value.f1 + " - " + value.f0;
}
});
使用自定义输出格式:
DataSet<Tuple3<String, Integer, Double>> myResult = [...]
// 将Tuple类型的数据集保存到关系型数据库中
myResult.output(
// 创建JDBC配置
JDBCOutputFormat.buildJDBCOutputFormat()
.setDrivername("org.apache.derby.jdbc.EmbeddedDriver")
.setDBUrl("jdbc:derby:memory:persons")
.setQuery("insert into persons (name, age, height) values (?,?,?)")
.finish()
);
调试程序
在对分布式集群中的大型数据集运行数据分析程序之前,最好确保实现的算法按预期工作。因此,实施数据分析程序通常是检查结果,调试和改进的增量过程。
Flink提供了一些很好的功能,通过支持IDE内的本地调试,测试数据的注入和结果数据的收集,显着简化了数据分析程序的开发过程。
本地执行环境
A LocalEnvironment 在创建它的同一JVM进程中启动Flink系统。如果从IDE启动LocalEnvironment,则可以在代码中设置断点并轻松调试程序。
创建LocalEnvironment并使用如下:
final ExecutionEnvironment env = ExecutionEnvironment.createLocalEnvironment();
DataSet<String> lines = env.readTextFile(pathToTextFile);
// build your program
env.execute();
收集数据源和接收器
通过创建输入文件和读取输出文件来为分析程序提供输入并检查其输出是麻烦的。Flink具有特殊的数据源和接收器,由Java集合支持以简化测试。一旦程序经过测试,源和接收器可以很容易地被读取/写入外部数据存储(如HDFS)的源和接收器替换。
final ExecutionEnvironment env = ExecutionEnvironment.createLocalEnvironment();
// Create a DataSet from a list of elements
DataSet<Integer> myInts = env.fromElements(1, 2, 3, 4, 5);
// Create a DataSet from any Java collection
List<Tuple2<String, Integer>> data = ...
DataSet<Tuple2<String, Integer>> myTuples = env.fromCollection(data);
// Create a DataSet from an Iterator
Iterator<Long> longIt = ...
DataSet<Long> myLongs = env.fromCollection(longIt, Long.class);
集合数据接收器指定如下:
DataSet<Tuple2<String, Integer>> myResult = ...
List<Tuple2<String, Integer>> outData = new ArrayList<Tuple2<String, Integer>> ();
myResult.output(new LocalCollectionOutputFormat(outData));
注意:目前,集合数据接收器仅限于本地执行,作为调试工具。集合数据源要求实现数据类型和迭代器 Serializable 。此外,收集数据源不能并行执行。
Table API和SQL编程
Flink针对标准的流处理和批处理提供了两种相关的API,Table API和sql。Table API允许用户以一种很直观的方式进行select 、filter和join操作。Flink SQL支持基于 Apache Calcite实现的标准SQL。针对批处理和流处理可以提供相同的处理语义和结果。Flink Table API、SQL接口和Flink的DataStream API、DataSet API是紧密联系在一起的。
架构原理:
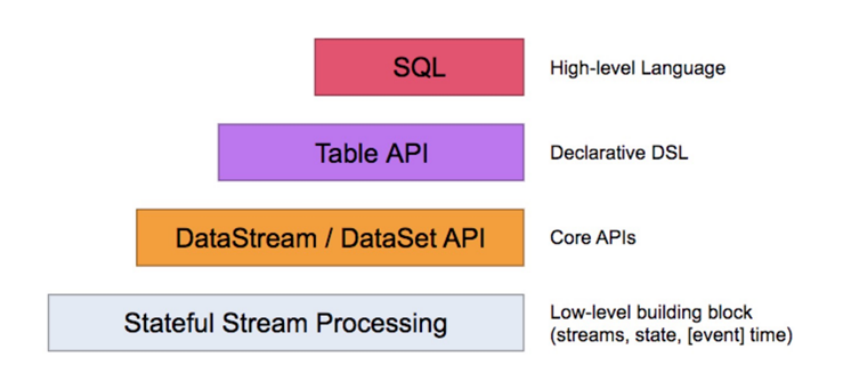
如果项目中想要使用Table API 和SQL的话,必须要添加下面依赖:
<properties>
<scala.binary.version>2.11</scala.binary.version>
<!-- 其他依赖包的版本... -->
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- 其他依赖包 -->
</dependencies>
Table API和SQL的程序示例
批处理和流式传输的所有Table API和SQL程序都遵循相同的模式。以下代码示例显示了Table API和SQL程序的常见结构。
public class StreamTable {
/**
* 1. 定义数据结构: order pojo
* 2 设置执行环境
* 3. 定义table环境
* 4. 定义数据源/输入源: from collection
* 5. datastream转化table
* 6. 执行table查询
* 7. 执行flink程序
* @param args
*/
public static void main(String[] args) throws Exception {
// 1. 设置执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// 2. 定义输入源
DataStream<Order> orderA = env.fromCollection(Arrays.asList(new Order(1L, "book1", 3), new Order(2L, "book2", 4), new Order(3L, "book3", 2)));
DataStream<Order> orderB = env.fromCollection(Arrays.asList(new Order(4L, "book4", 3), new Order(5L, "book5", 2), new Order(6L, "book6", 1)));
//将数据流转换成flink table
Table tableA = tEnv.fromDataStream(orderA, "user, product, amount");
Table tableB = tEnv.fromDataStream(orderB, "user, product, amount");
//执行查询操作
Table result = tEnv.sqlQuery("SELECT * FROM " + tableA + " WHERE amount > 2 union all " + "select * from " + tableB + " where amount < 2"); //Flink SQL操作
//Flink Table API
Table result2 = tableA.where("amount > 2").unionAll(tableB.where("amount < 2"));
// 3. 定义输出源
tEnv.toAppendStream(result, Order.class).print();
// 4. 执行flink
env.execute();
}
public static class Order{
public Long user;
public String product;
public int amount;
public Order(){}
public Order(Long user, String product, int amount){
this.user = user;
this.product = product;
this.amount = amount;
}
@Override
public String toString(){
return "Order{" +
"user=" + user +
", product=" + product +
", amount=" + amount+
"}";
}
}
}
TableEnvironment
TableEnvironment是Table API和SQL集成的核心概念,是用来创建 Table API 和 SQL 程序的上下文执行环境 ,也是 Table & SQL 程序的入口,Table & SQL 程序的所有功能都是围绕 TableEnvironment 这个核心类展开的。它负责:
- 在内部目录中注册表
- 注册外部目录
- 执行SQL查询
- 注册用户定义的(指标,表或聚合)函数
- 转换: DataStream 或 DataSet 转换为 Table
- 持有对 ExecutionEnvironment 或 StreamExecutionEnvironment 的引用
在 Flink 1.8 中,一共有 7 个 TableEnvironment ,在最新的 Flink 1.9 中,社区进行了重构和优化,只保留了 5 个TableEnvironment 。在实现上是 5 个面向用户的接口,在接口底层进行了不同的实现。5个接口包括一个 TableEnvironment 接口,两个 BatchTableEnvironment 接口,两个StreamTableEnvironment 接口,5 个接口文件完整路径如下:
- org/apache/flink/table/api/TableEnvironment.java
- org/apache/flink/table/api/java/BatchTableEnvironment.java
- org/apache/flink/table/api/scala/BatchTableEnvironment.scala
- org/apache/flink/table/api/java/StreamTableEnvironment.java
- org/apache/flink/table/api/scala/StreamTableEnvironment.scala
其中TableEnvironment 是顶级接口,是所有 TableEnvironment 的基类 ,BatchTableEnvironment 和StreamTableEnvironment 都提供了 Java 实现和 Scala 实现 ,分别有两个接口。
另一方面,TableEnvironment 作为统一的接口,其统一性体现在两个方面,一是对于所有基于JVM的语言(即 Scala API 和 Java API 之间没有区别)是统一的;二是对于 unbounded data (无界数据,即流数据) 和 bounded data (有界数据,即批数据)的处理是统一的。TableEnvironment 提供的是一个纯 Table 生态的上下文环境,适用于整个作业都使用 Table API & SQL 编写程序的场景。
- 两个 StreamTableEnvironment 分别用于 Java 的流计算和 Scala 的流计算场景,流计算的对象分别是 Java 的 DataStream 和 Scala 的 DataStream。相比 TableEnvironment,StreamTableEnvironment 提供了 DataStream 和 Table 之间相互转换的接口,如果用户的程序除了使用 Table API & SQL 编写外,还需要使用到 DataStream API,则需要使用StreamTableEnvironment。
- 两个 BatchTableEnvironment 分别用于 Java 的批处理场景和 Scala 的批处理场景,批处理的对象分别是 Java 的 DataSet 和 Scala 的 DataSet。相比 TableEnvironment,BatchTableEnvironment 提供了 DataSet 和 Table 之间相互转换的接口,如果用户的程序除了使用 Table API & SQL 编写外,还需要使用到 DataSet API,则需要使用 BatchTableEnvironment。
// 流处理
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.java.StreamTableEnvironment;
StreamExecutionEnvironment sEnv = StreamExecutionEnvironment.getExecutionEnvironment();
// 创建流查询的TableEnvironment
StreamTableEnvironment sTableEnv = StreamTableEnvironment.create(sEnv);
// 批处理
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.table.api.java.BatchTableEnvironment;
ExecutionEnvironment bEnv = ExecutionEnvironment.getExecutionEnvironment();
// 创建批查询的TableEnvironment
BatchTableEnvironment bTableEnv = BatchTableEnvironment.create(bEnv);
在表空间中注册表
TableEnvironment 是维护按名称注册的表的目录。有两种类型的表,输入表和输出表。输入表可以在表API和SQL查询中引用,并提供输入参数。输出表可用于将Table API或SQL查询的结果发送到外部系统。
- 可以从各种来源注册输入表:
- Table API或SQL查询的结果转换成 Table 对象。
- TableSource ,访问外部数据,例如文件,数据库或消息中间件。
- DataStream或DataSet程序创建的 DataStream 或 DataSet 。
- 可以使用 TableSink 注册输出表。
注册表
//获得StreamTableEnvironment(BatchTableEnvironment的用法类似)
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//从表空间中查找表,并执行select操作
Table projTable = tableEnv.scan("tableName").select(...);
// 用一个表注册成另外一个表
tableEnv.registerTable("projectedTable", projTable);
注册TableSource
TableSource 提供对外部数据的访问,存储在存储系统中,例如数据库(MySQL,HBase,…),具有特定编码的文件(CSV,Apache [Parquet,Avro,ORC] …)或消息系统(Apache Kafka,RabbitMQ,…)。
// 创建StreamTableEnvironment(BatchTableEnvironment类似)
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 创建TableSource
TableSource csvSource = new CsvTableSource("/path/to/file", ...);
// 将TableSource注册成表:CsvTable
tableEnv.registerTableSource("CsvTable", csvSource);
注册TableSink
已注册 TableSink 可用于将表API或SQL查询的结果发送到外部存储系统,例如数据库,键值存储,消息队列或文件系统(在不同的编码中,例如,CSV,Apache [Parquet] ,Avro,ORC],…)。
// 创建StreamTableEnvironment(BatchTableEnvironment类似)
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 创建TableSink
TableSink csvSink = new CsvTableSink("/path/to/file", ...);
// 定义字段名称和类型
String[] fieldNames = {"a", "b", "c"};
TypeInformation[] fieldTypes = {Types.INT, Types.STRING, Types.LONG};
// 将TableSink注册成表:CsvSinkTable
tableEnv.registerTableSink("CsvSinkTable", fieldNames, fieldTypes, csvSink);
Table执行过程分析
Flink Table API&SQL 利用了Apache Calcite的查询优化框架,为流式数据和批数据的关系查询保留统一的接口。使用Calcite作为SQL解析与处理引擎有Hive、Drill、Flink、Phoenix和Storm等平台。

Flink Sql 执行流程
一条stream sql从提交到calcite解析、优化最后到flink引擎执行,一般分为以下几个阶段:
- Sql Parser: 将sql语句通过java cc解析成AST(语法树),在calcite中用SqlNode表示AST;
- Sql Validator: 结合数字字典去验证sql语法;
- 生成Logical Plan: 将sqlNode表示的AST转换成LogicalPlan, 用relNode表示;
- 生成 optimized Logical Plan: 先基于calcite rules 去优化logical Plan, 再基于flink定制的一些优化rules去优化logical Plan;
- 生成Flink Physica lPlan: 这里也是基于flink里头的rules,将optimized LogicalPlan转成成Flink的物理执行计划;
- 将物理执行计划转成Flink Execution Plan: 就是调用相应的tanslateToPlan方法转换和利用CodeGen元编程成Flink的各种算子。
Flink Table Api 执行流程
如果是通过table api来提交任务的话,也会经过calcite优化等阶段,基本流程和直接运行sql类似:
- table api parser: flink会把table api表达的计算逻辑也表示成一颗树,用treeNode去表式; 在这棵树上的每个节点的计算逻辑用Expression来表示。
- Validate: 会结合数字字典(catalog)将树的每个节点的Unresolved Expression进行绑定,生成Resolved Expression;
- 生成Logical Plan: 依次遍历数的每个节点,调用construct方法将原先用treeNode表达的节点转成成用calcite 内部的数据结构relNode 来表达。即生成了LogicalPlan, 用relNode表示;
- 生成 optimized Logical Plan: 先基于calcite rules 去优化logical Plan, 再基于flink定制的一些优化rules去优化logical Plan;
- 生成Flink Physical Plan: 这里也是基于flink里头的rules,将optimized LogicalPlan转成成Flink的物理执行计划;
- 将物理执行计划转成Flink Execution Plan: 就是调用相应的tanslateToPlan方法转换和利用CodeGen元编程成Flink的各种算子。
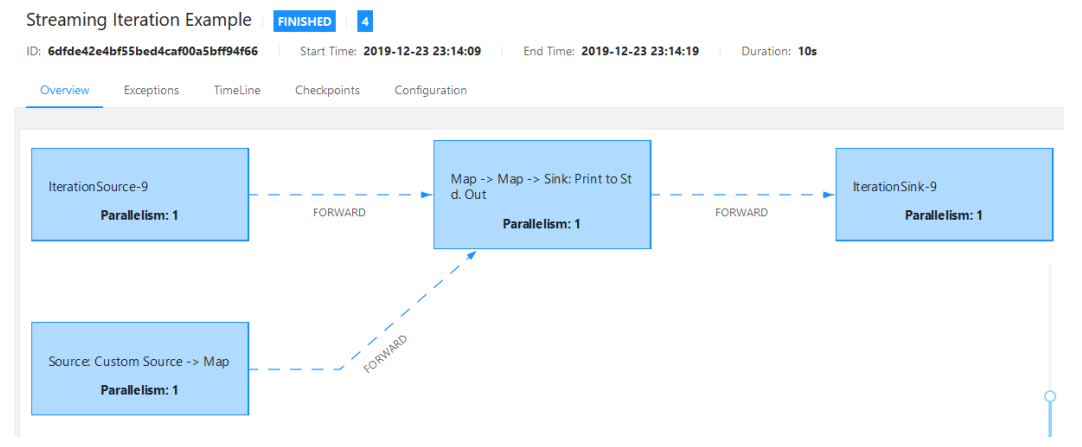
执行计划
Flink会根据客户端提交程序的一些参数,以及集群中机器(TaskManager)的数量去自动优化选取一个它认为合适的执行策略(使数据在DAG中流动计算);了解flink为job选取的执行计划对理解flink是如何执行客户端任务是非常有帮助的。flink提供了最少两种执行计划的可视化的方式,方便了解自己编码客户端的执行计划,从而针对性的进行调试。
- 提交Flink工程,在管理页面上查看执行计划
- Plan Visualization Tool
1.通过flink上下文环境的getExecutionPlan()API输出一段描述执行计划的JSON数据
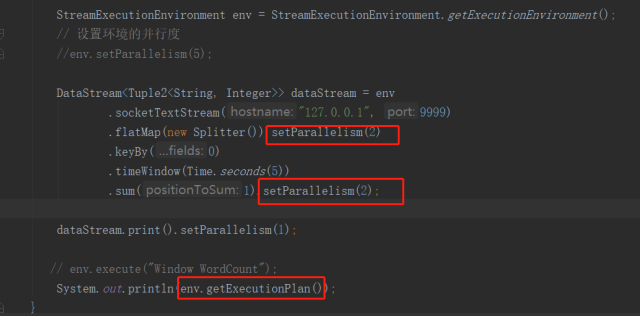
2.将输出的信息贴到flink提供的在线可视化工具(https://flink.apache.org/visualizer)
3.点击Draw效果如下:
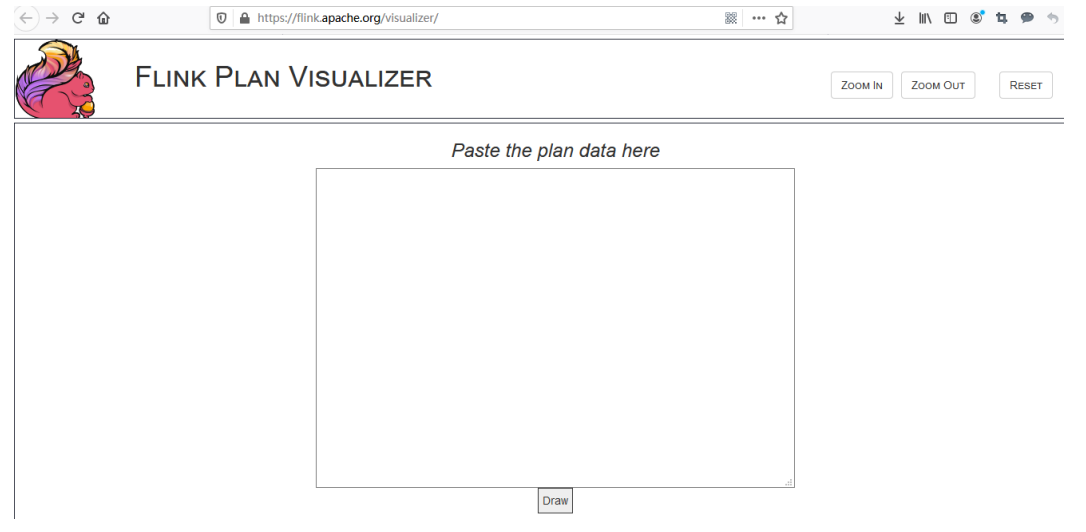
4.点击Draw按钮,效果如下:
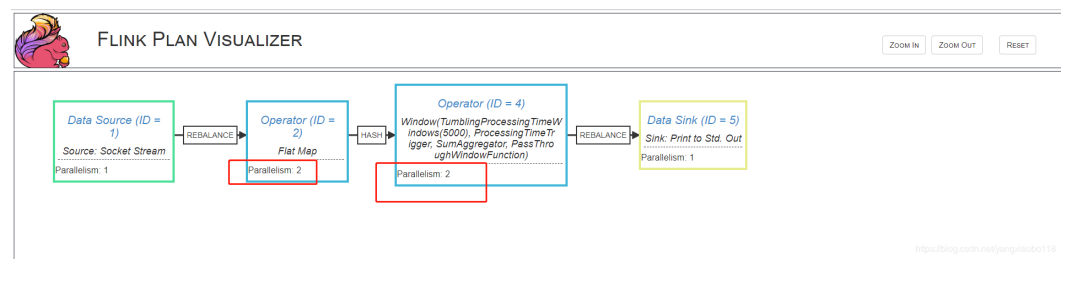
流和批与Table集成编程
表API和SQL查询可以轻松集成并嵌入到DataStream和DataSet程序中。例如,可以查询外部表(例如来自RDBMS),进行一些预处理,例如过滤,投影,聚合或与元数据连接,然后使用DataStream或DataSet API进一步处理数据。 相反,Table API或SQL查询也可以应用于DataStream或DataSet程序的结果。这种相互作用可以通过转换 DataStream 或 DataSet 转换来实现, Table 反之亦然。
将DataStream或DataSet注册为表
DataStream 或 DataSet 可以在 TableEnvironment 表中注册。结果表的模式取决于已注册DataStream 或的数据类型 DataSet 。
// get StreamTableEnvironment
// registration of a DataSet in a BatchTableEnvironment is equivalent
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
DataStream<Tuple2<Long, String>> stream = ...
// register the DataStream as Table "myTable" with fields "f0", "f1"
tableEnv.registerDataStream("myTable", stream);
// register the DataStream as table "myTable2" with fields "myLong", "myString"
tableEnv.registerDataStream("myTable2", stream, "myLong, myString");
注意: 表名: ^DataStreamTable[0-9]+ 和 ^DataSetTable[0-9]+ 是内部关键字,不能作为创建的表名。
将DataStream或DataSet转换为表
除了使用 TableEnvironment 注册 DataStream 或 DataSet ,还可以直接将它们转化成 Table 。这个特性在直接使用Table API查询时非常便利。
// get StreamTableEnvironment
// registration of a DataSet in a BatchTableEnvironment is equivalent
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
DataStream<Tuple2<Long, String>> stream = ...
// Convert the DataStream into a Table with default fields "f0", "f1"
Table table1 = tableEnv.fromDataStream(stream);
// Convert the DataStream into a Table with fields "myLong", "myString"
Table table2 = tableEnv.fromDataStream(stream, "myLong, myString");
将表转换为DataStream或DataSet
Table 可以转换为 DataStream 或 DataSet 。通过这种方式,可以在Table API或SQL查询的结果上运行自定义DataStream或DataSet程序。
当转换一个 Table 成 DataStream 或 DataSet ,需要指定将所得的数据类型 DataStream 或DataSet ,即,数据类型到其中的行 Table 是要被转换。通常最方便的转换类型是 Row 。以下列表概述了不同选项的功能:
- Row:字段按位置,任意数量的字段映射,支持 null 值,无类型安全访问。
- POJO:字段按名称映射(POJO字段必须命名为 Table 字段),任意数量的字段,支持 null 值,类型安全访问。
- Case类:字段按位置映射,不支持 null 值,类型安全访问。
- 元组:字段按位置映射,限制为22(Scala)或25(Java)字段,不支持 null 值,类型安全访问。
- 原子类型: Table 必须具有单个字段,不支持 null 值,类型安全访问。
将表转换为DataStream
Table 流数据查询的结果将动态更新,即它正在改变,因为新记录的查询的输入流到达。因此,DataStream 转换这种动态查询需要对表的更新进行编码。
将a转换 Table 为a 有两种模式 DataStream :
- 追加模式:只有在动态 Table 仅通过 INSERT 更改修改时才能使用此模式,即,它仅附加,并且以前发出的结果永远不会更新。
- 缩进模式:始终可以使用此模式。它用标志编码 INSERT 和 DELETE 改变 boolean 。
// get StreamTableEnvironment.
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// Table with two fields (String name, Integer age)
Table table = ...
// convert the Table into an append DataStream of Row by specifying the class
DataStream<Row> dsRow = tableEnv.toAppendStream(table, Row.class);
// convert the Table into an append DataStream of Tuple2<String, Integer>
// via a TypeInformation
TupleTypeInfo<Tuple2<String, Integer>> tupleType = new TupleTypeInfo<>(Types.STRING(), Types.INT());
DataStream<Tuple2<String, Integer>> dsTuple = tableEnv.toAppendStream(table, tupleType);
// convert the Table into a retract DataStream of Row.
// A retract stream of type X is a DataStream<Tuple2<Boolean, X>>.
// The boolean field indicates the type of the change.
// True is INSERT, false is DELETE.
DataStream<Tuple2<Boolean, Row>> retractStream = tableEnv.toRetractStream(table, Row.class);
将表转换为DataSet
// get BatchTableEnvironment
BatchTableEnvironment tableEnv = BatchTableEnvironment.create(env);
// Table with two fields (String name, Integer age)
Table table = ...
// convert the Table into a DataSet of Row by specifying a class
DataSet<Row> dsRow = tableEnv.toDataSet(table, Row.class);
// convert the Table into a DataSet of Tuple2<String, Integer> via a
TypeInformation
TupleTypeInfo<Tuple2<String, Integer>> tupleType = new TupleTypeInfo<>(Types.STRING(), Types.INT());
DataSet<Tuple2<String, Integer>> dsTuple = tableEnv.toDataSet(table, tupleType);
Mysql数据源
pom文件:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-jdbc_2.12</artifactId>
<version>1.9.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.48</version>
</dependency>
程序:
/**
* 将mysql数据转换成flink table
*/
public class TableJdbc {
public static void main(String[] args) throws Exception{
//1. 定义执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
BatchTableEnvironment batchTableEnvironment = BatchTableEnvironment.create(env);
//定义数据类型
TypeInformation[] fieldTypes = new TypeInformation[]{BasicTypeInfo.INT_TYPE_INFO, BasicTypeInfo.STRING_TYPE_INFO, BasicTypeInfo.INT_TYPE_INFO};
RowTypeInfo rowTypeInfo = new RowTypeInfo(fieldTypes);
//定义JDBC参数
JDBCInputFormat jdbcInputFormat = JDBCInputFormat.buildJDBCInputFormat()
.setDrivername("com.mysql.jdbc.Driver")
.setDBUrl("jdbc:mysql://ip:3306/test01?characterEncoding=utf8")
.setUsername("***")
.setPassword("***")
.setQuery("select * from users")
.setRowTypeInfo(rowTypeInfo)
.finish();
//定义数据源
DataSource source = env.createInput(jdbcInputFormat);
//注册flink table
batchTableEnvironment.registerDataSet("myTable", source);
//执行查询
Table table = batchTableEnvironment.sqlQuery("select * from myTable");
//返回查询结果
DataSet result = batchTableEnvironment.toDataSet(table, Row.class);
//输出
result.print();
}
}
最后
以上就是高大小伙最近收集整理的关于Flink分布式流式处理框架Flink概述单词统计示例基本概念DataStream编程DataSet编程Table API和SQL编程的全部内容,更多相关Flink分布式流式处理框架Flink概述单词统计示例基本概念DataStream编程DataSet编程Table内容请搜索靠谱客的其他文章。








发表评论 取消回复