一.片键简介
数据划分(partitioning)关键问题是怎么样将一个集合中的数据均衡的分布在集群中的节点上。 MongoDB 数据划分的是在集合的层面上进行的,它根据片键来划分集合中的数据。
设置分片的时候,需要从集合里选出一个字段,用该字段的值作为数据拆分的依据,这个字段称为片键(shard key),文档中的数据按照这个字段排序切分成块,分布到各个片上。比如说有个
表示人员的
集合,如果选择名字(“name”)字段作为片键,第一片可能会存放名字以A~F开头的文档,
第二个存放的是以G~P开头的文档,第三个存的Q~Z的名字。随着添加(删除)片,MonogDB会重新平衡数据,使每片的流量都比较均衡,数据量也在合理范围内。
片键可以是一个简单索引也可以是一个复合索引(它们必须是集合中某个字段)。
MongoDB将片键的值域划分为不重叠的区间(左闭右开区间),每一个子区间对应一个数据块。MongoDB 通过平衡器和分割器在集群间平衡数据块分布。
每个
数据块都是片键取值范围的子集,它们之间是没有重叠的
。当有新的文档需要插入的时候,MongoDB根据文档片键的取值,来将其放入包含该取值范围的数据块中。
除了直接使用片键的取值范围来指定数据块外,MongodDB也可以使用基于片键哈希值作为数据块的取值范围。
二 Range Based Sharding VS Hash Based Sharding
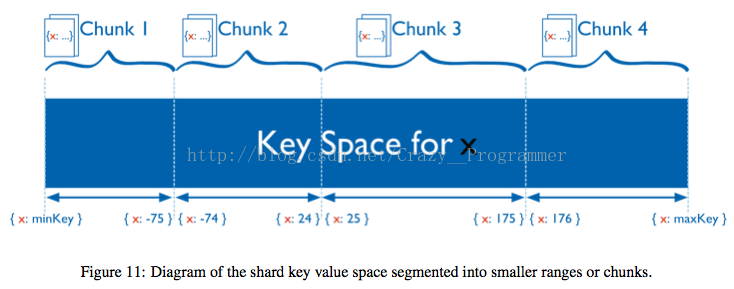
按照片键取值范围来作为数据块划分的区间依据,优点是按范围查询的时候它的效率很高,当给定一个查询范围,根据mongos中的映射表可以很快的定位到分片上的数据块。除此之外当两个分片的键取值比较靠近的时候,会被放到相近的块中,由于数据的局部性原理,这样的话可以加快查询效率,同时也可以减少内存换页次数。
缺点是可能会导致数据分布不均衡,如果选择的片键具有线性的性质,例如时间,将其作为片键的话 ,在某个时间段的写请求(读请求)都会被映射到同一个分片的同一个数据块上, 这样的话不仅会降低系统的读写性能,而且也会因写操作过于集中导致片间的不平衡。
注意:对于升序片键,要分析数据分布性问题,首先我们要记住分片是基于范围的。使用升序的片键,所有最新插入的数据都会落到某个很小的连续范围内。也就是说,这些插入都会被路由到一个块上,而这个块肯定存在某个片上,这实际上抵消了分片一个很大的好处,即将插入的负载自动分布到不同的机器上,这对插入负载很高的应用是不合理的。而且,mongodb是带平衡器的,如果某个片上的chunk过多,那么平衡器会将多出的chunk转移到其它片,升序片键其实也加重了转移chunk的负担。注意,升序片键并不影响更新,只要是随机更新的就可以。再想象这样一种情况,在最初的时候,整个分片里只有一个块,例如1到10000,当数据量增长至20000的时候,则该分片被分成两个数据块,然后将10000到20000的数据块迁移到分片2上,而之
后,所有的写入操作都是写入到分片2中。这就造成了热点全部集中到了分片2上,而人工造成了不平衡的情况。
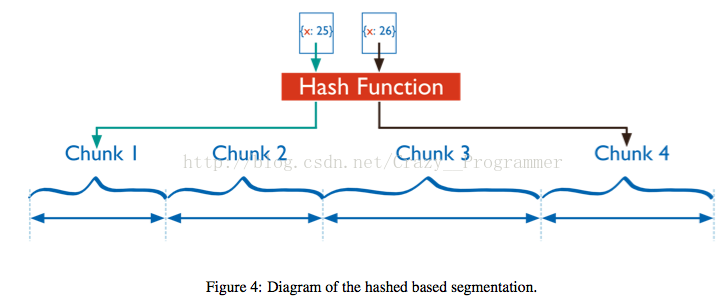
如果按照片键哈希值来作为数据块的划分区间依据,优点是可以确保一个比较均衡的数据分布,因为即使当两个文档的片键取值很接近的时候,例如上面例子中一个x=25,一个x=26,它们的哈希结果也会有很大的差别,这样的话数据会随机的分布到集群中,有利于数据的均衡的分布,减少数据块的移动次数,同时由于数据分散会减少单个数据块的写操作的压力,提高写入速度
。
缺点是随机划分导致数据过于分散,当要查询某个范围内的数据时比如年龄大于20小于25的所有男生信息,如果直接使用范围划分的话,由于其具有良好的数据局部性特点,可能只要访问几个相邻的数据块就行了, 但是如果要使用哈希划分的方法很可能要访问所有的数据块。
如果按照片键哈希值来作为数据块的划分区间依据,优点是可以确保一个比较均衡的数据分布,因为即使当两个文档的片键取值很接近的时候,例如上面例子中一个x=25,一个x=26,它们的哈希结果也会有很大的差别,这样的话数据会随机的分布到集群中,有利于数据的均衡的分布,减少数据块的移动次数,同时由于数据分散会减少单个数据块的写操作的压力,提高写入速度。
缺点是随机划分导致数据过于分散,当要查询某个范围内的数据时比如年龄大于20小于25的所有男生信息,如果直接使用范围划分的话,由于其具有良好的数据局部性特点,可能只要访问几个相邻的数据块就行了, 但是如果要使用哈希划分的方法很可能要访问所有的数据块。
注意:
对于像哈希这种完全随机片键,可以防止数据过度集中的分布性问题,有效减轻单个片的插入负载。但这并不完全合理。假设分片集合里的每个文档都包含一个MD5,而且MD5就是分片键,在对每个分片的MD5字段索引进行插入的时候,每次插入过程中,索引中的每个虚拟内存分页都有可能被访问到,实际上这就意味着索引必须总是装在内存里,如果索引和数据不断增多,超出了物理内存的限制,那么就会产生页错误(page fault),导致性能下降。
这其实是局部引用性问题。局部的概念,在这里指任意给定时间间隔内所访问的数据基本都是有关系的,例如虽然升序的片键是糟糕的,但是它提供了很好的局部性,对索引的连续插入都会发生在最近使用的虚拟内存分页里;因此,在任意时刻内存里只要有一部分索引就可以了。
再用上边的例子,比如说MD5是用户存的文件的MD5值,作为片键,用户上传100个文件,那么对索引的修改就基本会发生在随机的100个地方,但是如果我们使用用户ID作为片键,那么每次写索引基本都会发生在同一个地方,因为插入的文档都拥有相同的用户ID值。这就利用了局部性。
完全随机片键还有一个问题,对这个片键任意一个有意义的范围查询,都会被发送到所有的分片上,然后返回mongos汇总。但是对一个较粗粒度的片键进行范围查询,是可以落到单个分片上。
除了上面说的两种不好的片键之外,还有一种小基数的片键,即片键的值域比较小,通过该片键只能分成有限个数的片,取值有限的片键。这是一种粗力度的片键,比如上边说的用户ID。如果按照用户ID分片,你可以预料到插入会分布在各个分片上,因为无法预知哪个用户何时会插入数据。这样一来,粗粒度分片键也能拥有随机性,还能发挥分片集群的优势。而且粗粒度的片键还能使用局部性带来的效率提升。当某个用户上传100个文件,基于用户ID字段的分片建能确保这些插入都落到同一个分片上,并几乎能写入索引的同一部分,这样效率很高。粗粒度分片键在分布性和局部性上都表现很好,但是它也有一个很难解决的问题:块有可能无限制的增长。想想基于用户ID的片键,假如有几个特殊用户,他们上传了上百万个文件,那么一个块里就可能只有一个用户ID,这个块能拆分么?不能,因为用户ID是最小的粒度,拆分了查询就没法路由到数据。这就造成分片之间数据量不均衡。更典型的就是type,status这类的字段,因为它们的选择性实在是太低,导致无法拆分。片键基比较小时,所有的键值相同导致MongoDB不能分裂Chunk,迁移这些不可分裂的Chunk将更加耗时,即使迁移后也难以保证数据在各个分片上的平衡。Chunk数量被基约束住后,我们就不能利用MongoD分片集群特性将集合部署到更多的机器。
注意:1.片键可以是集合的索引,也可以是集合索引的部分前缀。
2.集群进行插入和查询的时候都要参照片键,它就相当于关系数据库中分库分表的作用。
3.如果查询条件中包含片键或者片键前缀的的话, mongos会将这个请求路由到分片的一个子集上;否则的话,mongos必须将请求转发到包含该集合所有文档的分片上。
例如: 片键 { zipcode: 1, u_id: 1, c_date: 1 }
如果查询请求包含以下的字段的话:
{ zipcode: 1 }
{ zipcode 1,u_id 1}
mongos都会将其路由到集合的子集上。
三 片键的选取原则
在Sharding结构中,分片策略,片键选择是影响性能的关键因素,片键不仅影响数据分布,而且影响业务逻辑,所以片键的选择不单单是均匀的将数据分布到各个片上,而且要考虑查询的性能。坏的片键有时候会导致数据分布很差,有时候会导致无法使用局部性原理,还有一些会影响数据块的拆分。
上边我们讨论了低效片键的问题和原因,理想的片键应该结合粗粒度分片键与细粒度片键两者的优势。
一个好的片键必须包含的特性:
1、保证CRUD能利用局限性 ==》升序片键的优点
2、将插入数据均匀分布到各个分片上 ==》随机片键的优点
3、有足够的粒度进行块拆分 ==》粗粒度片键的优点
满足这些要求的的片键通常由两个字段组成,第一个是粗粒度,第二个是粒度较细。那么我们需要使用复合片键。例如对上面的例子,选取{userid:1,_id:1}作为片键,当用户同时插入数据时,我们可以预见大多数情况下,这些数据会被均匀的分布到所有的片上,而且分片里的唯一字段_id能保证对任意一个文档的查询和更新始终都能指向单个分片。如果对用户ID执行更复杂的查询,那么路由也只会将查询路由包含此用户ID存在的片上,而不会发到所有分片。由于_id(升序)的存在,保证了块始终是能继续拆分的,哪怕用户创建了大量文档,情况也是如此。
所以在选择片键时尽量能保持良好的数据局部性而又不会导致过度热点的出现,很多时候,组合片键是一种比较常用的做法。
除此之外,也可以选择我们经常查询的字段作为片键,这类分片键可以使得查询时mongos仅仅将查询发送给特定的mongod实例,不需要等待多个实例返回数据后再进行合并。
三 总结
一个理想的片键可以极大的提升CRUD的性能,充分利用分片的优势。一般情况下,片键都会选择一个粗粒度+细粒度的组合片键,而且这也能充分利用复合索引的优势(注意顺序)。当然在一些系统中,比如确定用户不会上传大量文档,那么只要一个用户ID也是可以的,看系统设计。最后
以上就是奋斗钢笔最近收集整理的关于MongoDB 自动分片 (二) (Auto-Sharding)的全部内容,更多相关MongoDB内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复