浅谈storm流式处理框架
什么是流式处理
流式处理,有一个很形象的说法就是,流水线作业,你想象在一个工厂内,几十个工人一起干活,而且在同一个流水线上。比如说我负责生产纸板,有另外一条线是折叠纸板。然后我就做好了一个纸板,我就放到流水线上,这时候下一个工人看到了这个纸板跑过来了,好,拿过来折叠成一个月饼盒的形状,然后做完可能选择放起来,或者立即放到下一个流水线上面进行另外加工,可能是装月饼,或者加工文字。

storm流式处理框架又是什么
storm是apache开源的一款框架,storm是思路就是上边的流式处理思想,不过它处理的不是纸板,而且是一个消息。
什么意思呢,就是说流式处理的不是一个具体的事物,是一个个的消息,你而且是一个字符串,可以是从文件读到一段文字,从数据库读到一个记录,从kafka读到一个kafka消息,都可以理解为一个消息。
storm的架构
按照套路,先给看下storm拓扑架构的大致流程,先要有个大局观,才好知道框架做什么。
这个图呢,是storm的拓扑,这里不是讲storm框架的架构,拓扑是storm的一个理念,基础数据走向都是靠这个拓扑结构处理数据的。
个是一个线程处理类,一种情况可以自定义自己的处理类,也就是说我可以自定义我的消息源来自哪里。比如说我业务需要从kafka获取数据(实际上storm有工具类,可以不用自己写),我需要从activemq获取数据,从数据库表获取数据源,都是看你业务都可以的。
spout组件
是用来接收消息的,实际是一个线程处理类,一种情况可以自定义自己的处理类,也就是说我可以自定义我的消息源来自哪里。比如说我业务需要从kafka获取数据(实际上storm有工具类,可以不用自己写),我需要从activemq获取数据,从数据库表获取数据源,都是看你业务都可以的。
获取到消息后即可IBasicOutputCollector.emmit(new Values(msg) ),提交消息到下一个组件,说白就是提交到下一个流水线。
注意:spout只能用来取数据,不能做耗时任务,否则会导致消费消息阻塞。
bolt组件
bolt组件只是用来执行,执行耗时任务,数据源是从spout提交后过来的。bolt负责接收上一个组件的消息,只要接收到,我就处理任务。
处理完毕,执行IBasicOutputCollector.emmit(,new Values(msg) )时,这个消息又会流到下一个组件去了、如果没有下一个组件关联,当即结束。
案例介绍
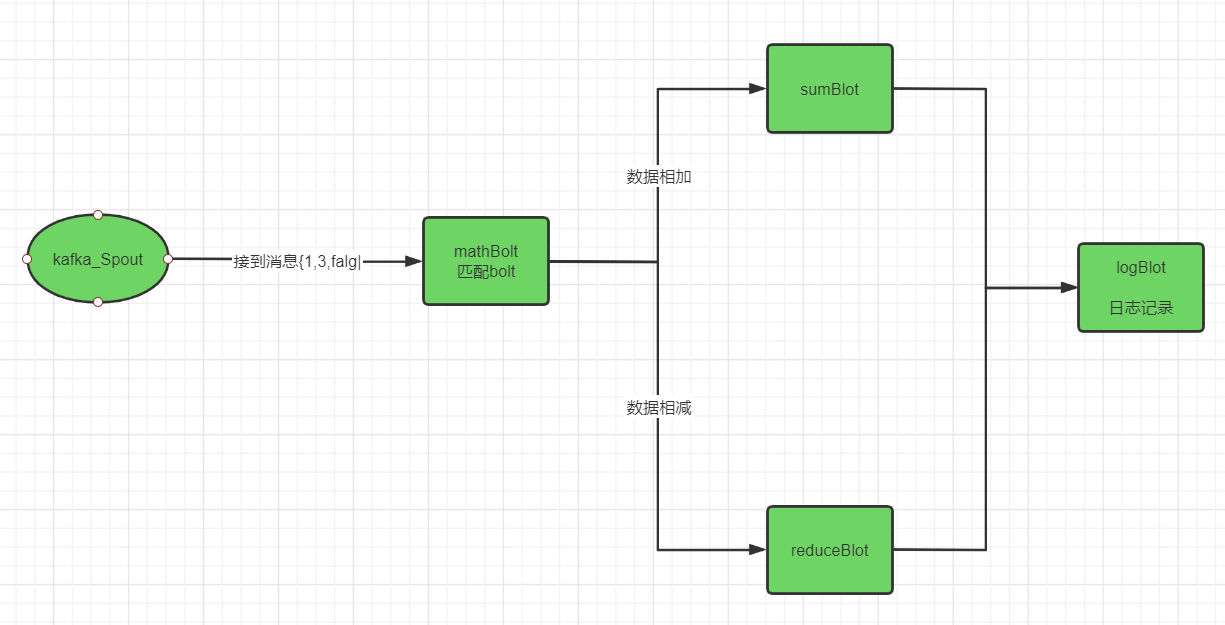
回到上面第二个图那里,是一个具体的案例,我们看到spout是kafka-spout,bolt有四个:matchBolt,sumBolt,reductBolt,logBolt。分别介绍作用。
kafka-spout:负责从kafak消费到消息,消息包括两个数字,用于计算,消费完提交消息到下一个组件matchBolt。
matchBolt:匹配规则bolt,用来匹配这条消息走向哪一个规则,是走sumBolt还是reductBolt。具体规则通过消息里面的falg标志位来判断sumBolt还是reductBolt。这里的匹配可以根据业务来灵活配置。
sumBolt、reductBolt:这里就是具体的数据操作逻辑了,主要用来计算结果,sumBolt 对消息的前两个值进行加法操作、reductBolt 对消息的前两个值进行减法操作。
logBlot:这里主要对sumBolt、reductBolt计算结果进行日志记录,记录计算结果
storm的妙用
连接通道
看了上面那个图,你们肯定还有疑问,那各个组件是什么连接起来的呢。这里涉及到一个连接概念。就是各种组件之间,其实有连接关系的,可以看下面这个图。
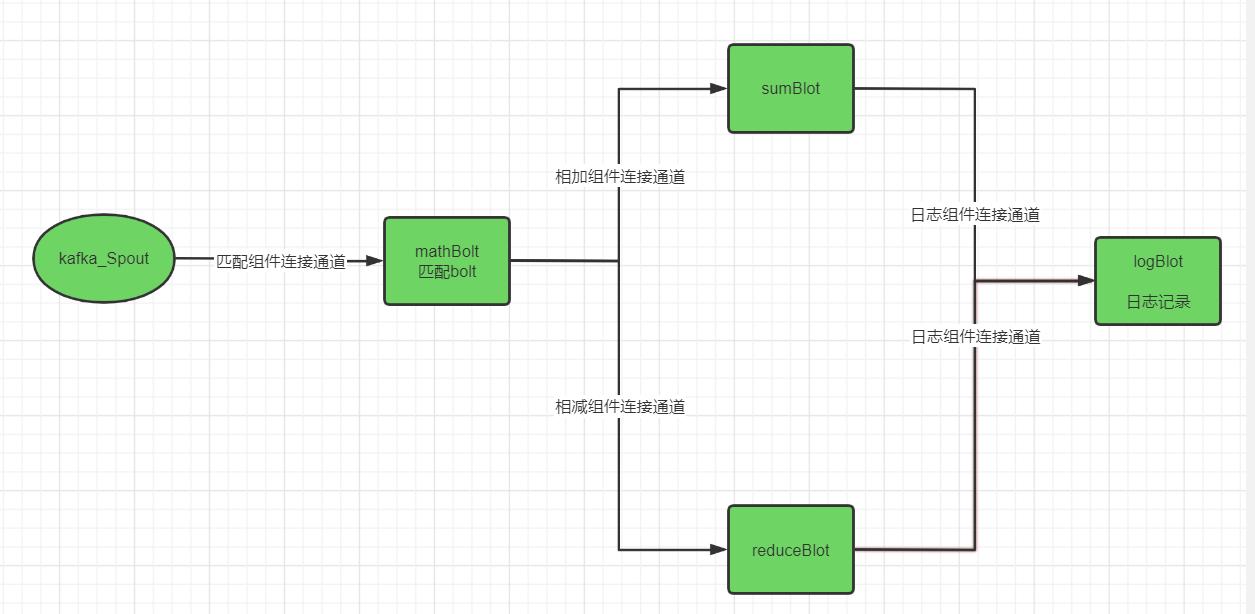
匹配组件连接通道:这里把kafka_spout与matchBolt连接起来。当在spout组件的execte()执行IBasicOutputCollector.emmit(matchBolt通道标识, new Values(msg))的时候,就会把消息提交到当前组件mathBolt。
相加组件连接通道:这里把matchBolt和sumBolt组件建立一个通道,当mathBolt的execute()执行IBasicOutputCollector.emmit(sumBolt通道标识, new Values(msg) )的时候,就会把消息提交到当前组件sumBolt。
相减组件连接通道:这里把matchBolt和reductBolt组件建立一个通道,当mathBolt的execute()执行IBasicOutputCollector.emmit(reductBolt通道标识, new Values(msg) )的时候,就会把消息提交到当前组件reductBolt。
日志组件连接通道:这里把sumBolt、reductBolt和logBolt组件建立一个通道,当sumBolt、reductBolt的execute()执行IBasicOutputCollector.emmit(logBolt通道标识, new Values(msg) )的时候,就会把消息提交到当前组件logBolt。
连接通道组装
这里讲下,实际代码业务中怎么把各个组件连接起来。想要把各个组件代码连接起来,这里要在提交拓扑之间就做好操作。一般可以通过硬编码的方式固定“写死”,适用于结构变动不大的情况。如果拓扑结构,即流水线流程变动频繁,那最好使用可配置的方式来构建拓扑结构。
根据第二、第三张图业务图片,相应的拓扑组装流程代码基本就如下所示,其中写了很多注释,相信你可以看得懂,就不多阐述了。
public static void main(String[] args) {
TopologyBuilder builder = new TopologyBuilder();
//"spout_kafka":通道标识
//new KafkaSpout(spoutConfig):kafkaspout业务处理类,可以传入参数
builder.setSpout("kafka_spout", new KafkaSpout(spoutConfig), kafkaSpout_num);
//.localOrShuffleGrouping:表示本地或随机分组分发
//.localOrShuffleGrouping("spout_kafka"):由kafkaSpout组件当执行emmit()时把消息传递到matchBolt组件
builder.setBolt("matchBolt", new matchBolt(), matchBolt_num).localOrShuffleGrouping("spout_kafka");
builder.setBolt("sumBolt", new sumBolt(), sumBolt_num).fieldsGrouping("matchBolt");
builder.setBolt("reductBolt", new reductBolt(), reductBolt_num).fieldsGrouping("matchBolt");
//.fieldsGrouping:表示指定字段分组
//.fieldsGrouping("matchBolt","sumBolt"):由matchBolt组件当执行emmit()时把消息传递分发到sumBolt组件
//.fieldsGrouping("matchBolt","reductBolt"):由matchBolt组件当执行emmit()时把消息传递分发到reductBolt组件
builder.setBolt("logBolt", new logBolt(), logBolt_num).fieldsGrouping("matchBolt","sumBolt")
.fieldsGrouping("matchBolt","reductBolt");
Config conf = new Config();
// 开启topic的匹配
conf.put("kafka.topic.wildcard.match", true);
// 配置zookeep地址
conf.put("ZK_STR", brokerZkStr);
if (args != null && args.length > 0) {
//worker数据
conf.setNumWorkers(workerNum);
//最大积压数
conf.setMaxSpoutPending(maxSpoutPending);
//超时时间
conf.setMessageTimeoutSecs(messageTimeoutSecs);
//提交单机拓扑
StormSubmitter.submitTopologyWithProgressBar(args[0], conf, builder.createTopology());
} else {
conf.setDebug(true);
conf.setMaxTaskParallelism(3);
LocalCluster cluster = new LocalCluster();
//提交集群拓扑
cluster.submitTopology("KafkaTopology", conf, builder.createTopology());
}
}
消息格式协定
IBasicOutputCollector.emmit(logBolt通道标识, new Values(msg))
这里还是有一点讲究的,emmit(logBolt通道标识, new Values(msg)),
第一个参数是指通道标识,表示流向下一个通道的标识;
第二个参数是指传递的消息,new Values(msg,value1,value2,value…),这里可以传多个参数。
但问题来了,你传了这个几个参数,别人怎么取呢。
其实是new Values(msg,value1,value2,value…),你可以理解为一个map结构,map.put(key,msg),map.put(key1,value1),map.put(key2,value2),map.put(key3,value3)。
采用这种结构就意味着别人取的时候必须根据key取值。那在哪里定义key值,就涉及到另外一个方法declareOutputFields()。
以上面的kafka-spout为例,如果想传两个参数给mathbolt,一个是msg消息体,一个是标志位flag,那就要在方法declareOutputFields(),定义两个标志,如下代码,你就知道怎么定义map的key。
//kafka-spout
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
//"matchBolt" 表示spout与matchbolt的连接通道标识,
//"msg" 表示new Values()方法传入的第一个参数key值是msg
//"falg" 表示new Values()方法传入的第一个参数key值是falg
declarer.declareStream("matchBolt", "msg","falg");
}
同理,如果想在matchBolt从map里面取值,需要在matchBolt类的execute()执行的时候获取,你可以理解Tuple input 就是一个map结构,input是从上一个组件传递下来的封装数据。参考如下代码,省掉了大部分无关代码。
public void execute(Tuple input, BasicOutputCollector collector) {
//input是从上一个组件传递下来的封装数据,其实就是一个map结构
// input.getValueByField("msg") 表示从map取出key值为msg的要统计的数据
JSONObject orderJson = (JSONObject) input.getValueByField("msg") ;
// input.getValueByField("falg") 表示从map取出key值为falg值,用来判断是加计算还是减计算
int falg = (int) input.getValueByField("falg");
}
基本以上就是storm的一个大致的介绍,基本入门使用的一些概念也算交代了一下,后面可能会出更深入的文章,请期待。
后续想第一个时间看到我的文章,可以微信搜索关注「BangBoom」第一时间接收最新文章(比博客推送更快喔),希望我们一起学点东西
最后
以上就是温婉衬衫最近收集整理的关于浅谈storm流式处理框架浅谈storm流式处理框架的全部内容,更多相关浅谈storm流式处理框架浅谈storm流式处理框架内容请搜索靠谱客的其他文章。








发表评论 取消回复