网址:https://github.com/intel-analytics/BigDL
BigDL: Distributed Deep Learning Library for Apache Spark https://bigdl-project.github.io/
Intel开源了基于Apache Spark的分布式深度学习框架BigDL。BigDL借助现有的Spark集群来运行深度学习计算,并简化存储在Hadoop中的大数据集的数据加载。
BigDL适用的应用场景主要为以下三种:
-
直接在Hadoop/Spark框架下使用深度学习进行大数据分析(即将数据存储在HDFS、HBase、Hive等数据库上);
-
在Spark程序中/工作流中加入深度学习功能;
-
利用现有的 Hadoop/Spark 集群来运行深度学习程序,然后将代码与其他的应用场景进行动态共享,例如ETL(Extract、Transform、Load,即通常所说的数据抽取)、数据仓库(data warehouse)、功能引擎、经典机器学习、图表分析等。
运行于Spark集群上
Spark是被工业界验证过的,并有很多部署的大数据平台。BigDL针对那些想要将机器学习应用到已有Spark或Hadoop集群的人。
对于直接支持已有Spark集群的深度学习开源库,BigDL是唯一的一个框架。
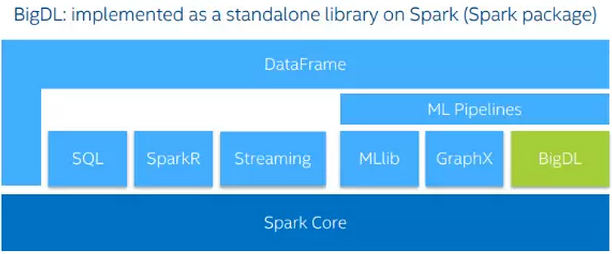
BigDL可以直接运行在已有Spark集群之上,和Spark RDD, DataFrame/DataSet直接接口,不需要额外的集群数据加载,从而大大提高从数据抽取到深度学习建模的开发运行效率。用户不需要对他们的集群做任何改动,就可以直接运行BigDL。BigDL可以和其它的Spark的workload一起运行,非常方便的进行集成。
![]()
BigDL库支持Spark 1.5、1.6和2.0版本。BigDL库中有把Spark RDDs转换为BigDL DataSet的方法,并且可以直接与Spark ML Pipelines一起使用。
BigDL是基于Apache Spark的分布式深度学习框架,借助现有的Spark集群来运行深度学习计算,并简化存储在Hadoop中的大数据集的数据加载。
1.1丰富的深度学习支持。模拟Torch之后,BigDL为深入学习提供全面支持,包括数字计算(通过Tensor)和高级神经网络 ; 此外,用户可以使用BigDL将预先训练好的Caffe或Torch模型加载到Spark程序中。
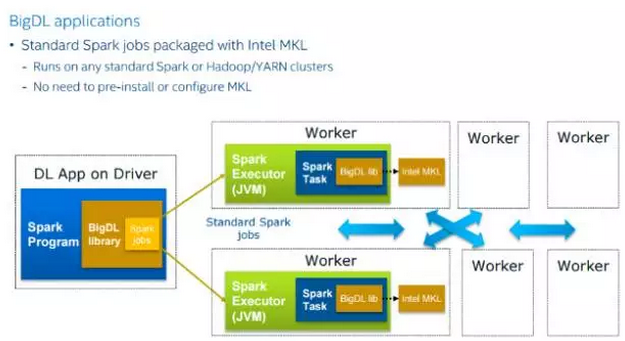
1.2极高的性能。为了实现高性能,BigDL在每个Spark任务中使用英特尔MKL和多线程编程。因此,在单节点Xeon(即与主流GPU 相当)上,它比开箱即用开源Caffe,Torch或TensorFlow快了数量级。
1.2有效地横向扩展。BigDL可以通过利用Apache Spark(快速分布式数据处理框架),以及高效实施同步SGD和全面减少Spark的通信,从而有效地扩展到“大数据规模”上的数据分析
2.为了满足什么应用场景
2.1直接在Hadoop/Spark框架下使用深度学习进行大数据分析(即将数据存储在HDFS、HBase、Hive等数据库上);
2.2在Spark程序中/工作流中加入深度学习功能;
2.3利用现有的 Hadoop/Spark 集群来运行深度学习程序,然后将代码与其他的应用场景进行动态共享,例如ETL(Extract、Transform、Load,即通常所说的数据抽取)、数据仓库(data warehouse)、功能引擎、经典机器学习、图表分析等。
3.核心技术点是那些
BigDL的API是参考torch设计的,为用户提供几个模块:
Module: 构建神经网络的基本组件,目前提供100+的module,覆盖了主流的神经网络模型。
Criterion:机器学习里面的目标函数,提供了十几个,常用的也都包含了。
Optimizer:分布式模型训练。包括常用的训练算法(SGD,Adagrad),data partition的分布式训练。
4.同类对比
速度对比:BigDL目前的测试结果是基于单节点Xeon服务器的(即,与主流GPU相当的CPU),在Xeon上的结果表明,比开箱即用的开源Caffe,Torch或TensorFlow速度上有“数量级”的提升,最高可达到48倍的提升。而且能够扩展到数十个Xeon服务器
语言对比:Caffe和Torch主要使用C++架构,bigDL主要使用Scala开发
对GPU的支持:caffe和Torch对GPU有较好的支持,但不同版本接口不兼容,BigDL不支持
5.优势劣势
优势:
针对每个Spark task使用了多线程编程。
BigDL使用英特尔数学内核库(Intel MKL)来得到最高性能要求
使用BigDL,由caffe和torch创建的模型可以加载到Spark程序并运行。Spark还允许跨集群的高效扩展。
劣势:对机器要求高 jdk7上运行性能差 在CentOS 6和7上,要将最大用户进程增加到更大的值(例如514585); 否则,可能会看到错误,如“无法创建新的本机线程”。
训练和验证的数据会加载到内存,挤占内存
6.发展前景
BigDL 是基于Spark的深度学习库,对大数据的实现有着非常好的契合度,也有着比较全面的API,非常适合直接在Hadoop/Spark框架下使用深度学习进行大数据分析。但与其他深度学习框架相比,开源时间较短,发展不成熟,对GPU并没有良好的支持,是intel为了提高自家处理器的竞争能力而设计的,如果能整合加入对GPU的支持,发展前景将会很好。
原文:http://blog.csdn.net/sinat_34233802/article/details/68942828
最后
以上就是鲜艳过客最近收集整理的关于Spark上的深度学习框架BigDL 介绍的全部内容,更多相关Spark上的深度学习框架BigDL内容请搜索靠谱客的其他文章。



![使用Spark\/BigDL高级机器学习实现寿险业务再发现 [session]](https://www.shuijiaxian.com/files_image/reation/bcimg9.png)




发表评论 取消回复